اگر بخواهیم دنیای امروز نرمافزار را فقط با چند واژه توصیف کنیم، احتمالاً باید از «پیچیدگی»، «مقیاس»، «تغییر مداوم» و «نیاز به پایداری» نام ببریم. نرمافزارهای امروزی دیگر فقط چند صفحه وب یا یک برنامه ساده دسکتاپ نیستند؛ آنها شبکهای از سرویسها، دادهها، فرایندها، زیرساختها و تصمیمهای معماری هستند که باید بهصورت هماهنگ کار کنند. به همین دلیل، برای درک درست فضای مدرن مهندسی نرمافزار، لازم است مجموعهای از مفاهیم کلیدی را نه بهصورت پراکنده، بلکه بهعنوان اجزای یک منظومه واحد ببینیم.
دنیای نرمافزار دیگر فقط نوشتن چند کلاس، چند API و اتصال به پایگاه داده نیست. امروزه ساختن یک سیستم واقعی، یعنی طراحی دقیق دامنه مسئله، انتخاب معماری مناسب، مدیریت داده و رویداد، خودکارسازی زیرساخت، کنترل ارتباط سرویسها، تضمین پایداری، و در بسیاری از موارد ترکیب اینها با مدلهای هوش مصنوعی. به همین دلیل، بسیاری از واژههایی که در چند سال اخیر وارد ادبیات مهندسی نرمافزار شدهاند، دیگر اصطلاحات لوکس یا صرفاً ترندی نیستند؛ این مفاهیم پاسخ مستقیم به مسائل واقعی سیستمهای بزرگ، توزیعشده و در حال رشد هستند.
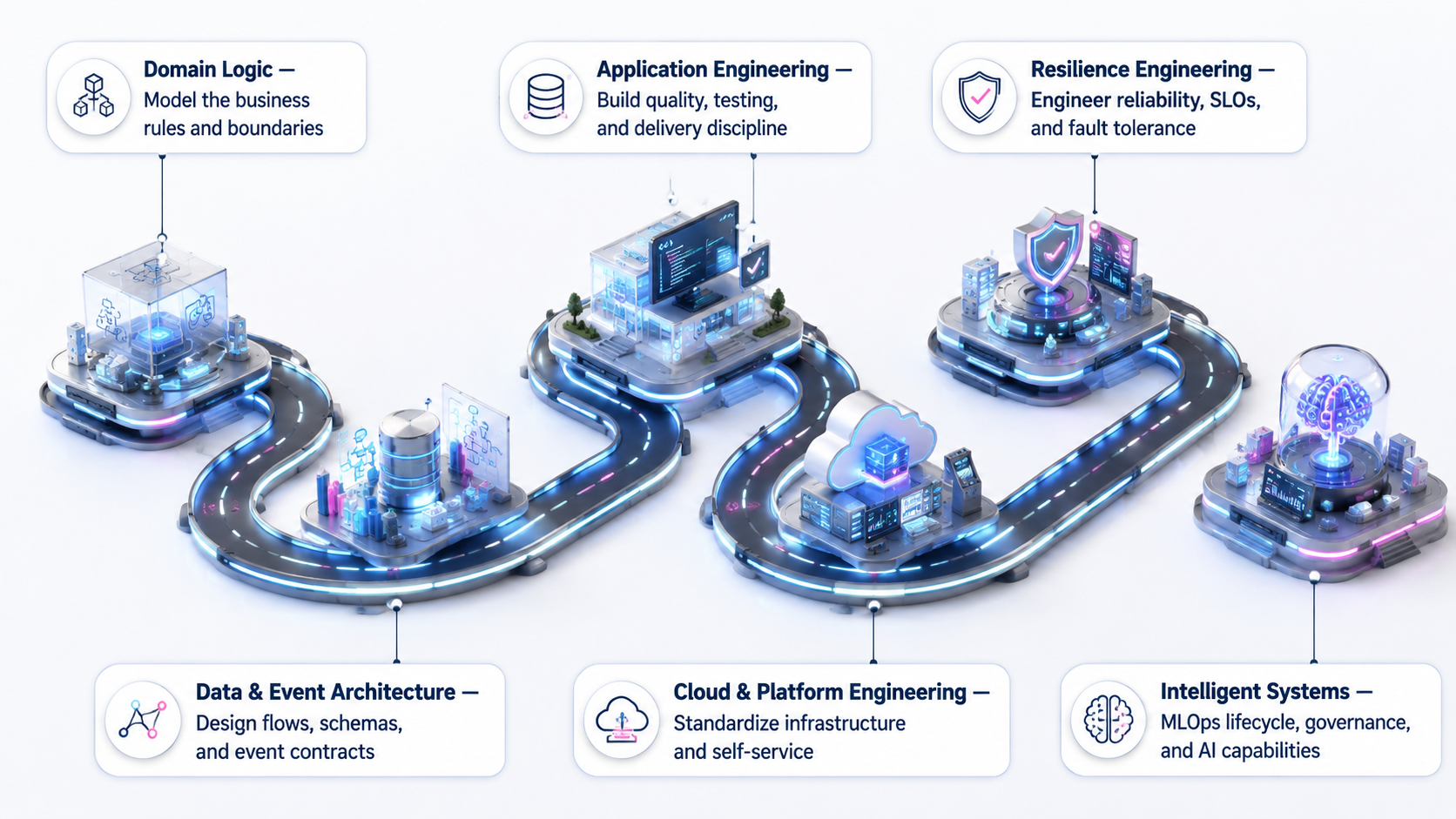
اگر بخواهیم معماری و توسعه نرمافزار مدرن را به یک نقشه راه تشبیه کنیم، باید از جایی شروع کنیم که مسئله کسبوکار را میفهمیم، سپس وارد طراحی معماری میشویم، و بعد از ساخت نرم افزار سراغ مدیریت داده، استقرار، مقیاسپذیری، تابآوری، اتوماسیون، و در نهایت استفاده مؤثر از هوش مصنوعی میرویم.
