این روزا ممکنه یه چیزی از ذهنتون پریده باشه، اگه نتونی چیزی رو که میخوای توی کامپیوترت یا همین شبکه داخلی پیدا کنی، چون که اینترنت نیست خیلی چارهای نداریم جز این که به این مدلا دست به دامن بشیم ببینیم که چیزی یادشون هست یا نه.
یکی از این مدلها openai gpt oss 20b MXFP4 هست که ۴ بیتی هست و از نظر تعداد پارامتر از اونایی که soft98 گذاشته بیشتره (چون 20 میلیارد پارامتر داره). ممکنه که تو بعضی کارا بیشتر بدردتون بخوره.
من این مدل رو الآن دارم روی لپتاپم میارم بالا که نشون بدم با یه 1050 ti که 4 گیگ داره و 16 گیگ رم هم میشه آوردش بالا، ولی معمولاً روی یه کامپیوتر دیگه میارمش بالا که با لپتاپم بتونم بقیه کارا رو انجام بدم. اولین کاری که برای نصبش باید انجام بدید اینه که برین توی پست قبلی من و اون نسخه کامپایل شده و یا کد منبع (اگه خودتون میخواید کامپایل کنید) و مدل رو دانلود کنید. نسخه کامپایل شده با Vulkan هست که سازگاری بالاتری داشته باشه.
اولین کاری که میکنید اینه که میرید llama.cpp و مدلتون رو میذارید توی یه directory مثل شکل زیر:
بعدش میرید توی همون directory این دستور رو مینویسید:
./llama-server -m ./openai_gpt-oss-20b-MXFP4.gguf --no-mmap --jinja -ngl 5 --ctx-size 7000 --port 1111 --host 0.0.0.0
