در دنیای یادگیری ماشین، مدیریت مدلها و آزمایشها میتواند چالشبرانگیز باشد. اما MLflow به شما کمک میکند تا این چالشها را به سادگی مدیریت کنید. در ادامه، مهمترین دلایلی را بررسی میکنیم که چرا MLflow یک ابزار ایدهآل برای شماست:
با استفاده از MLflow میتوانید تمام آزمایشهای خود را بهدقت ردیابی کنید. این ابزار به شما امکان میدهد پارامترها، متریکها و نتایج هر آزمایش را ثبت و ذخیره نمایید، طوری که بهراحتی بتوانید بهترین تنظیمات را بر اساس عملکردشان شناسایی کنید. این قابلیت به یادگیری از تجربیات گذشته و جلوگیری از تکرار اشتباهات کمک شایانی میکند.
با MLflow میتوانید مدلهای مختلف را با پارامترهای متنوع آموزش دهید و نتایج آنها را ثبت کنید. این قابلیت به شما امکان میدهد تاریخچهای کامل از تمام آزمایشهای خود داشته باشید و به سادگی تشخیص دهید کدام ترکیب پارامترها و تنظیمات بهترین عملکرد را ارائه میدهد. چنین مقایسههای سیستماتیکی به شما در اتخاذ تصمیمات آگاهانه و توسعهٔ مدلهای بهینهتر کمک میکنند.
ابزار MLflow این قابلیت را در اختیار شما قرار میدهد که پروژههای یادگیری ماشین خود را به شیوهای منظم و ساختاریافته مدیریت نمایید. با بهرهگیری از MLflow Projects، میتوانید کدها و وابستگیهای پروژه را به سادگی سازماندهی کنید، که این امر همکاری میان اعضای تیم را به میزان قابل توجهی تسهیل میبخشد.
مدلهای یادگیری ماشین غالباً از پیچیدگی بالایی برخوردارند. MLflow به شما اجازه میدهد مدلهای خود را به آسانی ذخیره کرده و در مواقع لزوم مجدداً بارگذاری نمایید. این قابلیت ارزشمند امکان استفاده مجدد از مدلها در پروژههای بعدی را فراهم میسازد، بدون آنکه نیازی به فرآیند زمانبر بازآموزی مدلهای قبلی وجود داشته باشد.
با MLflow Registry به شما کمک میکند تا نسخههای مختلف مدلهای خود را مدیریت کنید. این ویژگی به شما این امکان را میدهد که بتوانید هر زمان که نیاز دارید به نسخههای قبلی مدلها دسترسی داشته باشید و تغییرات را بهراحتی ردیابی کنید.
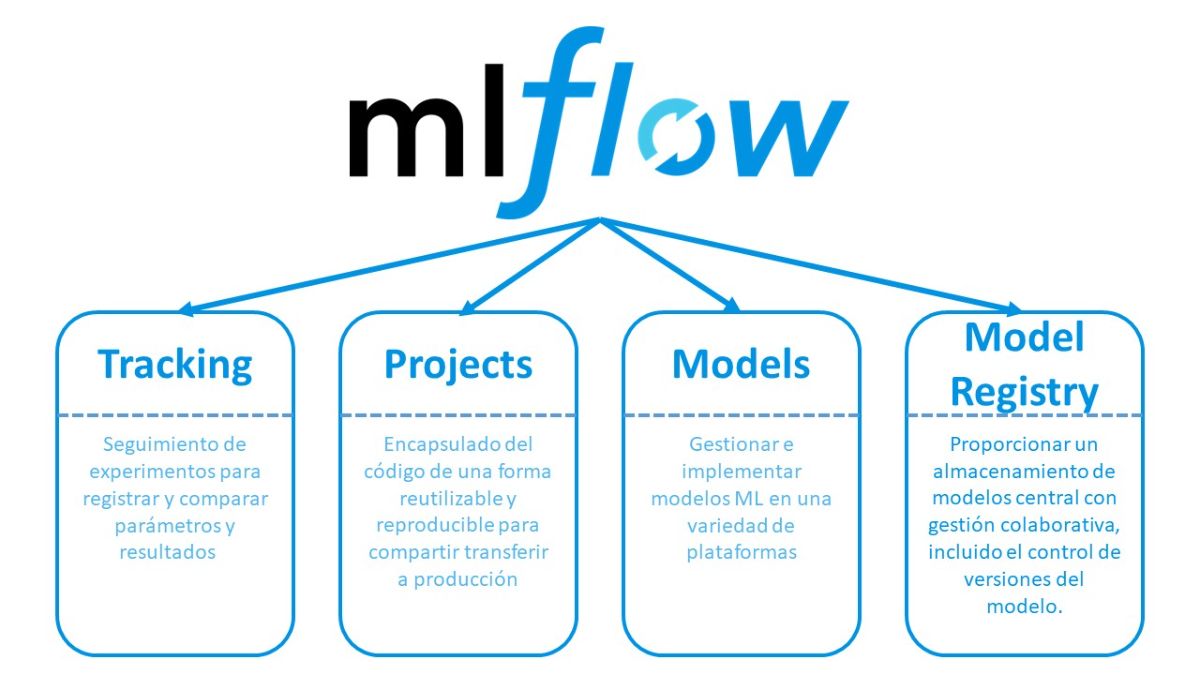
ابزار MLflow دارای چهار جزء اصلی است که هر کدام نقش مهمی دارند:
این قسمت به شما اجازه میدهد که آزمایشات خود را ردیابی کنید. شما میتوانید پارامترها، متریکها و مدلهای خود را ثبت کنید.