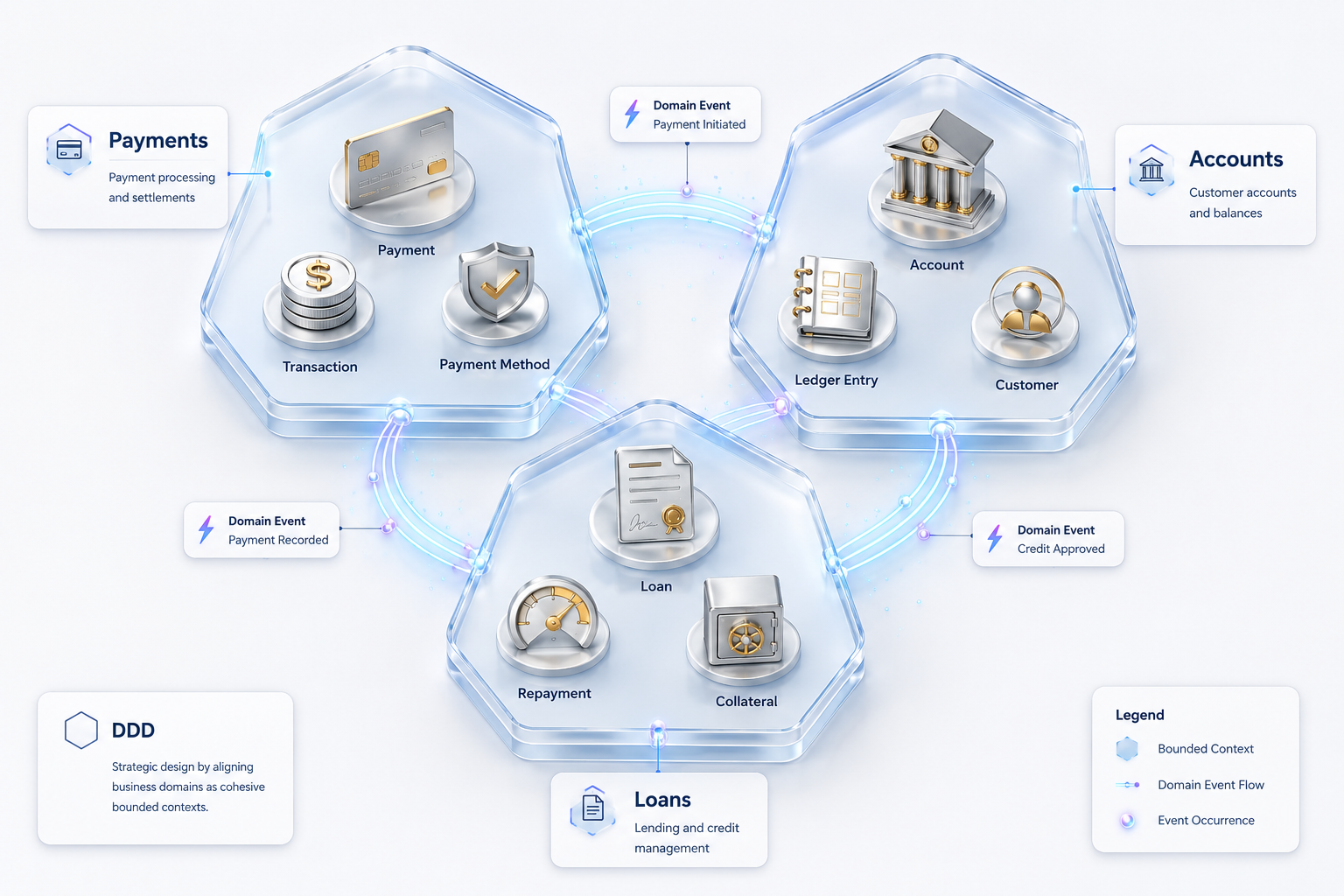
یکی از اشتباههای رایج در توسعه نرمافزار این است که تیمها خیلی زود وارد انتخاب فریمورک، دیتابیس یا ابزارهای فنی میشوند، در حالی که هنوز مسئله اصلی را بهدرستی نفهمیدهاند. در پروژههای موفق، معماری خوب از فهم دقیق دامنه مسئله شروع میشود، نه از تکنولوژی. Domain Driven Design یا طراحی دامنهمحور، رویکردی است که میگوید نرمافزار باید بازتابی از دنیای واقعی کسبوکار باشد. در این نگاه، مهمترین چیز این نیست که جدولهای دیتابیس چگونه طراحی شوند یا APIها چه شکلی باشند؛ مهم این است که مفاهیم اصلی حوزه کاری بهدرستی شناخته شوند و در کد هم به همان زبان مدلسازی شوند.
فرض کنید در حال طراحی یک سامانه بانکی هستیم. واژههایی مانند «حساب»، «تراکنش»، «مشتری»، «تسهیلات»، «سقف برداشت» و «مسدودی» فقط کلمات فنی نیستند، بلکه مفاهیم واقعی در دامنه کسبوکار بانک هستند. اگر این مفاهیم از ابتدا دقیق مدل نشوند، سیستم بهمرور دچار آشفتگی میشود و توسعه آن دشوار خواهد شد. DDD کمک میکند تیم فنی و تیم کسبوکار به یک زبان مشترک برسند؛ زبانی که هم در جلسات تحلیل استفاده میشود و هم در کد. در DDD معمولاً سیستم به چند بخش معنایی تقسیم میشود که به آنها Bounded Context میگویند. مثلاً در یک بانک، بخش مدیریت حساب با بخش تسهیلات یا مبارزه با تقلب، هر کدام میتوانند context مستقل داشته باشند. این جداسازی باعث میشود مرز مسئولیتها روشنتر شود و پیچیدگی مهار شود.
وقتی دامنه را شناختیم، سؤال بعدی این است که چگونه ساختار نرمافزار را طوری طراحی کنیم که منطق اصلی آن از وابستگیهای بیرونی در امان باشد. Hexagonal Architecture یا معماری ششضلعی دقیقاً برای همین هدف ایجاد شده است. در این معماری، هسته اصلی برنامه که همان منطق کسبوکار است، در مرکز قرار میگیرد. هر چیزی که به بیرون مربوط است، مانند دیتابیس، رابط کاربری، سرویس پیامک، API خارجی یا صف پیام، در نقش adapter قرار میگیرد. ارتباط بین هسته و این اجزای بیرونی از طریق interfaceهایی انجام میشود که به آنها port میگویند. مزیت اصلی این مدل آن است که اگر فردا تصمیم بگیرید دیتابیس را عوض کنید یا از REST به gRPC مهاجرت کنید، لازم نیست منطق اصلی کسبوکار را از نو بنویسید. در همان مثال بانکی، قوانین انتقال وجه یا محاسبه کارمزد نباید به این وابسته باشند که از PostgreSQL استفاده میکنید یا Oracle. این استقلال، هم تستپذیری را بالا میبرد و هم تغییرپذیری سیستم را بیشتر میکند.
