مهندسی آشوب یا Chaos Engineering در واقع مثل یک واکسن برای سیستمهای نرمافزاری
است؛ یعنی ما عمداً مقدار کمی از یک عامل بیماریزا (خطا یا خرابی) را به سیستم
تزریق میکنیم تا مقاومت و ایمنی آن را در برابر حوادث واقعی و بزرگتر بسنجیم و
تقویت کنیم.
از آنجایی که نمیتوان جلوی همه خرابیهای احتمالی (مثل قطع شدن ناگهانی برق یک مرکز داده یا کندی شبکه) را گرفت، باید مطمئن شویم که سیستم ما میتواند این ضربات را تحمل کند و از پا نیفتد.
در تستهای معمولی ما میدانیم چه چیزی را بررسی میکنیم، اما در مهندسی آشوب ما به دنبال ناشناختهها هستیم. فرآیند آن معمولاً شامل چهار مرحله ساده است:
ابتدا مشخص میکنیم که وقتی همهچیز مرتب است، سیستم چه رفتاری دارد (مثلاً در هر ثانیه ۱۰۰۰ نفر موفق به خرید میشوند)، فرض میکنیم که "اگر فلان سرور ناگهان خاموش شود، سیستم همچنان به کار عادی خود ادامه خواهد داد." سپس در یک محیط کنترلشده، واقعاً آن سرور را خاموش میکنیم یا سرعت شبکه را عمداً کم میکنیم. اگر سیستم طبق فرضیه ما پایدار ماند، اعتماد ما به آن بیشتر میشود. اما اگر سیستم به هم ریخت، ما یک نقطه ضعف پنهان پیدا کردهایم که باید قبل از
وقوع حادثه واقعی، آن را تعمیر کنیم.
البته ما هرگز طوری آزمایش نمیکنیم که کل سیستم از کار بیفتد و کاربران شاکی شوند؛ آزمایشها را از ابعاد بسیار کوچک شروع میکنیم.
شرکتهایی مانند نتفلیکس از این رویکرد استفاده میکنند تا مطمئن شوند خدماتشان حتی در شرایط بحرانی نیز در دسترس باقی میماند.
در معماری میکروسرویس، یک صفحه موبایل ممکن است به دادههایی از ۱۰ سرویس مختلف نیاز داشته باشد. اگر اپلیکیشن بخواهد مستقیماً با همه آنها صحبت کند، باید ۱۰ درخواست HTTP جداگانه بفرستد که باعث کندی شدید و مصرف باتری میشود. سرویس BFF یک درخواست از سمت کلاینت میگیرد، خودش چندین فرایند فراخوانی به سرویسهای پاییندستی انجام میدهد و نتایج را در قالب یک پاسخ واحد به کلاینت برمیگرداند.
مثلا کلاینت موبایل ممکن است فقط ۳ فیلد از یک شیء بزرگ با ۵۰ فیلد را نیاز داشته باشد. BFF وظیفه فیلتر کردن و پاکسازی دادههای اضافی را دارد تا حجم ترافیک مصرفی به حداقل برسد.
معایب:
· ممکن است منطقهای مشابهی در BFF وب و BFF موبایل تکرار شوند و مشکل تکرار کد را داشته باشیم.
· اضافه شدن یک لایه جدید یعنی یک لایه شبکه بیشتر در مسیر درخواستها که اگر درست مدیریت نشود، میتواند تاخیر ایجاد کند.
· نقطه شکست؛ اگر سرویس BFF از کار بیفتد، کل اپلیکیشن مرتبط با آن نیز از کار میافتد
استفاده از قدرت هوش مصنوعی برای کمک به برنامهنویسها تا بتوانند نرمافزارهای بهتر، سریعتر و با اشتباهات کمتری بسازند، یعنی هوش مصنوعی به کمک برنامهنویس میآید تا نرمافزار بسازد.
کمک های AI به برنامه نویس:
· هوش مصنوعی با نگاه کردن به میلیونها خط کد دیگر، به برنامهنویس پیشنهاد میدهد که چه کدی بنویسد تا وقتش برای کارهای تکراری تلف نشود.
· هوش مصنوعی کدها را اسکن کرده و قبل از اینکه برنامه به دست کاربر برسد، نقاط ضعف یا اشتباهات را پیدا کرده و حتی گاهی خودش آنها را تعمیر میکند.