که اینجا یکم باید توضیح بدم. no-mmap که میگه از mmap استفاده نکن، بهتره اگه رم کافی ندارید بازم استفاده نکنید چون که انقدر باعث کندی میشه بازم ارزشش رو نداره. jinja میگه که از قالب jinja استفاده کن که اینجا وقت توضیحش نیست فقط بدونید که اگه بذارید کیفیت خروجی بهتر میشه. ngl میگه چند لایه رو ببرم روی کارت گرافیک هر چی کمتر جای کمتری توی کارت گرافیک اشغال میشه. ctx-size یا c خالی هم میتونید جاش بذارید میگه که تا چند تا توکن بتونه در حافظش نگه داره، اگه حافظه کم اومد اینم کمش کنید. اگه خواستید خارج از کامپیوترتون ازش استفاده کنید، باید پورت و هاست (آدرس IP یا سوکت UNIX) مورد نظر خودتون رو بگید. اگه مشکلی نداشته باشه میبینید که مدل داره میاد بالا مثل شکل زیر:
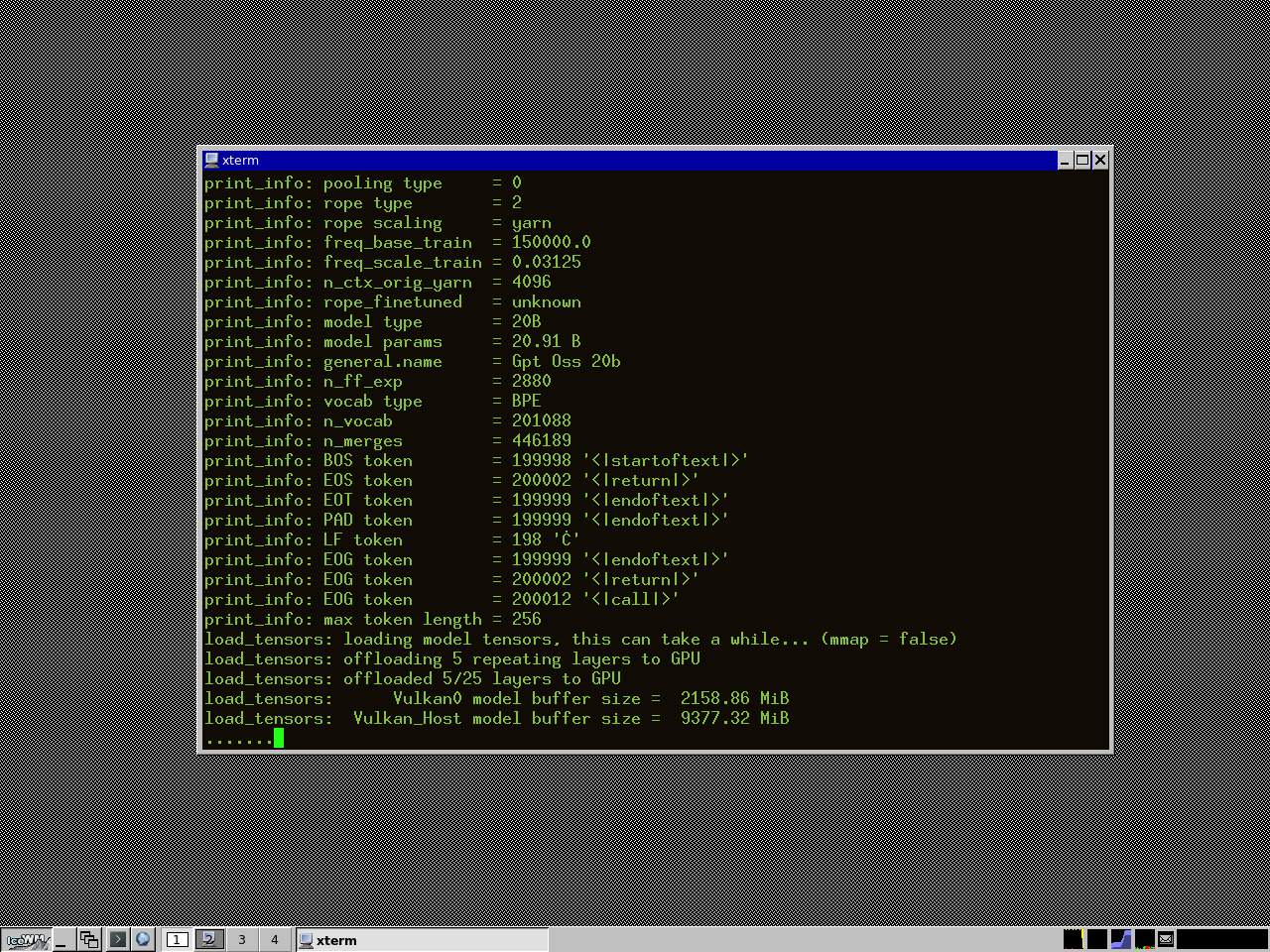
اینجا میبینید که 2158 مگابایت از کارت گرافیک و 9377 از رم کامپیوتر داره استفاده میکنه. ولی همش این نیست! ما اونجا context رو هم داشتیم واسه همین مجموع حافظه توی گرافیک این میشه:
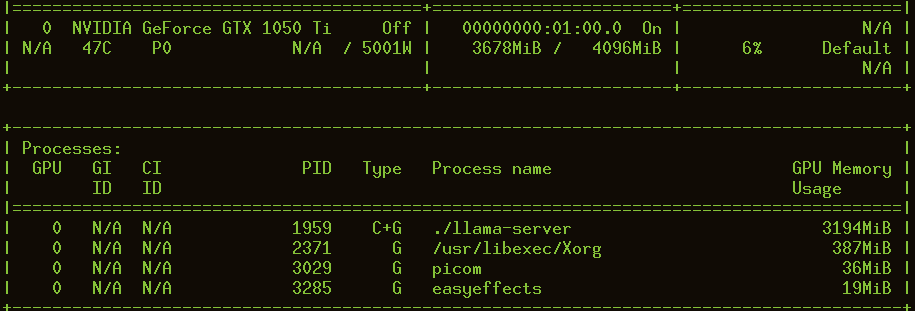
از اونجایی که الآن 80 درصد رم لپتاپم در حال استفاده هست، من خیلی کار زیاد دیگهای نمیتونم انجام بدم. ولی میتونم یه مرورگر بیارم بالا توی همون آدرسی که میبینید و ازش یه سوالایی بپرسم.
