در دنیای علم داده، یکی از مهمترین مراحل، جمعآوری داده (Data Collection) است.بخش قابل توجهی از دادههای ارزشمند، در وبسایتها و شبکههای اجتماعی قرار دارند. در مطلب نهم از علم داده با دو رویکرد مهم برای استخراج این دادهها آشنا میشویم:
خزش وب (Web Scraping)
جمعآوری دادههای شبکههای اجتماعی (Social Media Data Collection)
خزش وب (Web Scraping) چیست؟
خزش وب به معنای استخراج خودکار اطلاعات از وبسایتها با استفاده از برنامههای نرمافزاری (Web Scraper) است.
مثال کاربردی:
فرض کنید یک شرکت مسافرتی بخواهد قیمت و ظرفیت هتلها را از چندین سایت رزرو جمعآوری کند. به جای انجام دستی این کار، میتوان با خزش وب دادهها را بهصورت خودکار استخراج و برای تحلیل استفاده کرد.
تکنیکهای رایج در Web Scraping
1- Web Crawling
دنبال کردن لینکهای موجود در یک صفحه وب برای رفتن به صفحات دیگر و جمعآوری داده از آنها
مناسب برای استخراج داده از چندین صفحه یک وبسایت
2- XPath
یک زبان پرسوجوی قدرتمند
برای پیمایش عناصر موجود در یک سند HTML استفاده میشود
معمولاً همراه با تجزیه HTML برای انتخاب عناصر خاص بهکار میرود
3- Regular Expressions
جستجو و استخراج الگوهای خاص متنی از یک صفحه وب
مناسب برای دادههایی با قالب مشخص مانند تاریخها، شماره تلفنها یا ایمیلها
4- HTML Parsing
تحلیل ساختار HTML یک صفحه وب
شناسایی تگها و عناصری که داده موردنظر را در خود دارند
اغلب برای وظایف ساده استخراج داده استفاده میشود
5- XMl API
XML (زبان نشانهگذاری توسعهپذیر) برای تبادل داده استفاده میشود
عملکردی مشابه HTML API دارد؛ با ارسال درخواست HTTP به نقاط پایانی API و سپس تجزیه دادههای دریافتی در قالب XML
6- JSON API
JSON (قالب تبادل داده جاوااسکریپت) یک قالب سبک برای تبادل داده بین سرورها و برنامههای وب است
بسیاری از وبسایتها APIهای خود را در قالب JSON ارائه میدهند که آن را به روشی کارآمد برای دریافت داده تبدیل میکند
جمعآوری دادههای شبکههای اجتماعی
جمعآوری داده از شبکههای اجتماعی میتواند از طریق روشهای مختلفی مانند یکپارچهسازی API، شنود اجتماعی (Social Listening)، نظرسنجیهای شبکههای اجتماعی، تحلیل شبکه، و تحلیل تصویر و ویدئو انجام شود.
APIهایی که توسط پلتفرمهای شبکههای اجتماعی ارائه میشوند، به دانشمندان داده اجازه میدهند دادههای ساختاریافته درباره تعاملات کاربران و محتوا را جمعآوری کنند.شنود اجتماعی شامل پایش گفتوگوهای آنلاین برای بهدست آوردن بینش درباره رفتار مشتریان و روندها است.
نظرسنجیهایی که در شبکههای اجتماعی انجام میشوند میتوانند اطلاعاتی درباره ترجیحات و دیدگاههای مشتریان ارائه دهند.تحلیل شبکه، که به بررسی روابط و ارتباطات بین کاربران، دادهها یا موجودیتها در یک شبکه میپردازد، میتواند کاربران و جوامع تأثیرگذار را شناسایی کند. این روش شامل شناسایی و تحلیل افراد یا گروههای اثرگذار و همچنین درک الگوها و روندهای موجود در شبکه است.تحلیل تصویر و ویدئو نیز میتواند بینشهایی درباره روندهای بصری و رفتار کاربران ارائه دهد.
