پروژهٔ پایتون برای بررسی نتایج فوتبال و ضرایب شرطبندی

راهکارهای دادهمحور در انجام وظایف مختلف در سراسر جامعه جایگاه ویژهای پیدا کردهاند و با قدرتمندتر شدن مدلسازی داده، این حوزه به ابزاری مؤثر برای مواجهه با تصادفیبودن پدیدهها تبدیل شده است. در این مجموعه نوشتهها، هدف ما ساخت یک راهکار برای پیشبینی نتایج فوتبال بر اساس دادههایی است که از سراسر وب جمعآوری میشوند.
پیش از هر چیز لازم است هدف اصلی پروژه را مشخص کنیم؛ هدفی که هستهٔ اصلی کار ما را تشکیل میدهد. در زمان نگارش این مطلب، جام جهانی فوتبال فیفا در حال نزدیک شدن است و معمولاً در چنین رویدادهایی مردم دور هم جمع میشوند و روی نتایج بازیها و مسابقات گفت و گو میکنند؛ چه برای برنده شدن جایزه و چه صرفاً برای سرگرمی. این رفتار یک پدیدهٔ جهانی است و پیش بینی نتایج ورزشی صنعتی چند میلیارد دلاری به شمار میرود که میلیونها نفر را برای بررسی و تحلیل ضرایب به خود جذب میکند.
در چنین بستری، هدف اصلی این پروژه شکل میگیرد: ساخت ابزاری که بتواند به ما در پیش بینی نتایج فوتبال کمک کند. پس از مشخص شدن این هدف، میتوانیم مراحل لازم برای رسیدن به آن را بهصورت ساختیافته ترسیم کنیم.
اکنون هدف نهایی مشخص شده، اما هنوز هدفی کلی و دور به نظر میرسد. استفاده از نوعی مهندسی معکوس میتواند به شفافتر شدن مسیر کمک کند. نخستین ایدهای که به ذهن میرسد، ساخت یک برنامه کاربردی است که به ما امکان شبیهسازی استراتژیهای پیش بینی نتایج را بر اساس نوعی پیشبینی بدهد.
همانطور که قابل حدس است، چارچوب اصلی ما برای پیشبینی نتایج، یک مدل یادگیری ماشین یا یادگیری عمیق خواهد بود، چرا که قصد داریم از اطلاعات گذشته برای پیشبینی رویدادهای آینده استفاده کنیم. بر این اساس، لازم است دادههای ورودی را از منابع مختلف وب جمعآوری کنیم که اتفاقاً موضوع اصلی این مقالهٔ نخست محسوب میشود.
پیش از ورود به جزئیات وباسکریپینگ، مراحل مطرحشده را بهطور خلاصه مرور میکنیم:
جمعآوری داده
مهندسی ویژگی و مدلسازی
ساخت شبیهساز استراتژیهای شرطبندی
در نهایت، این پروژه در زمان نگارش همچنان در حال توسعه است و هدف اصلی آن، ارائهٔ یک گزارش مطالعاتی برای خود من است. بنابراین بهتر است با همین نگاه به آن بنگرید و در ارائهٔ پیشنهاد یا نقد کاملاً آزاد باشید. میتوانید به مخزن کد پروژه از طریق ارتباط با من دسترسی داشته باشید. خب، کافی است؛ بیایید وارد بحث جمعآوری داده شویم.
در جستوجوهای انجامشده در وب، با منابع دادهٔ مختلفی روبهرو شدم که هر کدام با هدف خاصی انتخاب شدند. در ادامه آنها را معرفی کرده و ویژگیهایشان را توضیح میدهم.
