سلام به همه. تو این نوشته میخوام یکمی در مورد اهمیت مدیریت لاگ ها صحبت کنیم و در آخر بیاییم و لاگ هارو از یه سرویس (تو این نوشته من access.log سرویس Nginx رو انتخاب کردم )بگیریم و بفرستیم به یه انبار مخصوص برای نگهداری لاگ هامون (Elastic Search) . خب اول کار اینم بگم این نوشته دو قسمت خواهد داشت . تو این قسمت پیاده سازی تماما خارج از کلاستر کوبر انجام میشه و تو قسمت بعدی همین سناریو رو میبریم تو دل کلاستر کوبر.
خب؛ بیایید با این شروع کنیم که اصلا لاگ هارو چرا لازم داریم و چرا باید تو یه انبار تخصصی لاگ مثل الستیک سرچ نگهداری کنیم ازشون.
لاگها مثل دزدگیر ماشین هستن. تا وقتی همه چیز اوکیه، کسی بهشون توجهی نمیکنه، اما همین که یه مشکل کوچیک پیش بیاد، همه میدونن که لاگها تنها چیزین که میتونن بگن «داستان از چه قرار بود؟!» . حالا چرا الستیک سرچ؟ یه مفهوم بسیار مهم در صنعت آی تی امروزی تو دنیا وجود داره و اونم اینه که در سرویسی که ساختی باید تو TPS های بالا بتونه عالی کار کنه و زیر لود سنگین جواب بده وگرنه سرهم کردن یه چیزی هنری نداره به اون صورت . اینا رو گفتیم که برسیم به این نکته که هنر کار ما زمانی مشخص میشه که بتونیم میلیارد ها لاگ رو مدیریت کنیم. حالا بیاییم در مورد دردسرهاش حرف بزنیم:
حجم بزرگی از لاگ ها : یه سرور شلوغ میتونه تو یه روز چندین میلیارد خط لاگ تولید کنه. حالا سرویس های معروف مثل همین Nginx به طور Default داره Log Rotate میکنه ولی حتما یادتون باشه تو محیط عملیاتی حتما مولفه Log Rotating فراموش نشه که اگر بشه باعث مشکلات زیادی بعدا میشه. یه استاد اون ور آبی تو یوتیوب همیشه میگفت تو بحث آی تی همیشه اگه اولش به آخرش فکر کنی آخرش آدم خوشحال تری هستی :) . بریم سراغ مورد بعدی ؛
مشکل جستجو بین حجم دیتای زیاد: پیدا کردن یه خطای خاص تو لاگها مثل این میمونه که تو یه کتابخونه تاریک با چراغ قوه دنبال یه خط تو یه کتاب بگردی!
مدیریت لاگ های به درد نخور یا قدیمی: اگه لاگها رو پاک نکنی، دیسک پر میشه. اگه پاک کنی، شاید همون روز بهشون نیاز پیدا کنی!
راه حل چیه؟
الستیک سرچ مثل یه گوگل برای لاگها میمونه. میتونی میلیونها خط لاگ رو تو چند ثانیه سرچ کنی.
کیبانا (همون داشبورد الستیک) هم بهت یه ویو زیبا میده تا لاگها رو راحتتر بفهمی.
میتونی به صورت تخصصی لاگ ها رو مدیریت کنی اون تو . برای مثال چند تا قابلیت میگم بهتون: شما میتونی لاگ هایی که تازه به انبارمون (الستیک) رسیدن رو بذاری رو دیسک های SSD و وقتی از سن لاگ هات مثلا دو ماه گذشت اینا رو کلا انتقال بدی روی دیسک های HDDت ؛ این کار باعث میشه سرچ روی لاگ های جدیدتر سریع تر باشه. یا میتونی از رو گرافانا روی لاگ هات کوئری بزنی و مانیتوریگ مشتی راه بندازی باهاش . یا حتی میتونی لاگ هات رو بین چندین سرور از کلاسترت پخش کنی تا اگه احیانا زبونم لال یه سرورت Down شد تو لاگ هات از بین نرن و همچنان در دسترس باشن و وقتی نود داون شده ت دوباره بالا اومد به صورت اتوماتیک جوین کلاستر بشه و لاگ های کلاستر رو هندل کنه و یا میتونی لاگ هات رو shard کنی و بین نود های مختلفت پخششون کنی تا زمان بازیابی دیتاهات کوتاه باشه تا حد ممکن و .... .
