
کلاس بندی (Classification) تا قبل از کلاس بندی با مدلی مثل رگرسیون میومدیم حدس میزدیم اگر داده کجای خط باشه تقریبا چه عددی میتونه داشته باشه حالا که کلاس بندی داریم یکم متفاوت تر میشه :) تو Classification، به جای پیشبینی یه مقدار پیوسته، داری دادهها رو به دستههای مجزا (برچسبها) تقسیم میکنی. خروجی مدل یه دسته یا کلاسه، نه یه عدد. برگردیم به مثال ایمیلها: تو دیتاست ما، میخوایم پیشبینی کنیم یه ایمیل "Spam" هست یا "Non-Spam". این یعنی خروجی فقتصویر ۱ : کلاس بندی (Classification)
ط یکی از این دو دسته میتونه باشه. مدل (مثل درخت تصمیم) به جای اینکه یه خط بکشه، یه "مرز تصمیمگیری" (decision boundary) میسازه که دادهها رو به دو دسته جدا میکنه. یه مثال سادهتر: فرض کن میخوای تصمیم بگیری یه میوه سیبه یا پرتقاله. ویژگیهایی که داری: وزن میوه و رنگش (قرمز یا نارنجی). دیتاستت اینه:
سیب: وزن 150 گرم، رنگ قرمز
پرتقال: وزن 200 گرم، رنگ نارنجی
سیب: وزن 140 گرم، رنگ قرمز
پرتقال: وزن 190 گرم، رنگ نارنجی حالا یه میوه جدید داری: وزن 170 گرم، رنگ نارنجی. مدل Classification (مثلاً درخت تصمیم) میگه: اگه رنگ نارنجی باشه و وزن بالای 160 گرم باشه، احتمالاً پرتقاله. پس این میوه جدید رو تو دسته "پرتقال" میذاره. خروجی تو Classification پیوسته نیست، گسسته است!
مثلاً تارگت ما تو این مسئله، اسپم بودن یا نبودن ایمیل بود (یعنی Label که میتونه "Spam" یا "Non-Spam" باشه). تو Classification، تارگت یه دستهی گسسته (discrete) هست، نه یه عدد پیوسته. اینجا میتونیم بگیم "Non-Spam" = 0 و "Spam" = 1.
طبقهبندی (Classification) کاربرد: وقتی میخوایم جواب نهایی (همون متغیر هدف) یک مقدار گسسته باشه. "گسسته" یعنی چیزی که میشه شمرد یا یه دستهبندی مشخص داره، نه یه عدد پیوسته.
مثال: فرض کن یه متن به کامپیوتر میدی و میخوای بفهمی این متن مثبته یا منفی یا خنثی. جواب فقط یکی از این دستههاست. یا مثلاً میخوای تشخیص بدی یه عکس، گربه است یا سگ. جواب یک "کلاس" یا "دسته" مشخصه.
رگرسیون (Regression) کاربرد: وقتی میخوایم جواب نهایی (همون متغیر هدف) یک مقدار پیوسته باشه. "پیوسته" یعنی هر عددی میتونه باشه، مثل دما، قیمت یا حقوق.
مثال: فرض کن اطلاعاتی مثل مدرک تحصیلی، سابقه کار، محل زندگی و سطح تجربه یک نفر رو به کامپیوتر میدی و میخوای میزان حقوق اون شخص رو پیشبینی کنی. حقوق میتونه هر عددی باشه (مثلاً $1500، $2345.75، $50000) و یک عدد پیوسته است. مثال دیگه میتونه پیشبینی قیمت خانه بر اساس متراژ و تعداد اتاقها باشه.
ما باید بدونیم با توجه به داده ای که داریم باید از چه نوع Classification استفاده کنیم فقط قبلش این ۲ مفهوم رو بدونیم :
Class (کلاس): نوع یا دسته کلی. (مثلا سگ)
Label (برچسب): اسم یا شناسه اون نوع برای هر تکتک داده (مثلا برچسب سگ روی یک سگ در کلاس سگ ها)
مثال: مثلاً میخوایم تشخیص بدیم یک عکس داده شده کامیون هست یا خیر. (یا ایمیل هرزنامه است یا نه.)
