یکی از مهمترین مراحل هر پروژه علم داده، مرحلهای است که معمولاً کمتر دیده میشود: پاکسازی و پیشپردازش دادهها. این فرآیند به ما کمک میکند دادههای خام، پراکنده و گاهی ناسازگار را به ساختاری منظم، دقیق و قابل تحلیل تبدیل کنیم.
در این مطلب، انتظار میرود بتوانیم:
روشهای مدیریت دادههای گمشده (Missing Data) و دادههای پرت (Outliers) را بهکار ببریم
و در مطلب بعد :
تکنیکهای استانداردسازی مانند نرمالسازی (Normalization)، تبدیل (Transformation) و تجمیع (Aggregation) را توضیح دهیم
منابع ایجاد نویز در دادهها را شناسایی کرده و با روشهای مناسب آن را کاهش دهیم
چرا پیشپردازش (Preprocessing) اینقدر مهم است؟
دادههای خام معمولاً ناقص هستند، شامل مقادیر تکراری یا اشتباهاند، قالب یکدست ندارند و یا حتی بخشی از آنها برای تحلیل بیربط است. اگر این مشکلات اصلاح نشوند، خروجی مدلها دچار سوگیری و خطا خواهد شد. بنابراین هدف اصلی پیشپردازش این است که دادهها دقیق، سازگار و آماده تحلیل شوند.
مراحل اصلی پاکسازی (Data Cleaning) و پیشپردازش
فرآیند پیشپردازش معمولاً شامل چند گام کلیدی است:
1. یکپارچهسازی دادهها (Data Integration)
در این مرحله دادهها از منابع مختلف جمعآوری و در یک مجموعهداده واحد ادغام میشوند. این کار از ناسازگاری بین منابع مختلف جلوگیری میکند.
2. پاکسازی دادهها (Data Cleaning)
در این مرحله دادهها از نظر خطا و ناسازگاری بررسی میشوند. اقدامات رایج شامل حذف مقادیر تکراری، مدیریت دادههای گمشده و اصلاح خطاهای قالببندی انجام می شوند.
3. تبدیل دادهها (Data Transformation)
برای آمادهسازی داده جهت تحلیل، معمولاً لازم است ما نوع دادهها را تغییر دهیم ، دادههای عددی نرمالسازی یا مقیاسبندی شوند و متغیرهای دستهای کدگذاری شوند.
4. کاهش دادهها (Data Reduction)
زمانی که تعداد ویژگیها زیاد است، از تکنیکهای انتخاب ویژگی استفاده میشود تا فقط متغیرهای مهم حفظ شوند.
5. گسستهسازی (Data Discretization)
در این مرحله دادههای پیوسته به بازهها یا دستهها تقسیم میشوند تا تحلیل سادهتر شود.
6. نمونهگیری (Data Sampling)
اگر حجم داده بسیار زیاد باشد، میتوان نمونهای نماینده از کل داده انتخاب کرد تا تحلیل سریعتر و مقرونبهصرفهتر انجام شود.
مدیریت دادههای گمشده و دادههای پرت
دو چالش رایج در پروژههای داده، Missing Data و Outliers هستند.
دادههای گمشده (Missing Data)
دادههای گمشده ممکن است به دلایل خطا در جمعآوری داده، خرابی تجهیزات و عدم پاسخدهی افراد در نظرسنجی ایجاد شوند. این موضوع میتواند باعث کاهش اندازه نمونه و ایجاد سوگیری شود.
از نظر آماری، دادههای گمشده به سه دسته تقسیم میشوند:
· کاملاً تصادفی و بدون ارتباط با سایر متغیرها(MCAR)
· مرتبط با متغیرهای مشاهدهشده (MAR)
· مرتبط با خود مقدار مشاهدهنشده (MNAR)
تشخیص درست این نوعها، در انتخاب روش مدیریت بسیار تعیینکننده است.
دادههای پرت (Outliers)
داده پرت مقداری است که بهطور قابل توجهی با سایر دادهها تفاوت دارد. این اختلاف میتواند ناشی از خطای انسانی، خطای اندازهگیری و یا یک مقدار واقعی اما غیرعادی باشد. اگر بدون بررسی حذف شوند، ممکن است اطلاعات مهمی از بین برود؛ و اگر نادیده گرفته شوند، ممکن است تحلیل را منحرف کنند.
چگونه دادههای پرت و گمشده را شناسایی کنیم؟
برای شناسایی آنها میتوان از دو رویکرد استفاده کرد:
روشهای بصری مانند :
· نمودار پراکندگی (Scatterplot)
· نمودار جعبهای (Box Plot)
· هیستوگرام
· بازه بین چارکی (IQR)
روشهای آماری مانند :
· میانگین
· میانه
· انحراف معیار
تصمیمگیری درباره نحوه مدیریت
پس از شناسایی، باید تصمیم بگیریم چگونه با این دادهها برخورد کنیم.
برای دادههای گمشده باید رکوردهای ناقص را حذف کنیم ، مقادیر (Imputation)را جایگزین کنیم و از مدلهای پیشبینی استفاده کنیم.