اولین مجموعهدادهای که قصد داریم بسازیم، دیتاستی است که برای تغذیهٔ مدل با آمارها و رویدادهای گذشتهٔ مسابقات فوتبال استفاده میشود. منبعی که از آن داده جمعآوری میکنیم وبسایت fbref است و میتوانید نتیجهٔ نمونهٔ وباسکریپینگ را در فایل sample.pkl در مخزن پروژه مشاهده کنید. نگاهی به ساختار صفحهٔ اصلی وبسایت fbref بیندازید:
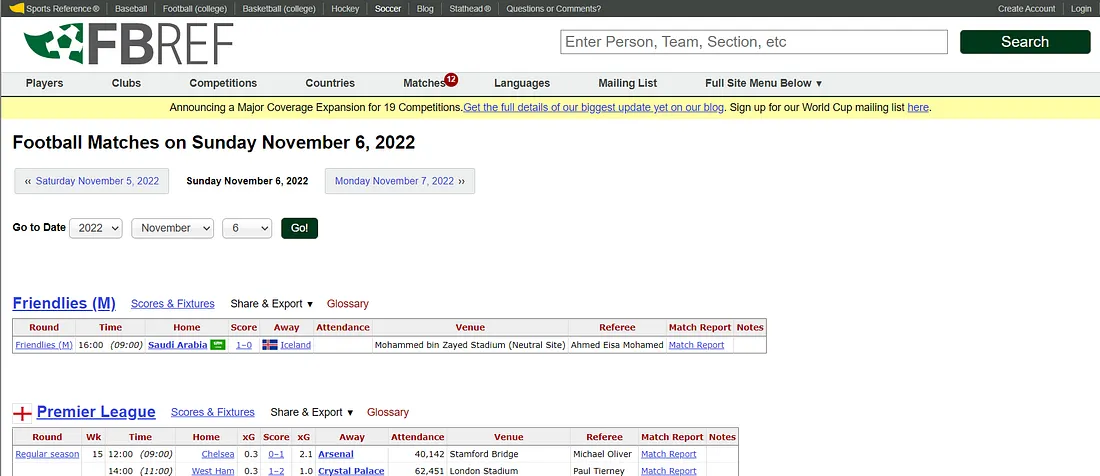
در ادامه، هدف ما تهیهٔ یک مجموعهدادهٔ سری زمانی است که شامل اطلاعات موجود در این صفحه در تاریخهای مختلف باشد؛ همچنین دادههایی که در لینکهای گزارش مسابقات قرار دارند نیز جمعآوری خواهند شد، چرا که این گزارشها آمارهای دقیقتر و جزئیتری از هر بازی ارائه میدهند. در تصویر زیر نیز نمونهای از گزارش یک مسابقه نشان داده شده است.
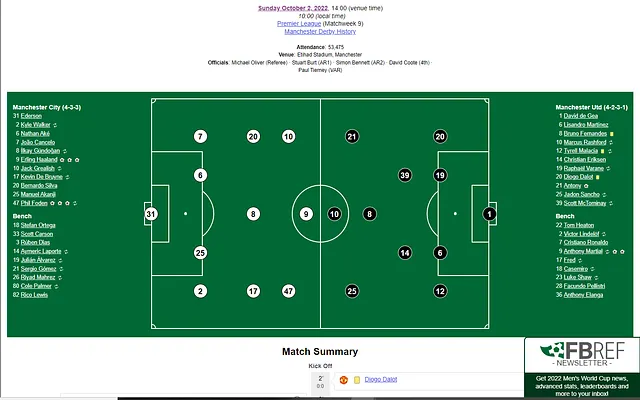
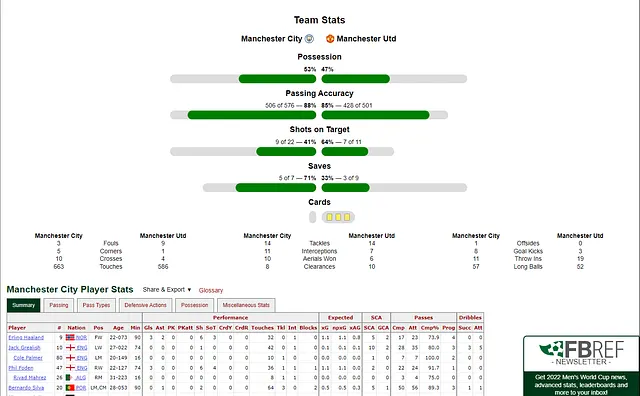
سپس با نگاهی به وبسایت و ساختار آن مشخص میشود که نیازی به پردازش کدهای JavaScript نداریم؛ موضوعی که در غیر این صورت میتوانست کار وباسکریپینگ را کمی پیچیدهتر کند. بنابراین از این مرحله به بعد از BeautifulSoup استفاده میکنیم.
اکنون باید ساختار اسکریپینگ خود را بر اساس اطلاعات موردنیازمان طراحی کنیم، چرا که اسکریپر بهصورت خطی عمل کرده و دادههای مورد نظر را جمعآوری میکند. کد نیز در قالب یک کلاس با نام scrapper پیادهسازی شده و تمام قابلیتها و عملکردهای لازم درون این کلاس تعریف شدهاند.