تعداد کلاس ها در این حالت ۲ تا بیشتر نیست (کلاس هرزنامه بودن و نبودن)
مدل ها :
Logistic Regression
Support Vector Machine (SVM)
K-Nearest Neighbors
Decission Trees
مثال: فرض کن یه عکس به مدل میدی و مدل به درستی تشخیص میده که اون عکس هواپیماست. (یا مثلاً تشخیص بده این حیوان "گربه" است یا "سگ" یا "پرنده".)
تعداد کلاس ها در این حالت بیشتر از ۲ تا میباشد (سگ,گربه,پرنده)
مدل ها :
Random Forest
Naive Bayes
K-Nearest Neighbors
Gradient Boosting
SVM
Logistic Regression
در این نوع کلسیفیکیشن برای رسیدن به نتیجه نهایی باید تمام کلاس ها رو تست کنیم مثلا یک تصویر به مدل میدیم و میخوایم بفهمیم این تصویر سیب , پرتقال یا موز میباشد ؟
که در نهایت به صورت زیر کار میکنه :
عکس رو به طبقهبند ۱ (سیب vs پرتقال) میدیم:طبقهبند میگه: "این عکس به احتمال زیاد سیبه." (۱ رای برای سیب)
همون عکس رو به طبقهبند ۲ (سیب vs موز) میدیم:طبقهبند میگه: "این عکس به احتمال زیاد سیبه." (۱ رای برای سیب)
باز همون عکس رو به طبقهبند ۳ (پرتقال vs موز) میدیم:طبقهبند میگه: "این عکس به احتمال زیاد موزه." (۱ رای برای موز)
حالا رایهای هر کلاس رو جمع میکنیم:
سیب: ۲ رای
پرتقال: ۰ رای
موز: ۱ رای
کلاسی که بیشترین رای رو آورده باشه، نتیجه نهایی پیشبینی ماست. در این مثال، "سیب" با ۲ رای برنده میشه.
اسم این تکنیک هست :
One-Vs-One
One-Vs-Rest
مثال : در پردازش زبان طبیعی (NLP) و برچسبگذاری خودکار: یک متن میتونه چندین موضوع (تاپیک) رو پوشش بده.
در بینایی کامپیوتر (Computer Vision): یک عکس میتونه چندین شیء مختلف داشته باشه. مثلاً مدلی که پیشبینی میکنه یک عکس شامل "هواپیما، قایق، کامیون و سگ" هست. (در یک عکس میتونه هم سگ باشه هم درخت هم ماشین).
