
اگر حتی یک بار سراغ ساختن یک pipeline برای استریم ویدیو رفته باشید، احتمالاً کار را با یک تصور ساده شروع کردهاید:
یک worker بالا میآورم، ویدیو را دانلود میکنم و با یک subprocess ساده، FFmpeg را اجرا میکنم.
روی سیستم local همهچیز خوب کار میکند. بعد پروژه وارد production میشود. یک کاربر ویدیوی ۲ ساعته 4K آپلود میکند. دیسک NVMe پر میشود. worker در ۹۹ درصد پردازش crash میکند. وضعیت دیتابیس هم با واقعیت sync نیست.
Transcoding ویدیو یکی از سنگینترین و غیرقابلپیشبینیترین workloadهایی است که روی زیرساخت cloud اجرا میشود. اگر پردازش ویدیو را مثل یک اسکریپت monolithic ببینید، در عمل سرویس نمیسازید. یک بمب ساعتی میسازید.
اینجا هدف این است که pipeline را طوری طراحی کنیم که input را درست stream کند، خروجی HLS یا DASH قابل اعتماد بسازد، ظرفیت NVENC را دقیق مدیریت کند، state را در دیتابیس نگه دارد و قبل از publish شدن خروجی، کیفیت را واقعاً verify کند.
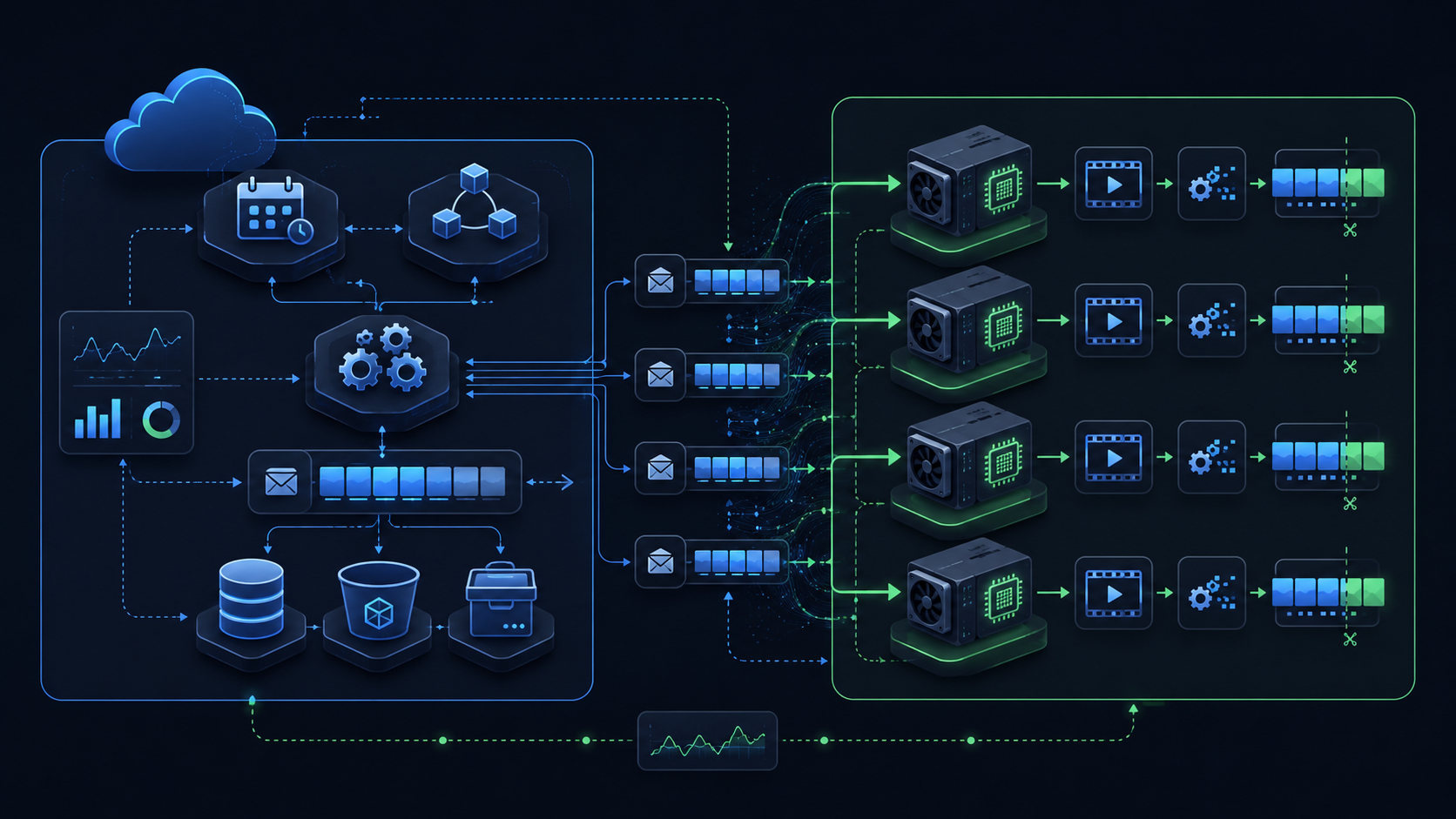
برای ساختن سیستمی که scale شود، باید Control Plane را از Data Plane جدا کنید.