حال بیایید مراحلی را که قدمبهقدم طی کردهام مرور کنیم:
1. رفتن به تاریخ مشخصشده در صفحهٔ مسابقات
در صفحهٔ مسابقات، به تاریخ موردنظر میرویم. این فرآیند و تمام مراحل بعدی، بهصورت روزانه در بازهای که کاربر تعریف میکند تکرار میشوند. تابع getMatches() یک تاریخ شروع و یک تاریخ پایان دریافت میکند که محدودهای را مشخص میکنند که اسکریپر در آن اجرا خواهد شد.
مطابق مثال مرحلهٔ اول، متغیر leagues میتواند توسط کاربر مقداردهی شود تا لیگهایی که قصد اسکریپ آنها را دارد انتخاب کند. همچنین در کد میتوان یک بلوک try-except مشاهده کرد که برای مدیریت خطاهای ساختاری استفاده میشود؛ خطاهایی مانند جدولهای جعلی یا غیرواقعی که ممکن است در وبسایت ظاهر شوند.
در این مرحله، علاوه بر اضافه کردن اطلاعات موردنظر به لیستها، به استفاده از time.sleep توجه ویژهای شده است؛ این کار برای کنترل تعداد درخواستها در یک بازهٔ زمانی مشخص انجام میشود تا از مسدود شدن IP جلوگیری شود.
نکتهٔ مهم دیگر، ذخیرهسازی لینک گزارش هر مسابقه است که در متغیر score قرار دارد. با استخراج لینک از متغیر score بهجای لینک مستقیم «Match Report»، میتوان از ذخیره شدن لینک مسابقاتی که به تعویق افتاده یا لغو شدهاند جلوگیری کرد. این موضوع ما را به مرحلهٔ بعد هدایت میکند.
همانطور که مشاهده میکنید، این مرحله کمی پیچیدهتر است؛ بنابراین توضیح کوتاهی ارائه میشود:
کارتهای زرد و قرمز با شمارش و جمعکردن تعداد آبجکتهای کارت در دستههای زرد و قرمز محاسبه میشوند.
سایر آمارها به این روش استخراج شدهاند:
بررسی اینکه آیا آماری خاص در دیکشنری آمارهای مورد انتظار وجود دارد یا خیر
در صورت وجود، دیکشنری با مقادیر مرتبط با آن آمار بهروزرسانی میشود؛ مقادیری که معمولاً قبل و بعد از نام آن آمار در ساختار صفحه قرار دارند
خوانندهٔ دقیق احتمالاً متوجه شده است که مرحلهٔ ۲ (دریافت جدول هر لیگ) الزاماً ضروری نیست، اما این مرحله انعطافپذیری لازم برای فیلتر کردن مسابقات بر اساس لیگهای موردنظر را در اختیار ما قرار میدهد؛ رویکردی که من در این پروژه انتخاب کردهام.
بهعنوان یک گام اضافی، نیاز به تعریف یک مکانیزم Checkpoint احساس شد، زیرا اسکریپر ممکن است با خطاهای غیرقابل پیشبینی مواجه شود یا وبسایت fbref دسترسی IP را مسدود کند. در چنین شرایطی، از دست رفتن زمان پردازش میتواند بسیار زیاد باشد.
به همین دلیل، در اولین روز هر ماه، وضعیت فعلی فرآیند اسکریپ ذخیره میشود تا در صورت بروز خطای غیرمنتظره، یک نقطهٔ امن برای ادامهٔ کار در اختیار داشته باشیم.
و این عملاً تمام فرایند است. در انتهای کد، میتوانید حلقهٔ بهروزرسانی روزانه (iterator تاریخ) و همچنین عملیات لازم برای قالببندی DataFrame نهایی را مشاهده کنید.
تمام این فرایند به ما امکان میدهد دادههایی را جمعآوری کنیم تا مدلی برای پیشبینی نتایج مسابقات فوتبال بسازیم؛ با این حال، هنوز لازم است دادههای مربوط به مسابقات پیشِرو را نیز اسکریپ کنیم تا بتوانیم از دادههایی که تاکنون جمعآوری کردهایم، به شکلی کاربردی استفاده کنیم.
بهترین منبعی که برای این منظور پیدا کردم SofaScore بود؛ یک اپلیکیشن که اطلاعات مربوط به مسابقات و بازیکنان را جمعآوری و ذخیره میکند. علاوه بر این، SofaScore ضرایب واقعی شرطبندی در Bet365 را نیز برای هر مسابقه در اختیار قرار میدهد.