مدل ها :
درختان تصمیم چندبرچسبی (Multi-label Decision Trees)
گرادیان بوستینگ چندبرچسبی (Multi-label Gradient Boosting)
جنگلهای تصادفی چندبرچسبی (Multi-label Random Forests)
حالا بیایم یه دیتاست ساده بسازیم و اون رو کلاسبندی کنیم:
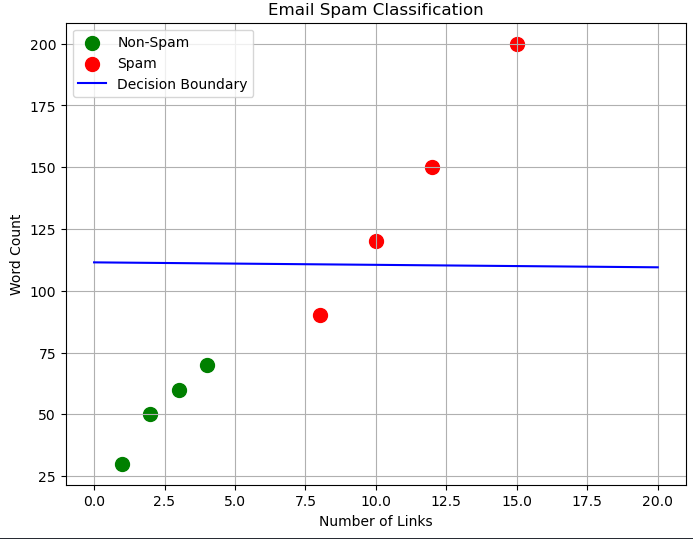
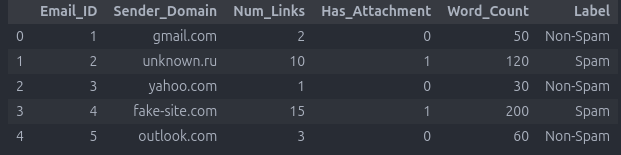
حالا میخوایم اون رو کلاس بندی کنیم :
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier import matplotlib.pyplot as plt data = { 'Num_Links': [2, 10, 1, 15, 3, 8, 4, 12], 'Word_Count': [50, 120, 30, 200, 60, 90, 70, 150], 'Label': [0, 1, 0, 1, 0, 1, 0, 1] # 0 = Non-Spam, 1 = Spam } df = pd.DataFrame(data) X = df[['Num_Links', 'Word_Count']] y = df['Label'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) model = DecisionTreeClassifier(random_state=42) model.fit(X_train, y_train) df['Predicted_Label'] = model.predict(X) df
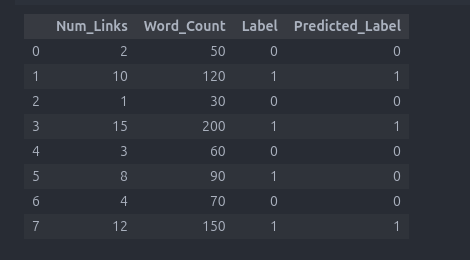
در نهایت همانطور که مشاهده میکنید Predict_Label و Label متناظر همدیگه هستن و یعنی مدل داره به درستی کار میکنه .
اما آیا این داده چقدر دقت داره ؟
توی بررسی نتیجه Classification دیگه مثل رگرسیون با دقت (Accuracy) سر و کار نداریم .
اینبار خروجی مدل ما دیگه یه عدد نیست. مثلاً مدل میگه:
این ایمیل اسپمه یا نه؟
این عکس سگ داره یا گربه؟
این آدم مریضه یا سالم؟
برای درک بهتر این قسمت میتونید این مقاله از سایت LabelF هم مطالعه کنید که عالیه :
https://www.labelf.ai/blog/what-is-accuracy-precision-recall-and-f1-score
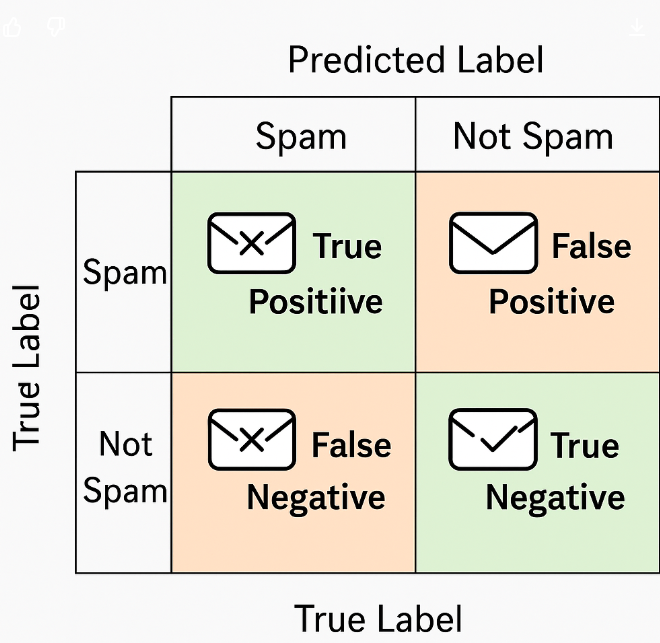
ردیف عمودی شرط اصلی ما بوده که دارای + و - میباشد .
