نویسنده: زهرا گودآسیایی
درس: شبکههای پیچیده پویا
در سالهای اخیر، ظهور مدلهای زبانی و ابزارهای تولید خودکار کد باعث شده است که بخش قابلتوجهی از فرآیند توسعهی نرمافزار بهسمت اتوماسیون پیش برود. با وجود مزایای آشکار این مدلها در سرعت و بهرهوری، پرسش مهمی در سطح معماری بیپاسخ مانده است: آیا ساختار کدهای تولیدشده توسط هوش مصنوعی از نظر الگوهای وابستگی و تمرکز ماژولها، تفاوتهایی اساسی با کدهای انسانی دارد؟ و اگر چنین تفاوتهایی وجود داشته باشد، آیا میتواند به شکلگیری یا افزایش بدهی فنی، بهویژه بدهی فنی معماری منجر شود؟
در این پژوهش، ساختار وابستگی دو مجموعه کد (نسخهای نوشتهشده توسط انسان و نسخهای تولیدشده توسط مدل هوش مصنوعی Cursor) بهصورت شبکههای پیچیده مدل شد. سپس با استفاده از متریکهای شبکهای، مقایسهی کمی و کیفی میان این دو نسخه انجام شد. نتایج نشان داد که ساختار وابستگی در نسخهی تولیدشده توسط هوش مصنوعی بهشکل محسوسی متمرکزتر است و این تمرکز میتواند نشانههایی از آسیبپذیری معماری و بدهی فنی بالاتر باشد. میتوان چنین تفسیر کرد که هرچند کدهای تولیدشده توسط هوش مصنوعی از نظر اندازه کوچکتر و از نظر ماژولاریتی در نگاه اول منسجمتر دیده میشوند اما در عمق، وابستگیهای ساختاری و مسیرهای ارتباطی آنها مستعد شکنندگی هستند.
دنیای نرمافزار در دههی اخیر شاهد جهشی بزرگ در استفاده از هوش مصنوعی برای تولید کد بوده است. مدلهای زبانی این امکان را فراهم کردهاند که توسعهدهندگان حتی بدون دانش عمیق از زبانهای برنامهنویسی، قطعهکدهایی قابلاجرا و کارآمد دریافت کنند. با این حال، در پس این سرعت و سهولت، پرسشی اساسی پنهان است: کیفیت معماری چنین کدهایی تا چه اندازه قابل اعتماد است؟
کیفیت معماری برخلاف صحت عملکرد کد در بلندمدت خود را نشان میدهد یعنی در زمان نگهداری، تغییر یا گسترش محصول. مفهومی که در مهندسی نرمافزار از آن با عنوان بدهی فنی (Technical Debt) یاد میشود به همین نقاط ضعف پنهان اشاره دارد. بدهی فنی مجموعهای از تصمیمات است که اگرچه در کوتاهمدت سرعت توسعه را افزایش میدهد، در بلندمدت منجر به پیچیدگی غیرضروری و دشواری در توسعههای بعدی میشود. یکی از انواع مهم این بدهی، بدهی فنی معماری است که مستقیما با نحوهی ساختار وابستگیها در سیستم ارتباط دارد.
در این پژوهش تلاش شد تا از چارچوب شبکههای پیچیده برای پاسخ به این پرسش استفاده شود که آیا کدهایی که توسط هوش مصنوعی تولید میشوند از نظر ساختار وابستگی، الگویی متفاوت از کدهایی که انسان توسعه میدهد دارند؟ و آیا این تفاوت میتواند بیانگر نشانههایی از بدهی فنی معماری باشد؟ برای پاسخ به این سوال، دو نسخهی متفاوت اما همدامنه از یک مسئلهی واقعی نرمافزاری انتخاب شد. هدف این بود که ساختارهای درونی و الگوهای ارتباطی میان واحدهای کد بهصورت شبکهای مدل شوند. در ادامه ویژگیهای توپوگرافیک این دو شبکه بررسی و تفسیر شد.
در سالهای اخیر، تحلیل ساختار نرمافزار با استفاده از مفاهیم شبکههای پیچیده بهعنوان رویکردی موثر برای درک کیفیت معماری مورد توجه پژوهشگران قرار گرفته است. در این رویکرد اجزای نرمافزار بهصورت گرهها و وابستگیهای میان آنها بهصورت یالها مدلسازی میشوند و با استفاده از متریکهای شبکهای، ویژگیهایی نظیر تمرکز وابستگی، ماژولاریتی، شکنندگی و تحملپذیری در برابر خطاها مورد بررسی قرار میگیرند. Newman [1] و Latora و همکاران [2] نشان دادهاند که ساختار شبکهای سیستمها میتواند نقش تعیینکنندهای در پایداری و رفتار آنها در مواجهه با اختلالات داشته باشد؛ مفهومی که بهطور مستقیم به معماری نرمافزار و بدهی فنی معماری قابل تعمیم است.
از سوی دیگر Albert و Barabási [3] با معرفی مفهوم شبکههای مقیاسآزاد نشان دادند که وجود گرههای مرکزی میتواند منجر به مقاومت بالا در برابر حذف تصادفی اما شکنندگی شدید در برابر حملات هدفمند شوند. این الگو بعدها در مطالعات نرمافزاری نیز مشاهده شد، بهگونهای که تمرکز وابستگیها حول تعداد محدودی ماژول، بهعنوان یکی از نشانههای بدهی فنی معماری و ریسک بالای تغییرپذیری شناخته میشود. Kruchten و همکاران [4] این پدیده را در قالب مفهوم بدهی فنی معماری معرفی کرده و تاکید میکنند که بدهی فنی معماری اغلب در ساختار وابستگیها نهفته است و با متریکهای سطح کد بهتنهایی قابل شناسایی نیست.
با گسترش استفاده از مدلهای زبانی بزرگ و ابزارهای تولید خودکار کد، پژوهشهایی به بررسی کیفیت کدهای تولیدشده توسط هوش مصنوعی پرداختهاند. Chen و همکاران [5] در یک مطالعهی تجربی نشان دادند که کدهای تولیدشده توسط مدلهای زبانی اگرچه از نظر عملکردی صحیح هستند اما در بسیاری موارد از نظر ساختار و تصمیمات طراحی دچار ضعفهایی میباشند. همچنین Pearce و همکاران [6] با تمرکز بر کدهای تولیدشده توسط Copilot نشان دادند که این کدها مستعد بروز ریسکهای پنهان در سطح قابلیت اطمینان و امنیت هستند.
