جما (Gemma) خانوادهای از مدلهای باز و پیشرفتهٔ سبکوزن گوگل است که بر پایهٔ فناوری مورد استفاده برای ایجاد مدلهای جمینی (Gemini) ساخته شدهاند. مدلهای Gemma 3n برای اجرای کارآمد روی دستگاههای با منابع محاسباتی محدود طراحی شدهاند. این مدلها قابلیت پردازش چندوجهی (مالتیمدیا) را دارند و میتوانند ورودیهای متنی، تصویری، ویدیویی و صوتی را پردازش کرده و خروجی متنی تولید کنند. وزنهای این مدلها برای هر دو نوع پیش آموزشدیده و تنظیمشده بر اساس دستورالعمل به صورت باز (open-weight) در دسترس است. این مدلها با استفاده از دادههایی از ۱۴۰ زبان آموزش دیدهاند. مدلهای Gemma 3n از فناوری فعالسازی انتخابی پارامترها (selective parameter activation) برای کاهش نیازمندیهای منابع استفاده میکنند. این فن به مدلها اجازه میدهد تا با اندازهی مؤثری معادل ۲B و ۴B پارامتر عمل کنند، که کمتر از تعداد کل پارامترهای موجود در آنها است. مبنای این سری از مدلها، معماری MatFormer است که امکان استفاده از زیرمدلها (sub-models) به صورت تو در تو در داخل مدل را فراهم میکند. نامگذاری این معماری از عروسکهای ماتروشکا الهام گرفته است. هدف این پست معرفی اجمالی این معماری است.

در فاز آموزش این مدل از یک معماری تودرتو استفاده میکند که در اصل روی شبکه عصبی رو به جلوی بلوک مبدل عمل میکند. البته در پیوست مقاله در مورد اعمال آن روی قسمتهای دیگر مانند توجه نیز صحبت شده، اما معماری در اصل بر قسمت FFN متمرکز است. برای ایجاد مدلهای تودرتو یک نسبت تعریف میشود که نشاندهنده تعداد گرههای لایه مخفی (dff) به تعداد گرههای ورودی=تعداد گرههای خروجی (dmodel) است. هر زیرمدل (Ti) در بردارنده (mi) سلول نخست شبکه عصبی است,:
1<=m1...<=mg = dff
بنابراین سلولهای نخست در فرایند آموزش حائز اهمیت بیشتری هستند. به صورت دقیق Ti به صورت زیر تعریف میشود:
Ti(x) = sigmoid(x.W1[0:mi].T).W2[0:mi]
که یک شبکه عصبی روبه جلوی ساده با قابلیت محدودسازی تعداد گرههای مورد استفاده است. در این مطالعه dff=4 در نظر گرفته شده و چهار سطح از آن (dff/8, dff/4, dff/2, dff) استفاده شده است. مورد آخر شبکه عصبی روبه جلوی اصلی که در بردارنده حالتهای دیگر است. در واقع چهار مدل تو در تو داریم که به ترتیب زیرمجموعه یکدیگر هستند. مدل انتخاب شده در تمام لایههای مبدل یکسان خواهد بود. در زمان آموزش به صورت تصادفی در هر قدم یکی از مدلها برای آموزش انتخاب میشود (روش انتخاب در ضمیمه مطالعه مورد بررسی قرار گرفته است).