Control Plane مسئول تصمیمگیری و هماهنگی است. با byteهای ویدیو کاری ندارد.
این بخش API requestها، برنامهریزی jobها، وضعیت دیتابیس، heartbeat workerها، retryها و ظرفیت encoderها را مدیریت میکند. Go برای این بخش انتخاب خوبی است، چون concurrency سبک و efficient دارد و برای مدیریت هزاران event هماهنگی مناسب است.
Data Plane جایی است که کار سنگین انجام میشود.
این بخش source ویدیو را stream میکند، با hardware acceleration کار میکند، فضای scratch دیسک را مدیریت میکند و ابزارهایی مثل FFmpeg و ffprobe را اجرا میکند.
Python برای این لایه انتخاب عملی و سریع است. کار با CLI toolها، parse کردن JSON خروجی ffprobe و ساختن ابزارهای عملیاتی در Python سادهتر و سریعتر جلو میرود.
اشتباه رایج این است که کل پردازش را فقط به یک subprocess کور بسپاریم و هیچ checkpoint معتبری در دیتابیس نداشته باشیم.
فرض کنید یک ویدیوی ۶۰ دقیقهای روی یک worker پردازش میشود. اگر Kubernetes در دقیقه ۵۸ آن pod را evict کند، سیستم باید دقیقاً بداند job در چه stateای بوده، روی چه workerای اجرا میشده و آیا باید retry شود یا failed بماند.
راهحل اصلی اینجا stateful orchestration است، نه الزاماً خرد کردن transcoding به jobهای کوچک.
قبل از اجرا، metadata ویدیو با ffprobe خوانده میشود. Job Planner بر اساس پروفایلهای موردنیاز، یک job قابل retry میسازد. Worker هنگام شروع job، دیتابیس را update میکند، heartbeat میفرستد و خروجی را فقط وقتی ready اعلام میکند که upload و QC کامل شده باشد.
اگر worker بمیرد، Control Plane از روی heartbeat و status دیتابیس تصمیم میگیرد job را retry کند. این مدل ساده، قابل فهم و برای بسیاری از pipelineهای production عملی است.
اشتباه رایج بعدی این است که worker اول فایل خام ۵۰ گیگابایتی را کامل دانلود کند و بعد FFmpeg را اجرا کند.
این کار دو مشکل میسازد. اول، workerها مدام روی disk I/O bottleneck میشوند. دوم، مجبور میشوید برای هر worker دیسک local بزرگ و گران provision کنید.
راهحل: Input Network Streaming
دانلود اولیه را حذف کنید.
FFmpeg میتواند فایل source را مستقیم از روی presigned S3 URL با HTTP stream بخواند. روش دیگر، استفاده از UNIX pipe است.
در این مدل، local storage فقط نقش scratch space موقت را دارد. worker خروجیهای موقت و فایلهای لازم برای packaging را کوتاهمدت روی NVMe مینویسد و بلافاصله خروجی encode شده را دوباره به S3 میفرستد.
دیسک local نباید محل نگهداری فایل اصلی باشد. باید فقط یک بافر سریع و موقت باشد.
خیلیها برای کنترل فشار روی workerها فقط به prefetch queue تکیه میکنند. مثلاً در RabbitMQ مقدار basic.qos را کم میکنند.
مشکل اینجاست که queue تعداد messageها را میفهمد، نه ظرفیت واقعی encoder سختافزاری را.
در NVIDIA، همیشه GPU usage معیار درستی نیست. ممکن است CUDA coreها فقط ۲۰ درصد درگیر باشند، ولی encoder سختافزاری یعنی NVENC به سقف sessionهای قابل استفاده رسیده باشد.