با وجود این مطالعات، بخش قابل توجهی از پژوهشهای موجود تمرکز خود را بر تحلیل خطبهخط کد، امنیت یا کیفیت موضعی قرار دادهاند و کمتر به مقایسهی ساختار کلان معماری کدهای انسانی و تولیدشده توسط هوش مصنوعی پرداختهاند. این پژوهش تلاش میکند نشان دهد که تفاوتهای معماری میان کد انسانی و کد تولیدشده توسط هوش مصنوعی در شاخصهای عملی کیفیت کد نیز بازتاب پیدا میکنند.
در این پژوهش تمرکز اصلی بر تحلیل ساختار درونی کدهای نرمافزاری از منظر شبکههای پیچیده بود و تلاش شد تا الگوی وابستگی میان اجزای کد بهعنوان نمایندهای از تصمیمات معماری بررسی شود. فرض اصلی این بود که تفاوت در شیوهی تولید کد توسط انسان یا هوش مصنوعی میتواند منجر به شکلگیری ساختارهای متفاوتی در شبکهی وابستگی شود. برای رسیدن به این هدف، مراحل انجام کار بهصورت زیر طراحی و اجرا شد:
انتخاب مسئله و تولید کدها
در گام نخست لازم بود مسئلهای انتخاب شود که از یکسو پیچیدگی معماری کافی برای شکلگیری یک شبکهی وابستگی معنادار را داشته باشد و از سوی دیگر امکان پیادهسازی مستقل آن توسط انسان و هوش مصنوعی وجود داشته باشد. بر این اساس، پیادهسازی یک کتابخانهی نرمافزاری برای محاسبهی شاخصهای شباهت متنی بهعنوان دامنهی مسئله انتخاب شد. چنین کتابخانهای شامل توابع کمکی متعدد، ماژولهای پردازشی و وابستگیهای درونی متنوع است که آن را به گزینهای مناسب برای تحلیل شبکهای تبدیل میکند.
دو نسخهی مجزا از این مسئله مورد بررسی قرار گرفت. نسخهی نخست توسط یک برنامهنویس انسانی توسعه داده شده و از یک مخزن متنباز در GitHub استخراج شد. نسخهی دوم با استفاده از مدل هوش مصنوعی Cursor تولید شد بهگونهای که ورودی مسئله و دامنهی عملکرد هر دو نسخه یکسان باشد. این همارزی دامنهای کمک میکند تا تفاوتهای مشاهدهشده، ریشه در شیوهی تولید کد داشته باشند نه تفاوت در صورت مسئله.
مدلسازی کد بهصورت شبکهی وابستگی
پس از آمادهسازی دو مجموعه کد، گام بعدی مدلسازی ساختار آنها بهصورت شبکهی وابستگی بود. در این مدل، هر واحد کد(تابع یا ماژول) بهعنوان یک گره در نظر گرفته شد و هر فراخوانی یا وابستگی میان دو واحد کد بهصورت یک یال جهتدار مدل شد و جهت یالها بیانگر جریان وابستگی است؛ به این معنا که اگر تابع A تابع B را فراخوانی کند، یالی از A به B در شبکه ایجاد میشود.
برای استخراج این اطلاعات کدها با استفاده از تحلیل درخت نحو انتزاعی (AST) در زبان پایتون پیمایش شدند. این روش امکان شناسایی دقیق فراخوانیهای داخلی و وابستگیهای کد را فراهم میکند و از خطاهای ناشی از تحلیل متنی ساده جلوگیری میکند. پس از استخراج تمام فراخوانیها، شبکهی وابستگی هر نسخه ساخته شد و خروجی نهایی بهشکل فایلهای edgelist ذخیره گردید بهگونهای که هر خط نمایانگر یک وابستگی از مبدا به مقصد باشد.
نتیجهی این مرحله دو شبکهی جهتدار با ابعاد متفاوت بود. شبکهی انسانی شامل ۳۴۴ گره و ۷۳۹ یال بود در حالی که شبکهی تولیدشده توسط هوش مصنوعی ۱۴۵ گره و ۲۰۹ یال داشت. هر دو شبکه از نوع sparse بودند، ویژگیای که در سیستمهای نرمافزاری واقعی امری رایج محسوب میشود. با این حال همین تفاوت در اندازه و تراکم، نشانهای اولیه از تفاوت در نحوهی سازماندهی کدها بهشمار میرود.
محاسبهی متریکهای پایهی شبکه
پس از ساخت گرافهای وابستگی برای هر دو نسخهی انسانی و تولیدشده توسط هوش مصنوعی، در گام بعدی مجموعهای از متریکهای پایهی شبکههای پیچیده محاسبه شد. هدف از این مرحله ارائهی تصویری کمی و قابلمقایسه از ساختار معماری هر نسخه پیش از ورود به تحلیلهای عمیقتر بود. این متریکها بهگونهای انتخاب شدند که بتوانند جنبههای مختلفی از معماری را پوشش دهند.
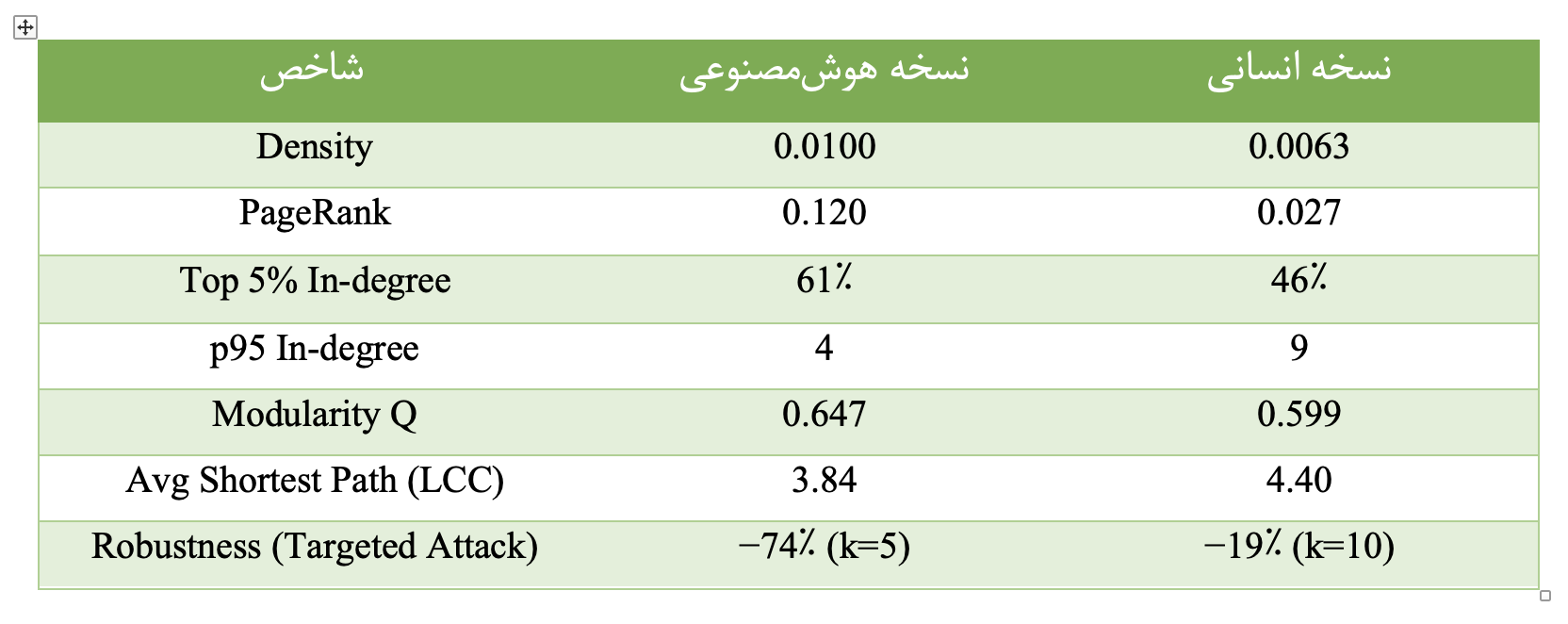
چگالی شبکهی جهتدار بهعنوان یکی از سادهترین اما مهمترین شاخصها نشان میدهد که شبکهی تولیدشده توسط هوش مصنوعی با مقدار ۰٫۰۱۰۰ متراکمتر از نسخهی انسانی با مقدار ۰٫۰۰۶۳ است. اگرچه هر دو مقدار پایین و متناسب با شبکههای نرمافزاری واقعی هستند اما چگالی بالاتر در نسخهی هوشمصنوعی بیانگر آن است که وابستگیها میان اجزای کد فشردهتر شدهاند. این فشردگی معمولا با افزایش coupling همراه است و میتواند نگهداری و توسعهی آتی سیستم را دشوارتر کند.