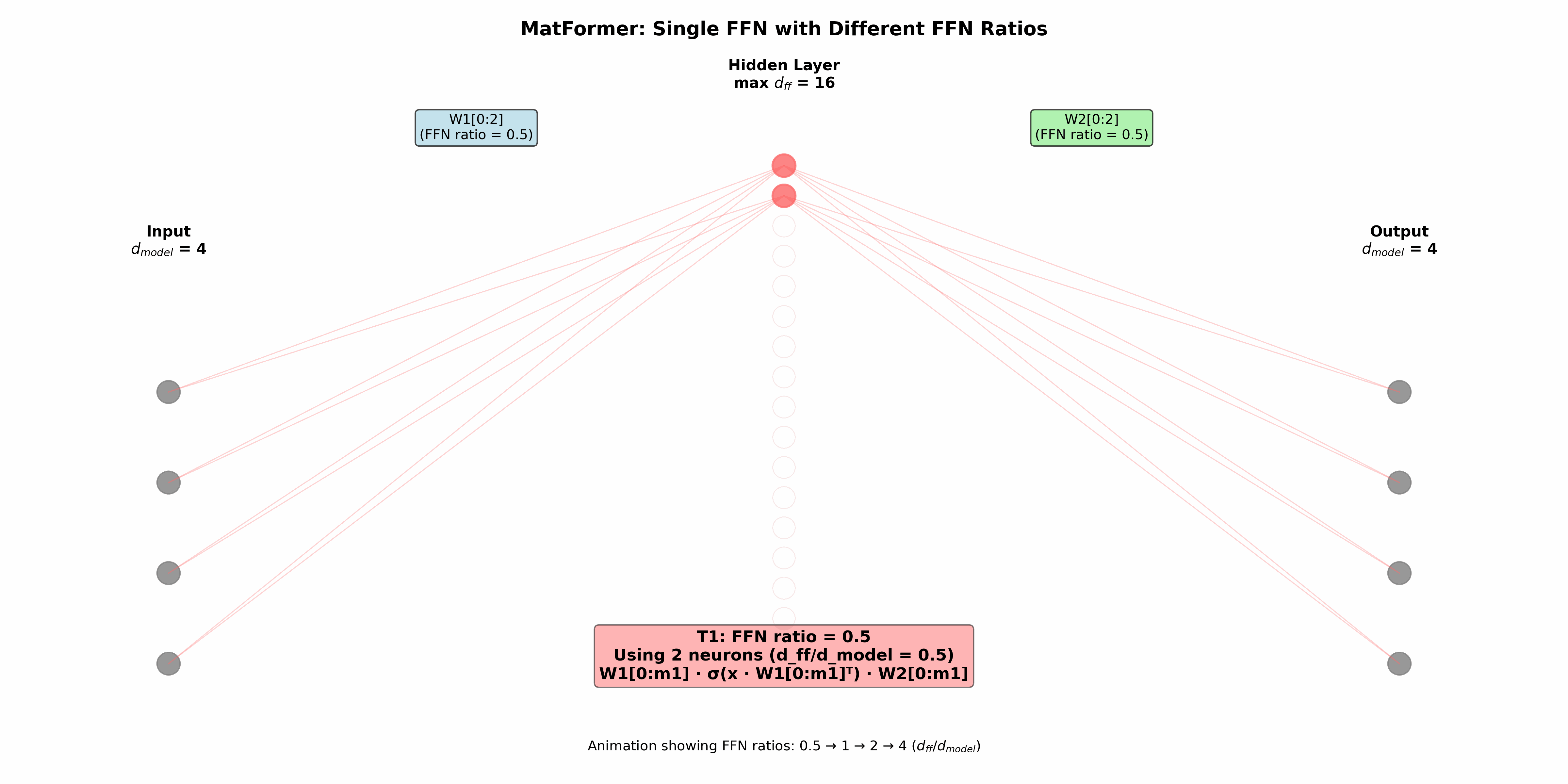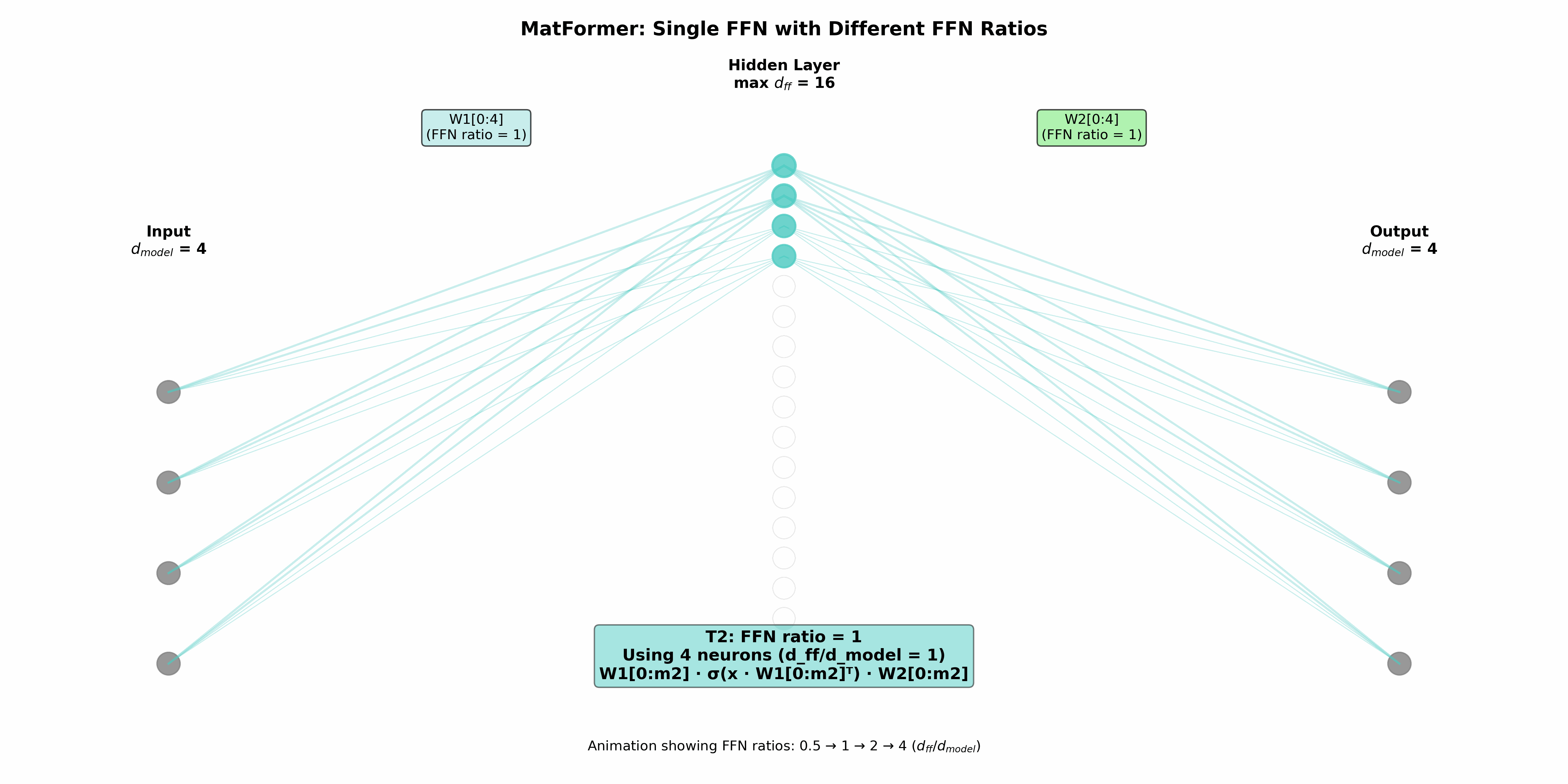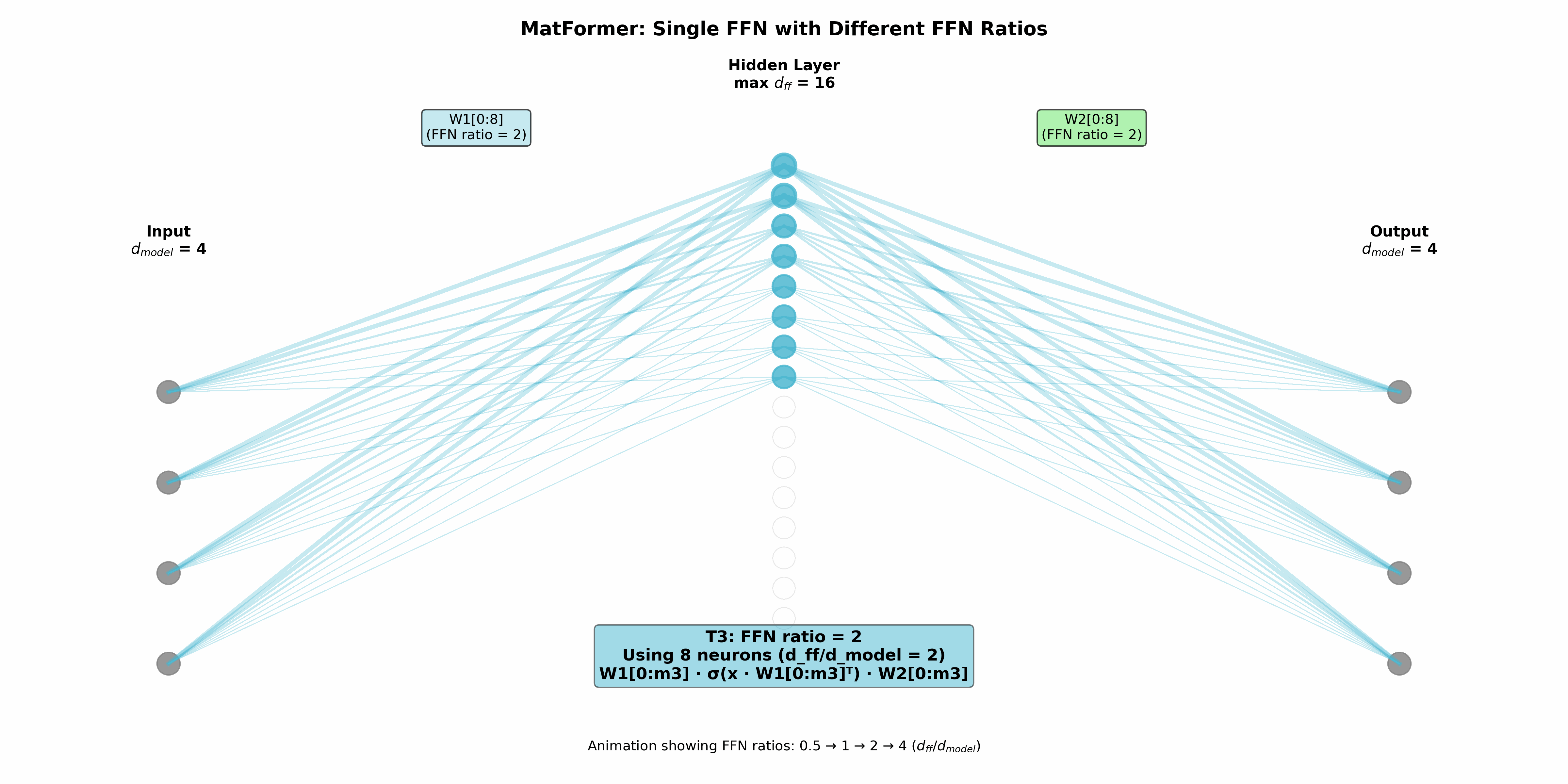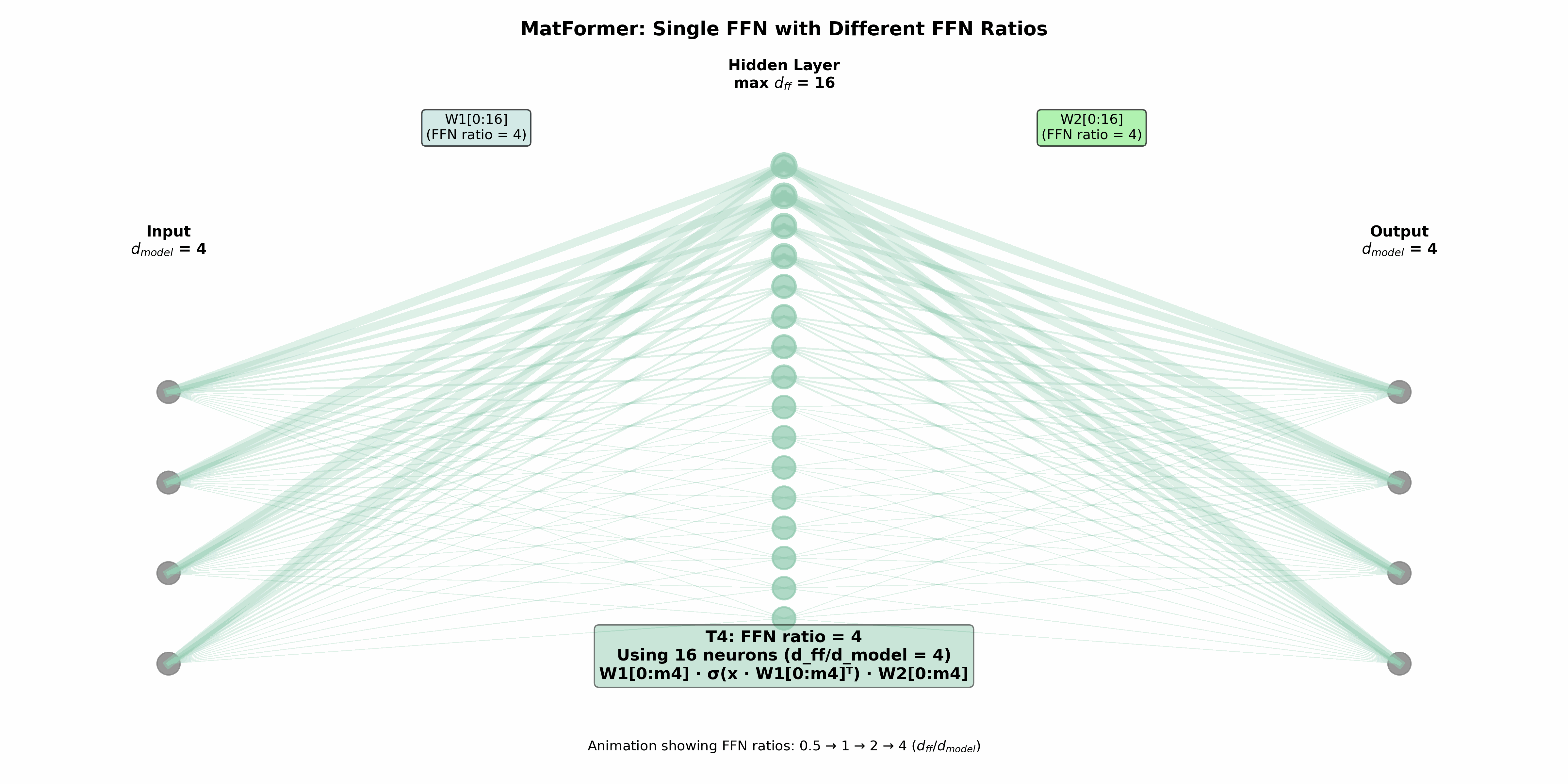
نویسندگان مشاهده کردهاند که در زمان استنتاج و استفاده از مدل، میتوان از ترکیبهای مختلفی که در زمان آموزش مورد استفاده قرار نگرفته نیز استفاده کرد و نتایج بهتری نیز کسب کرد. در زمان آموزش یک مدل ثابت در تمامی لایههای استفاده میشد اما در زمان استنتاج میتوان در هر لایه از مدلی دلخواه استفاده کرد. به