وبسایت SofaScore بهطور خاص از JavaScript برای بارگذاری محتوا استفاده میکند؛ به این معنا که کد HTML بهصورت کامل و مستقیم در دسترس نیست تا بتوان از آن با BeautifulSoup استفاده کرد. بنابراین لازم است از یک چارچوب دیگر برای استخراج دادهها بهره ببریم. در این پروژه، من پکیج پرکاربرد Selenium را انتخاب کردم که به ما اجازه میدهد از طریق کد پایتون، وب را درست مانند یک کاربر انسانی مرور کنیم.
در عمل، میتوانید مشاهده کنید که وبدرایور مرورگر را باز میکند، کلیک انجام میدهد و بین صفحات جابهجا میشود. مرورگری که من انتخاب کردم Chrome بوده است.
در تصویر زیر، صفحهٔ اصلی SofaScore با مسابقات در حال برگزاری یا پیشِرو نمایش داده شده است و در سمت راست میتوانید نتیجهٔ کلیک روی یکی از مسابقات و سپس انتخاب گزینهٔ LINEUPS را مشاهده کنید.
همانطور که توضیح داده شد، Selenium مانند یک کاربر انسانی وب را مرور میکند؛ بنابراین طبیعی است که این فرایند کمی کندتر باشد و همین موضوع صحت دارد. در نتیجه باید در هر مرحله دقت بیشتری به خرج دهیم تا روی دکمهای که هنوز وجود ندارد کلیک نکنیم؛ چرا که کدهای JavaScript تنها پس از انجام برخی تعاملات کاربر رندر میشوند.
بهعنوان مثال، وقتی روی یک مسابقه خاص کلیک میکنیم، سرور به زمانی نیاز دارد تا منوی کناریای که در تصویر دوم مشاهده میشود را بارگذاری کند. اگر در همین فاصله کد بخواهد روی دکمهٔ Lineup کلیک کند، با خطا مواجه خواهد شد. حالا بیایید وارد بخش کد شویم.
1. باز کردن صفحهٔ اصلی و فعالسازی دکمهٔ «نمایش ضرایب» (Show Odds)
همانطور که اشاره شد، پس از راهاندازی درایور و ورود به آدرس SofaScore، باید منتظر بمانیم تا دکمهٔ نمایش ضرایب رندر شود و سپس روی آن کلیک کنیم. همچنین لیستهایی ایجاد میکنیم تا اطلاعات استخراجشده را در آنها ذخیره کنیم.
در این بخش کار خاص یا پیچیدهای انجام نمیشود، اما توجه به این نکته مهم است که در خط ۸ تنها مسابقاتی فیلتر میشوند که هنوز آغاز نشدهاند. دلیل این کار آن است که پردازش مسابقات در حال برگزاری، اسکریپ ضرایب را بسیار پیچیدهتر میکند. علاوه بر این، هنوز مشخص نیست شبیهساز شرطبندی آینده چگونه عمل خواهد کرد و ممکن است با نتایج زنده عملکرد درستی نداشته باشد.
بهطور خلاصه، مطابق توضیحات بالا، منتظر میمانیم تا منوی کناری مربوط به هر مسابقه بهطور کامل بارگذاری شود، سپس روی دکمهٔ Lineup کلیک میکنیم و نام بازیکنان را استخراج میکنیم. در این مرحله باید دقت ویژهای به خرج داد، زیرا نام کاپیتان هر تیم در وبسایت با قالببندی متفاوتی نمایش داده میشود؛ به همین دلیل، یک تابع کمکی (helper function) برای مدیریت این مورد پیادهسازی کردیم.
پس از آن، نام بازیکنان هر مسابقه در یک DataFrame مجزا ذخیره میشود و در نهایت، پس از اتمام کل فرایند، اطلاعات مسابقات با ترکیبهای پیشبینیشدهٔ تیمها با یکدیگر ادغام (concatenate) میشوند.
خب، این هم از مطلب امروز. در این مقاله دو ابزار اسکریپینگ ساختیم که میتوانند:
اطلاعات مربوط به مسابقات گذشتهٔ فوتبال را جمعآوری کنند
و دادههای مربوط به مسابقات پیشِرو را استخراج نمایند
این تنها آغاز پروژه است. در ادامه میتوانید منتظر مقالات جدیدی دربارهٔ:
ساخت مجموعهداده شامل اطلاعات بازیکنان
مدلسازی پیشبینی نتایج
و در نهایت، پیادهسازی شبیهساز استراتژیهای پیش بینی
باشید. امیدوارم از این مطلب لذت برده باشید! 😊