مثال
یک نمونه از جمعآوری دادههای شبکههای اجتماعی، اجرای یک نظرسنجی در توییتر درباره میزان رضایت مشتریان برای یک شرکت تحویل غذا است. دانشمندان داده میتوانند با استفاده از API توییتر، توییتهایی را که شامل هشتگهای مرتبط با شرکت هستند جمعآوری کرده و آنها را تحلیل کنند تا دیدگاهها و ترجیحات مشتریان را درک کنند.همچنین میتوانند از شنود اجتماعی برای پایش مکالمات و شناسایی روندهای رفتاری مشتریان استفاده کنند.علاوه بر این، ایجاد یک نظرسنجی در توییتر میتواند بینشهای هدفمندتری درباره رضایت و ترجیحات مشتریان فراهم کند. در نهایت، این دادهها با استفاده از تکنیکهای علم داده تحلیل میشوند تا حوزههای کلیدی برای بهبود شناسایی شده و تصمیمگیریهای آگاهانه در کسبوکار انجام شود.
استفاده از پایتون برای استخراج داده از وب
همانطور که پیشتر اشاره شد، خزش وب روشی برای جمعآوری داده از اینترنت با استفاده از مکانیزمها یا برنامههای خودکار است.
پایتون یکی از زبانهای برنامهنویسی محبوب برای خزش وب محسوب میشود، زیرا کتابخانهها و فریمورکهای متعددی دارد که استخراج و پردازش داده از وبسایتها را آسان میکنند.
برای استخراج دادهای مانند یک جدول از یک وبسایت با استفاده از پایتون، مراحل زیر را دنبال میکنیم:
1- وارد کردن کتابخانه pandas
اولین قدم، وارد کردن کتابخانه pandas است که یکی از محبوبترین کتابخانههای پایتون برای تحلیل و دستکاری دادههاست.
import pandas as pd
- استفاده از تابع read_html()
این تابع برای خواندن جداول HTML از یک صفحه وب و تبدیل آنها به لیستی از اشیای DataFrame استفاده میشود.
همانطور که قبلاً گفته شد، DataFrame نوعی ساختار داده در pandas است که برای ذخیره دادههای جدولی چندستونه استفاده میشود.
df = pd.read_html("https://......")
3- دسترسی به داده موردنظر
اگر دادههای صفحه وب در چند جدول مختلف قرار داشته باشند، باید مشخص کنیم کدام جدول را میخواهیم استخراج کنیم.
برای این کار از اندیسگذاری استفاده میکنیم (مثلاً اندیس 4) تا به جدول موردنظر از لیست DataFrameهای بازگشتی دسترسی پیدا کنیم.
اندیس در اینجا نشاندهنده ترتیب جدول در صفحه وب است.
4- ذخیره داده در یک DataFrame
خروجی تابع read_html() یک لیست از DataFrameهاست که هرکدام نماینده یک جدول در صفحه وب هستند.
میتوانیم جدول موردنظر را در یک متغیر DataFrame ذخیره کنیم تا برای تحلیل و پردازشهای بعدی استفاده شود.
5- نمایش DataFrame
با فراخوانی متغیر DataFrame، میتوانیم داده استخراجشده را در قالب جدولی مشاهده کنیم.
6- تبدیل رشتهها به اعداد
همانطور که در مطلب اول اشاره شد، رشته (String) نوع دادهای است که دنبالهای از کاراکترها را نشان میدهد و داخل کوتیشن تکی (') یا دوتایی (") قرار میگیرد.
اگر دادههای جدول به صورت رشته باشند و بخواهیم عملیات عددی روی آنها انجام دهیم، باید آنها را به فرمت عددی تبدیل کنیم.
برای این کار از تابع to_numeric() در pandas استفاده میکنیم و نتیجه را در یک ستون جدید ذخیره میکنیم:
df['column_name'] = pd.to_numeric(df['column_name'])
این کار یک ستون جدید با مقادیر عددی تبدیلشده ایجاد میکند که میتوان از آن برای تحلیل یا مصورسازی استفاده کرد.
نکته مهم درباره اندیسگذاری
در برنامهنویسی، اندیسگذاری معمولاً از عدد 0 شروع میشود.
زیرا بیشتر زبانهای برنامهنویسی، مقدار 0 را به عنوان اندیس اولیه برای آرایهها، ماتریسها و سایر ساختارهای داده در نظر میگیرند.