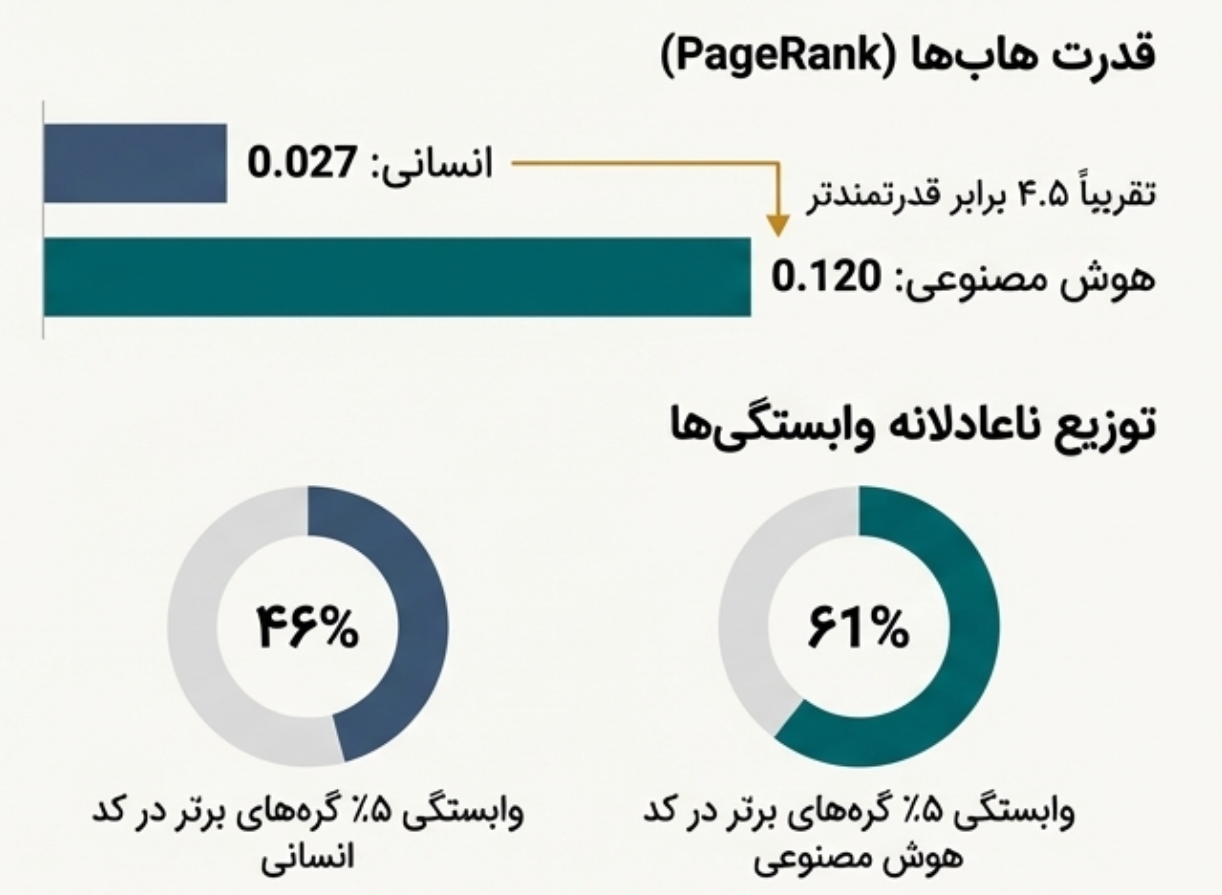
PageRank تصویری روشنتر از تمرکز معماری ارائه میدهد. بیشینهی PageRank در نسخهی هوشمصنوعی برابر با ۰٫۱۲۰ است در حالی که این مقدار در نسخهی انسانی تنها ۰٫۰۲۷ است. این اختلاف نشان میدهد که در معماری تولیدشده توسط هوش مصنوعی، یک یا چند گره نقش بسیار مسلطی در جریان وابستگیها ایفا میکنند. چنین گرههایی بهعنوان dependency hub شناخته میشوند و هرگونه تغییر یا خطا در آنها میتواند اثرات زنجیرهای گستردهای در کل سیستم ایجاد کند.
این تمرکز در شاخص Top 5% In-degree نیز دیده میشود. در نسخهی انسانی ۵٪ گرههای بالایی ۴۶٪ از کل وابستگیهای ورودی را در اختیار دارند در حالی که این مقدار در نسخهی هوشمصنوعی به ۶۱٪ میرسد. به بیان دیگر در معماری هوشمصنوعی، بخش بسیار کوچکی از گرهها بار اصلی وابستگیها را حمل میکنند. این الگو یکی از نشانههای کلاسیک بدهی فنی معماری محسوب میشود زیرا سیستم بهشدت به پایداری چند جز خاص وابسته میشود.