· هوش مصنوعی میتواند با بررسی پروژههای قبلی، پیشبینی کند که اتمام کار چقدر زمان میبرد یا احتمال بروز مشکل در کدام بخشها بیشتر است.
· هوش مصنوعی میتواند به طور خودکار «سناریوهای آزمایش» طراحی کند و برنامه را در شرایط مختلف امتحان کند تا از سلامت آن مطمئن شود.
SE4AI یعنی استفاده از اصول مهندسی برای اینکه هوش مصنوعی فقط یک ایده باقی نماند و تبدیل به سیستمی شود که ما هر روز بدون ترس از خراب شدن، از آن استفاده کنیم.
در نرمافزارهای معمولی، برنامهنویس دستورات صریحی مینویسد (مثلاً: اگر کاربر روی دکمه کلیک کرد، رنگ صفحه تیره شود). اما در سیستمهای هوش مصنوعی، ما دستور نمیدهیم، بلکه به سیستم داده میدهیم تا خودش یاد بگیرد. این موضوع چالشهای جدیدی ایجاد میکند که SE4AI به آنها پاسخ میدهد؛ اینکه چطور مطمئن شویم هوش مصنوعی اشتباه نمیکند، روشهایی بسازیم که سیستم خودش را بهروز نگه دارد و از دقتش کاسته نشود، یا اینکه چطور کاری کنیم که وقتی به جای ۱۰ نفر، ۱۰ میلیون نفر همزمان از هوش مصنوعی استفاده میکنند، سیستم از کار نیفتد.
بزرگترین تفاوت نرمافزارهای معمولی با هوش مصنوعی در نحوه خراب شدن آنهاست؛
نرمافزار معمولی اگر خراب شود، معمولاً «هنگ» میکند یا یک پیام خطا میدهد.
در هوش مصنوعی ممکن است سیستم کاملاً فعال باشد، اما به مرور زمان «خنگ» شود و جوابهای اشتباه بدهد. مثلاً سلیقه مردم عوض شود ولی مدل همچنان پیشنهادات قدیمی بدهد (Drift یا رانش). MLOps اینجا مثل یک ناظر تماموقت بر مدل نظارت میکند تا به محض اینکه دقت آن ذرهای کم شد، متوجه شود و آن را درست کند.
کارهای اصلی MLOps:
· کار آموزش مدل باید به صورت خودکار انجام شود.
· اگر مدل اشتباه کرد، باید بتوانیم دقیقاً بفهمیم با کدام دادهها و کدام تنظیمات ساخته شده بود تا به عقب برگردیم و مشکل را حل کنیم.
· مدل باید مرتباً با دادههای جدید دوباره آموزش ببیند تا همیشه بهروز بماند.
MLOps در واقع نقطه تلاقی سه تخصص است ۱. یادگیری ماشین: برای ساختن مغز اصلی. ۲. مهندسی داده: برای رساندن دادههای باکیفیت به این مغز ۳. DevOps: برای ساختن زیرساخت و ابزارهایی که این سیستم روی آن اجرا میشود.
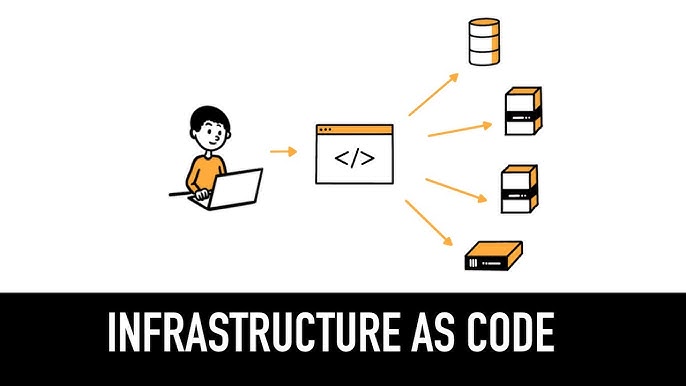
مدیریت و راهاندازی منابع دنیای دیجیتال (مثل سرورها، شبکهها و پایگاههای داده) از طریق فایلهای متنی و کدهای قابل خواندن برای ماشین است.
مزایا:
· کاری که قبلاً ممکن بود روزها یا هفتهها طول بکشد، حالا با اجرای یک کد در عرض چند دقیقه انجام میشود.