برای دادههای پرت می تواین داده ها را در صورت خطای قطعی حذف کنیم ، تحلیل جداگانه ای انجام دهیم و از روشهای آماری مقاوم مانند استفاده از میانه بهجای میانگین استفاده کنیم.
یک مثال واقعی از دنیای داده
از سال 1939، United States Bureau of Labor Statistics وضعیت اشتغال را بهصورت ماهانه پایش کرده است. فرض کنید دادههای اشتغال حوزه ساختوساز بین سالهای 1939 تا 2019 را تحلیل میکنیم و ناگهان در سال 1990 یک جهش غیرعادی مشاهده میشود؛ عددی که از حدود 5,400 به بیش از 9,500 افزایش یافته است.
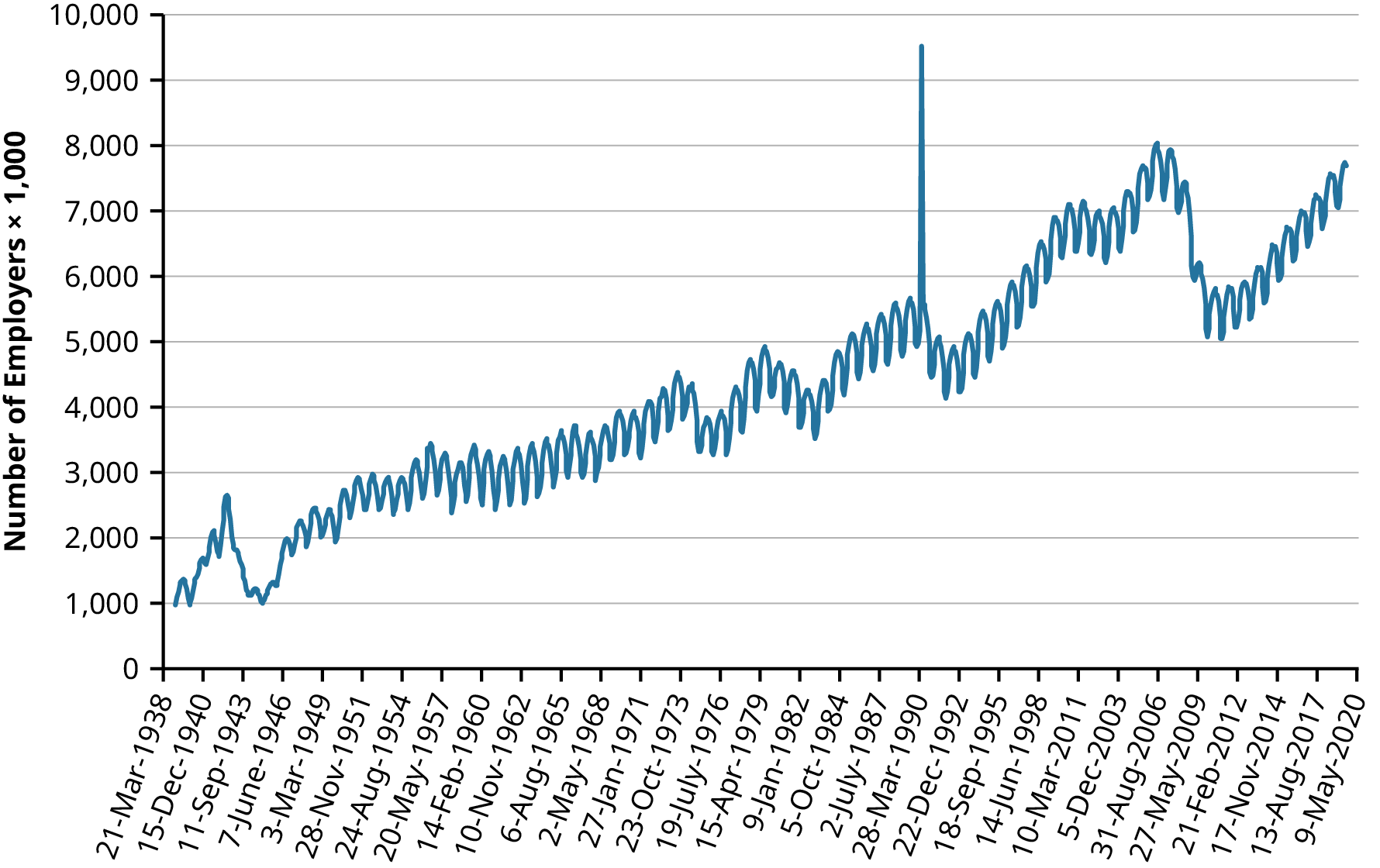
این سؤال مطرح میشود:
· آیا این مقدار یک داده پرت است؟
· اگر خطای ثبت داده باشد، چه باید کرد؟
در این مثال، یک راهکار جایگزینی مقدار پرت با میانه مقادیر اطراف آن است. محاسبات نشان میدهد مقدار 5,289 میتواند بهعنوان مقدار اصلاحی استفاده شود. این کار باعث:
· هموار شدن روند نمودار
· افزایش واقعگرایی دادهها
· کاهش اثر منفی بر تحلیل آماری
میشود.