پس بهتر است ظرفیت worker را بر اساس NVENC sessionهای آزاد مدل کنیم. وقتی jobها از h264_nvenc یا hevc_nvenc استفاده میکنند، contention اصلی تعداد sessionهای همزمان NVENC است.
Control Plane قبل از dispatch کردن job، یک session lease برای worker میگیرد. وقتی job تمام شد یا worker heartbeat خود را از دست داد، lease آزاد میشود.
{ "worker_id": "gpu-worker-us-east-12", "gpu_model": "NVIDIA L4", "max_nvenc_sessions": 14, "active_nvenc_sessions": 9, "supported_encoders": ["h264_nvenc", "hevc_nvenc"] }
اگر هر job یک NVENC session مصرف میکند، scheduler فقط بررسی میکند آیا session آزاد وجود دارد یا نه.
البته resolution هنوز برای زمان اجرا، bitrate، VRAM و هزینه مهم است؛ اما برای قفل کردن ظرفیت encoder، معیار اصلی session است. این تفاوت کوچک در production جلوی مدلسازی اشتباه و over-engineering را میگیرد.
دیتابیس relational باید single source of truth کل pipeline باشد.
اگر چیزی در دیتابیس ثبت نشده، از نگاه سیستم اتفاق نیفتاده است.
CREATE TYPE video_status AS ENUM ('uploaded', 'probing', 'processing', 'ready', 'failed'); CREATE TYPE job_status AS ENUM ('queued', 'running', 'succeeded', 'failed'); CREATE TYPE package_format AS ENUM ('hls', 'dash'); CREATE TABLE videos ( id UUID PRIMARY KEY DEFAULT gen_random_uuid(), source_s3_path VARCHAR(512) NOT NULL, duration_seconds NUMERIC(10, 2), input_resolution VARCHAR(20), current_status video_status NOT NULL DEFAULT 'uploaded', created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP ); CREATE TABLE transcode_jobs ( id UUID PRIMARY KEY DEFAULT gen_random_uuid(), video_id UUID NOT NULL REFERENCES videos(id) ON DELETE CASCADE, task_type VARCHAR(50) NOT NULL, package_format package_format NOT NULL DEFAULT 'hls', encoder_backend VARCHAR(50) NOT NULL DEFAULT 'h264_nvenc', required_nvenc_sessions INT NOT NULL DEFAULT 1, status job_status NOT NULL DEFAULT 'queued', retry_attempts INT NOT NULL DEFAULT 0, max_retries INT NOT NULL DEFAULT 3, worker_id VARCHAR(100), error_log TEXT, started_at TIMESTAMP WITH TIME ZONE, finished_at TIMESTAMP WITH TIME ZONE ); CREATE INDEX idx_jobs_status ON transcode_jobs(status, package_format, encoder_backend);
این مدل چند مزیت مهم دارد.
اول، هر ویدیو status مشخص دارد. دوم، هر job قابل retry است. سوم، worker فعلی و خطاها ثبت میشوند. چهارم، scheduler میتواند jobهای منتظر را سریع پیدا کند و قبل از dispatch ظرفیت encoder را lease کند.
در workloadهای رسانهای، failure یک اتفاق نادر نیست. بخشی از رفتار طبیعی سیستم است. طراحی دیتابیس باید از ابتدا این واقعیت را بپذیرد.