در دنیای مدرن، معمولاً چند تیم همزمان روی بخشهای مختلف کار میکنند: یک تیم روی اپلیکیشن موبایل، تیمی دیگر روی پنل وب، و تیمی هم روی back-end. اگر قرارداد ارتباطی بین این تیمها شفاف نباشد، اصطکاک زیادی ایجاد میشود. اینجا API-first Approach اهمیت پیدا میکند.در رویکرد API-first، قبل از شروع پیادهسازی، ابتدا APIها طراحی و مستند میشوند. یعنی مشخص میشود هر endpoint چه ورودیای میگیرد، چه خروجیای میدهد، چه خطاهایی ممکن است برگرداند و قرارداد دادهها به چه شکل است. این کار کمک میکند توسعه بهصورت موازی پیش برود و سوءتفاهمهای فنی کاهش پیدا کند.
در یک سامانه بانکی، وقتی قرار است موبایلبانک و اینترنتبانک هر دو از سرویس مشاهده موجودی استفاده کنند، تعریف دقیق API باعث میشود همه بدانند پاسخ این سرویس دقیقاً چه ساختاری دارد، کدام فیلدها اجباریاند و وضعیتهای خطا چگونه مدیریت میشوند. به این ترتیب، API از یک جزئیات فنی به یک قرارداد رسمی بین اجزای سیستم تبدیل میشود.
با گسترش انواع کلاینتها، استفاده از یک back-end عمومی برای همه آنها همیشه بهترین راهحل نیست. نیازهای اپلیکیشن موبایل با پنل وب مدیریتی یا نسخه عمومی وبسایت یکسان نیست. Back-end for Front-end یا BFF میگوید بهتر است برای هر نوع فرانتاند، یک back-end اختصاصی داشته باشیم که متناسب با نیاز همان کلاینت طراحی شده باشد.BFF یا Back-end for Front-end زمانی مطرح میشود که یک بکاند عمومی نمیتواند نیازهای متفاوت کلاینتها را بهخوبی پوشش دهد. برای مثال، اپلیکیشن موبایل، پنل وب مدیریتی و نسخه اینترنت ضعیف، هر کدام ممکن است نیاز به داده، فرمت پاسخ و سطحی از پردازش متفاوت داشته باشند. اگر همه این نیازها را به یک API عمومی تحمیل کنیم، معمولاً یا API بیش از حد پیچیده میشود یا بعضی کلاینتها کارایی مطلوبی نخواهند داشت.
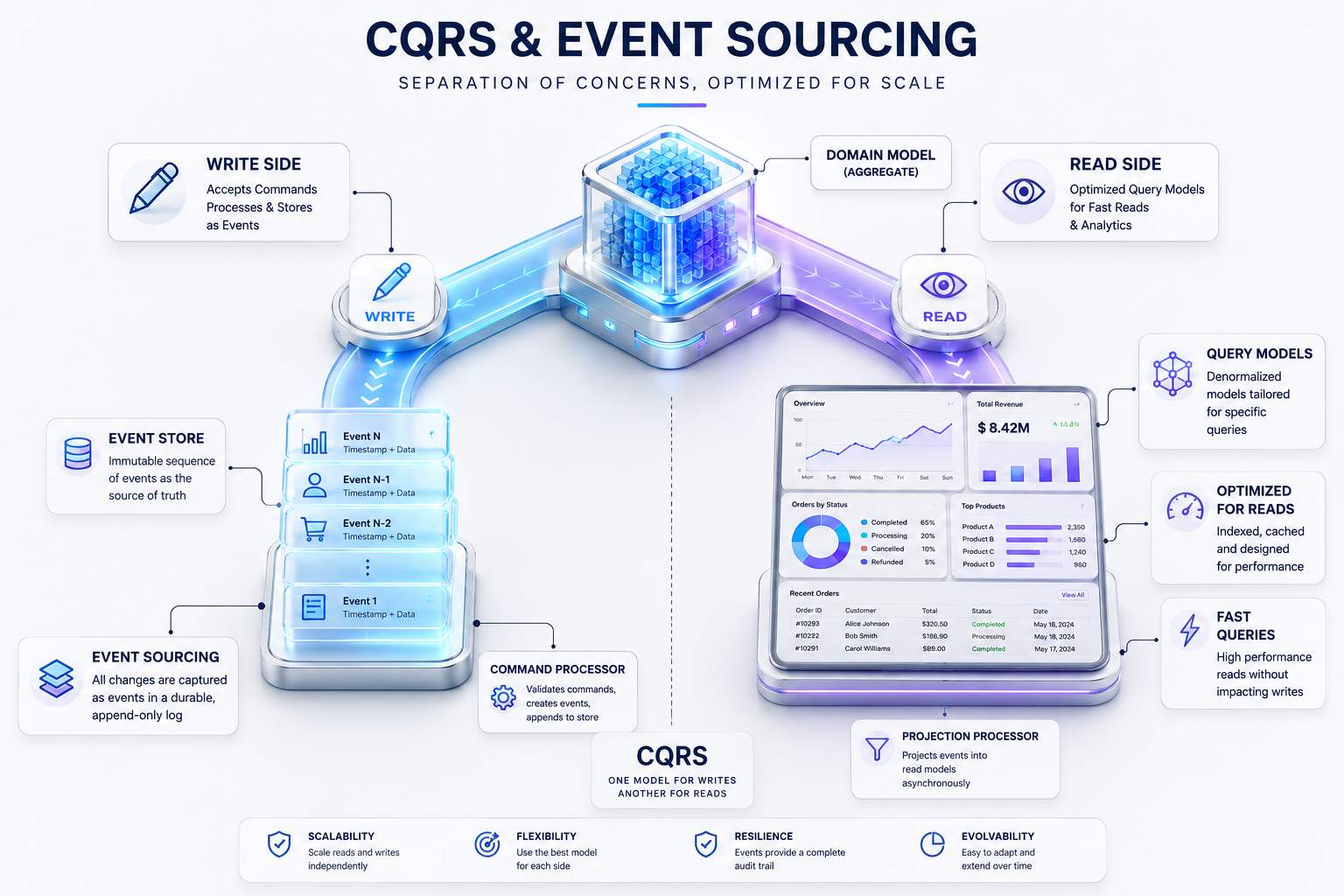
وقتی سیستم بزرگتر میشود، دیگر فقط این مهم نیست که داده کجا ذخیره میشود؛ بلکه مهم است بدانیم حقیقت سیستم چگونه شکل میگیرد، تغییرات چگونه ثبت میشوند، و سرویسها چگونه از تغییرات هم مطلع میشوند. در این بخش، مفاهیمی مثل CQRS، Event Sourcing، Event-Driven Architecture و Message Queue وارد میدان میشوند. این مفاهیم معمولاً در سیستمهای توزیعشده، پرترافیک و نیازمند مقیاسپذیری بالا اهمیت زیادی پیدا میکنند.
