
یک نمونه دیتاست که داده خالی داره نشونتون بدم :
import pandas as pd import numpy as np data = { 'Name': ['Ali', 'Sara', 'Reza', 'Niloofar', 'Omid'], 'Age': [25, 28, np.nan, 22, 30], 'Score': [85, np.nan, 78, 90, 88], 'Gender': ['M', 'F', 'M', 'F', np.nan] } df = pd.DataFrame(data)
چطوری بفهمیم دیتاستمون داده های NAN داره یا خیر :
df.info()
یک خروجی میده به این شکل :
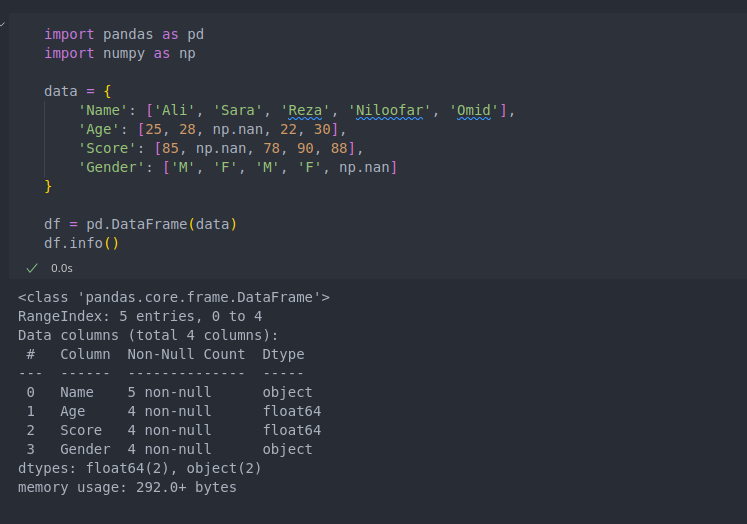
دقت کنید نوشته
5 Entries یعنی ما ۵ تا داده ردیف داده داریم
حالا نگاه کنیم برای هر ستون نوشته مثلا 4 non-null معنیش میشه اینکه ما ۵ تا داده داریم که ۴ تاش نال نیستن و یکیشون نال هستن
یک روش دیگه و باحالتر برای فهمیدن Missing Value ها :
import missingno as msno %matplotlib inline msno.matrix(collisions.sample(250))

الان دیتا رو ببینید مقادیری داره که NAN هستند (وجود ندارند) خب حالا باهاشون چیکار کنیم ؟ بیاید بگم بهتون :
اگر کیفیت دادهها برات مهمتر از تعدادشونه یا تعداد دادههای ناقص کمه، میتونی کل سطرهایی که NaN دارن رو حذف کنی.
df_drop_rows = df.dropna()
اگر ستونی مقدارهای زیادی گمشده داره و اطلاعات ارزشمندی منتقل نمیکنه، میتونی حذفش کنی.
df_drop_cols = df.drop(columns=['Gender'])
اگر نمیخوای دادهای رو حذف کنی، میتونی مقدارهای گمشده عددی رو با میانگین یا میانه پر کنی، و دادههای متنی (categorical) رو با مد (پُرتکرارترین مقدار).
df_mean_imputed = df.copy() df_mean_imputed['Age'].fillna(df['Age'].mean(), inplace=True) df_mean_imputed['Score'].fillna(df['Score'].mean(), inplace=True) df_mean_imputed['Gender'].fillna(df['Gender'].mode()[0], inplace=True)
4-Regression
هدف: پر کردن Age گمشده با مدل LinearRegression با توجه به Score
from sklearn.linear_model import LinearRegression # جدا کردن سطرهایی که Age ندارن df_reg = df.copy() df_known = df_reg[df_reg['Age'].notna()] df_unknown = df_reg[df_reg['Age'].isna()] # مدل رگرسیون ساده model = LinearRegression() model.fit(df_known[['Score']], df_known['Age']) # پیشبینی مقدار گمشده predicted_age = model.predict(df_unknown[['Score']]) df_reg.loc[df_reg['Age'].isna(), 'Age'] = predicted_age
Score با استفاده از نزدیکترین رکوردهاfrom sklearn.impute import KNNImputer # انتخاب فقط ستونهای عددی برای KNN df_knn = df[['Age', 'Score']].copy() # اجرای KNN برای پر کردن مقادیر گمشده imputer = KNNImputer(n_neighbors=2) df_knn_imputed = imputer.fit_transform(df_knn) # جایگذاری در دیتافریم اصلی df_knn_result = df.copy() df_knn_result['Age'] = df_knn_imputed[:, 0] df_knn_result['Score'] = df_knn_imputed[:, 1]
امیدوارم از این مطلب هم استفاده کرده باشید و نظرتون رو خوشحال میشم بدونم .