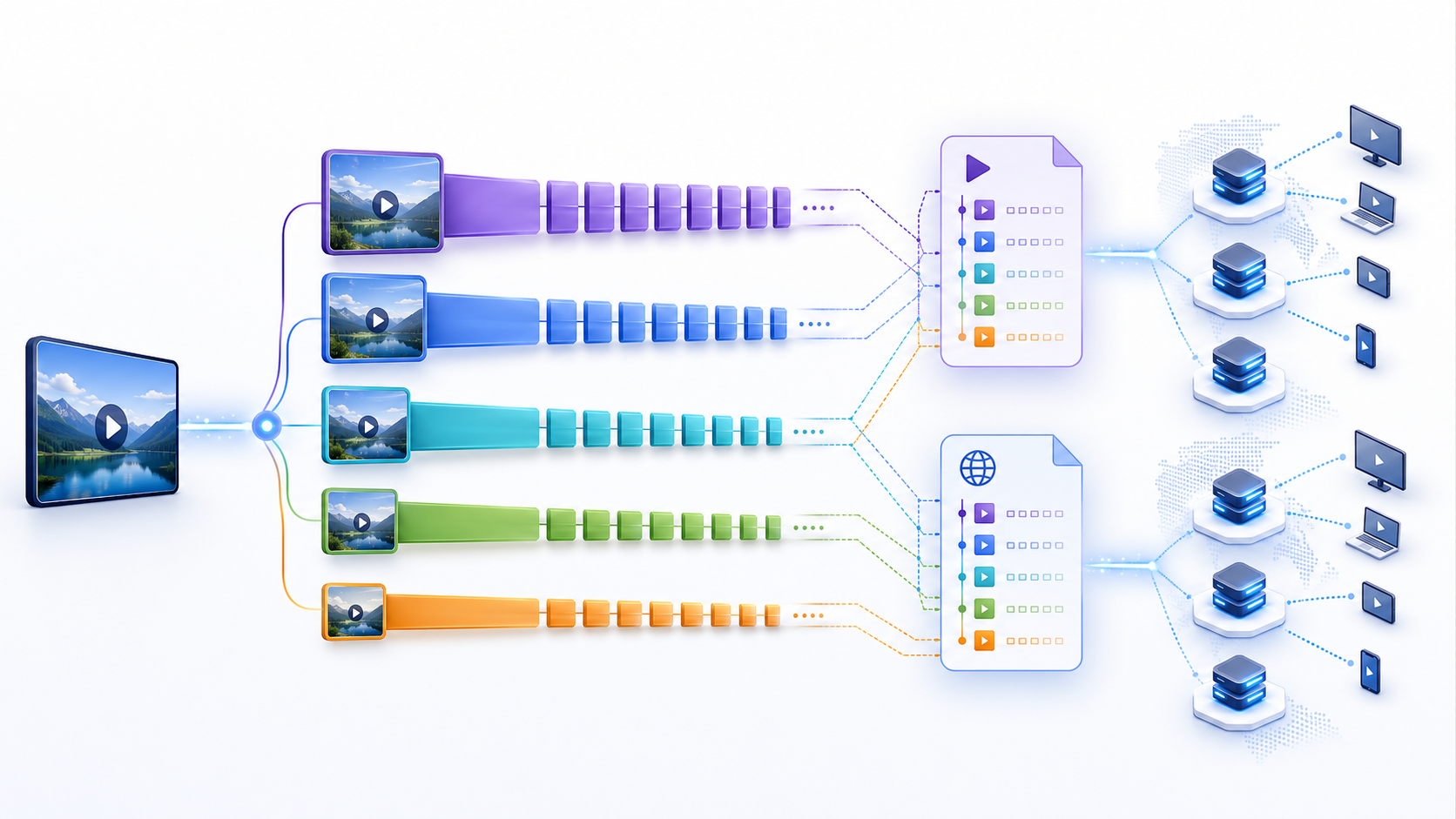
در یک video platform، خروجی نهایی معمولاً یک فایل MP4 ساده نیست. برای playback در scale، خروجی باید به شکل adaptive bitrate یا ABR ساخته شود.
یعنی بهجای یک کیفیت ثابت، چند rendition میسازید: مثلاً 1080p، 720p، 480p و 360p. Player بر اساس سرعت اینترنت، device و buffer کاربر بین این renditionها جابهجا میشود.
HLS و DASH هر دو همین ایده را اجرا میکنند:
HLS با playlistهای m3u8 و segmentها کار میکند.
DASH با manifest فایل mpd و segmentهای fMP4 کار میکند.
Codec هنوز مهم است، اما لایه delivery چیز دیگری است. ممکن است داخل HLS یا DASH از H.264 یا H.265 استفاده کنید، اما معماری scale بیشتر در packaging، manifest، segmentها، object storage، CDN و player behavior خودش را نشان میدهد.
برای بیشتر محصولها، یک ladder ساده بهتر از یک طراحی بیش از حد پیچیده است.
1080p، 720p، 480p و 360p برای شروع کافی است.
اگر source خودش 720p است، خروجی 1080p نسازید.
اگر bitrate ورودی پایین است، با encode دوباره معجزه کیفیت نمیسازید؛ فقط artifact را تثبیت میکنید.
segment duration را ثابت نگه دارید؛ ۴ تا ۶ ثانیه معمولاً انتخاب عملی است.
GOP و keyframe interval باید با segment boundary هماهنگ باشد.
manifest را فقط بعد از آماده شدن segmentهای معتبر publish کنید.
