
فرض کن داری با یک مدل یادگیری ماشین کار میکنی که میخواد مثلاً بیماری قلبی رو پیشبینی کنه.
برای این کار، اطلاعات مختلفی از بیماران داری، مثل:
سن (Age)
فشار خون (Blood Pressure)
کلسترول (Cholesterol)
ضربان قلب (Heart Rate)
گروه خونی
قد، وزن، رنگ چشم!
و کلی ویژگی دیگه...
اما واقعاً آیا همهی این ویژگیها برای پیشبینی بیماری مهم هستن؟ نه!
پس بیاید ویژگی های بدرد بخور رو انتخاب کنیم Feature Selections
چون بعضی ویژگیها اطلاعات تکراری یا بیربط دارن
بعضیها فقط باعث سردرگمی مدل و افت دقت میشن
دادهی کمتر = مدل سریعتر، سادهتر و دقیقتر
Feature Engineering یعنی ساختن یا اصلاح ویژگیها (مثلاً BMI رو از وزن و قد بسازی)
Feature Selection یعنی انتخاب بهترینها و حذف بقیه
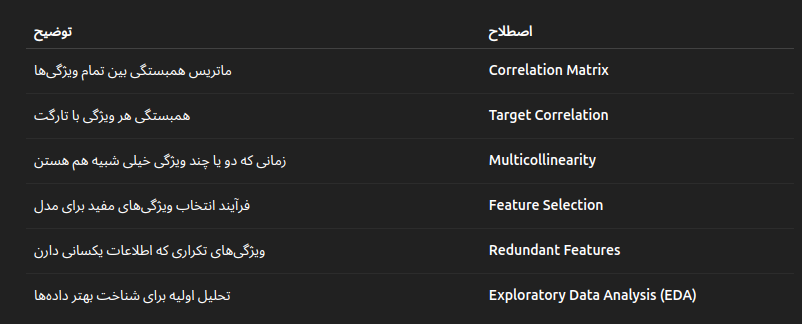
1-همبستگی (Correlation):
ابتدا میایم HeatMap رو رسم میکنیم و سپس ویژگیهایی که بیشترین همبستگی رو با Target دارن، نگه میداریم.
کد رسم HeatMap :
import seaborn as sns import matplotlib.pyplot as plt # انتخاب فقط ستونهای عددی numeric_df = df.select_dtypes(include=["int64", "float64"]) # محاسبه همبستگی correlation_matrix = numeric_df.corr() # رسم heatmap plt.figure(figsize=(10, 6)) sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm", fmt=".2f", linewidths=0.5) plt.title("Correlation Matrix") plt.show()
نتیجه :
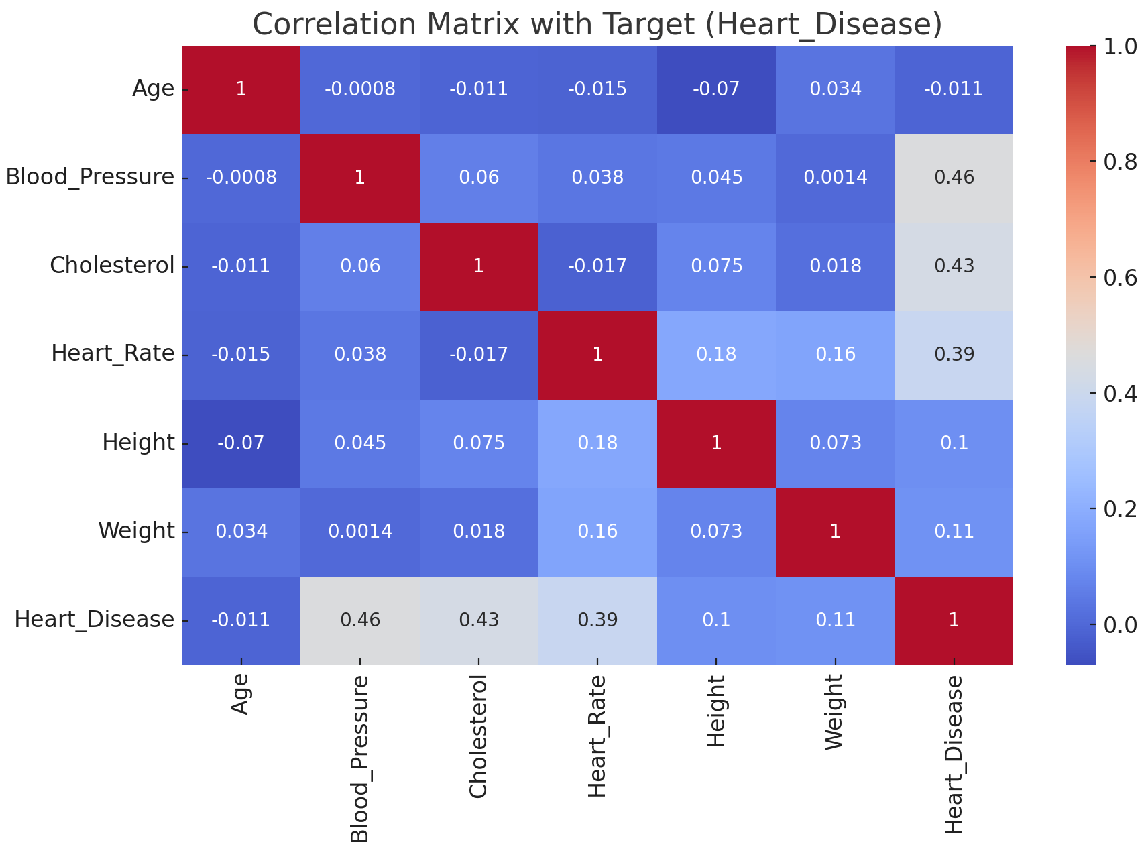
به نمودار بالا نگاه کنید .