CQRS مخفف Command Query Responsibility Segregation است و بر این ایده بنا شده که مسیر نوشتن و مسیر خواندن الزاماً نباید یکسان باشند. در بسیاری از سیستمها، نیازمندیهای بخش خواندن داده با بخش نوشتن کاملاً متفاوت است. بخش نوشتن معمولاً نیازمند اعتبارسنجی، اعمال قوانین کسبوکار و کنترل سازگاری است، در حالی که بخش خواندن بیشتر به سرعت، سادگی و بهینهسازی برای گزارش یا نمایش نیاز دارد.
برای نمونه، در یک سامانه بانکی، عملیات انتقال وجه باید از قواعد سختگیرانهای پیروی کند؛ مثل بررسی موجودی، محدودیت روزانه، وضعیت حساب و ثبت رخدادها. اما صفحه مشاهده تاریخچه تراکنشها فقط نیاز دارد دادهها را سریع و در قالب مناسب نمایش دهد. اگر این دو مسیر را از هم جدا کنیم، میتوانیم طراحی هر کدام را متناسب با نیاز واقعیاش انجام دهیم. البته CQRS همیشه لازم نیست، اما در سیستمهای پیچیده میتواند مزیت بزرگی ایجاد کند.
در Event Sourcing، به جای اینکه فقط وضعیت نهایی سیستم ذخیره شود، تمام رویدادهایی که باعث شکلگیری آن وضعیت شدهاند ذخیره میشوند. یعنی به جای اینکه فقط موجودی فعلی حساب را داشته باشیم، همه رویدادهای مرتبط مثل افتتاح حساب، واریز، برداشت، انتقال، مسدودی و رفع مسدودی ثبت میشوند. وضعیت فعلی هر زمان با بازپخش این رویدادها قابل بازسازی است. این رویکرد در حوزههایی که تاریخچه، قابلیت حسابرسی، ردیابی تغییرات و تحلیل دقیق اهمیت زیادی دارد، بسیار ارزشمند است. در بانکداری، دانستن اینکه موجودی چگونه به وضعیت فعلی رسیده، فقط یک نیاز فنی نیست؛ گاهی یک الزام نظارتی، حسابرسی یا حقوقی است. البته Event Sourcing طراحی پیچیدهتری نسبت به ذخیرهسازی معمولی دارد و باید با دقت بالا پیادهسازی شود، اما در جای درست، مزایای آن بسیار چشمگیر است.
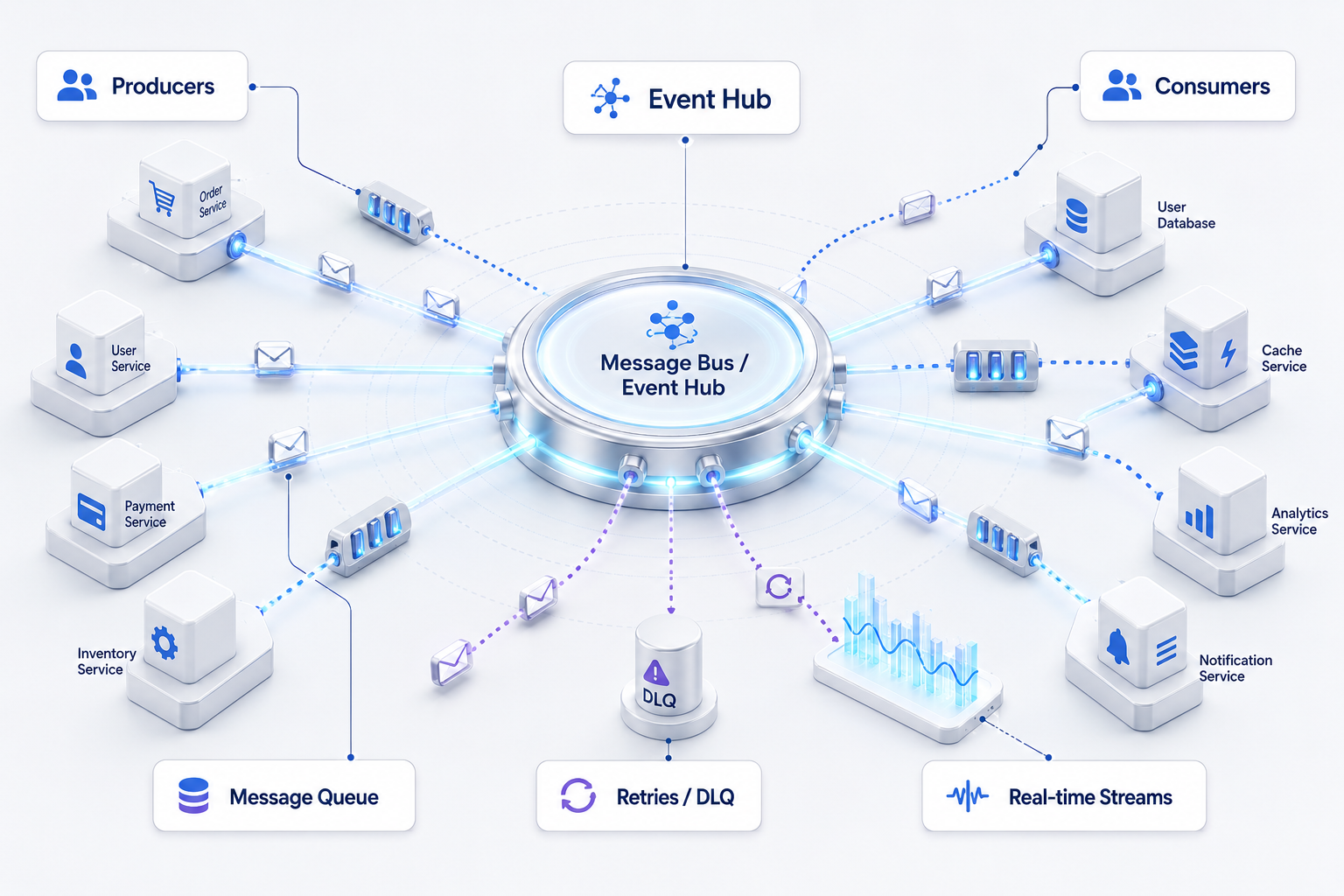
معماری رویدادمحور یا EDA بر این اصل استوار است که سرویسها بهجای وابستگی مستقیم و همزمان به یکدیگر، با انتشار و دریافت رویداد با هم تعامل کنند. در این مدل، وقتی اتفاقی در یک سرویس رخ میدهد، یک Event منتشر میشود و سرویسهای دیگر که به آن علاقهمند هستند میتوانند مستقل از سرویس اولیه به آن واکنش نشان دهند.