تا الان در مورد اینکه چرا لاگ ها واسمون مهمن صحبت کردیم و هم اینکه در مورد اینکه چرا جایی که لاگ هارو نگهداری میکنیم هم مهمه صحبت کردیم. حالا بیاییم در این مورد صحبت کنیم که چطور میشه لاگ هارو فرستاد به انبار داده مون؟ برای این کار یه سری ابزار ها توسعه داده شده . تعدادشون هم به نسبت زیاده حتی. مثلا Filebeat , Fluentbit و Vector .
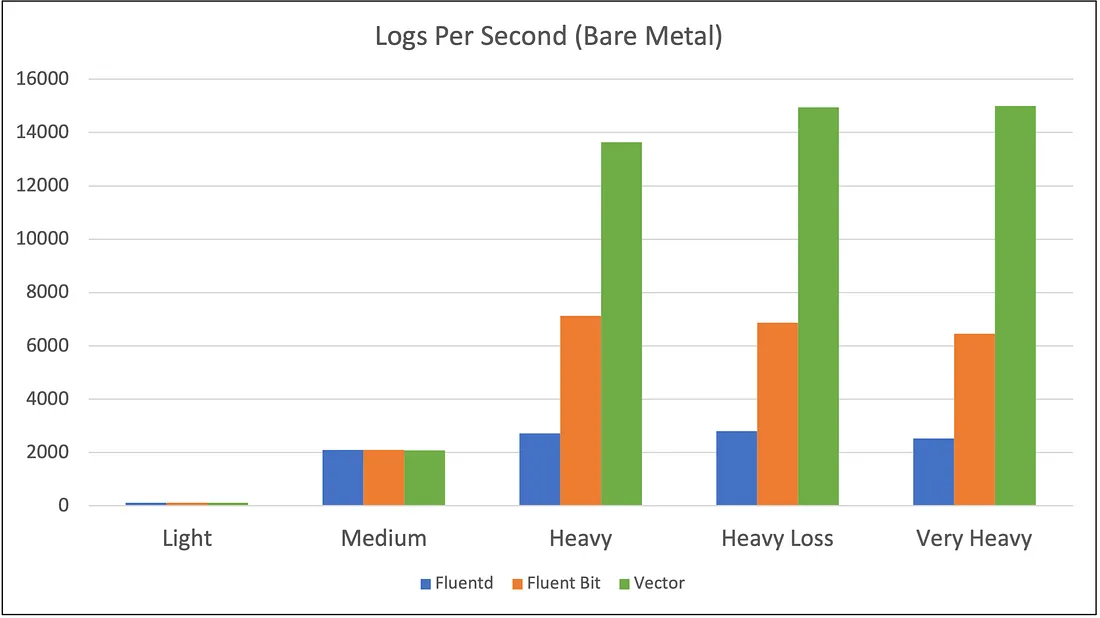
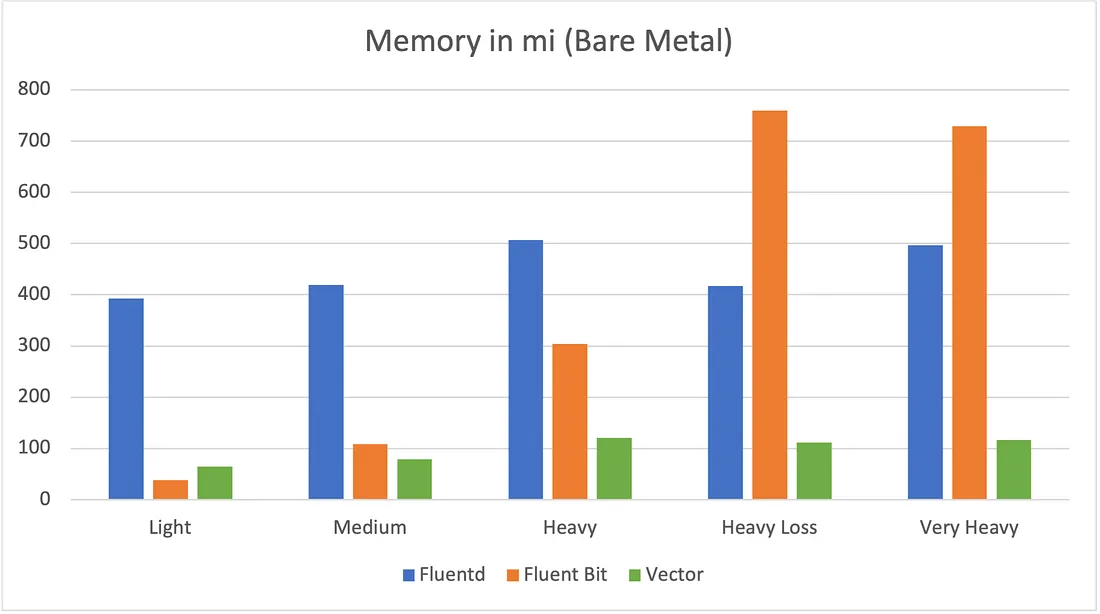
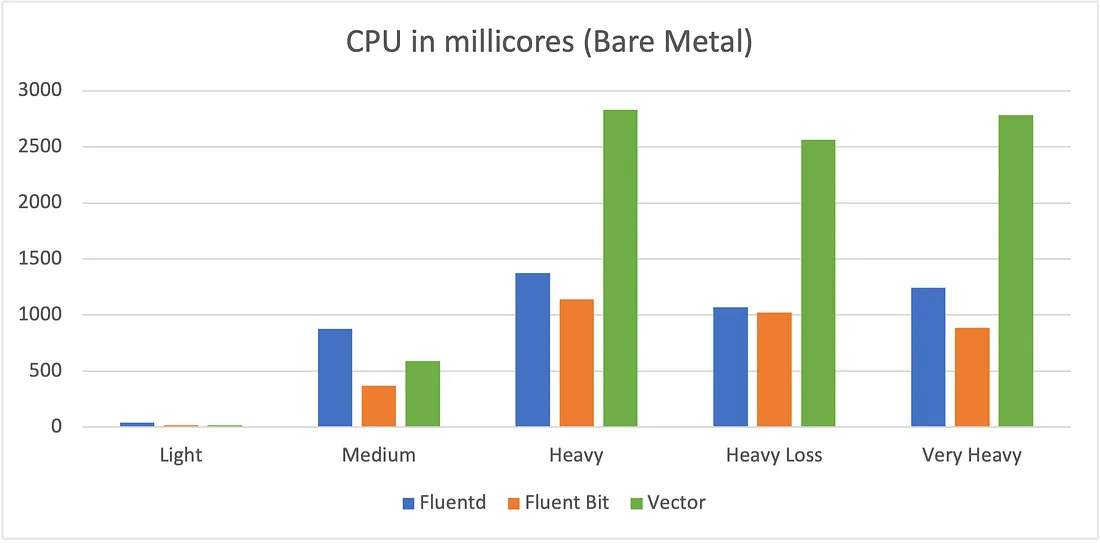
یه سری Benchmark های پابلیک در مورد این لاگ کالکتور و شیپر ها وجود داره که من لینکشو این زیر براتون میذارم که نشون میده Vector گزینه به شدت مناسبی هستش برای جاهایی که لود بالایی دارن. لینک
خب بریم سراغ پیاده سازی سرویس هامون. اول از همه بریم فرمت لاگ های سرویس Nginx رو جوری که دوس داریم درستش کنیم . فایل nginx.conf رو باز کنید و فرمت لاگتون رو مثل کانفیگ پایینی بکنید.