میزان همبستگی داده ها رو با Heart_Disease که تارگتمونه میتونید مشاهده کنید
این اصطلاحات رو یاد بگیرید :
قدمهای تحلیل دقیق
از سطر یا ستون مربوط به Heart_Disease استفاده کن تا بفهمی هر ویژگی چقدر روی تارگت اثر داره.
اگر مقدار همبستگی با Heart_Disease بزرگ باشه (مثلاً >0.4 یا <-0.4):
این ویژگی احتمالاً اطلاعات مفیدی در مورد پیشبینی تارگت داره.
✅ نگهدار (Strong predictor)
اگر مقدار خیلی کم باشه (مثلاً بین -0.1 تا 0.1):
نشون میده که ارتباط خطی خاصی با تارگت نداره.
🔍 بررسی کن که آیا در مدلهای پیچیدهتر مفید هست یا نه.
❌ در مراحل اولیه میتونه کاندید حذف (Low importance) باشه.
📌 این تکنیک اسمش هست: Target-wise Correlation Analysis
اگر دو ویژگی با هم همبستگی بالا (مثلاً >0.85 یا <-0.85) داشته باشن:
به احتمال زیاد اطلاعات تکراری دارن و یکیشون اضافهست.
این مشکل به اسم Multicollinearity شناخته میشه.
🔁 راهکار: یکی از اونها رو حذف کن (ترجیحاً اونی که با تارگت همبستگی کمتری داره)
📌 اسم این تحلیل هست: Redundancy Analysis یا بررسی Multicollinearity
این روش با ترکیب خودش با Logistic Regression (که بعدا در موردش صحبت میکنیم) کار میکنه و برای ما بهترین ویژگی ها رو انتخاب میکنه
شروع با تمام ویژگیها: ابتدا مدل رو با همه فیچرها آموزش میده.
محاسبه اهمیت ویژگیها: بررسی میکنه که هر فیچر چقدر در پیشبینی تارگت نقش داره.
حذف ضعیفترین فیچر: ضعیفترین فیچر رو حذف میکنه.
تکرار مراحل بالا: این فرآیند رو تکرار میکنه تا به تعداد مشخصی از ویژگیها (که ما مشخص میکنیم) برسه.
سفارشیپذیر: میتونی تعداد ویژگی نهایی رو خودت تعیین کنی (n_features_to_select).
قابل ترکیب با مدلهای مختلف: مثلاً با Logistic Regression برای دادههای خطی یا با Random Forest برای دادههای پیچیدهتر.
یادگیرندهمحور: چون از خود مدل برای تعیین اهمیت ویژگی استفاده میکنه، معمولاً دقت خوبی داره.
هزینه محاسباتی زیاد: چون مدل چندین بار آموزش داده میشه.
ممکنه گیر کنه در local minimum: چون ویژگیها بهصورت greedy حذف میشن.
مثال کدی که داریم :
from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import LabelEncoder import pandas as pd categorical_columns = ["Age_Group", "BP_Category", "Cholesterol_Level"] df_encoded = df.copy() for col in categorical_columns: df_encoded[col] = LabelEncoder().fit_transform(df_encoded[ X = df_encoded.drop(columns=["PatientID", "Target"]) y = df_encoded["Target"] model = LogisticRegression() rfe = RFE(model, n_features_to_select=4) rfe.fit(X, y) selected_features = X.columns[rfe.support_]
که در خروجی به شما یک آرایه میده که بهترین پیشنهادش برای ویژگی ها کدوم ویژگی ها میباشد .
['Blood_Pressure', 'Cholesterol', 'Heart_Rate', 'BP_Category']
انتخاب چند زیرمجموعه از ویژگیها → آموزش مدل روی هر زیرمجموعه → ارزیابی عملکرد مدل → انتخاب بهترین زیرمجموعه.
تعریف:
شروع با مجموعه خالی از ویژگیها و به تدریج اضافه کردن ویژگیهایی که بیشترین بهبود عملکرد مدل را دارند.
مزیت: کمهزینهتر از جستجوی همه زیرمجموعهها
کد نمونه:
pythonCopyEditfrom sklearn.datasets import load_iris from sklearn.linear_model import LogisticRegression from sklearn.feature_selection import SequentialFeatureSelector X, y = load_iris(return_X_y=True) model = LogisticRegression(max_iter=200) sfs = SequentialFeatureSelector(model, n_features_to_select=2, direction='forward') sfs.fit(X, y) print("Selected features indices:", sfs.get_support(indices=True))
تعریف:
شروع با تمام ویژگیها و حذف تدریجی ویژگیهایی که کمترین تاثیر را دارند.
مزیت: مناسب وقتی تعداد ویژگیها کم است و میخواهیم اطمینان داشته باشیم هیچ ویژگی مهمی حذف نمیشود
کد نمونه:
pythonCopyEditsbs = SequentialFeatureSelector(model, n_features_to_select=2, direction='backward') sbs.fit(X, y) print("Selected features indices:", sbs.get_support(indices=True))
تعریف:
یک مدل آموزش داده میشود و ویژگیهای کماهمیت بر اساس وزن مدل به صورت تکراری حذف میشوند تا تعداد مشخصی ویژگی باقی بماند.
مزیت: دقت بالا به خاطر ارزیابی دقیق وزن هر ویژگی در مدل
کد نمونه:
pythonCopyEditfrom sklearn.feature_selection import RFE rfe = RFE(estimator=model, n_features_to_select=2) rfe.fit(X, y) print("Selected features indices:", rfe.get_support(indices=True))