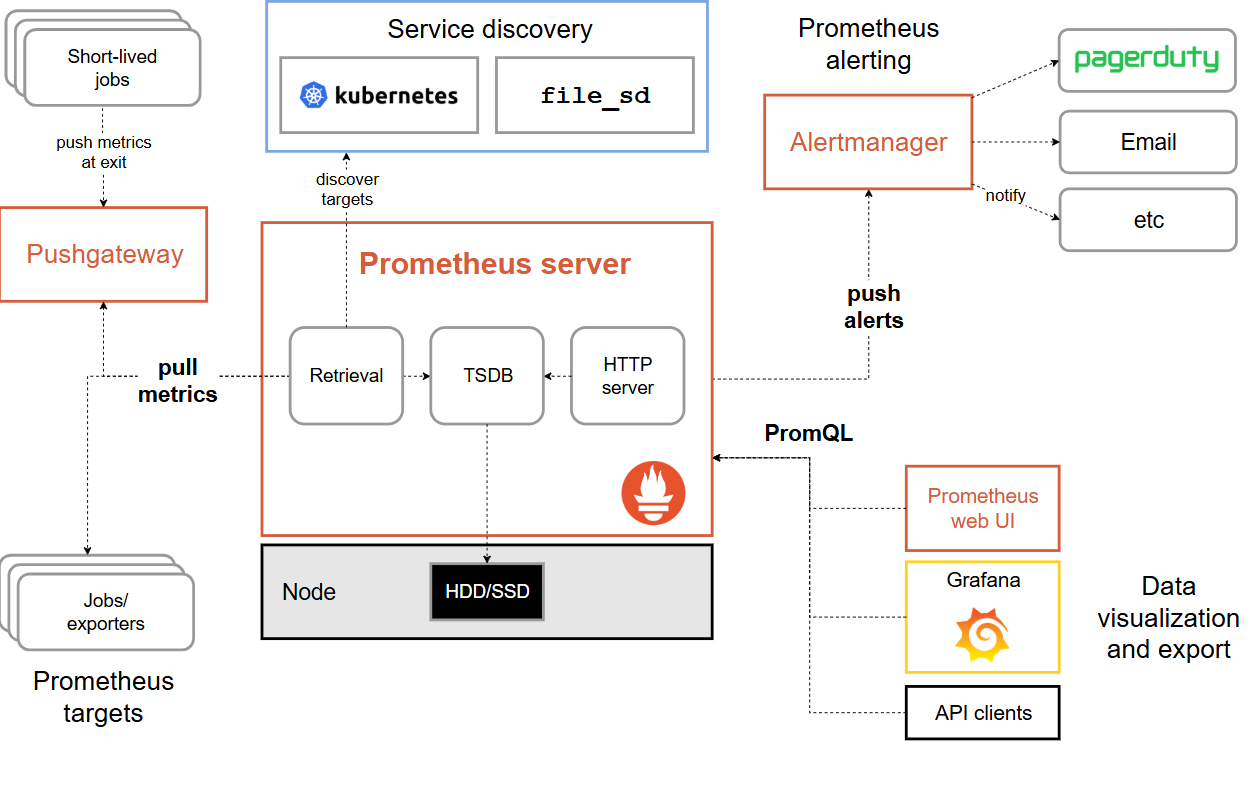
معماری Prometheus:
ایدهی اولیهی Prometheus از پروژهای به نام Borgmon اومد که بعداً توسط چند نفر از DevOps Engineerهای شرکت SoundCloud توسعه داده شد. در سال ۲۰۱۶، Prometheus دومین پروژهای بود که وارد CNCF شد، و در نهایت به عنوان ابزار defacto در مانیتورینگ Kubernetes شناخته شد.
Prometheus معماری بسیار سادهای داره و یکی از اصلیترین نقاط قوتش، پایگاهدادهی time-series بسیار قدرتمندشه.
انواع مدلهای مانیتورینگ در دنیا:
دو مدل اصلی داریم:
روش Pull-based:
در این مدل، Prometheus خودش میره و متریکها رو از سرویسها یا همون targets جمع میکنه.
روش Push-based:
در این مدل، خود سرویسها متریکها رو push میکنن به سمت ابزار مانیتورینگ . ایرادی که به این روش وارده اینه که اگه تعداد سرویسها (targets) زیاد بشه، ممکنه باعث Crash شدن سرویس مانیتورینگ بشه.
از منظر دیگه، روشهای مانیتورینگ یا Agent-based هستند یا Agent-less.
در روشهای سنتی مانیتورینگ (مثل Zabbix)، معمولاً روشها Push-based و Agent-based هستند. یعنی روی هر نود یک Agent نصب میشه که متریکها رو جمعآوری و ارسال میکنه.اما این روش برای دنیای Cloud Native مناسب نیست.
