در علم داده، همیشه نیاز داریم تا یک نمای کلی و سریع از دادههایمان به دست آوریم. میانگین و میانه از مهمترین معیارهای مرکز هستند که به ما درک درستی از توزیع داده میدهند. در این مطلب یاد میگیرید چگونه با استفاده از کتابخانه Pandas در پایتون، این معیارها را محاسبه کنید.
گام ۱: نصب و وارد کردن کتابخانه مورد نیاز
ابتدا مطمئن شوید Pandas روی سیستم شما نصب است. در صورت نداشتن، از دستور زیر استفاده کنید:
pip install pandas
سپس در محیط کدنویسی خود، پانداس را وارد کنید:
import pandas as pd
گام ۲: بارگذاری مجموعه داده
در این مثال از مجموعه داده (movie_profit.csv) استفاده میکنیم. فرض کنید فایل CSV در مسیر فعلی شما قرار دارد:
df = pd.read_csv('movieprofit.csv')
برای مشاهده چند سطر اول داده:
df.head()
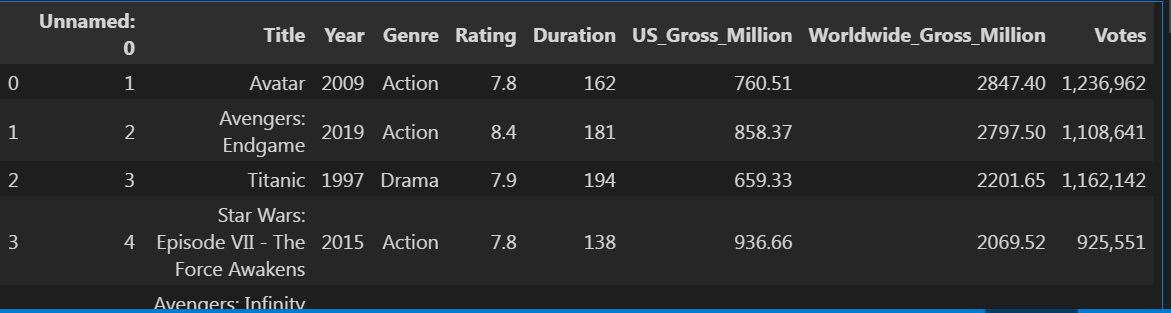
گام ۳: استفاده از متد describe
متد describe خلاصهای آماری از دادههای عددی شامل میانگین، میانه (چارک ۵۰٪)، انحراف معیار و ... ارائه میدهد:
df.describe()
خروجی شامل جدولی مانند زیر است:

گام ۴: تفسیر خروجی برای ستون درآمد ناخالص
میانگین : mean
میانه : 50%
انحراف معیار: std
کمترین مقدار : min
بیشترین مقدار : max
ستون worldwide_gross_million درآمد ناخالص جهانی فیلمها را نشان میدهد:
میانگین: حدود ۴۱۰.۱۴ میلیون دلار، میانگین کل درآمدها
میانه: حدود ۳۰۹.۳۵ میلیون دلار ، نقطه وسط دادهها
نکته: اگر میانگین بزرگتر از میانه باشد، یعنی دادهها به سمت راست چولگی (Skewness) دارند و تعدادی فیلم با درآمد خیلی بالا وجود دارد.
گام ۵: محاسبه جداگانه میانگین و میانه
اگر فقط بخواهید میانگین یا میانه یک ستون خاص را مشاهده کنید:
میانگین ستون worldwide_gross_million
df['worldwide_gross_million'].mean()
میانه ستون worldwide_gross_million
df['worldwide_gross_million'].median()
نکته مهم: ستونهای بیربط
گاهی در دادهها ستونهایی مثل Unnamed: 0 وجود دارند که صرفاً نقش شناسه دارند. محاسبه میانگین و میانه برای چنین ستونهایی بیمعناست، اما متد describe به هر حال آنها را محاسبه میکند. بنابراین همیشه قبل از تحلیل، ستونهای مناسب را انتخاب کنید:
حذف ستونهای بیربط
df.drop(columns=['Unnamed: 0'])