این قسمت به شما کمک میکند کد و وابستگیهای پروژههای یادگیری ماشین خود را سازماندهی کنید. این به شما امکان میدهد که پروژههای خود را به راحتی به اشتراک بگذارید.
با این قسمت، شما میتوانید مدلهای خود را ذخیره و بارگذاری کنید. MLflow از فرمتهای مختلف مدل پشتیبانی میکند، مانند TensorFlow و Scikit-learn و ONNX.
این قسمت به شما کمک میکند تا نسخههای مختلف مدلهای منتخب خود را مدیریت کنید. شما میتوانید مدلها را ثبت و مستند کنید.

pip install mlflow
مشاهده نتایج و ردیابیهای خود، میتوانید از رابط کاربری MLflow استفاده کنید. با اجرای دستور زیر در ترمینال، رابط کاربری را راهاندازی کنید و ادرسی که میتوانید به آن دسترسی پیدا کنید را بیابید:
mlflow ui
برای شروع ردیابی از دستور :
mlflow.start_run()
و برای پایان ردیابی از دستور زیر استفاده می کنیم:
mlflow.end_run()
برای ثبت هر پارامتر از دستور:
mlflow.log_param("param_name", param_value)
برای ثبت متریک و ارزیابی مدل از دستور:
mlflow.log_metric("metric_name", metric_value)
و برای ذخیره مدل sk-learn از دستور:
mlflow.sklearn.log_model(model, "model_name")
مدل تورچ از :
mlflow.pytorch.log_model(model, "simple_model")
مدل تنسورفلو:
mlflow.tensorflow.log_model(model, "tensorflow_model")
استفاده می کنیم. مدل را ذخیره می کنیم تا در آینده بتوانیم به راحتی به آن دسترسی داشته باشیم و از آن بهرهبرداری کنیم.
بارگذاری مدل:
loaded_model = mlflow.sklearn.load_model("random_forest_model")
loaded_model = mlflow.pytorch.load_model("simple_model")
loaded_model = mlflow.tensorflow.load_model("tensorflow_model")
مثال:
import mlflow
import mlflow.sklearn
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100, n_features=1, noise=0.1)
model = LinearRegression()
with mlflow.start_run():
model.fit(X, y)
score = model.score(X, y)
mlflow.sklearn.log_model(model, "linear_regression_model")
mlflow.log_metric("r2_score", score) run_id = run.info.run_id print(f"Run ID: {run_id}")
در این مثال از with برای ایجاد یک context استفاده شده تا به صورت خودکار عمل mlflow.end_run انجام شود.
متغیرrun_id در MLflow یک شناسه منحصر به فرد است که به هر ردیابی (run) اختصاص داده میشود. این شناسه به شما این امکان را میدهد که بهراحتی به اطلاعات مربوط به یک ردیابی خاص دسترسی پیدا کنید، از جمله پارامترها، متریکها و مدلهای ثبتشده.
ابتدا نامی برای آزمایش (Experiment) انتخاب میکنید. این نام کمک میکند تمامی آزمایشهای مرتبط در یک دستهبندی مشخص قرار بگیرند.
یک experiment در MLflow دارای ویژگیهایی است:
- شناسه یا experiment_id که به صورت خودکار یک شناسه یکتا دارد که از آن برای ارجاع به آن استفاده میشود.
- نام یا name که در هنگام ساخت آن تعیین میشود.
- ویژگی artifact_location که مسیری (میتواند یک دایرکتوری محلی یا آدرس یک مخزن ابری باشد)که نتایج آزمایشها و artifacts مربوط به experiment در آن ذخیره میشود.
- ویژگی های creation_time و last_update_time
هر بار که یک مجموعه هایپرپارامتر را تست میکنید، یک "Run" جدید ایجاد میشود.
برای هر Run، مقادیر هایپرپارامترها (مثلاً تعداد لایهها، نرخ یادگیری) و متریکهای خروجی (مثل دقت، F1-Score) را ثبت میکنید.