منظور یافتن معماری بهینه میتوان از جستجوی معماری عصبی استفاده کرد اما این مورد از نظر هزینه گران است. در مقابل نویسندگان روشی به نام ترکیب و تطبیق (Mix’n’Match) را پیشنهاد کردهاند. روش مذکور که به صورت تجربی کارایی خود را نشان داده به این این صورت است که در هر لایه مدل انتخابی بزرگتر یا مساوی مدل مورد استفاده در لایه قبل است.
نویسندگان همچنین این معماری را برای مدلهای تصویر نیز پیشنهاد کردهاند. همچنین نشان میدهند که سرگشتگی و صحت تک نمونه این معماری با مدلهای مشابه که به صورت مستقل آموزش داده شده برابری میکند. همچنین این مدلها رمزگشایی حدسی را تسریع میکنند. رمزگشایی حدسی از یک مدل زبانی سبک و دقیق به عنوان مدل پیشنویس استفاده میکند تا به صورت خودبازگشتی چند توکن را تولید نماید. سپس این پیشنویسها توسط یک مدل بزرگتر از طریق رمزگشایی موازی بر روی توکنهای تولیدشده، تأیید یا تصحیح میشوند. در صورت عدم دقت پیشنویس، مدل پیشنویس به خروجی مدل بزرگتر بازگردانده و تنظیم میشود. این روش باعث افزایش قابل توجه سرعت استنتاج میگردد، در حالی که دقت مدل بزرگ را حفظ میکند. کندی این روش عمدتاً ناشی از مواردی است که پیشبینیهای مدل کوچکتر با مدل بزرگتر همخوانی ندارند. استفاده از یک مدل پیشنویس که به طور قابل توجهی با مدل تأییدکننده بزرگتر هماهنگتر باشد، باعث کاهش تعداد بازگرداندنهای پیشبینیهای مدل پیشنویس میشود و در نتیجه تأخیر را کاهش میدهد. زیرمدلهای MatFormer میتوانند تا ۱۱٫۵٪ بیشتر با مدل بزرگ خود هماهنگ باشند، در نتیجه در این زمینه نیز سبب افزایش سرعت استنتاج میشوند.