فرض کن در یک بانک، بعد از افتتاح حساب جدید، چند کار باید انجام شود: ارسال پیام خوشآمدگویی، ایجاد پروفایل در سامانه وفاداری، فعالسازی تنظیمات ریسک، و ثبت داده برای تحلیل. اگر همه اینها بهصورت مستقیم و همزمان به سرویس افتتاح حساب وابسته باشند، سیستم بهشدت درهمتنیده میشود. اما در معماری رویدادمحور، سرویس افتتاح حساب فقط Event مربوطه را منتشر میکند و هر سرویس دیگر مستقلاً آن را مصرف میکند. این کار هم انعطافپذیری را افزایش میدهد و هم توسعه مستقل سرویسها را آسانتر میکند.
Message Queue یا صف پیام یکی از ابزارهای اصلی برای پیادهسازی ارتباط غیرهمزمان بین سرویسهاست. با استفاده از صف پیام، لازم نیست فرستنده و گیرنده دقیقاً در یک زمان در دسترس باشند. پیام در صف قرار میگیرد و مصرفکننده هر زمان آماده باشد آن را دریافت و پردازش میکند. این موضوع برای تحمل بار، پایداری و جدا کردن اجزای سیستم از هم بسیار مهم است.
ابزارهایی مثل RabbitMQ و Kafka هر دو در این حوزه کاربرد دارند، اما نوع استفاده از آنها متفاوت است. RabbitMQ معمولاً برای الگوهای کلاسیک صف و مسیردهی پیام بسیار مناسب است، در حالی که Kafka بیشتر برای جریان رویداد، پردازش حجیم و نگهداری log ترتیبی رویدادها کاربرد دارد. در یک سامانه بانکی، ممکن است رویدادهای تراکنشی به Kafka بروند تا چندین سرویس تحلیلی و عملیاتی آنها را مصرف کنند، در حالی که اعلانهای غیرهمزمان خاص از طریق RabbitMQ مدیریت شوند.
نرمافزار فقط طراحی دامنه و مدل داده نیست؛ باید جایی اجرا شود، مقیاس بگیرد، امن بماند، قابل کنترل باشد و در شرایط واقعی دوام بیاورد. در اینجا بحث وارد زیرساخت، استقرار، شبکه، کنترل ترافیک و معماری عملیاتی میشود. مفاهیمی مثل Container، Kubernetes، Infrastructure as Code، API Gateway، Service Mesh، Server-less و Multi-Tenancy دقیقاً در همین مرحله اهمیت پیدا میکنند.
کانتینرها راهی برای بستهبندی نرمافزار همراه با وابستگیهایش هستند، بهطوری که برنامه بتواند در محیطهای مختلف با رفتار قابل پیشبینی اجرا شود. Docker شناختهشدهترین ابزار این حوزه است. مزیت اصلی کانتینر این است که اختلاف بین محیط توسعه، تست و تولید را کمتر میکند و استقرار نرمافزار را استانداردتر میسازد.
اما وقتی تعداد کانتینرها زیاد میشود، مدیریت دستی آنها دیگر ممکن نیست. Kubernetes برای حل همین مسئله آمده است. این پلتفرم استقرار، مقیاسپذیری، خودترمیمی، توزیع بار، و مدیریت rollout و rollback را خودکار میکند. در یک سامانه بانکی که در ساعات خاصی بار تراکنش بالا میرود، Kubernetes میتواند تعداد نمونههای سرویسهای حساس را افزایش دهد و اگر یک نود از کار افتاد، سرویسها را روی نودهای دیگر بالا بیاورد.
Infrastructure as Code یا IaC یعنی زیرساخت را هم مانند کد مدیریت کنیم. به جای اینکه سرورها، شبکهها، Load Balancerها، Secretها یا محیطهای مختلف را دستی بسازیم، همه اینها در قالب فایلهای قابل نسخهبندی تعریف میشوند. ابزارهایی مثل Terraform، Pulumi، Ansible و Cloud-formation در این حوزه کاربرد فراوانی دارند.
این رویکرد چند مزیت مهم دارد: بازتولیدپذیری، کاهش خطای انسانی، امکان code review، و همسانسازی محیطها. در پروژههای بانکی یا سازمانی، داشتن محیطهای Dev، staging، production و disaster recovery که با تعریف یکسان و کنترلشده ایجاد میشوند، یک مزیت استراتژیک است. IaC فقط ابزار Dev-ops نیست؛ بخشی از انضباط مهندسی سیستم است.

API Gateway دروازه ورودی درخواستهای بیرونی به سیستم است. این لایه معمولاً مسئول احراز هویت، rate limiting، routing، SSL termination، versioning و گاهی aggregation است. در معماریهای مبتنی بر چند سرویس، داشتن یک نقطه کنترل در لبه سیستم بسیار مهم است.
