یکی از نقاط قوت پایتون این است که شامل مجموعهای متنوع از کتابخانههای رایگان و متنباز است.
کتابخانهها مجموعهای از متدها و توابع از پیش پیادهسازیشده هستند که برنامهنویس میتواند به آنها مراجعه کند و به این ترتیب، نیازی به نوشتن دوبارهی توابع رایج از صفر نداشته باشد.
Pandas یک کتابخانهی پایتون است که بهطور تخصصی برای کار و تحلیل داده طراحی شده و در بین دانشمندان داده بسیار پرکاربرد است. این کتابخانه متدهای متنوعی را ارائه میدهد که به تحلیلگران داده اجازه میدهد بهسرعت از آنها برای تحلیل داده استفاده کنند. در طول این دوره، نحوهی تحلیل داده با استفاده از Pandas را یاد خواهید گرفت.
نصب کتابخانه Pandas
قبل از اینکه بتوانیم با Pandas کار کنیم ، باید آن را نصب کنیم .برای نصب Pandas ابتدا باید پایتون روی سیستم ما نصب شده باشد. برای این کار، ترمینال VS Code رو باز میکنیم و این دستور رو میزنیم:
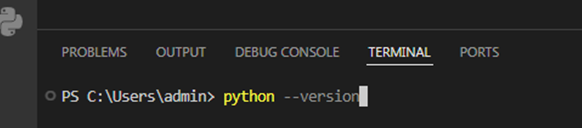
اگر نسخه پایتون نمایش داده شد، یعنی پایتون آمادهی استفادهست.
برای نصب Pandas از ابزار مدیریت بستهی پایتون یعنی pip استفاده میکنیم.

Import کردن Pandas
نخست یک فایل جدید جوپیتر پایتون ( Jupyter Notebook ) بنام main.ipynb ایجاد کنید:
. برای استفاده از Pandas ، کافی است که ، آن را import کنیم :
فایل main.ipynb را باز کنید.
import pandas as pd
توجه داشته باشید که طبق یک قرارداد رایج، نام pandas بهصورت pd مخفف میشود تا هنگام استفاده از متدهای آن، بهجای نوشتن کامل نام Pandas ، فقط از pd استفاده شود؛ این کار باعث راحتی و سرعت بیشتر در برنامهنویسی میشود.
بارگذاری داده با Pandas در پایتون
اولین قدم در تحلیل داده ، بارگذاری دیتاست مورد نظر در محیط کاری است. دیتاست movieprofit.csv رو دانلود کنید و در پوشه پروژه قرار دهید.
خواندن دیتاست
متد read_csv در Pandas برای خواندن فایلهای CSV استفاده میشود و دادهها را به شکل یک DataFrame ذخیره میکند.
DataFrame نوع دادهای در Pandas است که برای ذخیرهی دادههای جدولی چندستونه استفاده میشود.
data = pd.read_csv("movieprofit.csv") data
بعداز اجرا خروجی همانند تصویر زیر خواهد بود :
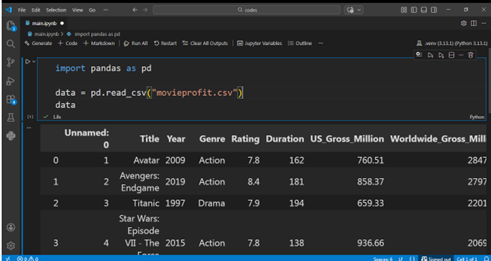
Pandas دو نوع دادهی اصلی برای دادههای جدولی تعریف میکند:
DataFrame : برای دادههای چندستونه
Series : برای دادههای تک ستونه
بسیاری از متدهای Pandas هم روی DataFrame و هم روی Series کار میکنند، اما بعضی متدها فقط مخصوص یکی از آنها هستند؛ بنابراین همیشه بهتر است بررسی کنید متدی که استفاده میکنید دقیقاً چه رفتاری دارد.
میتوانید با استفاده از متد DataFrame.describe خیلی سریع آمارهای پایهای دادهها را محاسبه کنید.
کد زیر را اضافه و اجرا کنید. این کد متد describe را روی متغیر data فراخوانی میکند.
data = pd.read_csv("movieprofit.csv") data.describe()
متد describe یک جدول برمیگرداند که ستونهای آن زیرمجموعهای از ستونهای کل مجموعهداده هستند و سطرهای آن شامل آمار های مختلف می باشند.
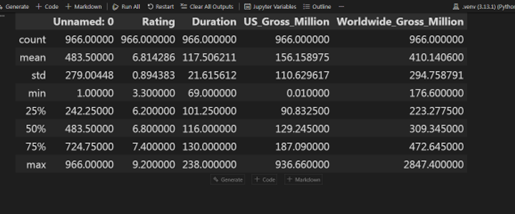
این آمارها شامل تعداد مقادیر موجود در هر ستون (count)، میانگین (mean)، انحراف معیار (std)، کمینه و بیشینه (max, min) و همچنین چارکهای مختلف (25% ، 50% و 75%) که در مبحث «معیارهای پراکندگی» با آنها آشنا خواهید شد.
