تحلیل آماری، علم جمعآوری، سازماندهی و تفسیر دادهها برای تصمیمگیری است. این تحلیل در قلب علم داده قرار دارد و کاربردهای گستردهای از امتیازات اعتباری و بیمه تا پیش بینی تورم و تحلیلهای پزشکی دارد. پس نیاز است شما بعنوان تحلیل گر داده ، علم داده ، دانشمند داده و سایر عناوین مرتبط با علم داده آمار توصیفی ؛ اندازهگیریهای آماری و توزیعهای احتمالی را به خوبی بشناسید.
آمار توصیفی شامل سه دسته اصلی است: سنجههای گرایش مرکزی (میانگین، میانه، مد)، سنجههای پراکندگی (انحراف معیار) و سنجههای موقعیت (صدک، چارک). همچنین شامل تولید مدیشهای گرافیکی مانند هیستوگرام و نمودار جعبهای میشود.
نظریه احتمال نیز در این مطلب معرفی میشود که به کمیسازی عدم قطعیت در دادههای واقعی کمک کرده و پایهگذار تحلیلهای پیشرفتهتری مانند فواصل اطمینان، آزمون فرضیه و یادگیری ماشین است. ابزارهایی مانند پایتون، اکسل و R برای خودکارسازی محاسبات آماری استفاده میشوند.
میانگین (Mean)
رایجترین سنجه گرایش مرکزی است که از تقسیم مجموع دادهها بر تعداد آنها به دست میآید. نقطه ضعف اصلی آن حساسیت به دادههای پرت است.
در علم داده با دو نوع میانگین مواجهیم:
میانگین نمونه (x̄): محاسبه شده از زیرمجموعهای از جامعه با فرمول
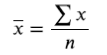
که در آن:
x̄ = میانگین جامعه
Σx = مجموع تمام مقادیر داده در جامعه
N = حجم جامعه (تعداد کل دادهها)
مثال :
در یک کارآزمایی بالینی، ضربان نبض ۱۰ بیمار به این صورت ثبت شده: 68, 92, 76, 51, 65, 83, 94, 72, 88, 59. برای محاسبه میانگین، مجموع مقادیر یعنی 748 را بر تعداد دادهها یعنی 10 تقسیم میکنیم. نتیجه: میانگین 74.8 ضربان در دقیقه.

میانگین جامعه (μ): محاسبه شده از کل جامعه با فرمول :

میانگین را میتوان با استفاده از توزیع فراوانی نیز تعیین کرد. برای هر مقدار داده یکتا در مجموعه داده، توزیع فراوانی، تعداد دفعات یا فراوانی ظهور آن مقدار یکتا را در مجموعه داده نشان میدهد. در این نوع موقعیت، میانگین را میتوان با ضرب هر مقدار متمایز در فراوانی آن، جمع کردن این مقادیر، و سپس تقسیم این مجموع بر تعداد کل مقادیر داده، محاسبه کرد. در اینجا فرمول مربوط به میانگین نمونه با استفاده از توزیع فراوانی آورده شده است:

که در آن:
μ = میانگین نمونه
f = فراوانی هر مقدار داده یکتا
x = مقدار داده یکتا
Σ(f × x) = مجموع حاصلضرب هر مقدار در فراوانی آن
n = حجم نمونه (تعداد کل دادهها)
مثال :
یک استاد دانشگاه، سن 25 دانشجو را در کلاس علم داده به صورت زیر ثبت میکند:

میانگین سنی را برای این نمونه از دانشجویان محاسبه کنید.
حل:
مقادیر جدول را در فرمول زیر جایگزین میکنیم:

میانگین بریدهشده (Trimmed Mean)
میانگین بریدهشده به کاهش تأثیر دادههای پرت (مقادیری که تفاوت زیادی با بقیه دادهها دارند) کمک میکند. وجود دادههای پرت باعث میشود میانگین معمولی منحرف شده و نتیجه گمراهکنندهای ارائه دهد.
برای محاسبه میانگین بریدهشده:
۱. دادهها را از کوچک به بزرگ مرتب کنید.
۲. درصد مشخصی (معمولاً ۱۰٪ یا ۲۰٪) از دادههای دو انتهای مجموعه را حذف کنید.
۳. میانگین دادههای باقیمانده را محاسبه کنید.
برای محاسبه میانگین بریدهشده ۱۰٪، دادهها را مرتب کرده، ۱۰٪ مقادیر کوچکتر و ۱۰٪ مقادیر بزرگتر را حذف میکنیم، سپس میانگین دادههای باقیمانده را محاسبه میکنیم. این روش دادههای پرت را حذف کرده و میانگین مدیندهتری ارائه میدهد.
مسئله
یک مشاور املاک دادههایی را در مورد نمونهای از خانههای اخیراً فروختهشده در یک محله خاص جمعآوری میکند، و دادهها در مجموعه داده زیر نشان داده شده است:
397900, 452600, 507400, 488300, 623400, 573200, 1689300, 403890, 612300, 599000, 2345800, 499000,525000, 675000, 385000
۱. میانگین مجموعه داده را محاسبه کنید.
۲. میانگین بریدهشده ۲۰ درصد را برای مجموعه داده محاسبه کنید.
حل
۱. برای میانگین، ۱۵ مقدار داده را با هم جمع میکنیم، و مجموع برابر با ۱۰,۷۷۷,۰۹۰ است. این مجموع را بر تعداد دادهها که ۱۵ است تقسیم میکنیم. نتیجه به صورت زیر است:

۲. برای میانگین بریدهشده، ابتدا دادهها را از کوچک به بزرگ مرتب میکنیم. مجموعه داده مرتبشده به صورت زیر است:
385000, 397900, 403890, 452600, 488300, 499000, 507400, 525000, 573200, 599000, 612300, 623400,675000, 1689300, 2345800
بیست درصد از ۱۵ مقدار داده برابر با ۳ است، و این نشان میدهد که ۳ مقدار داده از هر انتهای پایین و بالای مجموعه داده حذف میشوند. ۹ مقدار داده حذفنشده به دست آمده عبارتند از:
452600, 488300, 499000, 507400, 525000, 573200, 599000, 612300, 623400
سپس میانگین را برای مقادیر داده باقیمانده محاسبه میکنیم. مجموع این ۹ مقدار داده برابر با ۴,۸۸۰,۲۰۰ است. این مجموع را بر تعداد دادهها 9 تقسیم میکنیم. نتیجه به صورت زیر است:

توجه کنید که میانگین محاسبهشده در بخش (۱) در مقایسه با میانگین بریدهشده محاسبهشده در بخش (۲) به طور قابل توجهی بزرگتر است. دلیل این امر وجود چندین مقدار پرت بزرگ قیمت خانه است. هنگامی که این مقادیر داده پرت توسط محاسبه میانگین بریدهشده حذف میشوند، میانگین بریدهشده به دست آمده در مقایسه با میانگین معمولی، مدیندهتری از قیمت معمولی خانه در این محله است.
میانه (Median)
میانه سنجه دیگری از گرایش مرکزی است که در حضور دادههای پرت، معیار بهتری نسبت به میانگین محسوب میشود، زیرا تحت تأثیر مقادیر عددی دادههای پرت قرار نمیگیرد و فقط به مقدار میانی توجه دارد.
روش محاسبه میانه:
دادهها را از کوچک به بزرگ مرتب کنید.
مقدار میانی را پیدا کنید:
اگر تعداد دادهها فرد باشد ، میانه همان مقدار میانی است.
اگر تعداد دادهها زوج باشد ، میانه برابر با میانگین دو مقدار میانی است.
مسئله :
همان مجموعه داده ضربان نبض را در نظر بگیرید:
68, 92, 76, 51, 65, 83, 94, 72, 88, 59
میانه ضربان نبض را برای این نمونه محاسبه کنید.
حل
ابتدا ۱۰ مقدار داده را از کوچک به بزرگ مرتب میکنیم:
51, 59, 65, 68, 72, 76, 83, 88, 92, 94
از آنجا که تعداد دادهها زوج است، دو مقدار میانی را با هم جمع کرده و بر ۲ تقسیم میکنیم.
دو مقدار میانی عبارتند از 72 و 76 پس میانه :