Service Mesh اما بیشتر به ارتباطات داخلی بین سرویسها مربوط میشود. در سیستمهای بزرگ، نیازهایی مثل mTLS، retry، timeout، circuit breaking، tracing و observability برای ارتباط سرویس با سرویس بهوجود میآید. اگر همه این منطق را داخل تکتک سرویسها بنویسیم، سیستم بسیار پیچیده میشود. Service Mesh این قابلیتها را بهصورت لایهای مشترک فراهم میکند. به زبان ساده، API Gateway بیرون سیستم را کنترل میکند و Service Mesh داخل آن را.

در معماری Server-less، تیم توسعه بیشتر روی اجرای کد تمرکز میکند و مدیریت مستقیم سرورها تا حد زیادی به ارائهدهنده cloud سپرده میشود. این مدل معمولاً برای بارهای متغیر، وظایف event-driven، jobهای کوتاهمدت و سناریوهایی که نیاز به provisioning دائمی ندارند مناسب است.
برای مثال، تولید فایل PDF صورتحساب ماهانه، پردازش یک webhook، تغییر اندازه تصویر، یا اجرای یک تابع زمانبندیشده میتواند با Server-less بسیار اقتصادی و سریع انجام شود. البته این معماری هم محدودیتهای خودش را دارد: cold start، محدودیت زمان اجرا، پیچیدگی debugging و وابستگی بیشتر به vendor. بنابراین باید آگاهانه انتخاب شود، نه صرفاً بهعنوان یک مد روز.
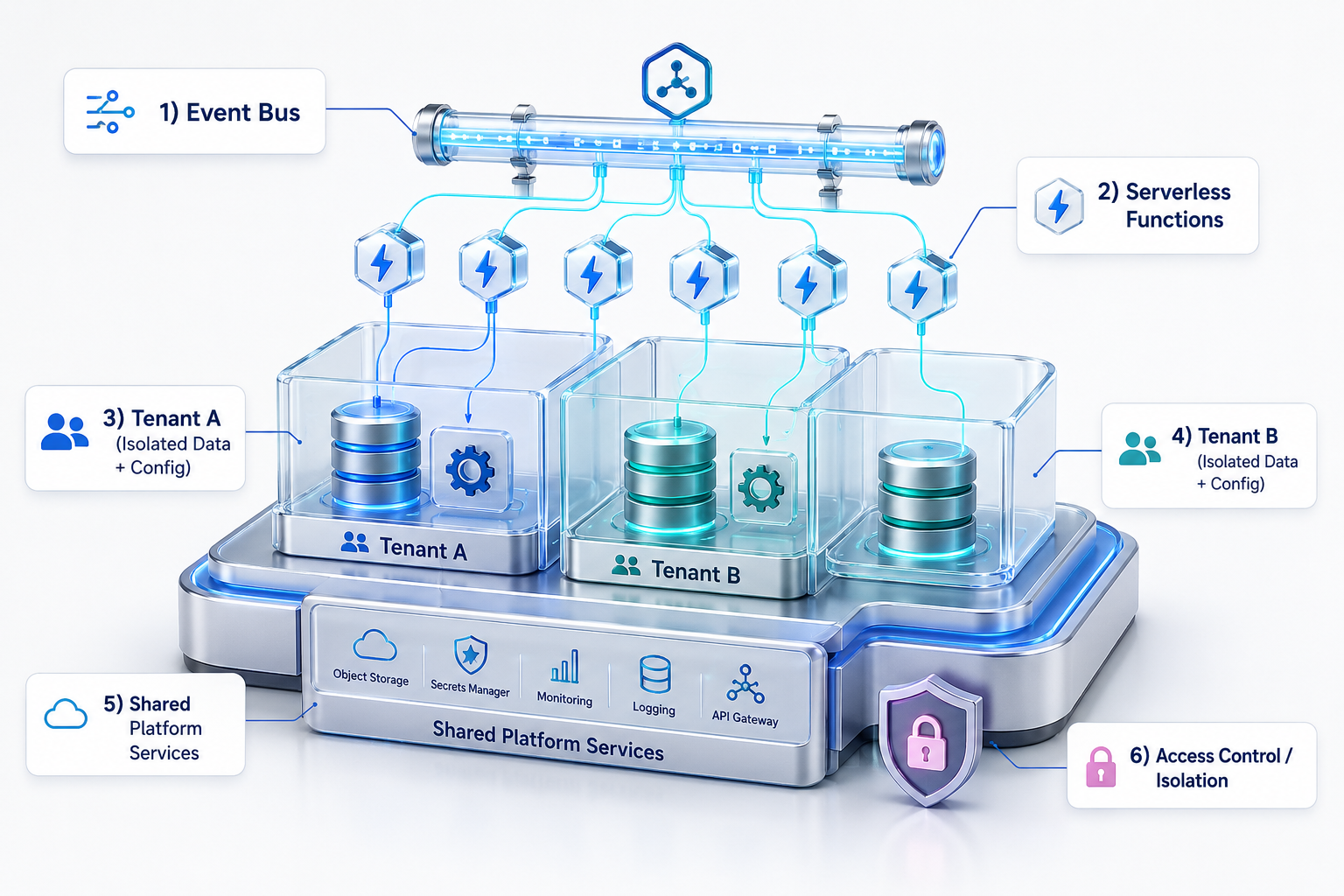
معماری Multi-Tenancy زمانی مطرح میشود که یک سیستم واحد باید به چند مشتری، سازمان یا مستأجر سرویس بدهد، بدون اینکه لازم باشد برای هر کدام یک سامانه کامل جداگانه ساخته شود. در این مدل، منابع زیرساختی ممکن است مشترک باشند، اما داده، تنظیمات، سطح دسترسی و گاهی حتی قابلیتها باید برای هر tenant بهصورت جداگانه مدیریت شوند.
در پلتفرمهای بانکی، بیمهای یا SaaS های سازمانی، این معماری بسیار رایج است. فرض کن یک پلتفرم مرکزی به چند بانک منطقهای سرویس میدهد. هر بانک باید کاربران، دادهها، سیاستهای امنیتی، قالبهای گزارش و تنظیمات خاص خودش را داشته باشد، اما همه روی یک بستر نرمافزاری مشترک کار میکنند. طراحی درست Multi-Tenancy هم بهینهسازی اقتصادی دارد و هم حساسیت امنیتی بسیار بالایی.