با استفاده از این نمایش، میتوانید بهراحتی چنین آمارهایی را برای ستونهای مختلف مجموعهداده محاسبه کنید.
انتخاب داده با استفاده از Pandas در پایتون
DataFrame در کتابخانه Pandas این امکان را به برنامهنویس میدهد که برای انتخاب یک ستون، مستقیماً از نام ستون استفاده کند.
برای مثال، کد زیر تمام مقادیر ستون US_Gross_Million را چاپ میکند. خروجی این انتخاب بهصورت یک Series خواهد بود (یادآوری: دادههای یک ستون تکی در Pandas در قالب Series ذخیره میشوند.)
import pandas as pd data = pd.read_csv("movieprofit.csv") data["US_Gross_Million"]
خروجی کد بالا مانند تصویر زیر است :
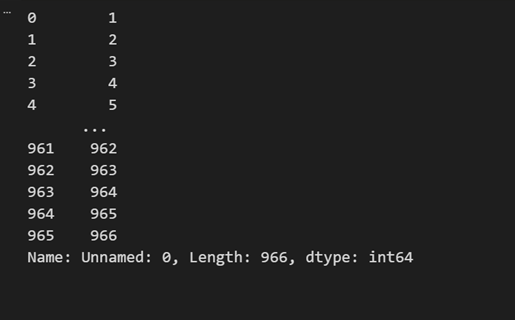
علاوه بر این، متد DataFrame.iloc[] امکان انتخاب پیشرفتهتری را فراهم میکند. با استفاده از iloc میتوان هم سطر و هم ستون را بر اساس اندیس عددی آنها انتخاب کرد.
data.iloc[:,2]
خروجی همانند تصویر زیر خواهد بود:
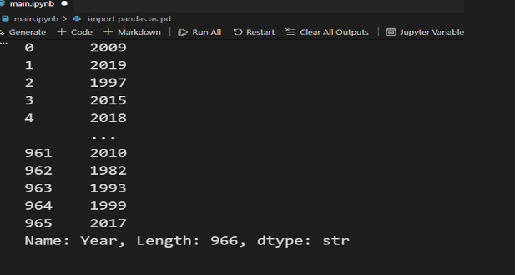
در ادامه، چند مثال ارائه میشود تا نحوهی استفاده از این روشها را بهتر درک کنیم.
مثال یک : انتخاب همه مقدار ها در ستون دوم :
data.iloc[:,2]
مثال دوم : انتخاب هم مقدارها در ردیف سوم :
data.iloc[2, :]
خروجی:
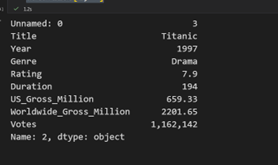
مثال سوم : برای تعیین یم مقدار دقسق در یک ستون ، می توانیم از شماره اندیس استفاده کنیم:
print(data["US_Gross_Million"][0])
شما همچنین میتوانید از []DataFrame.iloc برای انتخاب یک بخش مشخص از سلولها در جدول استفاده کنید.
کد نمونهی زیر روشهای مختلف استفاده از []iloc را نشان میدهد.vوشهای متعددی برای کار با []iloc وجود دارد، اما در این جلسه فقط چند روش رایج معرفی میشود.
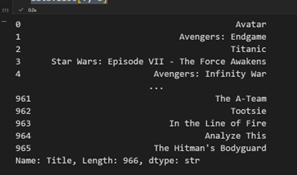
مثال چهار : انتخاب همه مقادیر در ستون دوم ( اندیس 1 )
data.iloc[:, 1]
خروجی :
مثال زیر را امتحان کنید :
data.iloc[[1, 3], [2, 3]]
جستوجوی داده با استفاده از Python Pandas
برای جستوجو یا فیلتر کردن دادههایی که شرایط خاصی را برآورده میکنند، میتوانید از [] DataFrame.loc در کتابخانهی Pandas استفاده کنید.
زمانی که شرط فیلتر را داخل براکتها [] مشخص میکنید، خروجی فقط شامل ردیفهایی از DataFrame خواهد بود که آن شرط را دارند.
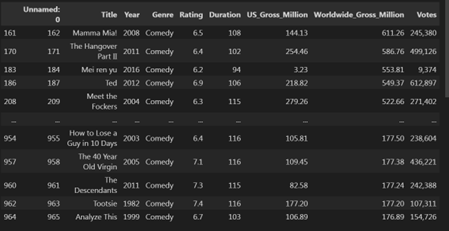
برای مثال، در کد زیر ردیفهایی فیلتر میشوند که مقدار ستون Genre آنها برابر با Comedy است.