· چون انسان دیگر به صورت دستی تنظیمات را تغییر نمیدهد، احتمال خطاهای تصادفی بسیار کم میشود.
· اگر تغییری در کد بدهید و متوجه شوید اشتباه بوده، میتوانید خیلی سریع به نسخه قبلی کد برگردید و سیستم را به حالت سالم قبلی برگردانید.
دو روش اصلی برای نوشتن این کدها وجود دارد:
روش اعلامی (Declarative): شما میگویید چه چیزی میخواهید (مثلاً: من ۵ سرور میخواهم) و ابزار خودش میفهمد که چطور آن را بسازد. ابزارهایی مثل Terraform اینگونه عمل میکنند.
روش امری (Imperative): شما میگویید چطور کار انجام شود (مثلاً: اول این پوشه را بساز، بعد این برنامه را نصب کن). ابزارهایی مثلAnsible بیشتر در این دسته قرار میگیرند.
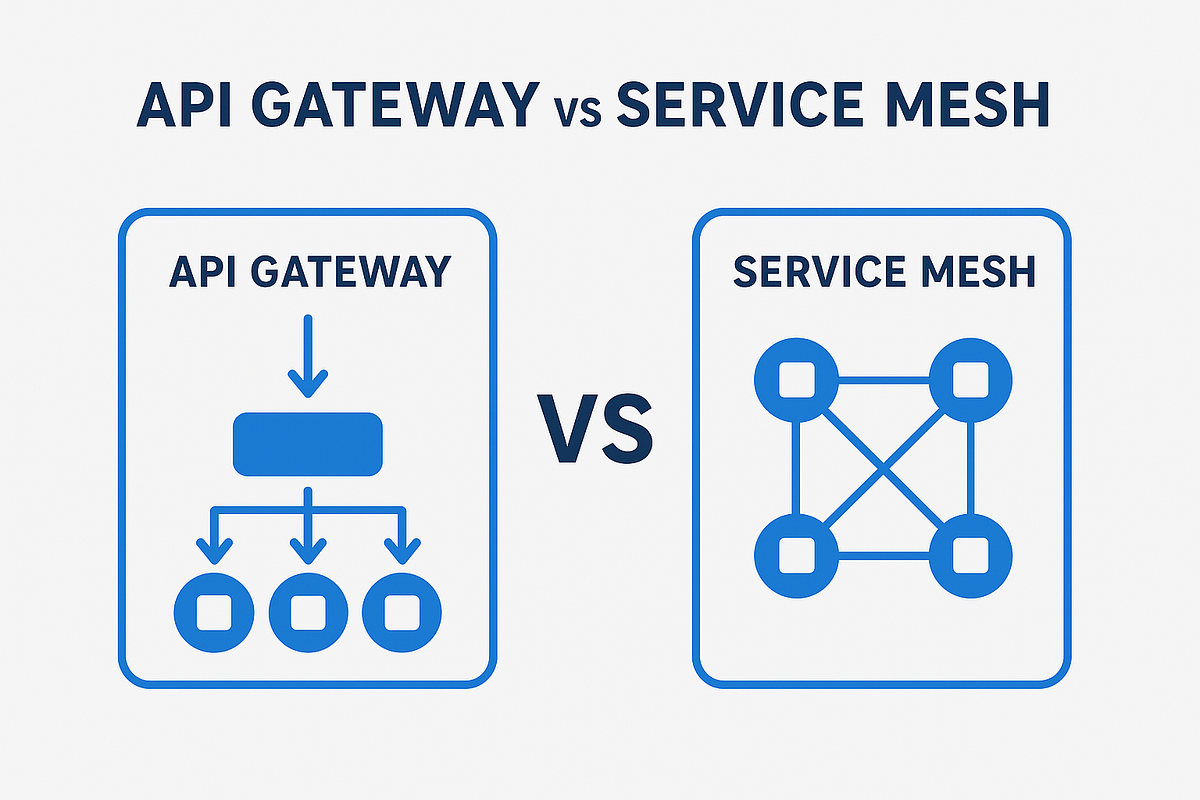
API Gateway دروازه ورود درخواستهای کاربران به مجموعه سرویسها است. این لایه وظایفی مانند احراز هویت، مدیریت دسترسی، محدودسازی درخواستها و مسیریابی ترافیک را انجام میدهد.
