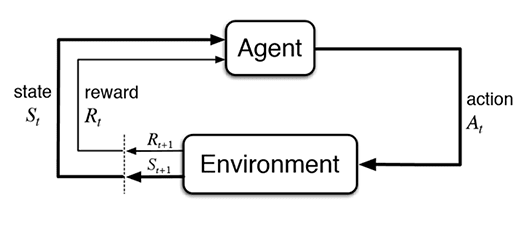
در این نوشته با ترتیب زیر به نحوهی آموزش یک عامل برای حل محیط تاکسی در OpenAI Gym میپردازیم.
در نظر بگیرید میخواهید به حیوان خانگیتان آموزش دهید تا هنگام شنیدن سوت بنشیند یا هنگامی که به او اشاره میکنید نزد شما بیاید.
با ادامه دادن این روند سگ شما با توجه به پاداشی که دریافت میکند یاد میگیرد تا با انجام حرکتهای که موجب دریافت پاداش میشود سود خود را بیشینه کند، در نتیجه حیوان شما آموزش میبیند تا به هنگام شنیدن سوت بنشیند. یادگیری تقویتی به عنوان زیرمجموعهای از یادگیری ماشین سعی میکند عامل را به نحوی آموزش دهد تا عامل بتواند مجموعه اقدامهایی که موجب بیشینه شدن پاداشش در محیط میشود را انتخاب کند.
تاکسی یک محیط از چندین محیط قابل دسترسی در OpenAI Gym میباشد. هدف تاکسی سوار کردن مسافر و پیاده کردن آن در مقصد با کمترین میزان حرکت میباشد. در این آموزش شما ابتدا با یک عامل که بهصورت تصادفی عمل میکنید آشنا میشوید و سپس یک عامل که توسط یادگیری تقویتی آموزش دیده شدهاست را مشاهده میکنید.
در ابتدا لازم است شما دو کتابخوانهی OpenAI Gym و NumPy را بهصورت زیر نصب کنید
OpenAI Gym pip install gym NumPy pip install numpy
قطعه کد زیر پکیجهای مورد نیاز را فراخوانی میکند و محیط تاکسی را ایجاد میکند.
import numpy as np import gym import random env = gym.make('Taxi-v3')
اجازه دهید ابتدا با پیادهسازی یک عامل که اصلا یاد نمیگیرد و اقداماتش را به صورت تصادفی انتخاب میکند شروع کنیم. در ابتدا نیاز است که به عامل خود حالت اولیه را تخصیص دهیم تا درک درستی از محیط داشته باشد. در مسئلهی تاکسی حالت اولیه نمایانگر این است که تاکسی، مسافر، مقصد و مبدا در کجا قرار دارند. شکل زیر سه حالت مختلف برای مسالهی تاکسی را نمایش میدهد.

برای دریافت حالت اولیه میتوان از کد زیر استفاده کرد:
state = env.reset()
در ادامه ما یک حلقه ایجاد میکنیم تا عاملمان در هر مرحله:
کد آن به صورت زیر میباشد
import gym import numpy as np import random # create Taxi environment env = gym.make('Taxi-v3') # create a new instance of taxi, and get the initial state state = env.reset() num_steps = 99 for s in range(num_steps+1): print(f"step: {s} out of {num_steps}") # sample a random action from the list of available actions action = env.action_space.sample() # perform this action on the environment env.step(action) # print the new state env.render() # end this instance of the taxi environment env.close()
اگر کد بالا را اجرا کنید میبینید که عامل شما به صورت تصادفی اقداماتی را انجام میدهد. البته این اقدامات نتایج مثبتی ندارد اما برای درک محیط تاکسی میتواند مفید باشد.
یادگیری Q یک الگوریتم یادگیری تقویتی است که بدنبال پیدا کردن اقدام احتمالی بعدی بر اساس حالت فعلی است تا بتواند پاداش را بیشینه کند. حالت زیر را تصور کنید.

به نظر شما تاکسی که به رنگ زرد میباشد چه اقدامی را انتخاب میکند ؟
بگذارید ابتدا به نحوهی پاداشدهی محیط تاکسی بپردازیم.