مثال:
ابتدا کتابخانه های مورد نیاز را ایمپورت میکنیم:
import mlflow
import mlflow.sklearn
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
و سپس نام آزمایش را مشخص میکنیم:
experiment_name = "Hyperparameter Optimization"
mlflow.set_experiment(experiment_name)
و برای کسب مشخصات آزمایش ها میتوانید از این کد استفاده کنید:
experiments = mlflow.search_experiments()
for experiment in experiments:
print(f"Experiment ID: {experiment.experiment_id}")
print(f"Experiment Name: {experiment.name}")
print(f"Artifact Location: {experiment.artifact_location}")
print(f"Creation Time: {experiment.creation_time}")
print("----------------------------------------------------")
مقادیر مختلف برای هایپرپارامتر را مشخص میکنیم:
c_values = [0.01, 0.1, 1, 10]
برای تست مدل با هر کدام از هایپرپارامترها میتوانیم این کد استفاده کنیم:
for c in c_values:
with mlflow.start_run():
model = LogisticRegression(C=c, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
mlflow.log_param("C", c)
mlflow.log_metric("accuracy", accuracy)
mlflow.sklearn.log_model(model, f"logistic_model_c_{c}")
هدف نسخهبندی و مدیریت وضعیت مدلها (مانند staging یا production) است.
در پروژههای یادگیری ماشین، مدیریت نسخههای مختلف یک مدل و وضعیت آنها بسیار مهم است. به این فکر کنید که ممکن است یک مدل:
اگر در آینده نیاز باشد نسخهای از مدل بازیابی شود، میدانید دقیقاً کدام نسخه کجا استفاده شده است.
قبل از استقرار مدل در تولید، میتوانید آن را در مرحله Staging تست کنید.
مطمئن میشوید که فقط مدلهای تستشده در تولید قرار میگیرند.
با MLflow Registry شما می توانید این فرآیند را بهصورت ساختاریافته و دقیق مدیریت کنید.
نسخهبندی مدلها (Model Versioning):
هر بار که یک مدل جدید ثبت میشود، یک نسخه به آن اختصاص مییابد.
مثلاً:
نسخه 1: اولین مدل
نسخه 2: مدل بهبودیافته.
وضعیت مدلها (Stages):
هر مدل میتواند یکی از وضعیتهای زیر را داشته باشد:
مقدار None: وضعیت اولیه مدل، بدون تخصیص خاص.
مقدار Staging: مدل در حال تست است.
مقدار Production: مدل آماده استفاده در محیط واقعی است.
مقدار Archived: مدل قدیمی شده و دیگر استفاده نمیشود.
۱. ابتدا باید آن مدل در یک Run با استفاده از mlflow.log_model یا ابزار مشابه ثبت شده باشد.
۲. حالا که مدل در مرحله قبلی ثبت شده، میتوانید آن را در رجیستری نسخهبندی کنید.
experiment_name: برای دستهبندی آزمایشها.model_name: نام مدل در رجیستری.model_path: مسیر ثبت مدل در MLflow.run_id: شناسایی هر Run.from mlflow.tracking import MlflowClient model_uri = f"runs:/{run_id}/ridge_model" registered_model = client.create_registered_model( name=model_name, description="Ridge Regression Model for testing different alpha values") client = MlflowClient() model_version = client.create_model_version( name=model_name, source=model_uri, run_id="<RUN_ID>") print(f"Model Name: {model_name}") print(f"Model Version: {model_version.version}")
متد create_registered_model() تنها زمانی ضروری است که بخواهید ابتدا رجیستری را بهصورت دستی ایجاد کنید، قبل از اضافه کردن نسخههای مدل به آن. این متد به شما اجازه میدهد توضیحات اولیه یا ویژگیهای متادیتا برای رجیستری مشخص کنید. وقتی برای اولین بار از متد client.create_model_version() استفاده میکنید، رجیستری مدل بهصورت خودکار ایجاد میشود اگر قبلاً وجود نداشته باشد.
۳. میتوانید وضعیت آن را مدیریت کنید:
تغییر وضعیت به Staging:
client.transition_model_version_stage(
name=model_name,
version=model_version.version,
stage="Staging" )
print(f"Model {model_name} Version {model_version.version} moved to Staging.")
تغییر وضعیت به Production پس از تایید:
client.transition_model_version_stage(
name=model_name,
version=model_version.version,
stage="Production" )
print(f"Model {model_name} Version {model_version.version} moved to Production.")
۴. استفاده ار مدل
از اطلاعات ثبتشده برای بارگذاری مدل در وضعیت Production استفاده میکنید.
مثال:
import mlflow.sklearn
model_uri = f"models:/{model_name}/Production"
loaded_model = mlflow.sklearn.load_model(model_uri)
predictions = loaded_model.predict(X)