بررسی صدک ۹۵ام in-degree نیز تفاوت ماهیت توزیع وابستگیها را نشان میدهد. مقدار p95 در نسخهی انسانی برابر با ۹ و در نسخهی هوشمصنوعی برابر با ۴ است. این موضوع بیانگر آن است که در نسخهی انسانی وابستگیها بهشکل تدریجیتری توزیع شدهاند در حالی که نسخهی هوشمصنوعی ساختاری دوقطبی دارد: تعداد زیادی گره با وابستگی بسیار کم و تعداد اندکی گره با وابستگی بسیار زیاد.
از منظر ماژولاریتی نسخهی هوشمصنوعی با مقدار Q برابر با ۰٫۶۴۷ نسبت به نسخهی انسانی با مقدار ۰٫۵۹۹ ماژولارتر بهنظر میرسد. با این حال این ماژولاریتی بالاتر الزاما به معنای معماری سالمتر نیست زیرا خوشهها درشتدانهتر بوده و تفکیکپذیری عملکردی کمتری دارند.
در نهایت، میانگین طول کوتاهترین مسیر در بزرگترین مولفهی همبند (LCC) در نسخهی هوشمصنوعی کوتاهتر است (۳٫۸۴ در مقابل ۴٫۴۰). این ویژگی اگرچه از دید انتشار سریع اطلاعات جذاب بهنظر میرسد اما در زمینهی معماری نرمافزار میتواند به معنای انتشار سریعتر اثر تغییرات و خطاها در کل سیستم باشد.
پس از محاسبهی متریکهای پایهی شبکه، در این بخش نتایج بهدستآمده بهصورت تحلیلی مورد بررسی قرار میگیرند. هدف از این تحلیل فراتر رفتن از مقایسهی اعداد و شناسایی الگوهای معماری نهفته در ساختار وابستگی کدها است؛ الگوهایی که میتوانند بهطور مستقیم با پایداری، نگهداریپذیری و بدهی فنی معماری مرتبط باشند. در این راستا، توزیع درجهها، شناسایی گرههای بحرانی (Hotspot) و تحلیل مقاومت شبکه در برابر حذف گرهها بررسی شده است.
تحلیل توزیع درجهها و تمرکز وابستگی
یکی از محدودیتهای متریکهای میانگین این است که رفتار گرههای بسیار مهم را پنهان میکنند. به همین دلیل برای تحلیل دقیقتر ساختار شبکه، توزیع درجههای ورودی و خروجی با استفاده از صدکها مورد بررسی قرار گرفت. این رویکرد امکان مقایسهی رفتار گرههای معمولی با گرههای بسیار پراهمیت را فراهم میکند.
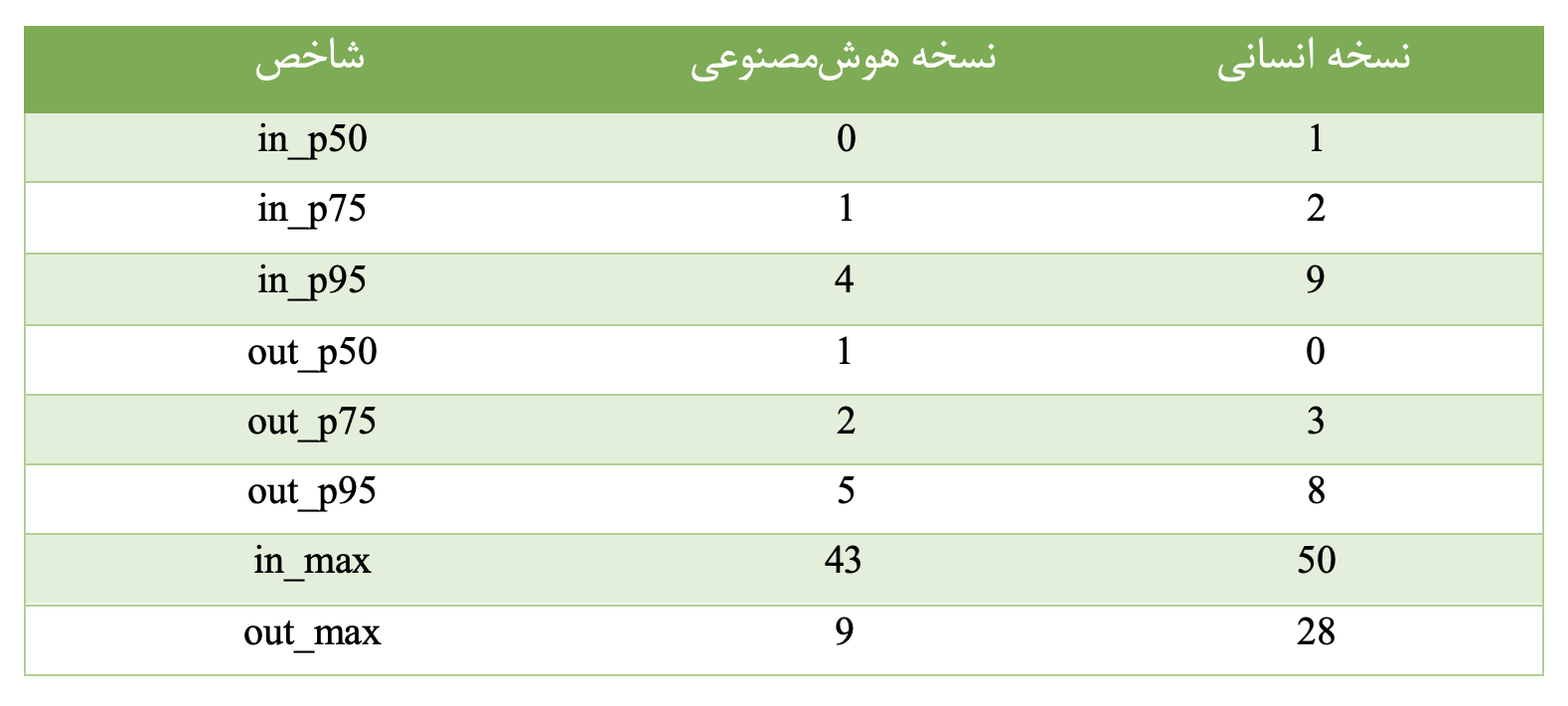
نتایج توزیع in-degree نشان میدهد که در نسخهی انسانی، میانهی درجهی ورودی برابر با ۱ است؛ به این معنا که بیش از نیمی از گرهها حداقل یک وابستگی ورودی دارند و در ساختار کلی سیستم نقش فعالی ایفا میکنند. در مقابل در نسخهی تولیدشده توسط هوش مصنوعی، میانهی in-degree برابر با ۰ است که بیانگر آن است که بیش از نیمی از گرهها هیچ وابستگی ورودی ندارند و عملا نقش حاشیهای در معماری سیستم دارند.