این سیاست ساده باعث میشود تیم به جای بازی با codecها، روی reliability pipeline تمرکز کند.
این pipeline decode را به GPU میسپارد، frame buffer را در VRAM split میکند، scale را داخل memory سختافزار انجام میدهد و چند کیفیت را همزمان encode میکند.
هدف، کم کردن I/O و ساختن یک master playlist برای playback adaptive است.
ffmpeg -y -hwaccel cuda -hwaccel_output_format cuda -i input.mp4 \ -filter_complex "\ [0:v]split=4[v1][v2][v3][v4]; \ [v1]scale_cuda=1920:1080[v1080]; \ [v2]scale_cuda=1280:720[v720]; \ [v3]scale_cuda=854:480[v480]; \ [v4]scale_cuda=640:360[v360]" \ -map "[v1080]" -c:v:0 h264_nvenc -preset p4 -b:v:0 6000k -maxrate:v:0 6500k -bufsize:v:0 12000k \ -map "[v720]" -c:v:1 h264_nvenc -preset p4 -b:v:1 3000k -maxrate:v:1 3300k -bufsize:v:1 6000k \ -map "[v480]" -c:v:2 h264_nvenc -preset p4 -b:v:2 1200k -maxrate:v:2 1350k -bufsize:v:2 2400k \ -map "[v360]" -c:v:3 h264_nvenc -preset p4 -b:v:3 700k -maxrate:v:3 800k -bufsize:v:3 1400k \ -map 0:a -c:a aac -b:a 128k \ -g 180 -keyint_min 180 -sc_threshold 0 \ -f hls -hls_time 6 -hls_playlist_type vod \ -master_pl_name master.m3u8 \ -hls_segment_filename "stream_%v/data_%03d.ts" stream_%v/playlist.m3u8
نکته مهم: فایلهای HLS اینجا خروجی packaging هستند و worker همچنان job اصلی را به شکل یک جریان کنترلشده اجرا میکند.
DASH هم همان ایده adaptive playback را دارد، اما خروجی اصلی آن manifest با پسوند mpd است. در بسیاری از stackها، segmentهای fMP4 برای DASH انتخاب تمیزتری هستند.
ffmpeg -y -hwaccel cuda -hwaccel_output_format cuda -i input.mp4 \ -filter_complex "\ [0:v]split=3[v1][v2][v3]; \ [v1]scale_cuda=1920:1080[v1080]; \ [v2]scale_cuda=1280:720[v720]; \ [v3]scale_cuda=854:480[v480]" \ -map "[v1080]" -c:v:0 h264_nvenc -preset p4 -b:v:0 6000k -maxrate:v:0 6500k -bufsize:v:0 12000k \ -map "[v720]" -c:v:1 h264_nvenc -preset p4 -b:v:1 3000k -maxrate:v:1 3300k -bufsize:v:1 6000k \ -map "[v480]" -c:v:2 h264_nvenc -preset p4 -b:v:2 1200k -maxrate:v:2 1350k -bufsize:v:2 2400k \ -map 0:a -c:a aac -b:a 128k \ -g 180 -keyint_min 180 -sc_threshold 0 \ -f dash -seg_duration 6 \ -adaptation_sets "id=0,streams=v id=1,streams=a" \ manifest.mpd
نکته مهم این است که HLS و DASH فقط فرمت خروجی نیستند؛ قرارداد playback با player هستند. segment duration، keyframe alignment، MIME typeها، CDN cache behavior و manifest correctness روی تجربه کاربر اثر مستقیم دارند.

فایل کاربر ممکن است metadata غلط داشته باشد، duration اشتباه گزارش کند، audio track ناقص داشته باشد، rotation tag داشته باشد، variable frame rate باشد یا وسط فایل corruption داشته باشد.
قبل از transcoding، با ffprobe حداقل این موارد را بخوانید:
duration واقعی
codec و resolution
frame rate
وجود یا نبود audio
rotation و display aspect ratio
bitrate تقریبی
اگر input ویدیو 854x480 است، ساختن 1080p فقط storage و compute را هدر میدهد. Job Planner باید ladder را بر اساس source بسازد، نه یک لیست ثابت.
در HLS و DASH، player باید بتواند از ابتدای هر segment decode را شروع کند. اگر segment وسط GOP شروع شود، بعضی playerها stutter، black frame یا seek مشکلدار نشان میدهند. برای همین -g و segment duration باید با هم طراحی شوند.