Service Mesh برای مدیریت ارتباطات داخلی میان سرویسهای یک معماری میکروسرویسی طراحی شده است. Service Mesh قابلیتهایی مانند رمزنگاری ارتباطات، توازن بار و مدیریت خطا را فراهم میکند.
API Gateway بیشتر با کاربران و کلاینتهای خارجی سروکار دارد، در حالی که Service Mesh بر ارتباطات داخلی سرویسها تمرکز میکند. استفاده همزمان از این دو فناوری باعث افزایش امنیت، کنترل بهتر ترافیک و سادهتر شدن مدیریت سامانههای بزرگ و توزیعشده میشود.
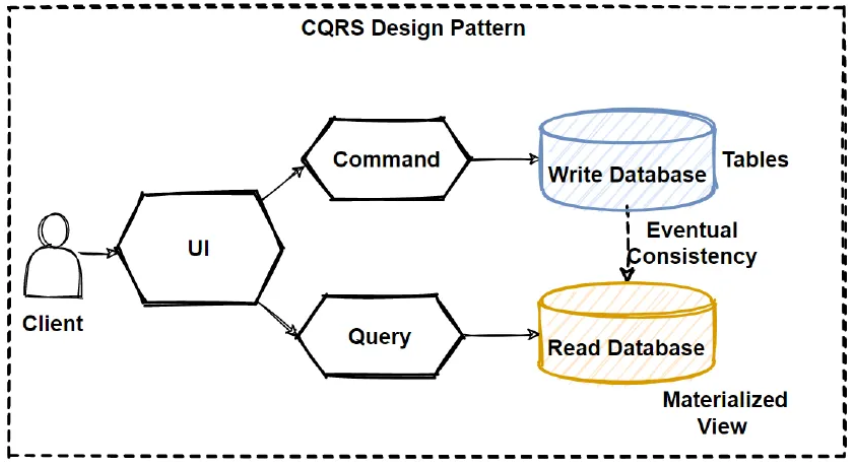
جداسازی مسئولیت فرمان یا Command و پرسوجو یا Query است. در واقع این یک الگوی طراحی در دنیای نرمافزار است که میگوید مدلی که برای تغییر دادن اطلاعات استفاده میکنیم، باید از مدلی که برای خواندن اطلاعات استفاده میکنیم، کاملاً جدا باشد.
اجزای اصلی CQRS
فرمانها (Commands): درخواستهایی هستند که میخواهند چیزی را در سیستم تغییر دهند. فرمانها معمولاً جوابی به شما بر نمیگردانند، فقط انجام میشوند
پرسوجوها (Queries): اینها فقط سوال هستند. شما میپرسید؛ پرسوجوها اجازه ندارند هیچ چیزی را در سیستم تغییر دهند، آنها فقط اطلاعات را به شما نشان میدهند.
در بیشتر برنامهها (مثل اینستاگرام یا دیجیکالا)، تعداد افرادی که اطلاعات را میبینند (Read) هزاران برابر بیشتر از افرادی است که چیزی مینویسند .(Write) با CQRS میتوانید بخش «دیدن اطلاعات» را به شدت تقویت کنید بدون اینکه نگران بخش «ثبت اطلاعات» باشید.
EDA روشی برای طراحی سیستمهای کامپیوتری است که در آن اجزای مختلف برنامه از طریق اعلام وقایع یا خبرها با هم ارتباط برقرار میکنند. هر زمان اتفاقی در سیستم رخ دهد، یک رویداد منتشر میشود و سرویسهای دیگر میتوانند به آن واکنش نشان دهند. این روش وابستگی مستقیم بین سرویسها را کاهش میدهد و باعث افزایش انعطافپذیری میشود.
بزرگترین چالش این است که اطلاعات در کل سیستم به صورت تدریجی بهروز میشوند یعنی در یک فاصله زمانی کوتاه ممکن است اطلاعات بخشهای مختلف کاملاً با هم هماهنگ نباشند، اما سیستم تضمین میکند که در نهایت همه به یک وضعیت یکسان و درست برسند.
یک روش مدرن برای اجرای برنامههای کامپیوتری در فضای ابری است که در آن، مدیریت تمام کارهای سخت و پیچیده زیرساختی (مثل تهیه کامپیوترها، تنظیمات شبکه و امنیت) به عهده شرکت ارائهدهنده (مثل آمازون یا گوگل) است و توسعهدهنده فقط بر نوشتن منطق برنامه تمرکز میکند.