در عین حال صدک ۹۵ام in-degree در نسخهی انسانی برابر با ۹ و در نسخهی هوشمصنوعی برابر با ۴ است اما بیشینهی in-degree در هر دو نسخه بسیار بالا باقی میماند؛ بهطوری که بیشینهی in-degree در نسخهی انسانی ۵۰ و در نسخهی هوشمصنوعی برابر با ۴۳ گزارش شده است. این ترکیب از مقادیر نشاندهندهی یک الگوی دوقطبی در نسخهی هوشمصنوعی است: تعداد زیادی گره با وابستگی بسیار کم و تعداد بسیار محدودی گره با وابستگی بسیار زیاد. چنین ساختاری معمولا نشانهی تمرکز شدید وابستگیها و افزایش ریسک بدهی فنی معماری است.
تحلیل توزیع out-degree نیز الگوی مشابهی را تایید میکند. در نسخهی انسانی، صدکهای بالاتر out-degree مقادیر بزرگتری دارند که نشان میدهد وابستگیهای خروجی بهصورت تدریجی و توزیعشدهتری میان گرهها پخش شدهاند. در مقابل در نسخهی هوشمصنوعی، بیشینهی out-degree برابر با ۹ است در حالی که این مقدار در نسخهی انسانی به ۲۸ میرسد. این اختلاف نشان میدهد که در معماری تولیدشده توسط هوش مصنوعی، فراخوانیها محدودتر و متمرکزتر انجام شدهاند و جریان کنترل در مسیرهای مشخص و تکرارشوندهای حرکت میکند.
در مجموع تحلیل توزیع درجهها نشان میدهد که نسخهی هوشمصنوعی دارای ساختاری متمرکز و دوقطبی است در حالی که نسخهی انسانی از توزیع یکنواختتری برخوردار است؛ ویژگیای که معمولا با معماریهای پایدارتر و قابلنگهداریتر همراه است.
مقایسهی معماریهای Hotspot
در ادامهی تحلیل تمرکز بر شناسایی گرههای Hotspot قرار گرفت؛ گرههایی که هم از نظر تعداد وابستگیها و هم از نظر اهمیت ساختاری، نقش مرکزی در شبکه ایفا میکنند. برای این منظور ۱۰۰ گره برتر از نظر in-degree و ۱۰۰ گره برتر از نظر PageRank استخراج شدند و میزان همپوشانی میان این دو مجموعه مورد بررسی قرار گرفت.
در نسخهی انسانی ۹ گره مشترک میان این دو مجموعه مشاهده شد. این همپوشانی نشان میدهد که گرههایی که وابستگیهای زیادی دارند همان گرههایی هستند که از نظر ساختاری نیز اهمیت بالایی دارند. چنین الگویی حاکی از آن است که مرکزیت شبکه در نسخهی انسانی حاصل تصمیمات معماری آگاهانه است. Hotspotها در این نسخه منسجم و قابل پیشبینی هستند.
در نسخهی تولیدشده توسط هوش مصنوعی تنها ۶ گره مشترک میان دو مجموعهی مذکور وجود دارد. این نتیجه نشان میدهد که مرکزیت ساختاری در نسخهی هوشمصنوعی الزاما با میزان وابستگیها همراستا نیست. علاوه بر این، بررسی ماهیت برخی از گرههای مرکزی نشان میدهد که بخشی از آنها شامل عناصر عمومی و built-in هستند. این موضوع بیانگر آن است که Hotspotها در نسخهی هوشمصنوعی ناهمگنتر بوده و کمتر حاصل یک طراحی معماری هدفمند هستند؛ بلکه بیشتر نتیجهی الگوهای تولید کد و تکرار ساختارهای پیشفرضاند.
تحلیل پایداری و شکنندگی شبکه
برای ارزیابی میزان پایداری معماری، رفتار شبکهها در برابر حذف گرهها مورد بررسی قرار گرفت. هدف از این تحلیل سنجش میزان وابستگی ساختار کلی سیستم به گرههای مرکزی و شناسایی میزان شکنندگی معماری بود. در این راستا، حذف هدفمند گرههای با بالاترین PageRank بهعنوان بدترین سناریوی ممکن در نظر گرفته شد و معیار ارزیابی افت اندازهی بزرگترین مولفهی همبند شبکه (LCC drop ratio) بود.
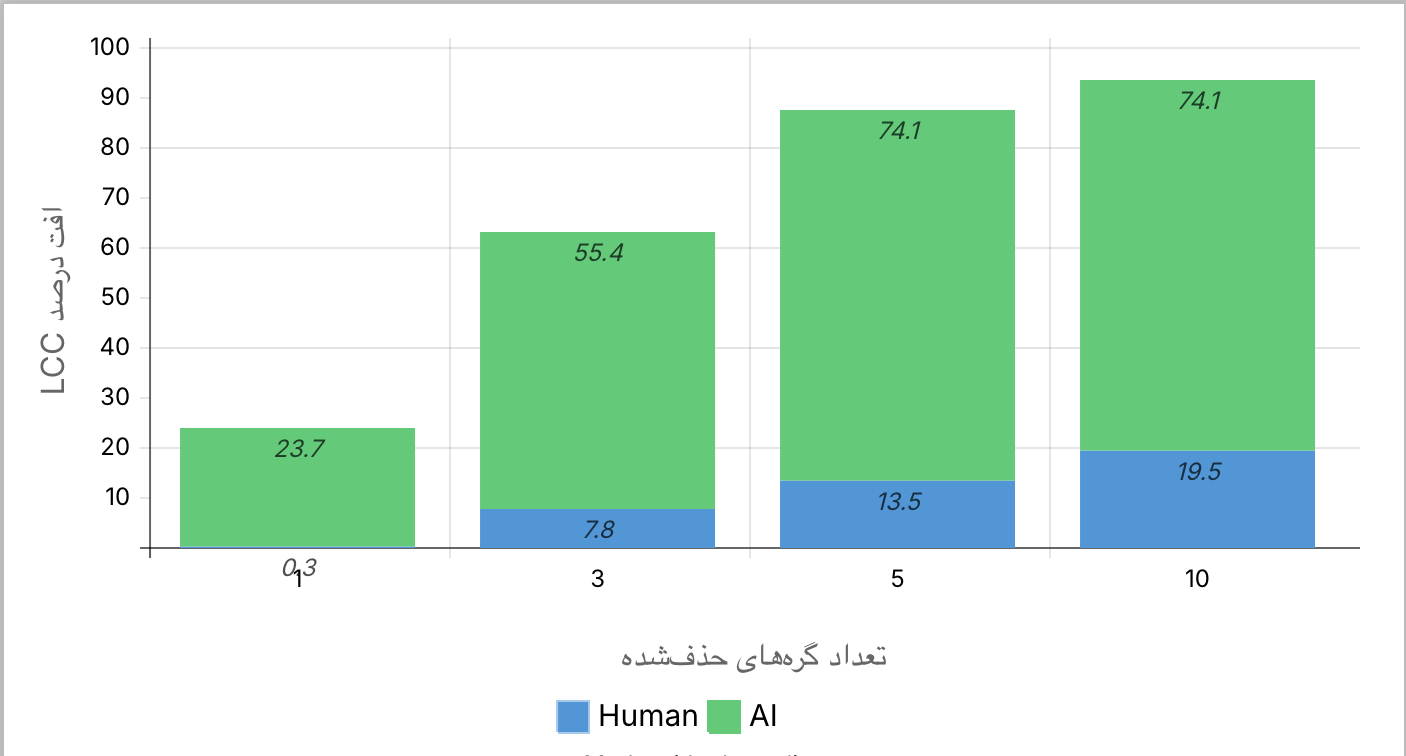
نتایج نشان میدهد که نسخهی انسانی مقاومت قابلتوجهی در برابر حذف گرههای مرکزی دارد. حذف یک گره مرکزی تنها منجر به افت حدود ۰٫۳٪ در اندازهی LCC میشود. با حذف سه گره مرکزی افت LCC به حدود ۷٫۸٪ میرسد و حتی با حذف ده گره مرکزی، افت اتصال شبکه حدود ۱۹٫۵٪ باقی میماند. این نشان میدهد که معماری انسانی بهگونهای طراحی شده است که وابستگی بیشازحد به تعداد محدودی گره ندارد و ساختار کلی سیستم حتی در صورت آسیب به اجزای مهم همچنان پایدار باقی میماند.