اگر master playlist یا MPD قبل از upload کامل segmentها روی S3/CDN visible شود، کاربر manifest سالم میبیند ولی segmentها 404 میدهند. خروجی را اول در prefix موقت بسازید، QC کنید، بعد pointer نهایی را در دیتابیس update کنید.
روی object storage و CDN، Content-Type مهم است:
application/vnd.apple.mpegurl برای m3u8
application/dash+xml برای mpd
video/mp2t برای ts
video/mp4 برای m4s یا fMP4
header اشتباه همیشه در تست local دیده نمیشود، ولی روی device واقعی یا browser خاص playback را خراب میکند.
خیلی از failureهای media از video نیستند. audio ممکن است چند stream داشته باشد، sample rate عجیب داشته باشد، یا از video کوتاهتر باشد. برای خروجی عمومی، AAC با bitrate ثابت و sample rate استاندارد انتخاب امنتری است.
FFmpeg ممکن است بدون crash تمام شود، ولی manifest ناقص، segment صفر بایتی، duration mismatch یا خروجی بدون video stream بسازد. status دیتابیس فقط بعد از QC باید ready شود.
برای HLS و DASH، QC فقط ffprobe روی یک فایل نیست. باید manifest را parse کنید، segmentها را بشمارید، existence آنها را چک کنید و حداقل چند segment را probe کنید.
Retry نباید خروجی قبلی را کورکورانه خراب کند. هر job باید output prefix موقت خودش را داشته باشد. بعد از موفقیت کامل، pointer نهایی در دیتابیس تغییر کند. این کار جلوی publish شدن خروجی نصفه را میگیرد.
اگر worker وسط encode بمیرد، NVENC session lease نباید برای همیشه قفل بماند. lease را با heartbeat تمدید کنید و اگر heartbeat قطع شد، آن را expire کنید.
Queue depth بهتنهایی کافی نیست. باید metrics واقعی مثل active sessions، job age، retry rate، average encode speed، scratch disk pressure و S3 upload latency را ببینید.
نباید فرض کنید چون FFmpeg با exit code صفر تمام شده، خروجی سالم است.
در پردازش فایلهای آپلودی کاربران، corruption خاموش زیاد رخ میدهد. فایل صفر بایتی، audio track حذفشده، frame stutter، اختلاف مدت audio و video و خروجیهای ناقص، همگی در production دیده میشوند.
قبل از اینکه status ویدیو را در دیتابیس ready کنید، خروجیها را با ffprobe اعتبارسنجی کنید.
import sys import json import subprocess def verify_media_integrity(file_path): cmd = [ "ffprobe", "-v", "quiet", "-print_format", "json", "-show_format", "-show_streams", file_path ] res = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True) if res.returncode != 0: return False, f"ffprobe execution failure: {res.stderr}" data = json.loads(res.stdout) streams = data.get("streams", []) has_video = any(s["codec_type"] == "video" for s in streams) if not has_video: return False, "Corrupt file: No video streams found." if int(data["format"]["size"]) == 0: return False, "Corrupt file: File size is 0 bytes." try: v_dur = next(float(s["duration"]) for s in streams if s["codec_type"] == "video") a_dur = next((float(s["duration"]) for s in streams if s["codec_type"] == "audio"), None) if a_dur and abs(v_dur - a_dur) > 0.5: return False, f"A/V sync drift out of bounds: {abs(v_dur - a_dur)}s" except KeyError: pass return True, "Passed" if __name__ == "__main__": is_valid, reason = verify_media_integrity("output.mp4") if not is_valid: print(f"QC Rejected: {reason}") sys.exit(1) sys.exit(0)
ساختن یک video platform فقط نوشتن چند wrapper دور FFmpeg نیست. مسئله اصلی، هماهنگی زیرساخت است.
باید از روز اول فرض کنید workerها میمیرند، فایلها خراباند، GPUها محدودیت واقعی دارند، queueها ظرفیت encoder را نمیفهمند و دیتابیس باید حقیقت نهایی سیستم باشد.
اگر input را stream کنید، workerها را stateful و قابل retry طراحی کنید، ظرفیت NVENC را با session lease مدیریت کنید، ladder را بر اساس source بسازید، HLS و DASH را با manifest و segment سالم publish کنید و قبل از ready کردن خروجی QC واقعی انجام دهید، pipeline شما از یک اسکریپت شکننده به یک سیستم قابل اعتماد و قابل scale تبدیل میشود.
Transcoding ویدیو جنگ با FFmpeg نیست. جنگ با resource، failure و cost است.