در این روش شما فقط به ازای مدت زمانی که کدتان در حال اجراست پول پرداخت میکنید. البته چون کد شما وقتی استفاده نمیشود در حالت «خواب» است، اولین نفری که بعد از مدتی طولانی از آن استفاده میکند، ممکن است با چند ثانیه تاخیر مواجه شود تا سیستم بیدار شود و راه بیفتد. همچنین محدودیتهایی مانند وابستگی به ارائهدهنده سرویس و پیچیدگی در اشکالزدایی نیز در این روش وجود دارد.
رویکرد API-first یعنی قبل از اینکه حتی یک خط کد برای ظاهر برنامه یا پایگاه داده بنویسید، ابتدا مشخص میکنید که این برنامه قرار است چطور با دنیای بیرون ارتباط برقرار کند. تمام بخشهای دیگر مثل وبسایت، اپلیکیشن موبایل یا ساعت هوشمند، همگی بر پایه این API ساخته میشوند.
در واقع API-First یعنی اول راه ارتباطی را طراحی کنیم تا مطمئن شویم محصول ما منعطف، قابل گسترش و آماده وصل شدن به هر تکنولوژی جدیدی در آینده است.
این رویکرد همکاری بین تیمهای مختلف را آسانتر میکند و امکان توسعه موازی بخشهای مختلف پروژه را فراهم میسازد. همچنین کیفیت مستندسازی و قابلیت استفاده مجدد از سرویسها افزایش مییابد.
هدف اصلی این روش این است که ساختار نرمافزار دقیقاً بازتابدهنده مدل کسبوکار باشد، نه صرفاً مجموعهای از کدهای فنی.
Domain یا قلمرو همان حوزه فعالیتی است که نرمافزار برای آن ساخته میشود (مثل بانکداری، فروشگاه یا هواپیمایی). در DDD، منطق کسبوکار قلب تپنده پروژه است و همه چیز باید حول محور آن باشد. یعنی بهجای اینکه بیزنس را مجبور کنیم خودش را با تکنولوژی وفق دهد، تکنولوژی را طوری طراحی کنیم که کاملاً در خدمت مفاهیم و نیازهای واقعی آن کسبوکار باشد.
یکی از بزرگترین مشکلات این است که برنامهنویسها با زبان فنی (مثل دیتابیس و کلاس) حرف میزنند و مدیران با زبان بازار. DDD اصرار دارد که همه تیم باید از یک زبان واحد و مشترک استفاده کنند؛ یعنی همان واژههایی که پزشک در بیمارستان به کار میبرد، باید عیناً در کدهای برنامه هم دیده شود تا سوءتفاهمی پیش نیاید.
که به آن Ports and Adapters هم میگویند، روشی برای طراحی نرمافزار است که هدف اصلیاش جدا کردن «منطق اصلی کسبوکار» از ابزارهای جانبی و تکنولوژیهای بیرونی است.
هسته مرکزی شامل تمام قوانین و منطق کسبوکار است. این هسته کاملاً «مستقل» است؛ یعنی اصلاً نمیداند وبسایت چیست یا دیتابیس چطور کار میکند و نباید به هیچ تکنولوژی خاصی وابسته باشد.
تکنولوژیها (مثل فریمورکهای وب) دائم عوض میشوند، اما قوانین کسبوکار شما ثابت میمانند. با این معماری، برنامه شما برای دههها قابل استفاده و بهروزرسانی باقی میماند.
این معماری یعنی کشیدن یک مرز محکم بین آنچه برنامه انجام میدهد و چگونگی ارتباط آن با دنیای بیرون.
در این روش به جای اینکه فقط آخرین وضعیت یک چیز را ذخیره کنید، تمام اتفاقاتی که تا الان افتاده را به ترتیب یادداشت میکنید.
روشهای قدیمی فقط وضعیت فعلی را میگویند، اما Event Sourcing دلیل و تاریخچه رسیدن به آن وضعیت را هم ذخیره میکند
چون تمام تاریخچه را دارید، میتوانید دقیقاً بفهمید که مثلاً «سه شنبه هفته پیش ساعت ۴ عصر» وضعیت سیستم چطور بوده است. این کار در سیستمهای معمولی تقریباً غیرممکن است.