log_format main escape=json '{' '"remote_addr":"$remote_addr",' '"time_local":"$time_local",' '"remote_user":"$remote_user",' '"request":"$request",' '"status": "$status",' '"body_bytes_sent":"$body_bytes_sent",' '"http_referer":"$http_referer",' '"http_user_agent":"$http_user_agent",' '"request_time":"$request_time",' '"request_body":"$request_body",' '"http_x_forwarded_for":"$http_x_forwarded_for",' '"http_host":"$host",' '"uri":"$uri",' '"args":"$args"' '}';
خب الان لاگ های جدید رو چک کنیم میبینیم که تو فرمت json ذخیره میشن و ما به راحتی دیگه میتونیم اونا رو با سرویس Vectorمون بخونیم و تو الستیک ذخیره کنیم با حداقل مصرف فضای دیسک و حداقل over head .
الان باید بریم سراغ نصب سرویس vector روی سرورمون . اولین کاری که میکنیم اینه که میریم به صفحه گیتهاب وکتور و بعدش برحسب نیازمون پکیجش رو دانلود میکنیم و روی سرورمون نصبش میکنیم . مثلا من سرورم دبین هستش پکیج .deb رو دانلود کردم و بعدش با استفاده از کامند زیر روی سرورم نصبش کردم .
dpkg -i PACKAGE_NAME.deb
حالا فایل تو مسیر /etc/vector/vector.yaml کانفیگ زیر رو اضافه میکنیم بهش .