شبکهی تولیدشده توسط هوش مصنوعی رفتار کاملا متفاوتی از خود نشان میدهد. حذف تنها یک گره مرکزی باعث افت ۲۳٫۷٪ در اندازهی LCC میشود. با حذف سه گره مرکزی این افت به ۵۵٫۴٪ میرسد و حذف پنج گره مرکزی موجب افت ۷۴٫۱٪ اتصال شبکه میشود. پس از این نقطه شبکه عملا فروپاشیده تلقی میشود و حذف گرههای بیشتر تغییر معناداری در میزان اتصال ایجاد نمیکند. این نتایج بهوضوح نشان میدهد که معماری نسخهی هوشمصنوعی بهشدت به تعداد بسیار محدودی گره مرکزی وابسته است و حذف همین گرهها برای از کاراندازی بخش عمدهای از سیستم کافی است.
در کنار حذف هدفمند گرههای مرکزی، سناریوی حذف تصادفی نیز بهعنوان خط مبنای پایداری طبیعی شبکه مورد بررسی قرار گرفت. نتایج نشان داد که هر دو شبکه در برابر حذف گرههای معمولی نسبتا مقاوماند اما تفاوت میان دو نسخه همچنان معنادار باقی میماند. در نسخهی انسانی حذف ۱۰ گره تصادفی تنها حدود ۴٫۶٪ کاهش در اندازهی بزرگترین مولفهی همبند ایجاد کرد؛ افتی ملایم که بیانگر توزیع متعادل وظایف و نبود وابستگی بیشازحد به مسیرهای ارتباطی خاص است. در نسخهی تولیدشده توسط هوش مصنوعی با حذف همان تعداد گره دچار افت ۱۱٫۴٪ در LCC شد یعنی بیش از دو برابر شبکهی انسانی. این اختلاف نشان میدهد که حتی در شرایطی که گرههای کلیدی حذف نمیشوند، ساختار هوشمصنوعی همچنان مستعد گسستهای ناگهانی است و بخشی از شکنندگی آن ناشی از تمرکز ذاتی وابستگیهاست.
بهمنظور ارزیابی عملی نتایج بهدستآمده از مدلسازی شبکهی وابستگیها، از ابزار SonarQube بهعنوان یک چارچوب متداول مهندسی نرمافزار برای ارزیابی کیفیت کد استفاده شده است. هدف از این مرحله بررسی این موضوع است که آیا الگوهای شناساییشده در تحلیل شبکهای در شاخصهای عملی کیفیت کد نیز بازتاب پیدا میکنند یا خیر.
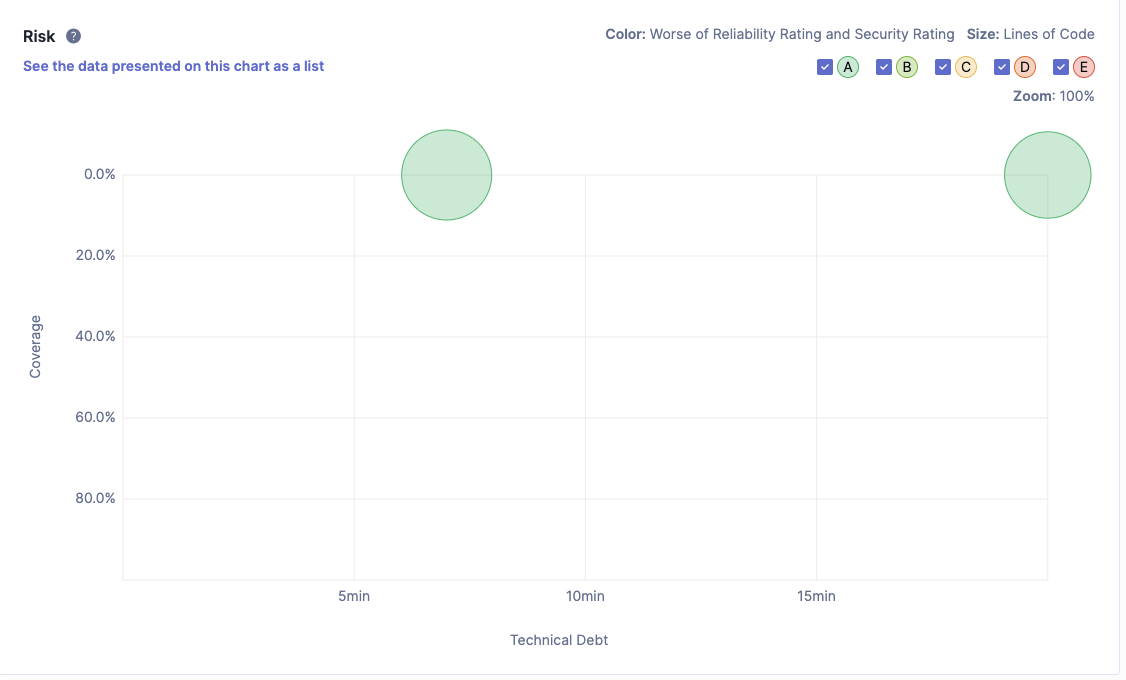