اگر برنامهنویس بخواهد بفهمد چرا یک خطا رخ داده، میتواند تمام اتفاقاتی که در دنیای واقعی افتاده را دوباره در کامپیوتر خودش Replayکند تا دقیقاً همان لحظه خطا را ببیند.
چون تمام جزئیات ذخیره شده، شما میتوانید سالها بعد گزارشهایی بگیرید که در روز اول اصلاً به فکرتان نرسیده بود؛ چون چیزی را دور نریختهاید.
هرچند این رویکرد مزایای زیادی دارد، اما مدیریت حجم رویدادها و افزایش پیچیدگی سیستم از چالشهای اصلی آن محسوب میشود.
پلتفرمهای Low-code و No-code ابزارهایی هستند که امکان توسعه نرمافزار را با حداقل یا بدون نیاز به برنامهنویسی فراهم میکنند. پلتفرمهای No-code معمولاً برای کاربران تجاری طراحی شدهاند، در حالی که Low-code امکان افزودن کد سفارشی را نیز فراهم میکند. این پلتفرمها قدرت ساختن را از انحصار متخصصان خارج کرده و به دست همه آدمها دادهاند تا هر ایدهای را به سرعت به یک اپلیکیشن تبدیل کنند.
با این ابزارها میتوان ۵۰ تا ۷۰ درصد سریعتر از روشهای قدیمی نرمافزار تولید کرد، چون زمان کمتری صرف میشود، هزینههای ساخت برنامه هم تا ۶۰ درصد کاهش مییابد، در سال ۲۰۲۶، این پلتفرمها به هوش مصنوعی مجهز شدهاند؛ یعنی شما فقط به زبان فارسی یا انگلیسی میگویید «یک برنامه برای مدیریت مرخصیها میخواهم» و پلتفرم خودش بخشهای اصلی را برایتان میسازد.
این فناوریها برای ساخت نمونه اولیه، اتوماسیون فرآیندها و برنامههای ساده بسیار مفید هستند. با این حال در پروژههای بسیار پیچیده ممکن است محدودیتهایی از نظر انعطافپذیری و سفارشیسازی داشته باشند.
سیستمهای مدیریت فرآیندهای کسبوکار ابزارهایی هستند که برای مدلسازی، اجرا، پایش و بهینهسازی فرآیندهای سازمانی استفاده میشوند. این سیستمها به سازمانها کمک میکنند فعالیتهای مختلف خود را بهصورت استاندارد و خودکار مدیریت کنند.
مزیت اصلی این فناوری افزایش بهرهوری، کاهش خطاهای انسانی و شفافیت بیشتر در فرآیندها است. همچنین امکان تحلیل عملکرد و شناسایی گلوگاههای سازمانی را فراهم میکند.
امروزه این سیستمها در حال تبدیل شدن به سیستمهای هوشمند (iBPMS) هستند. یعنی از هوش مصنوعی استفاده میکنند تا نه تنها کارها را جابهجا کنند، بلکه خودشان دادهها را تحلیل کرده و پیشنهاد بدهند که چطور کارها را حتی بهتر و سریعتر انجام دهیم.

در دنیای نرمافزار، گاهی بخشهای مختلف باید با هم حرف بزنند. صف پیام باعث میشود که وابستگی مستقیم از بین برود؛ سیستم فرستنده نیازی ندارد بداند گیرنده کیست یا در چه وضعیتی است؛ فقط پیام را میفرستد و به کارش ادامه میدهد. همچنین اگر بخش گیرنده برای مدتی خراب شود، پیامها در صف ذخیره میمانند و از بین نمیروند تا وقتی که گیرنده دوباره وصل شود و اگر ناگهان هزاران درخواست به سیستم برسد، صف مثل یک ضربهگیر عمل میکند تا سیستم گیرنده زیر فشار له نشود.
سیستم RabbitMQ مثل یک پستچی هوشمند است. پیام را میگیرد، دقیقاً میداند به کدام صندوق برساند و به محض اینکه گیرنده پیام را خواند، RabbitMQ آن را پاک میکند. این ابزار برای کارهای اداری منظم و تراکنشهای بانکی که دقت در آنها مهم است، خوب است.