sources: nginx_logs: type: file include: - /var/log/nginx/access.log ignore_older_secs: 600 read_from: beginning transforms: parse_nginx: type: remap inputs: - nginx_logs source: | parsed, _ = parse_json(.message) del(.message) ., _ = merge(., parsed) sinks: elasticsearch-nginx: type: elasticsearch inputs: - parse_nginx endpoint: https://CLUSTER_IPs:9200 auth: strategy: basic user: VECTOR_USER password: YOUR_PASSWORD tls: ca_file: CERT_PATH/ca.crt verify_certificate: false mode: "data_stream" data_stream: type: "nginx" dataset: "dev" namespace: "default" bulk: action: "create" batch: max_bytes: 1 max_events: 1 timeout_secs: 1
خب بیایین یکمی در مورد کانفیگ بالایی صحبت کنیم . ببینید در کل هر پایپلاینی که برای لاگ ها میزنید کلا سه بخش اصلی داره. یه بخشش برای این هستش که شما لاگ ها دریافت کنید یا بخونید از فایلی . مرحله بعدیش میتونید یه سری تمیز کاری ها یا فیلتر ها انجام بدید روش و در مرحله نهایی باید مکان نهایی برای ذخیره لاگ ها رو بدید بهش. اینجا ما اومدیم گفتیم برو از مسیر پیش فرض لاگ های انجین ایکس لاگ هات رو بخون بعد بیار پارسش کن و فیلد هاش رو جدا کن از هم و بعد اون دیتای گنده قبل از پارس شدن دیتا رو پاک کن تا لاگ هامون جای اضافی نگیرن رو دیسک الستیکمون و در نهایت بیار و بریزش تو الستیک مون .
خب اینجا چند تا نکته هستش تو بخش سینک کردن دیتا تو الستیک:
مورد اول اینکه برای هندل کردن دیتا های حجیم شما میتونید از مفاهیم Data stream یا Alias ها در الستیک استفاده کنید. به این صورت که شما اون جلو یه آبجکتی دارید با یه نام مشخص و اون آبجکت اون پشت وصله به کلی ایندکس داخل کلاستر الستیکتون که به صورت hidden هستن. خب این از این . به علاوه مفاهیم بالاتر یه مفهوم دیگه هم داریم در الستیک به نام index lifecycle managment که همونطوری که از اسمش پیداست میاد طول عمر یه ایندکس رو مشخص میکنه و طبق فازبندی هایی میاد اونا رو منتقل میکنه به فاز های بعدی و اگر دوست داشته باشید بعد از مدتی کلا پاکش میکنه . خب این باعث میشه شما لاگ های 10 سال پیشتون رو بتونید پاک کنید اگر نیاز نباشه. یا اگر نیازه ولی کم استفاده میشه انتقالش بدید به سرور هایی با دیسک های کم ارزش تر با سرعت پایین تر تا پرفورمنس کلی کلاستر هاتون به مشکل نخوره. اینم از این. خب بریم سمت الستیکمون کارای دیتا استریم و index template رو هم اون ور اوکی کنیم به عنوان حسن خطام مسئله.
شما میتونید دستورات خودتون رو به کلاستر الستیکتون از دو روش بدید . یا مستقیم Api کلاسترمون رو میتونیم کال کنیم یا نه میتونیم از Dev Tools روی کیبانا استفاده کنیم.
PUT _ilm/policy/nginx-dev { "policy": { "phases": { "hot": { "actions": { "rollover": { "max_age": "1d" } } }, "delete": { "min_age": "30d", "actions": { "delete": {} } } } } }
خب مرحله اول میاییم یه ilm میسازیم که بگیم بهش چطور ایندکس هامون رو مدیریت کنه . مثلا این بالا من بهش گفتم یه روز اول دیتاهام تو فاز Hot باشه و اگه ایندکسی سنش 30 روز شد رو کلا پاک کن . عالی نیست؟ :)
خب بریم سراغ مرحله بعدیمون
PUT /_index_template/nginx-template { "data_stream": {}, "index_patterns": ["nginx-dev*"], "template": { "settings": { "index.number_of_shards": 1, "index.number_of_replicas": "0", "index.lifecycle.name": "nginx-dev" } } }
این کانفیگمون هم میاد یه Template کلی برای ایندکس ها میسازه و باعث میشه هر ایندکسی که با فرمت nginx-dev-* بیاد رو میندازه پشت یه دیتااستریم و مدیریتشون میکنه.
خب حالا بعد از گذشت چندین روز اگه لاگ های انجین ایکسمون رو ببینیم میبینیم که لاگ ها به صورت Hidden ذخیره شدن و اگه برید و دیتاویو ازش بسازید میتونید همونجا تو کیبانا دیتاهاتون رو به صورت لایو ببینید.

این یه پیاده سازی کاملا ساده از این سرویس بود امیدوارم نفسی بیاد و بره تا تو نوشته های بعدی در مورد Best Practice های این سرویس تو محیط پروداکشن و همچنین پیاده سازیش داخل کلاستر کوبرنتیزمون بنویسم . ممنون از اینکه خوندید. عزت زیاد باد :)