ردیف افقی نتیجه Classification ما بوده
تمام داده ها بین این ۴ خونه پخش میشوند مثل شکل زیر نتیجه CLassification یک عکس CT_Scan
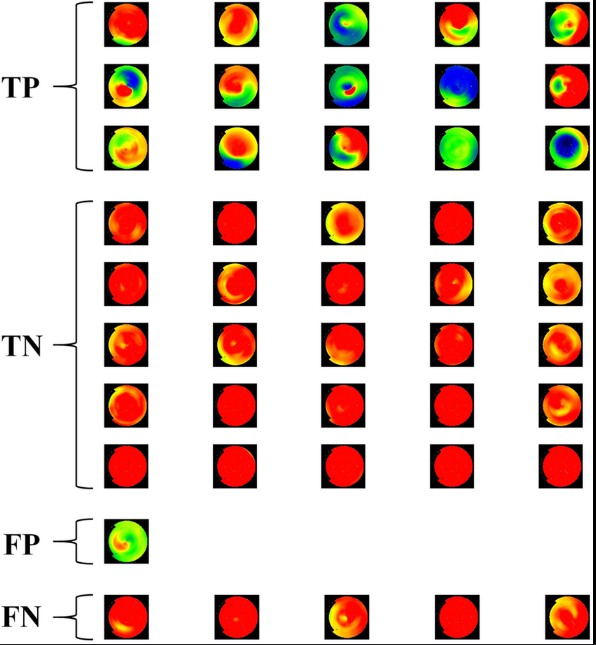
حالا چطوری از این داده ها نتیجه بگیریم ؟ قبلش این متریک ها رو یاد بگیریم :
از بین همه چیزایی که مدل گفت مریضان، چندتاش واقعاً مریض بودن؟
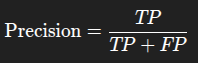
از بین همه آدمهای واقعاً مریض، مدل چندتا رو پیدا کرد؟
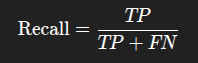
وقتی بخوای Precision و Recall رو با هم در نظر بگیری
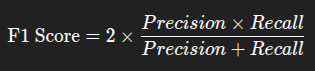
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import confusion_matrix, classification_report np.random.seed(0) n = 1000 data = pd.DataFrame({ 'num_links': np.random.poisson(2, n), 'has_offer': np.random.randint(0, 2, n), 'has_attachment': np.random.randint(0, 2, n), 'length': np.random.normal(300, 50, n).astype(int), }) data['is_spam'] = ((data['num_links'] > 3) | (data['has_offer'] == 1)).astype(int) X = data.drop('is_spam', axis=1) y = data['is_spam'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) model = RandomForestClassifier(random_state=42) model.fit(X_train, y_train) y_pred = model.predict(X_test) cm = confusion_matrix(y_test, y_pred) report = classification_report(y_test, y_pred) print("Confusion Matrix:\n", cm) print("\nClassification Report:\n", report)
نتیجه :
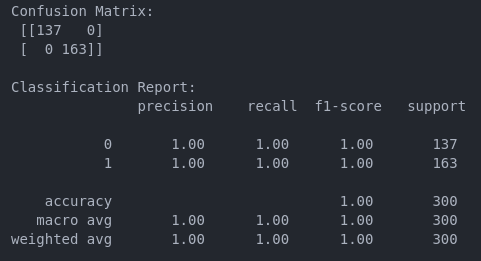
حالا تحلیل کنیم :
نتیجه Confusion Matrix (دقیقا مثل تصویر ۵)

مدل تمام ایمیلهای واقعی Not Spam رو درست تشخیص داده (137 مورد).
مدل تمام ایمیلهای واقعی Spam رو هم درست تشخیص داده (163 مورد).
هیچ ایمیلی اشتباه طبقهبندی نشده!
این مورد رو در مسئله بعدی به صورت کامل و دقیق بررسی میکنیم چون مربوط میشه به ImBalancedData
این بود مقاله کلاس بندی (Classification) امیدوارم از این مقاله لذت برده باشید .