
ترجمه کد یکی از فرآیندهای حیاتی دنیای بزرگ نرم افزار است و میتوان گفت از آن دسته نیازهاییست که بهبود آن نقش گستردهای در رشد حوزه نرم افزار خواهد داشت. این فرآیند، شاید در نگاه اول ساده به نظر آید، اما در پروژههای بزرگ در دنیای واقعیست که دشواری آن مشخص میشود. در میان همه روشهای طاقت فرسا و زمانبر این فرآیند، مدلهای زبانی بزرگ(Large Language Model) مانند GPT ظهور میکنند. در این مقاله بررسی خواهیم کرد که این مدلها که به صورت Unsupervised آموزش میبینند، در مقایسه با روشهای دستی ترجمه کد، چه مزایا و معایبی را برای ما به ارمغان خواهند آورد.
ترجمه کد عملیات تبدیل یک کد نوشته شده از یک زبان برنامه نویسی به یک زبان برنامه نویسی دیگر است.
با توجه به اینکه توسعه بیشتر نرم افزارهای مدرن مبتنی بر استفاده مجدد از کدها یا نرم افزارهایی میباشد، در صورتی که شما کد مورد نیاز سیستم خود را پیدا کردید که نیازهای سیستم را به خوبی برطرف میکرد، با احتمال بالایی زبان برنامه نویسی آن متفاوت از زبان برنامه نویسی سیستم جدید شما خواهد بود؛ در نتیجه نیاز به ترجمه کد در زمان کوتاه و به صورت موثر، که عملکرد کد را تغییر ندهد، یک نیاز ضروری و ارزشمند است.
یکی از دلایل دیگر اهمیت ترجمه کد، نیاز به آپدیت کدهاست. ممکن است کدهایی برای پروژههای بزرگ قدیمی نوشته شده باشد که زبانهای برنامه نویسی آنها دیگر رایج نیست و افراد مسلط به آنها معدود هستند؛ این مسئله ماندگاری و بهبود کد را سخت میکند. چه بسا ترجمه آن به یک زبان برنامه رایج بسیار آسانتر و کاربردیتر از آموزش آن زبانهای برنامه نویسی به افراد است.
گاهی اوقات نیز لازم است جهت بهبود عملکرد، کد را به زبانهایی مانند C++ تبدیل کنیم تا در پردازشهای سنگین بهتر عمل کنند.
در گذشته، روشی که مورد استفاده قرار میگرفت، ترجمه دستی بود. هر چند لازم به ذکر است که امروزه نیز ر برخی پروژهها ناچار به استفاده از این روش هستیم. در این روش احتمال اینکه توسعه دهنده به طور ناخواسته منطق کد را تغییر دهد و یا جزئیات مهم را نادیده بگیرد، بالاست. همچنین پروژههای واقعی معمولا شامل وابستگیهای پیچیدهای هستند که درک انها برای انسان پیچیده است و اگر ندانسته توسط توسعه دهنده نادیده گرفته شوند، کد ناقص خواهد بود. ترجمه دستی نیاز به صرف زمان زیادی دارد؛ زیرا توسعه دهنده باید هر خط کد را خود بخواند و تحلیل کند و به زبان مقصد ترجمه کند. همچنین اگر چندین نفر در فرآیند ترجمه همکاری کنند و بخشهای مختلف را ترجمه کنند، هماهنگی بین آنها دشوار است. اگر در کد مبدا از کتابخانه خاصی استفاده شده باشد، پیدا کردن معادل آن چالش بزرگیست؛ البته اگر معادلی وجود داشته باشد!
این مدلها، مدلهای یادگیری عمیق بسیار بزرگی هستند که از قبل بر روی حجم وسیعی از دادهها آموزش دیدهاند. این مدلها قابلیت تحلیل، بررسی و انجام کارهای مربوط به زبان را دارند. این مدلها با استفاده از NLP و مدلهای یادگیری ماشین و هوش مصنوعی تمرین داده میشوند و سپس با استفاده از دانشی که از زبان طبیعی دارند، قادر به نوشتن سریع کدهایی معتبر هستند. لازم به ذکر است که LLMها، در این حوزه، بر اساس کدهایی که در حال حاضر وجود دارند(به خصوص کدهایی که منبع باز هستند در سایتها و برنامههای مختلف)، آموزش داده میشوند؛ این قرار گرفتن در معرض نمونه کدهای متنوع به آنها کمک میکند تا الگوها، ساختارها و زبانهای برنامه نویسی مختلف را بیاموزند.