در دنیای Cloud Native، ما به دنبال مانیتورینگ Pull-based و Agent-less هستیم. Prometheus دقیقاً چنین روشی رو پیاده میکنه: با یک HTTP Request به سمت target میره، متریکها رو scrape میکنه و روی خودش لود میکنه.
سرویس Prometheus شامل سه کامپوننت اصلیه:
دیتابیس TSDB (Time-Series Database):
سرویس Prometheus از پایگاهدادهی TSDB خودش استفاده میکنه به نام Prometheus TSDB. کل مزیت Prometheus به این پایگاهدادهی تخصصی برای متریکهاست؛ در حالی که مثلاً Zabbix دادهها رو در پایگاهدادهی Relational ذخیره میکنه.
کامپوننت HTTP Server:
دو وظیفه اصلی داره: یک رابط کاربری تحت وب (نسبتاً ساده) برای مشاهده وضعیت کلی Prometheus.
ارائهی یکسری RESTful API برای اجرای کوئری روی پایگاهداده TSDB.
کامپوننت Retrieval:
وظیفهش گرفتن متریکها از targets (همون Pull) و نوشتنشون توی TSDB هست.همچنین میتونه یکسری پردازش اولیه مثل Label زدن انجام بده. وقتی متریکها رو میگیره، زمان محلی خودش (برحسب epoch time) رو هم روی متریک ثبت میکنه.
چند کلیدواژهی مهم در Prometheus:
الف) Metric:
هر متریک یک اسم داره، یکسری label داره و در نهایت یک مقدار.
مثلاً: http_response_time
Labelها برای تفکیک متریکها بین سرویسها یا منابع مختلف به کار میرن. مثلاً اگر متریکی به اسم cpu داریم، میتونیم با label مثل node=5 مشخص کنیم که مربوط به کدوم نود هست. به ازای هر ترکیب متفاوت از labelها، یک Time Series جداگانه ایجاد میشه.
ب) Target:
همون Endpointهایی هستن که Prometheus (یا دقیقتر بگیم: Retrieval )ازشون متریکها رو میگیره.
ج) Exporter:
بعضی از اپلیکیشنها خودشون بهصورت مستقیم متریک ندارن. Prometheus برای این موارد Exporterهایی داره که اطلاعات اون اپ رو میگیرن و به فرمت قابل فهم برای Prometheus تبدیل میکنن.
نکته: چیزی که توی labelها خیلی مهمه، تنوع (Diversity) labelهاست. چون به ازای هر label متفاوت، یک Time Series جدید ساخته میشه، باید در تعریف labelها دقت زیادی کرد تا حجم داده کنترل بشه.
کامپوننت Push Gateway:
فرض کنید اپلیکیشنی داریم که فقط میتونه متریکها رو Push کنه. Prometheus بهطور پیشفرض این سناریو رو ساپورت نمیکنه. برای این مورد، یک ابزار به نام Push Gateway وجود داره که متریکها رو از سرویسهای Pushکننده میگیره، نگهداری میکنه، و Prometheus بعداً خودش اونها رو Pull میکنه.
Data Sharding:
سرویس Prometheus قابلیت Data Sharding داره. یعنی میتونیم دادهها رو بین چند دیتابیس توزیع کنیم. مثلاً چند Prometheus مختلف راهاندازی کنیم که هرکدوم متریکهای خودش رو جمع کنه و در TSDB خودش بنویسه.
Visualization:
خود Prometheus ابزار قدرتمندی برای نمایش داده نداره. برای این کار از ابزارهایی مثل Grafana استفاده میشه. Grafana میتونه Prometheus رو به عنوان Data Source اضافه کنه.
سؤال مهم: چطور Grafana از Prometheus داده میخونه؟
از طریق زبان کوئری مخصوصی به نام PromQL. گرافانا کوئری رو به HTTP Server میفرسته و اون هم داده رو از TSDB برمیگردونه.
آلارمدهی (Alerting):
سرویس Prometheus قابلیت تعریف آلارم رو داره. مثلاً میتونی بگی: "اگه فلان متریک از مقدار X بیشتر شد، آلارم بده" اما Prometheus خودش آلارم رو ارسال نمیکنه. فقط میتونه از طریق Webhook آلارم رو بفرسته (یعنی یک HTTP POST به یک سرویس دیگه).
برای همین، Prometheus معمولاً آلارمها رو به یک سرویس دیگه به نام Alertmanager میفرسته.
سرویس Alertmanager این آلارمها رو مدیریت میکنه و میتونه از طریق ایمیل، Slack، PagerDuty و... ارسالشون کنه.
ذخیرهسازی بلندمدت (Long-term storage):
سرویس Prometheus بهطور پیشفرض برای نگهداری دادهی بلندمدت مناسب نیست. برای این کار، دادهها رو Downsampling میکنیم و از ابزارهای مکملی مثل Thanos استفاده میکنیم. Thanos میتونه دادههای Prometheus رو بخونه، فشردهسازی کنه.