کافکا بیشتر شبیه یک لیست طولانی یا دفتر Log است که هیچچیز در آن به این راحتی پاک نمیشود. پیامها پشت سر هم نوشته میشوند و گیرندههای مختلف میتوانند هر زمان که خواستند، بروند و از هر جای لیست که دوست داشتند مطالعه کنند (حتی میتوانند به عقب برگردند و دوباره بخوانند). کافکا برای جابهجایی حجم عظیمی از دادهها (مثلاً ثبت تمام کلیکهای کاربران یک وبسایت بزرگ) طراحی شده است.
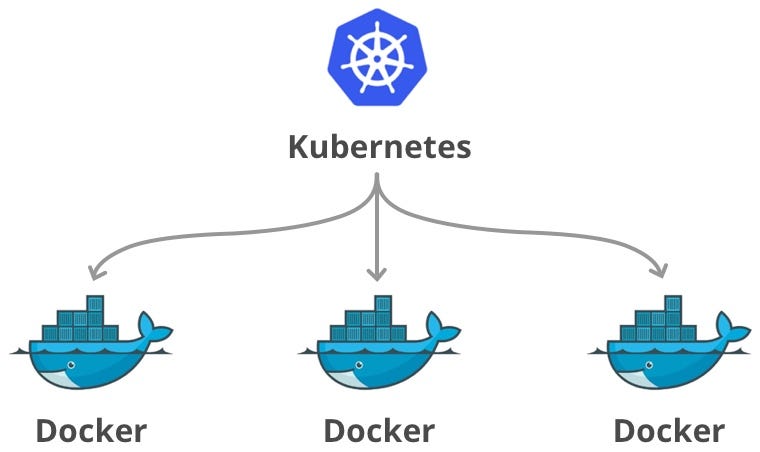
در گذشته، وقتی برنامهنویسان نرمافزاری میساختند، ممکن بود روی کامپیوتر خودشان عالی کار کند اما روی سرور اصلی شرکت خراب شود؛ چون نسخهی ویندوز یا کتابخانههای آن متفاوت بود. کانتینرها روشی برای بستهبندی نرمافزار همراه با تمام وابستگیهای آن هستند تا برنامه در محیطهای مختلف بهصورت یکسان اجرا شود.
داکر معروفترین ابزاری است که به ما کمک میکند این کانتینرها را بسازیم.
وقتی شرکت شما بزرگ میشود، دیگر با یک یا دو کانتینر طرف نیستید؛ ممکن است هزاران جعبه داشته باشید که روی صدها سرور مختلف در حال اجرا هستند. اینجا مدیریت دستی غیرممکن است. شما به سیستمی نیاز دارید که بداند کدام جعبه را روی کدام سرور بگذارد تا از منابع مثل CPU و RAM بهترین استفاده شود و اگر یک جعبه خراب شد، سریع آن را دور بیندازد و یک نسخهی جدید جایگزین کند همچنین اگر مشتریان زیاد شدند، خودکار تعداد جعبهها را زیاد کند.
کوبرنتیز قدرتمندترین و محبوبترین سیستم برای انجام همان "هماهنگسازی" است که در بالا گفته شد. این سیستم را گوگل بر اساس تجربههای عظیم خودش ساخته است.