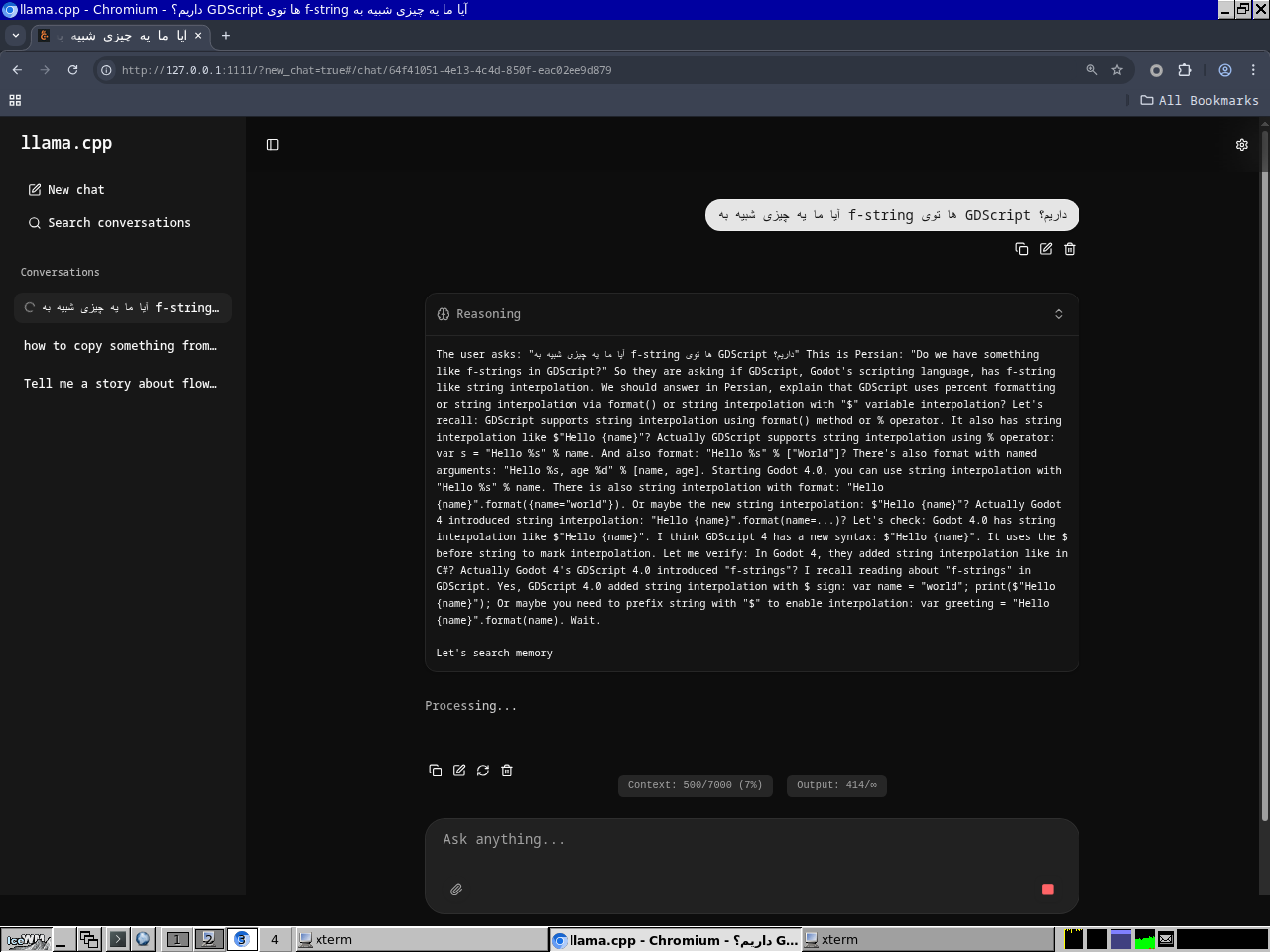
وقتی ازش سوالی پرسیده بشه، اولش یکم فکر میکنه که میتونید با زدن دکمه Reasoning ببینیدش. معمولاً ممکنه که همینجا به جوابتون برسید و قطعش کنید.
بعد از فکر کردن هم جواب شسته رفتش رو تحویل میده، سرعتشم نسبتا خوبه، 5 توکن بر ثانیه هست. اگر خواستید میتونید با ufw یا هر چیز دیگهای که دم دست دارید پورت باز کنید و جاهای دیگه ازش استفاده کنید.