انواع مختلفی از باگها ممکن است هنگام ترجمه کد رخ دهد. باگهایی که در ادامه معرفی میشود مستقل از نوع طراحی مدلهاست و در انواع آنها ممکن است رخ دهند:
1. نقض الزامات زبان برنامه نویسی مقصد: هر زبان برنامه نویسی مجموعه قوانین مربوط به خود را داراست که باید برقرار باشند. به عنوان مثال یک import بدون استفاده در یک زبان برنامه نویسی ممکن است خطا ایجاد کند در حالی که در زبانهای برنامه نویسی دیگر نادیده گرفته میشود.
import "os"
import "strconv" # Unused imports are not permitted in Go.
2. کپی کردن syntax مبدا به مقصد.
const ld PI = atan2l(0, -1); # Original C++ code
PI = atan2l(0, -1) # Incorrect Go code
3. عدم تطابق رفتار API مبدا و مقصد: کتابخانه API اغلب در برنامههای هر زبان برنامه نویسی ای استفاده میشوند. در طول ترجمه، فراخوانیهای API در مبدا یا باید به فراخوانیهای معادل در زبان برنامه نویسی مقصد تبدیل شوند یا از ابتدا پیاده سازی شوند.
S.substring(i, i + 1) # Original Java code (returns String)
strings.IndexByte(S, i) # Incorrect Go code (returns Int64)
4. کمبود منطق کد مبدا در کد مقصد: مدلها ها ممکن است کدی را تولید کنند که با منطق برنامه منبع ارتباطی نداشته باشد، در نتیجه باعث می شود که رفتار کد ترجمه شده با کد مبدا تطابق نداشته باشد.
5. نوع نادرست داده: این دسته از اشکالات مربوط به تایپ نادرست اختصاص داده شده به متغیرهاست.
public static Class<File[]> FILES_VALUE=File[].class; # Java code
FILES_VALUE = List[os.path] # Incorrect Python code
6. فرمت خروجی: اگر منطق کد ترجمه شده درست باشد، اما فرمت خروجی متفاوت از قالب برنامه مبدا باشد، اشکال را در این دسته برچسب گذاری می کنیم.
System.out.print("H"); System.out.println(Y -1988); # Java code
print("H", Y - 1988) # Incorrect Python code
7. شرط و حلقههای نادرست.
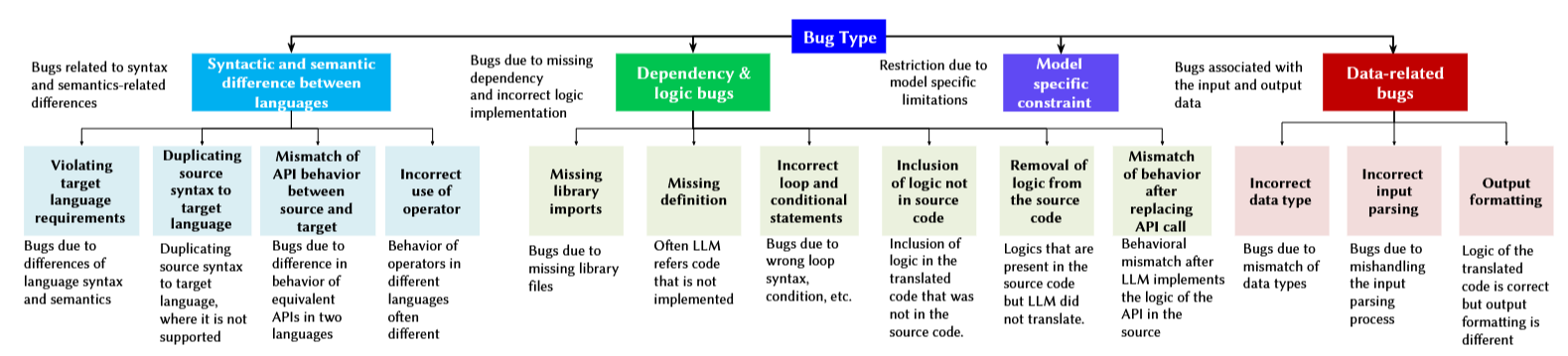
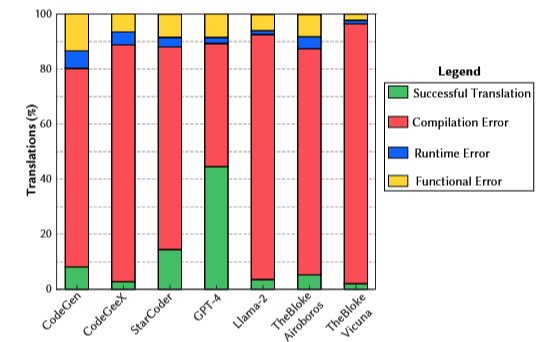
تحقیقاتی نیز بر روی خطاهای مرتبط با مدلهای مختلف وجود دارد که به شرح زیر است:
1. تولید کد طبیعی و خواناتر
هاLLM کدهایی تولید میکنند که به سبک و عبارات متداول زبان مقصد نزدیکتر هستند. این امر باعث افزایش خوانایی و نگهداری کد میشود.