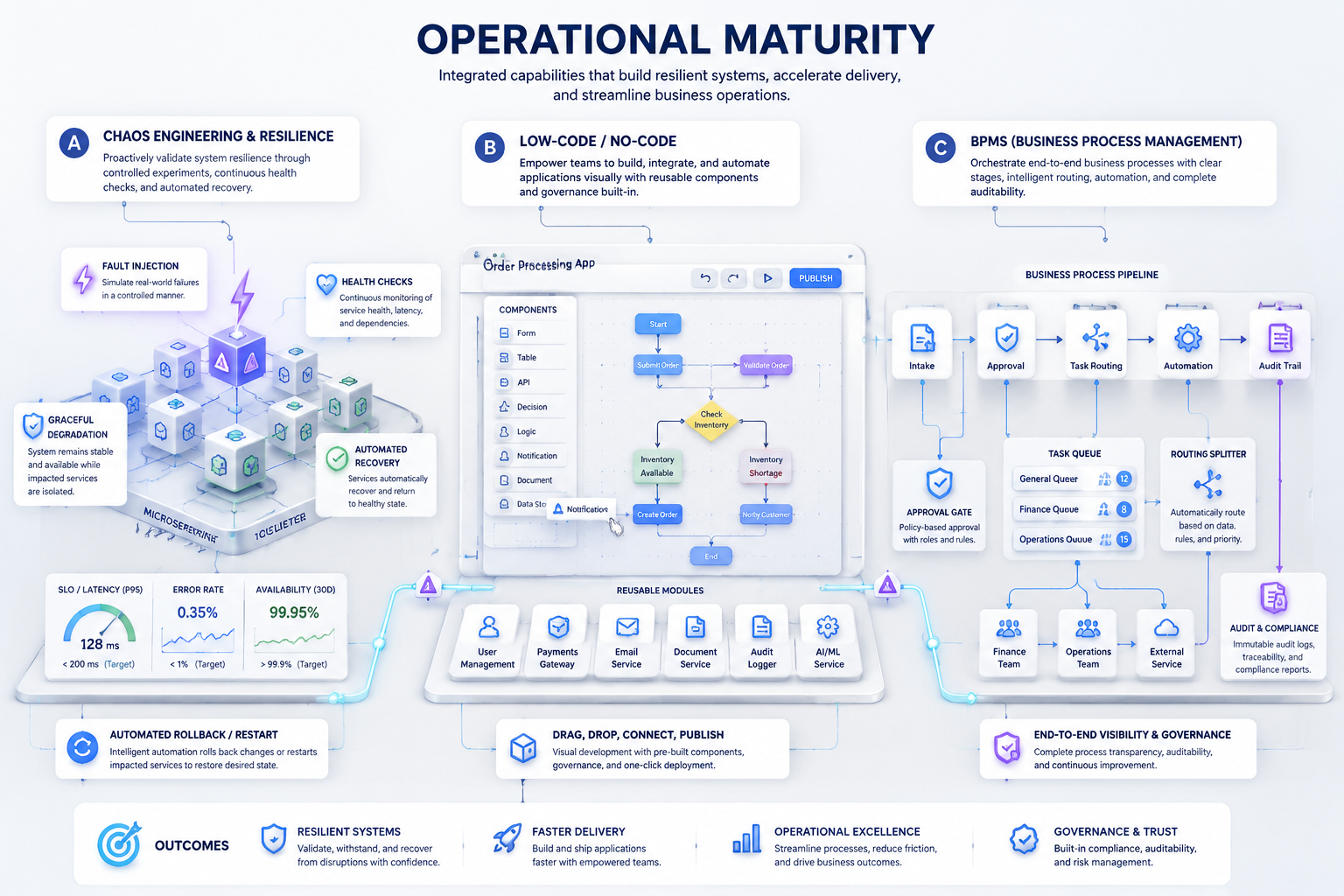
هرچه سیستم بزرگتر و حساستر میشود، صرفاً کار کردن آن کافی نیست. باید مطمئن باشیم که در شرایط غیرعادی هم دوام میآورد، فرایندهای سازمانی را میتوان روی آن اجرا کرد، و در جاهایی که لازم است، سرعت توسعه را با ابزارهای مناسب بالا برد. در این بخش، Chaos Engineering، Low-code/No-code و BPMS را میتوان بهعنوان سه پاسخ متفاوت به سه نوع نیاز واقعی دید: تابآوری، سرعت، و فرایندسازی.
Chaos Engineering رویکردی است که در آن بهصورت کنترلشده، اختلالهایی را به سیستم تزریق میکنیم تا ببینیم در شرایط واقعی بحران چگونه رفتار میکند. ایده اصلی این است که ضعف سیستم را قبل از رخداد واقعی کشف کنیم، نه بعد از آن. این اختلال میتواند قطع شدن یک سرویس، افزایش ناگهانی latency، از دست رفتن یک node، یا خطای ارتباطی بین اجزا باشد.
در سامانههای حساس مثل بانکداری، تجارت الکترونیک یا خدمات ابری، این رویکرد بسیار مهم است. برای مثال، اگر سرویس احراز هویت کند شود یا ارتباط با یک dependency موقتاً قطع شود، آیا سیستم fail gracefully میکند یا کل سرویس از دسترس خارج میشود؟ Chaos Engineering کمک میکند پاسخ این سؤال را قبل از بحران واقعی بدانیم. این کار البته باید با دقت، مرحلهبندی و observability مناسب انجام شود.
پلتفرمهای Low-code و No-code با هدف افزایش سرعت توسعه برای سناریوهای خاص شکل گرفتهاند. در این ابزارها، بخشی از منطق یا رابط کاربری بهصورت drag-and-drop، فرممحور یا از طریق تنظیمات آماده ساخته میشود. No-code بیشتر برای کاربرانی است که برنامهنویس نیستند و Low-code معمولاً اجازه میدهد توسعهدهندگان هم در صورت نیاز کدنویسی تکمیلی انجام دهند.