توجه کنید که خروجی فقط شامل ۳۰۷ ردیف از مجموع ۳۴۰۰ ردیف کل دادههاست. اگر خودتان خروجی را بررسی کنید، خواهید دید که مقدار ستون Genre در همهی این ردیفها برابر با "Comedy" است.
import pandas as pd data = pd.read_csv("movieprofit.csv") data.loc[data["Genre"] == "Comedy"]
خروجی :
مصورسازی دادهها با استفاده از Python و Matplotlib
روشهای مختلفی برای رسم نمودار دادهها در پایتون وجود دارد. رایجترین و سادهترین روش این است که از کتابخانهای به نام Matplotlib استفاده کنیم که بهطور تخصصی برای مصورسازی دادهها طراحی شده است.
Matplotlib یک کتابخانهی بزرگ است، اما برای رسم نمودارها فقط کافی است زیرماژولی به نام pyplot را وارد کنیم.
برای نصب matplotlib دستور زیر را وارد کنید و همانند pandas عمل کنید. توجه داشته باشید که طبق قرارداد، معمولاً از نام کوتاه plt برای matplotlib.pyplot استفاده میشود؛ درست مشابه کاری که برای Pandas از pd استفاده میکنیم.
import matplotlib.pyplot as plt
Matplotlib برای هر نوع نمودار یک متد اختصاصی ارائه میدهد و در طول این دوره با متدهای مربوط به رایجترین انواع نمودارها آشنا خواهید شد. با این حال، در این جلسه بهطور خلاصه نحوهی رسم یک نمودار با استفاده از Matplotlib را بررسی میکنیم.
فرض کنید میخواهید یک نمودار پراکندگی (Scatter Plot) بین ستونهای US_Gross_Million و Worldwide_Gross_Million از مجموعهدادهی سود فیلمها (movieprofit.csv) رسم کنید. در فصل «تحلیل همبستگی و رگرسیون خطی» بهصورت مفصلتر به نمودارهای پراکندگی میپردازیم.
در کد نمونهی زیر، با استفاده از متد ()scatter چنین نموداری رسم میشود. این متد دو ستون مورد نظر شما، یعنی
data["US_Gross_Million"] و data["Worldwide_Gross_Million"] را بهعنوان ورودی دریافت میکند و آنها را بهترتیب به محورهای x و y اختصاص میدهد.
import pandas as pd import matplotlib.pyplot as plt data = pd.read_csv("movieprofit.csv") plt.scatter(data["US_Gross_Million"], data["Worldwide_Gross_Million"])
خروجی :
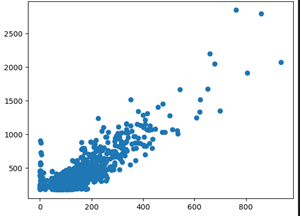
توجه کنید که این نمودار فقط مجموعهای از نقاط را روی یک صفحهی سفید نشان میدهد. خودِ نمودار بهتنهایی مشخص نمیکند هر محور چه چیزی را نمایش میدهد یا این نمودار دقیقاً دربارهی چیست. بدون این توضیحات، درک مفهوم نمودار دشوار خواهد بود.
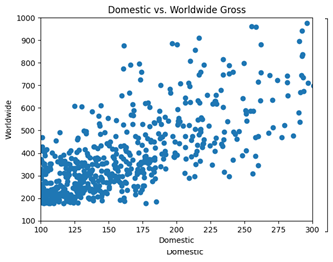
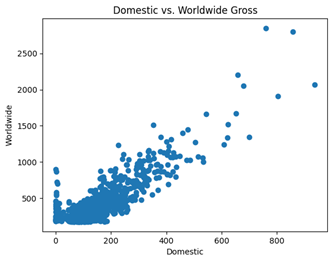
میتوانید این اطلاعات را با استفاده از کد زیر تنظیم کنید. نمودار نهایی نشان میدهد که بین فروش داخلی (Domestic Gross) و فروش جهانی (Worldwide Gross) یک همبستگی مثبت وجود دارد.
import pandas as pd import matplotlib.pyplot as plt data = pd.read_csv("movieprofit.csv") plt.scatter(data["US_Gross_Million"], data["Worldwide_Gross_Million"]) plt.title("Domestic vs. Worldwide Gross") plt.xlabel("Domestic") plt.ylabel("Worldwide")
خروجی :
همچنین میتوانید بازهی اعداد روی محورهای افقی و عمودی را با استفاده از توابع ()plt.xlim و () plt.ylim تغییر دهید.
دو خط کد زیر را اضافه کنید که در مثال قبلی برای رسم نمودار پراکندگی (scatterplot) استفاده شده بود.
plt.xlim(100, 300) plt.ylim(100, 1000)
خروجی :