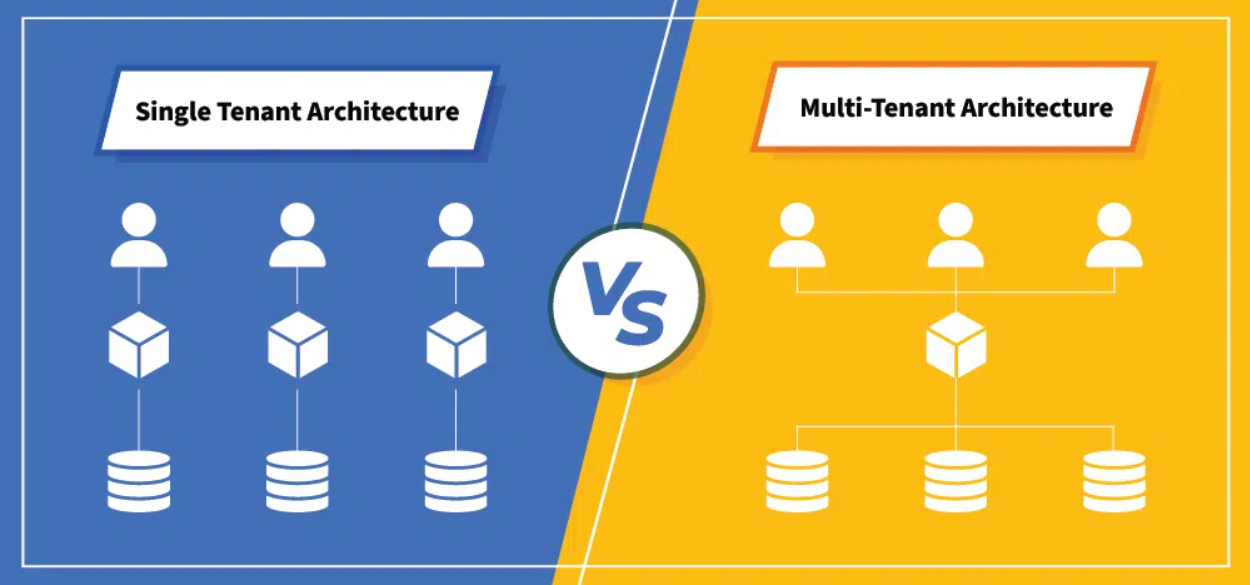
در این مدل، تنها یک نسخه از نرمافزار روی سرورها در حال اجرا است، اما این نسخه به صورت همزمان به چندین مشتری (که به آنها مستاجر یا Tenant میگوییم) سرویس میدهد اما دادههای هر مشتری کاملاً از دیگران جدا و مخفی است؛ یعنی هیچ مشتریای نمیتواند اطلاعات مشتری دیگر را ببیند.
در این مدل چون همه مشتریان از یک زیرساخت استفاده میکنند، هزینههای نگهداری و سختافزار بین همه تقسیم میشود، وقتی شرکت سازنده بخواهد ویژگی جدیدی اضافه کند، فقط یک بار سیستم را آپدیت میکند و همه مشتریان بلافاصله به آن دسترسی پیدا میکنند، اضافه کردن یک مشتری جدید به سیستم، به سادگیِ دادنِ کلیدِ یک واحدِ خالی به یک مستاجر جدید است.
شرکتها بسته به حساسیت کارشان، از روشهای مختلفی برای تقسیم منابع استفاده میکنند:
مدل استخر (Pool): مثل یک خوابگاه است. همه چیز (سرور، بانک اطلاعاتی و کدها) کاملاً مشترک است. این روش ارزانترین حالت است و مدیریت آن بسیار ساده است .
مدل سیلو (Silo): مثل خانههای سازمانی جداگانه است. هر مشتری نسخه اختصاصی و بانک اطلاعاتی خودش را دارد. این مدل برای جاهایی که امنیت و حریم خصوصی بسیار حیاتی است (مثل بانکها) استفاده میشود.
مدل پل (Bridge): ترکیبی از دو مدل بالا است؛ مثلاً بخش محاسبات مشترک است اما بانک اطلاعاتی هر مشتری جداست.
مهاجرت داده فرآیند انتقال دادهها از یک سیستم، پایگاه داده یا محیط عملیاتی به محیطی دیگر است. این فرآیند معمولاً هنگام ارتقای سامانهها، تغییر فناوری یا انتقال به فضای ابری انجام میشود.
مراحل انجام کار:
· قبل از هر کاری باید بدانید چه چیزهایی دارید. در این مرحله مشخص میکنید که مثلاً "نام مشتری" در سیستم قدیمی، دقیقاً در کدام بخش از سیستم جدید قرار بگیرد.
· قبل از انتقال، دادههای تکراری، ناقص یا اشتباه پاک میشوند تا فضای سیستم جدید هدر نرود.
· مرحله بعد شامل سه کار بیرون کشیدن داده از جای قبلی، تغییر فرمت آن برای سیستم جدید و ریختن آن در مقصد نهایی است که به آن ETLهم میگویند.
· بعد از تمام شدن کار، باید مطمئن شوید که چیزی در راه گم نشده یا آسیب ندیده است. مثلاً تعداد رکوردها را میشمارند تا با مبدأ یکی باشد.
اطلاعات در حین جابهجایی بسیار حساس هستند و ممکن است دزدیده شوند؛ پس باید حتماً رمزگذاری شوند.