برای یافتن سریع میانه یک مجموعه داده، ابتدا تعداد دادهها یعنی n را مشخص میکنیم.
اگر تعداد دادهها فرد باشد، میانه برابر با مقداری است در موقعیت (n+1)/2. به عنوان مثال، در مجموعهای با ۲۵ داده، میانه در موقعیت سیزدهم قرار دارد.
اگر تعداد دادهها زوج باشد، میانه برابر با میانگین دو مقداری است که در موقعیتهای n/2 و (n/2)+1 قرار دارند. به عنوان مثال، در مجموعهای با ۱۰۰ داده، میانه میانگین دادههای پنجاهم و پنجاه و یکم است.
مد (Mode)
مد سنجه دیگری از گرایش مرکزی است و به مقداری گفته میشود که بیشترین فراوانی را در مجموعه داده دارد.
اگر هیچ مقدار تکراری وجود نداشته باشد، آن مجموعه داده مد ندارد.
اگر دو مقدار بیشترین فراوانی برابر داشته باشند، modality (bimodal) نامیده میشود.
مثال عددی: در دادههای قیمت سهام زیر مد را حساب کنید :
50, 53, 59, 59, 63, 63, 72, 72, 72, 72, 72, 76, 78, 81, 83, 84, 84, 84, 90, 93
راه حل :
برای یافتن مد، بیشترین عدد تکراری را تعیین کنید، که ۷۲ است و پنج بار تکرار شده است. بنابراین، مد این مجموعه داده ۷۲ میباشد.
مزیت مهم مد: بر خلاف میانگین و میانه، مد را میتوان برای دادههای غیرعددی (کیفی) مانند رتبهبندی رضایت مشتری (عالی، خوب، ضعیف) نیز استفاده کرد.
مد همچنین میتواند برای دادههای غیرعددی (کیفی) به کار رود، در حالی که میانگین و میانه فقط برای دادههای عددی (کمی) قابل استفاده هستند. برای مثال، یک مدیر رستوران ممکن است بخواهد مد را برای پاسخهای نظرسنجی مشتریان در مورد کیفیت خدمات یک رستوران تعیین کند، همانطور که در جدول زیر نشان داده شده است.

بر اساس پاسخهای نظرسنجی، مد، رتبهبندی خدمات مشتری Very Good است، زیرا این مقدار داده با بیشترین فراوانی میباشد.
تأثیر دادههای پرت بر معیارهای مرکز
همانطور که قبلاً اشاره شد، هنگامی که دادههای پرت در یک مجموعه داده وجود داشته باشند، ممکن است میانگین مرکز مجموعه داده را نشان ندهد، و میانه معیار بهتری برای مرکز ارائه خواهد داد. دلیل این امر آن است که میانه بر روی مقدار میانی مجموعه داده مرتبشده تمرکز دارد. بنابراین، هیچ داده پرتی در انتهای پایینی مجموعه داده یا در انتهای بالایی مجموعه داده، تأثیری بر میانه نخواهد داشت.
نکته: روشی رسمی برای شناسایی دادههای پرت، در بحث معیارهای موقعیت ( Measures of Position ) در مطالب بعد ارائه خواهد شد.
مثال زیر این نکته را نشان میدهد که وقتی دادههای پرت بالقوه وجود دارند، میانه معیار بهتری برای سنجش گرایش به مرکز است.
مسئله:
فرض کنید در یک شرکت کوچک با ۴۰ کارمند، یک نفر حقوق سالانه ۳ میلیون دلار دریافت میکند و ۳۹ نفر دیگر هر کدام ۴۰,۰۰۰ دلار دریافت میکنند. کدام معیار مرکز بهتر است: میانگین یا میانه؟
حل:
میانگین به دلار به صورت ریاضی به شرح زیر محاسبه میشود:

اما میانه برابر با ۴۰,۰۰۰ دلار خواهد بود، زیرا این مقدار میانی در مجموعه داده مرتبشده است. ۳۹ نفر ۴۰,۰۰۰ دلار و یک نفر ۳,۰۰۰,۰۰۰ دلار دریافت میکند.
توجه کنید که میانگین معرف مقدار معمول در مجموعه داده نیست، زیرا ۱۱۴,۰۰۰ دلار نشاندهنده میانگین حقوق برای اکثر کارمندان (که ۴۰,۰۰۰ دلار دریافت میکنند) نمیباشد. در این حالت، میانه معیار بسیار بهتری برای متوسط نسبت به میانگین است، زیرا ۳۹ تا از مقادیر ۴۰,۰۰۰ دلار و یکی ۳,۰۰۰,۰۰۰ دلار است. مقدار ۳,۰۰۰,۰۰۰ دلار یک داده پرت محسوب میشود. نتیجه میانه یعنی ۴۰,۰۰۰ دلار، درک بهتری از مرکز مجموعه داده به ما میدهد.