با توجه به سند OpenAI Gym برای محیط TAXI
…you receive +20 points for a successful drop-off, and lose 1 point for every timestep it takes. There is also a 10 point penalty for illegal pick-up and drop-off actions.
حال اگر به حالت بالا نگاه کنیم اقدامهای احتمالی و متناسبا پاداشهای دریافتی بهصورت زیر میباشد

عامل اگر چهار اقدام حرکتی را انجام دهد یک امتیاز از دست میدهد و همچنین اگر اقدام پیادهکردن و یا سوارکردن را انجام دهد ۱۰ امتیاز از دست میدهد. اما ما میخواهیم که عامل به سمت نقطهی آبی حرکت کند تا مسافر را سوار کند پس این سوال بوجود میآید که چطور باید عامل از بین چهار اقدام با پاداش مساوی -۱ انتخاب کند ؟
عامل ما در حال حاضر نمیداند چه اقدامی را انجام دهد و کدامین آنها باعث میشود تا به نقطهی آبی نزدیک گردد. اینجاست که مبحث صحیح و خطا مطرح میشود و عامل مجبور است تا اقدامات تصادفی انجام دهد تا مشاهده کند چه پاداشی دریافت میکند. بعد از تکرارهای زیاد، عامل متوجه میشود چه مجموعه اقدامهایی باعت دریافت بیشتر پاداش میشود. در طول مسیر عامل نیاز دارد تا سرنخی از مقادیر برای خود ذخیره کند.
جدول Q جدولی است که در خود مقادیر مورد انتظار پاداشهای آینده که عامل انتظار دارد با اقدامی مشخص دریافت کند را در خود ذخیره دارد که به آن اصطلاحا مقادیر-Q میگویند. در اصل این مقادیر به عامل ما میگوید که با روبرو شدن با یک حالت قطعی، برخی اقدامات محتملتر برای رسیدن به پاداش بیشتر میباشند. تصویر زیر نمایانگر این است که یک جدول Q به چه شکل میباشد.
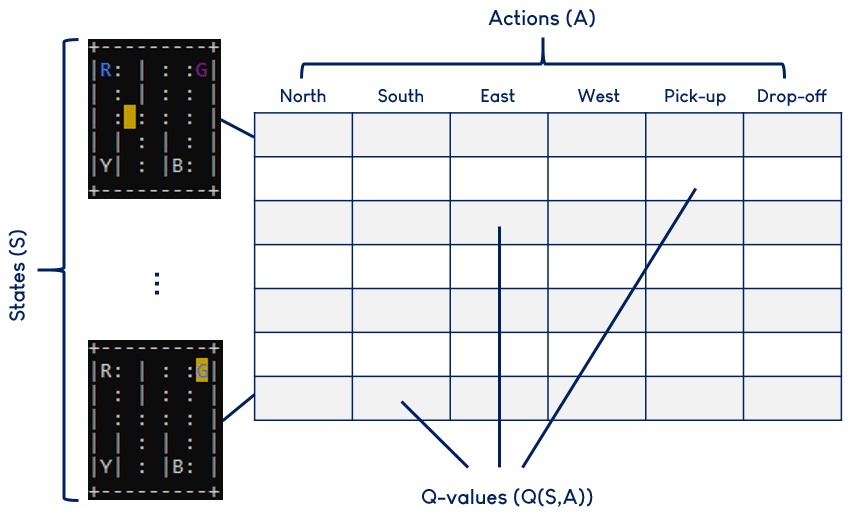
قبل از اینکه لازم باشد ما عامل خود را پیادهسازی کنیم، نیاز است تا جدول Q را بسازیم. کد زیر این امر را برای ما میسر میسازد.
state_size = env.observation_space.n # total number of states (S) action_size = env.action_space.n # total number of actions (A) # initialize a qtable with 0's for all Q-values qtable = np.zeros((state_size, action_size))
عامل ما در محیط جستجو میکند و جدول Q را با مقادیر Q که پیدا کردهاست بروزرسانی میکند. برای محاسبهی مقدار Q از الگوریتم یادگیری-Q استفاده میکنیم
الگوریتم یادگیری-Q در زیر آمده است، در این متن به جزییات آن نمیپردازیم اما شما میتوانید جزییات بیشتر را در کتاب ساتن و بارتو مشاهده کنید.