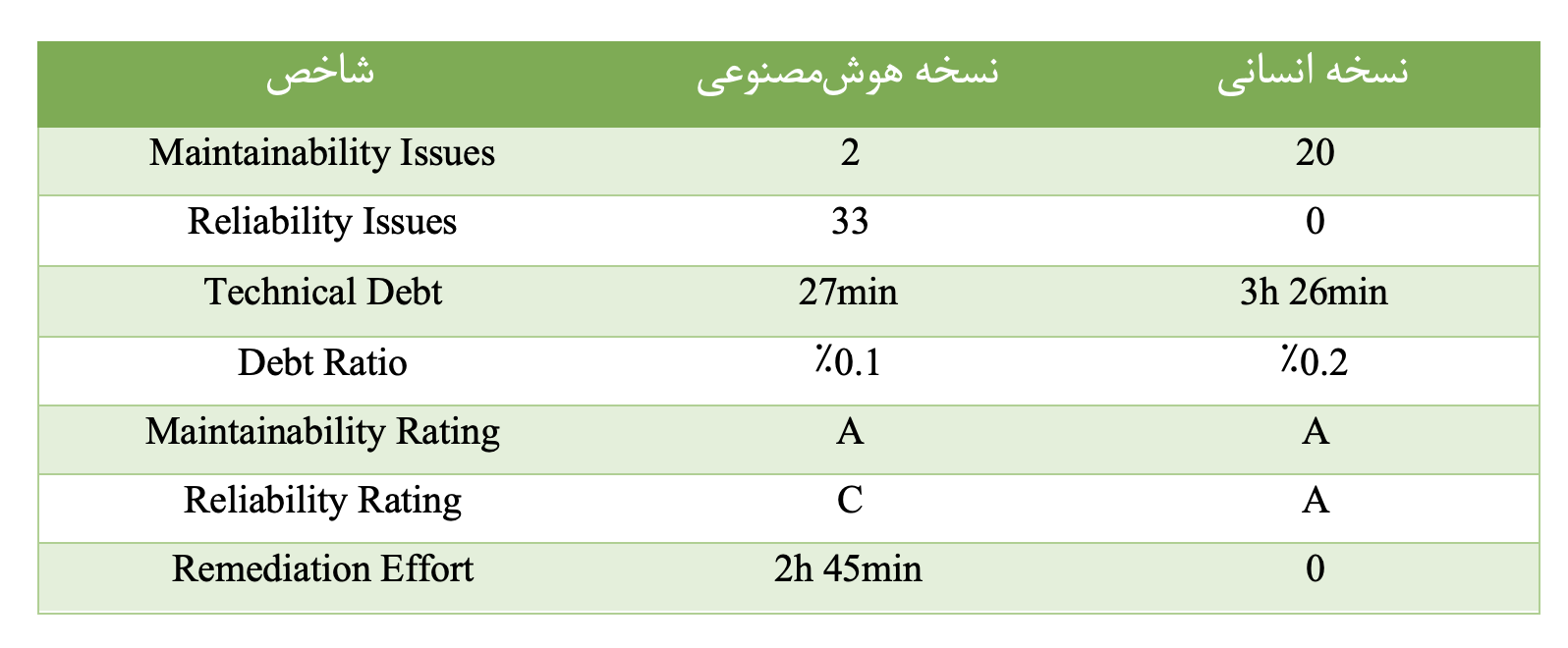
برای این منظور هر دو نسخهی کد تولیدشده بهصورت جداگانه و تحت شرایط یکسان مورد تحلیل SonarQube قرار گرفتند. نتایج حاصل نشان میدهد که نسخهی تولیدشده توسط هوش مصنوعی از نظر بدهی نگهداری (Maintainability Debt) وضعیت نسبتا مطلوبی دارد. در این نسخه تنها ۲ مسئلهی نگهداری شناسایی شده و نسبت بدهی فنی برابر با ۰٫۱٪ گزارش شده است که منجر به دریافت رتبهی A در شاخص Maintainability شده است. این موضوع با برخی نتایج تحلیل شبکهای از جمله ماژولاریتی نسبتا بالا و تعداد کمتر گرهها همخوانی دارد و نشان میدهد که کد از نظر ساختار ظاهری و خوانایی، ساده و کمهزینه به نظر میرسد.
نسخهی هوشمصنوعی دارای ۳۳ مسئلهی مرتبط با Reliability بوده و رتبهی C را در این شاخص دریافت کرده است. این یافته اهمیت ویژهای دارد چرا که مشکلات Reliability معمولا به خطاهای اجرایی و مدیریت نادرست استثناها اشاره دارند. وجود چنین تعداد بالایی از مسائل قابلیت اطمینان نشان میدهد که اگرچه کد از نظر نگهداری کمهزینه به نظر میرسد اما از منظر پایداری اجرایی و تحمل خطا دارای ریسکهای قابلتوجهی است.
این نتیجه بهطور مستقیم با یافتههای تحلیل شبکهای همراستا است. همانگونه که در بخشهای پیشین نشان داده شد، معماری نسخهی هوشمصنوعی دارای تمرکز بالای وابستگیها، بیشینهی PageRank بزرگتر و سهم بالاتر گرههای بالادستی از وابستگیهای ورودی است. چنین ساختاری باعث میشود که بروز خطا در تعداد محدودی گره مرکزی، اثرات مخربی بر کل سیستم داشته باشد؛ پدیدهای که در تحلیل حذف هدفمند گرهها نیز بهصورت افت شدید اندازهی بزرگترین مولفهی همبند (LCC) مشاهده شد. بنابراین، افزایش مسائل Reliability در SonarQube را میتوان بازتاب عملی همان شکنندگی ساختاری دانست که در تحلیل شبکهای شناسایی شده بود.