2. انعطاف پذیری و خلاقیت بالا
هاLLM خلاق هستند و میتوانند کدهای جدید تولید کنند، حتی زمانی که ترجمه مستقیم امکانپذیر نباشد.
3. قابلیت تطبیق پذیری با نیازهای خاص پروژه
مدلها میتوانند بر اساس توضیحات و درخواستهای کاربر، ترجمهها را با اهداف خاصی (مانند بهینهسازی یا افزودن امنیت) تنظیم کنند.
4. پتانسیل برای استفاده در ترکیب با تکنیکهای دیگر
میتوان از LLMها در ترکیب با تکنیکهای دیگر مانند تحلیل برنامه برای بهبود دقت ترجمه استفاده کرد.
1. محدودیت دسترسی به متن و کانتکست کامل پروژه
به دلیل محدودیت در اندازه توکنها، LLMها نمیتوانند به تمامی اطلاعات مربوط به ساختارها، نوع متغیرها، متدها و وابستگیها در یک پروژه دسترسی داشته باشند. این کمبود کانتکست میتواند منجر به خطا یا کاهش کیفیت ترجمه شود.
2. احتمال تولید کدی که باگ دارد
در نظر داشته باشید که LLMها به صورت احتمالاتی عمل میکنند و ممکن است کدهایی تولید کنند که دارای باگهای منطقی یا مشکلات امنیتی باشند. این امر به خصوص در پروژههای پیچیده و با وابستگیهای زیاد بیشتر نمایان میشود.
3. غیر قابل پیشبینی بودن
برخلاف تکنیکهای غیر LLM (مانند ترنسپایلرها) که رفتارهای قابل پیشبینی دارند، LLMها میتوانند خروجیهای متغیری تولید کنند که نیاز به بررسی دستی دارند.
4. عدم قطعیت در پروژههای بزرگ و دنیای واقعی
فایلهای بزرگ و پروژههای واقعی اغلب دارای وابستگیهای پیچیده هستند. ترجمه دقیق این پروژهها بدون استفاده از ابزارهای مکمل، ممکن است فراتر از توانایی LLM باشد.
1. ترکیب مدلها با تکنیکهای مکمل غیر LLM
2. ارتقای مقیاس پذیری ترجمه برای پروژههای واقعی: استفاده از تکنیکهایی مانند تقسیمبندی فایلها به بخش های کوچکتر و ترجمه آنها به صورت جداگانه.
Op8en A8I’s Codex
این برنامه قادر به ترجمه کد از یک زبان به زبان دیگر در عین حفظ منطق و عملکرد اصلی است و آن را به ابزاری ارزشمند برای توسعه دهندگانی تبدیل می کند که به دنبال تطبیق سریع پروژه های خود با پشتههای فناوریهای مختلف هستند.
Micr8osoft’s CodeBERT
با همکاری Git8Hub توسعه یافته است، به طور خاص برای زبان های برنامه نویسی طراحی شده است. این برنامه بر روی مجموعه داده ای متشکل از زبان طبیعی و کد آموزش داده شده است که باعث میشود در ترجمه کد بین زبان های برنامه نویسی مختلف مهارت داشته باشد. آموزش دوگانه آن به آن اجازه میدهد تا هم نظرات قابل خواندن توسط انسان و هم منطق برنامه نویسی درون کد را درک کند.
هماهنگسازی با سیستمهای پیچیده: پروژههای واقعی معمولاً شامل کتابخانهها و APIهای خاص هستند. توسعه تکنیکهایی که بتوانند APIهای متناظر در زبان مقصد را پیدا کنند یا جایگزینهای مناسبی برای آنها بسازند، ضروری است.
تکنیکهای جدید برای مدیریت پروژههای بزرگ: ترجمه قطعات بزرگ کد به بخشهای کوچکتر به همراه حفظ وابستگیها، میتواند کیفیت ترجمه را به طور چشمگیری بهبود دهد.
رفع مشکلات محیطی: LLMها باید بتوانند با تفاوتهای میان محیطهای توسعه(Development Environment) در زبانهای مختلف تطبیق پیدا کنند، مثلاً تفاوتهای در مدیریت حافظه بین C++ و Python.
جمعبندی و نتیجهگیری
آینده ترجمه کد با استفاده از LLMها پر از فرصتها و چالشها است. از یک سو، پیشرفتهای تکنولوژی میتوانند ابزارهای قدرتمندتری برای توسعهدهندگان ایجاد کنند که فرآیند ترجمه را سریعتر، دقیقتر و کارآمدتر میکند. از سوی دیگر، چالشهای فنی و اخلاقی، نیازمند توجه دقیق و رویکردهای نوآورانه برای مدیریت مسائل پیچیدهای مانند حریم خصوصی و امنیت دادهها هستند.