کد زیر مربوط به پیاده سازی این الگوریتم میباشد.
# hyperparameters to tune learning_rate = 0.9 discount_rate = 0.8 # dummy variables reward = 10 # R_(t+1) state = env.observation_space.sample() # S_t action = env.action_space.sample() # A_t new_state = env.observation_space.sample() # S_(t+1) # Qlearning algorithm: Q(s,a) := Q(s,a) + learning_rate * (reward + #discount_rate * max Q(s',a') - Q(s,a)) qtable[state, action] += learning_rate * (reward + discount_rate * / np.max(qtable[new_state,:]) - qtable[state,action])
تا اکنون ما اجازه دادیم تا عامل در محیط به جستجو بپردازد، همینکه بعد از تعداد زیادی تکرار عامل نسبت به محیط آگاهی مناسبی پیدا کرد حال به اجازه میدهیم تا عملیات بهره برداری از محیط را آغاز کند. در طول مراحل بهرهبرداری عامل به جدول Q نگاه میکند و بهترین اقدام متناسب با بیشترین پاداش را انتخاب میکند. روشهای مختلفی برای پیادهسازی مراحل بهرهبرداری میباشد، کد زیر یک نمونه از آن میباشد.
episode = random.randint(0,500) qtable = np.random.randn(env.observation_space.sample(), env.action_space.sample()) # exploration-exploitation tradeoff epsilon = 1.0 # probability that our agent will explore decay_rate = 0.01 # of epsilon if random.uniform(0,1) < epsilon: # explore action = action = env.action_space.sample() else: # exploit action = np.argmax(qtable[state,:]) # epsilon decreases exponentially --> our agent will explore less and less epsilon = np.exp(-decay_rate*episode)
در این قطعه کد ما مقدار اپسیلون رو برابر با ۰.۷ قرار دادیم در نتیجه در این گام ۷۰ درصد عامل جستجو و ۳۰ درصد بهرهبرداری انجام میدهد. در طی زمان مقدار اپسیلون به صورت نمایی کاهش مییابد تا عامل بیشتر به بهرهبرداری بپردازد.
مراحل یادگیری برای عامل ما به شکل زیر میباشد.
پیاده سازی کامل به شکل زیر میباشد.
import numpy as np import gym import random def main(): # create Taxi environment env = gym.make('Taxi-v3') # initialize q-table state_size = env.observation_space.n action_size = env.action_space.n qtable = np.zeros((state_size, action_size)) # hyperparameters learning_rate = 0.9 discount_rate = 0.8 epsilon = 1.0 decay_rate= 0.005 # training variables num_episodes = 1000 max_steps = 99 # per episode # training for episode in range(num_episodes): # reset the environment state = env.reset() done = False for s in range(max_steps): # exploration-exploitation tradeoff if random.uniform(0,1) < epsilon: # explore action = env.action_space.sample() else: # exploit action = np.argmax(qtable[state,:]) # take action and observe reward new_state, reward, done, info = env.step(action) # Q-learning algorithm qtable[state,action] = qtable[state,action] + learning_rate * (reward + discount_rate * np.max(qtable[new_state,:])-qtable[state,action]) # Update to our new state state = new_state # if done, finish episode if done == True: break # Decrease epsilon epsilon = np.exp(-decay_rate*episode) print(f"Training completed over {num_episodes} episodes") input("Press Enter to watch trained agent...") # watch trained agent state = env.reset() done = False rewards = 0 for s in range(max_steps): print(f"TRAINED AGENT") print("Step {}".format(s+1)) action = np.argmax(qtable[state,:]) new_state, reward, done, info = env.step(action) rewards += reward env.render() print(f"score: {rewards}") state = new_state if done == True: break env.close() if __name__ == "__main__": main()