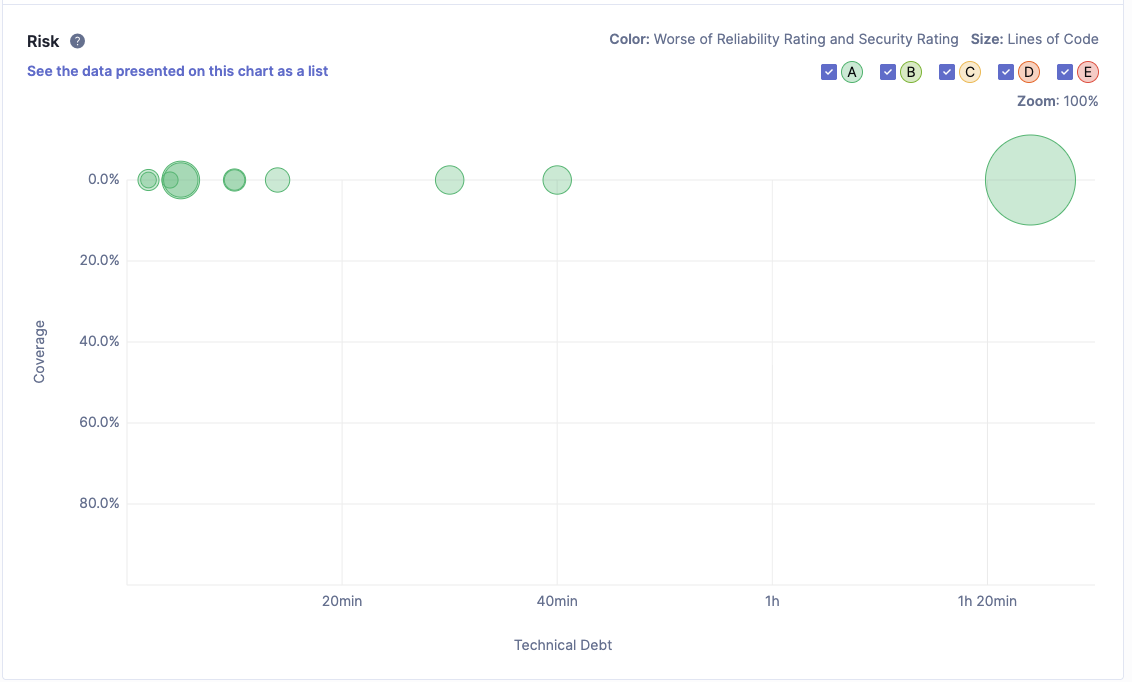
نتایج نسخهی انسانی تصویری متفاوت ارائه میدهد. اگرچه این نسخه دارای تعداد بیشتری مسئلهی نگهداری (۲۰ مورد) و نسبت بدهی فنی بالاتر (۰٫۲٪) است اما در شاخص Reliability هیچ مسئلهای گزارش نشده و رتبهی A را دریافت کرده است. این موضوع نشان میدهد که کد انسانی علیرغم هزینهی نگهداری بالاتر از نظر پایداری اجرایی و قابلیت اطمینان در وضعیت بسیار مناسبی قرار دارد.
این یافته نیز با نتایج تحلیل شبکهای نسخهی انسانی سازگار است. توزیع یکنواختتر درجهها، نبود وابستگی شدید به تعداد محدودی گره مرکزی و مقاومت بالاتر در سناریوهای حذف هدفمند و تصادفی گرهها، همگی حاکی از معماریای هستند که تصمیمات طراحی در آن بهصورت آگاهانهتر و با در نظر گرفتن پایداری سیستم اتخاذ شدهاند. به بیان دیگر بدهی نگهداری بالاتر در نسخهی انسانی به جای آنکه نشانهی ضعف معماری باشد، هزینهای آگاهانه برای دستیابی به قابلیت اطمینان و پایداری بیشتر تلقی میشود.
نتایج SonarQube بهعنوان یک ابزار مستقل و رایج در مهندسی نرمافزار بهطور معناداری یافتههای تحلیل شبکهای این پژوهش را تایید میکند. تمرکز وابستگیها و شکنندگی معماری در نسخهی تولیدشده توسط هوش مصنوعی نهتنها در متریکهای نظری شبکه بلکه در شاخصهای عملی کیفیت کد نیز قابل مشاهده است. این همراستایی نشان میدهد که تحلیل شبکهی وابستگیها میتواند بهعنوان ابزاری مکمل و موثر در شناسایی بدهی فنی معماری و ریسکهای پنهان کیفیت کد مورد استفاده قرار گیرد.
این پژوهش با هدف بررسی و مقایسهی ساختار معماری کدهای تولیدشده توسط هوش مصنوعی و انسان انجام شد. در این مطالعه هر دو نسخه از یک مسئلهی نرمافزاری بهصورت شبکههای وابستگی مدلسازی شده و بر اساس شاخصهای مختلف شبکهای تحلیل گردیدند. نتایج نشان داد که اگرچه نسخهی تولیدشده توسط هوش مصنوعی اندازهی کوچکتر و ظاهرا ساختار سادهتری دارد اما از نظر الگوی وابستگی دارای تمرکز بسیار بالاتری است؛ بهگونهای که بخش عمدهای از جریان وابستگیها حول چند گره مرکزی متمرکز شده و حذف این گرهها باعث فروپاشی سریع ساختار شبکه میشود. در مقابل، نسخهی انسانی توزیع یکنواختتر و ماژولاریتی متعادلتری دارد که موجب پایداری بیشتر معماری و تحملپذیری بالاتر در برابر خطاهای موضعی میگردد.
نتایج اعتبارسنجی با استفاده از ابزار SonarQube نیز بهعنوان شاهدی مستقل این الگو را تایید کرد. در حالیکه نسخهی تولیدشده توسط هوش مصنوعی بدهی نگهداری اندکی داشت، تعداد بالای مشکلات قابلیت اطمینان و رتبهی پایینتر در شاخص Reliability نشان داد که سادگی ظاهری آن با شکنندگی ساختاری همراه است. برعکس، نسخهی انسانی با وجود بدهی نگهداری بیشتر، فاقد مشکلات Reliability بوده و از نظر پایداری و اطمینان اجرایی در وضعیت برتری قرار داشت.
[1] M. E. J. Newman, Networks: An Introduction. Oxford University Press, 2010.
[2] V. Latora, V. Nicosia, and G. Russo, Complex Networks: Principles, Methods and Applications. Cambridge University Press, 2017.
[3] R. Albert, H. Jeong, and A.-L. Barabási, “Error and attack tolerance of complex networks,” Nature, vol. 406, no. 6794, pp. 378–382, 2000.
[4] P. Kruchten, R. L. Nord, and I. Ozkaya, “Technical debt: From metaphor to theory and practice,” IEEE Software, vol. 29, no. 6, pp. 18–21, 2012.
[5] X. Chen, Y. Zhang, and Z. Li, “An empirical study on code generated by large language models,” arXiv preprint arXiv:2303.08774, 2023.
[6] H. Pearce, M. Ahmad, B. Tan, K. Dolos, and R. Karri, “Asleep at the keyboard? Assessing the security of GitHub Copilot’s code contributions,” in IEEE Symposium on Security and Privacy, 2022.
[7] G. Baxter and I. Sommerville, “Socio-technical systems: From design methods to systems engineering,” Interacting with Computers, 2011.
[8] SonarSource, “SonarQube Documentation,” 2024. Available: https://docs.sonarsource.com/sonarqube
[9] B. Vasilescu, Y. Yu, H. Wang, P. Devanbu, and V. Filkov, “Quality and productivity outcomes relating to continuous integration in GitHub,” in Proceedings of ESEC/FSE, 2015.