این قرارداد باعث سادهتر شدن پیادهسازی برخی الگوریتمها و همچنین هماهنگی با نحوه ذخیرهسازی داده در حافظه کامپیوتر میشود.
در زمینه استخراج جداول از صفحات HTML نیز شروع اندیس از 0 به برنامهنویسان اجازه میدهد بهراحتی به جداول مختلف یک صفحه دسترسی پیدا کرده و آنها را پردازش کنند. این موضوع باعث کارآمدتر شدن پردازش و تحلیل داده میشود.
مسئله :
جدول دادهای با عنوان Table of States را از وبسایت به آدرس زیر استخراج کنید:
https://www.geograf.in/en/table.php
داده های این وب سایت شامل جدولی از نام تمامی کشورهای دنیا است، مانند تصویر زیر :

با استفاده از پایتون و کتابخانه pandas داده های این جدول را جمع آوری کنید :
import pandas as pd df_list = pd.read_html("https://www.geograf.in/en/table.php") df_list[1]
خروجی این کد به مانند تصویر زیرشامل جدولی از نام کشورها خواهد بود :
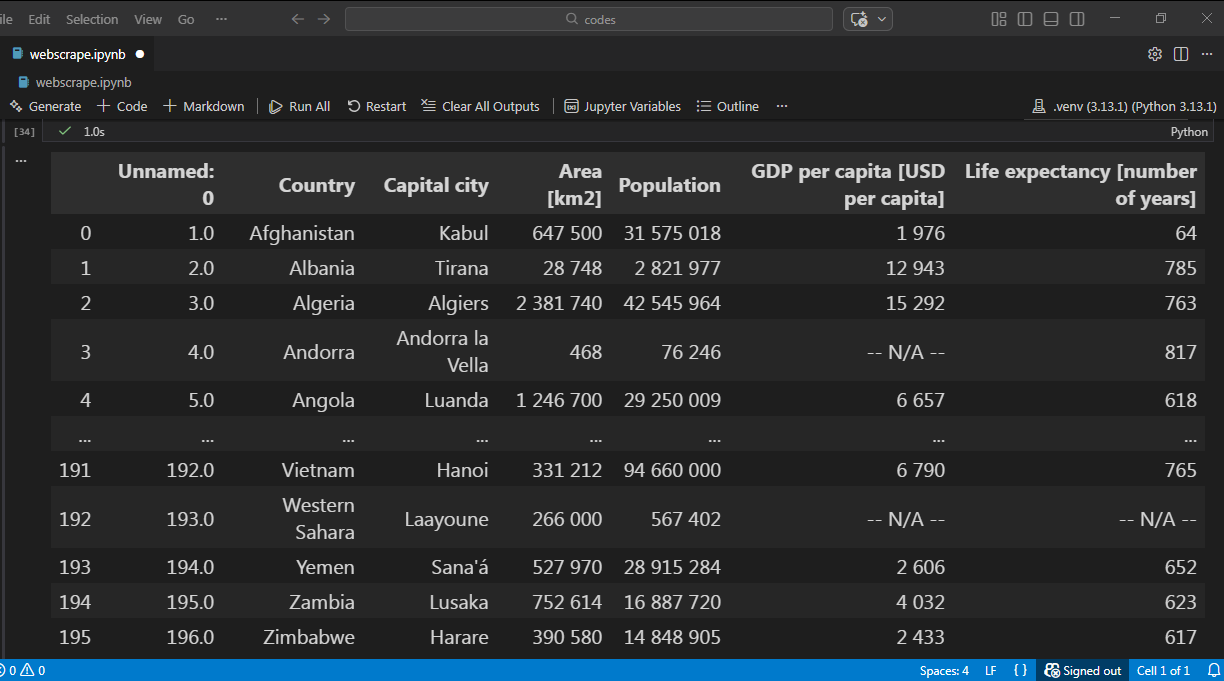
برای اینکه نام کشور عزیزمان ایران را از دیتافریم کشورها فیلتر کنیم دستور زیر خواهیم داشت:
df.loc[df["Country"] == "Iran"]
خروجی به مانند تصویر زیر خواهد بود :