این پلتفرمها برای ساخت سریع فرمها، گردشکارهای ساده، پنلهای داخلی، ابزارهای اداری یا MVPها بسیار مفیدند. اما برای سامانههای پیچیده، هستههای حساس تراکنشی یا منطق دامنه عمیق، معمولاً کافی نیستند. در نتیجه، باید آنها را بهعنوان ابزار مناسب برای مسئله مناسب دید، نه جایگزین کامل مهندسی نرمافزار.
BPMS یا سامانههای مدیریت فرایند کسبوکار برای مدلسازی، اجرا، پایش و بهینهسازی فرایندهای سازمانی استفاده میشوند. در بسیاری از سازمانها، مسئله اصلی فقط داده یا کد نیست؛ بلکه هماهنگی مراحل، مسئولیتها، تأییدها، SLAها و گردش کارهاست. BPMS دقیقاً برای مدیریت این سطح از پیچیدگی مفید است.
برای مثال، فرایند اعطای وام ممکن است شامل ثبت درخواست، ارزیابی اولیه، بررسی مدارک، اعتبارسنجی، تأیید مدیر، قرارداد و پرداخت باشد. اگر این مراحل فقط در ذهن افراد یا در چند سیستم پراکنده باشند، کنترل و شفافیت پایین میآید. اما BPMS میتواند این فرایند را رسمی، قابل ردیابی و قابل بهینهسازی کند. ابزارهایی مانند Camunda، Bizagi و Appian در این حوزه شناختهشدهاند.
هوش مصنوعی دیگر فقط یک قابلیت جانبی برای محصول نیست. امروز هم در ساخت نرمافزار از AI استفاده میشود و هم خود سیستمهای AI نیاز به مهندسی نرمافزار جدی دارند. به همین دلیل، سه مفهوم AI4SE، SE4AI و MLOps اهمیت زیادی پیدا کردهاند. این سه حوزه به هم نزدیکاند، اما نقش یکسانی ندارند.
AI4SE یعنی استفاده از هوش مصنوعی برای بهبود فرایندهای مهندسی نرمافزار. این میتواند شامل تولید کد، پیشنهاد تکمیل خودکار، ساخت تست، خلاصهسازی مستندات، تحلیل لاگ، یافتن ناهنجاری، بررسی pull request و حتی کمک در طراحی باشد. در اینجا AI ابزار کمکی مهندس نرمافزار است.
در تیمهای حرفهای، AI4SE میتواند سرعت و کیفیت را همزمان بالا ببرد، بهشرط آنکه بهدرستی استفاده شود. یعنی خروجی AI نباید بدون بررسی وارد تولید شود، بلکه باید مانند یک دستیار توانمند در کنار توسعهدهنده قرار گیرد. در بانکداری یا سامانههای حساس، این کنترل حتی مهمتر است، چون خطاهای کوچک هم میتوانند اثرات بزرگ داشته باشند.
SE4AI برعکس AI4SE است. اینجا مسئله این نیست که AI به مهندسی نرمافزار کمک کند، بلکه این است که چگونه برای خود سامانههای مبتنی بر AI مهندسی نرمافزار درست انجام دهیم. وقتی یک مدل یادگیری ماشین قرار است در یک سامانه واقعی تصمیم بگیرد، دیگر فقط دقت مدل مهم نیست. موضوعاتی مثل نسخهبندی مدل، مانیتورینگ، fallback، explainability، کنترل drift، امنیت، تستپذیری و قابلیت استقرار نیز حیاتی میشوند.
برای مثال، اگر یک مدل کشف تقلب در تراکنشهای بانکی ناگهان رفتار غیرمنتظره نشان دهد، باید مشخص باشد چه نسخهای فعال است، چه دادهای دیده، چگونه پایش میشود، و در صورت بروز مشکل سیستم به چه حالت امنی برمیگردد. SE4AI یعنی وارد کردن انضباط مهندسی نرمافزار به جهان سیستمهای هوش مصنوعی.
MLOps مجموعهای از روشها و ابزارها برای عملیاتیسازی چرخه عمر مدلهای یادگیری ماشین است. همانطور که DevOps تلاش میکند فاصله توسعه و عملیات را در نرمافزار کم کند، MLOps نیز فاصله بین ساخت مدل، استقرار، پایش و بهروزرسانی آن را کاهش میدهد. این حوزه شامل pipelineهای داده، آموزش مدل، ارزیابی، ثبت artifactها، استقرار، مانیتورینگ عملکرد، drift detection و retraining است.
در یک سامانه بانکی، اگر مدلی برای امتیازدهی اعتباری یا کشف تقلب داشته باشیم، بدون MLOps نگهداری آن در محیط واقعی بسیار دشوار خواهد بود. مدلها با گذر زمان کهنه میشوند، رفتار داده عوض میشود و نیاز به کنترل مداوم وجود دارد. MLOps کمک میکند این چرخه بهصورت استاندارد، قابل تکرار و قابل اعتماد مدیریت شود.

تقریباً هیچ سازمان جدیای وجود ندارد که برای همیشه روی یک سیستم ثابت بماند. نرمافزارها عوض میشوند، معماریها تکامل پیدا میکنند، فناوریها منسوخ میشوند و نیازهای کسبوکار تغییر میکند. در این میان، یکی از سختترین و حساسترین کارها Data Migration است. مهاجرت داده فقط انتقال چند رکورد از یک پایگاه داده به پایگاه داده دیگر نیست؛ بلکه انتقال یک دارایی حیاتی کسبوکار از یک جهان معنایی و فنی به جهان جدید است.
در مهاجرت داده، باید درباره mapping، پاکسازی داده، تبدیل فرمت، کنترل کیفیت، reconciliation، migration strategy، rollback plan و cutover فکر کرد. در صنایع حساسی مثل بانکداری، بیمه و سلامت، این موضوع حتی حساستر است، چون کوچکترین مغایرت میتواند به خطاهای عملیاتی، مالی یا حقوقی منجر شود. برای همین، مهاجرت داده نیازمند dry run، اعتبارسنجی چندمرحلهای، پایش، و گاهی مهاجرت تدریجی است.
اگر بخواهیم صادق باشیم، Data Migration فقط یک فعالیت فنی نیست؛ ترکیبی از مهندسی، تحلیل، مدیریت ریسک و شناخت عمیق داده است. هرچه سیستم قدیمیتر و دادهها آلودهتر یا مبهمتر باشند، اهمیت طراحی درست مهاجرت بیشتر میشود.
