مستندات راهاندازی ابزار جمعآوری لاگ Vector
جمعآوری لاگ چیست و چرا به آن نیاز داریم؟
جمعآوری لاگ (Log Aggregation) روشی است برای جمعآوری، مدیریت و تحلیل لاگها (رکوردهایی که فعالیتها و خطاهای برنامهها را ثبت میکنند) از سیستمها و سرویسهای مختلف در یک مکان مرکزی. هدف اصلی از این کار، سادهتر شدن نظارت بر سیستمها، تشخیص سریعتر مشکلات، و تسهیل تحلیل دادهها است.
Vector چیست؟
Vector یک ابزار مدرن، قدرتمند و سریع برای جمعآوری، تبدیل و ارسال لاگها و متریکها است. از Vector برای ساخت خطوط انتقال داده (Pipelines) از برنامهها و سرویسها به سیستمهای تحلیل داده مثل Kafka، Elasticsearch و غیره استفاده میشود.
سرعت بالا و مصرف بهینه منابع
انعطافپذیری در مدیریت دادهها
پشتیبانی از منابع متنوع (Docker، Kubernetes و غیره)
استفاده از زبان ساده و قدرتمند Vector Remap Language برای تبدیل لاگها
توپولوژیهای Vector
Vector سه نوع توپولوژی برای پیادهسازی دارد:

هر برنامه یا نود به طور مستقل لاگها را مستقیماً به مقصد ارسال میکند.
مزایا:
ساده و قابل مقیاسپذیری
معایب:
کارایی کمتر، احتمال از دست رفتن دادهها، فشار بیشتر به سرویس مقصد

نودها لاگها را به یک Vector مرکزی میفرستند که آنها را جمعآوری و سپس ارسال میکند.
مزایا:
مدیریت بهتر منابع، کاهش فشار روی سرویس مقصد، قابلیت تحلیل بین سرویسها
معایب:
پیچیدگی بیشتر، امکان از دست رفتن دادهها در صورت خرابی سرویس مرکزی
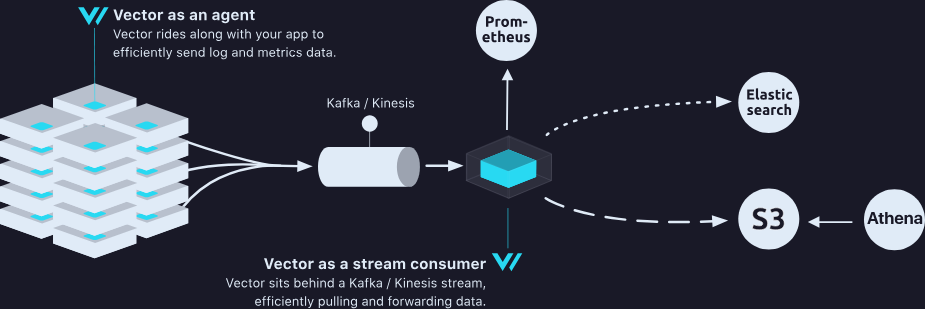
نودها دادهها را به یک سرویس جریانمحور مثل Kafka ارسال کرده و سپس از طریق Vector دادهها مجدداً توزیع میشوند.
مزایا:
بیشترین دوام و قابلیت اطمینان، بازده بالا، امکان پخش مجدد دادهها
معایب:
پیچیدگی بیشتر و نیاز به تیم متخصص
راهاندازی سریع با Docker Compose (Vector Agent)
برای جمعآوری لاگها با Vector Agent از طریق Docker Compose کافی است فایل زیر را استفاده کنید:
services: vector: image: timberio/vector:nightly-debian container_name: vector volumes: - ./vector.toml:/etc/vector/vector.toml:ro - /var/run/docker.sock:/var/run/docker.sock:ro environment: - DOCKER_HOST=unix:///var/run/docker.sock command: ["--config", "/etc/vector/vector.toml"] restart: always healthcheck: test: ["CMD", "vector", "validate"] interval: 30s timeout: 10s retries: 5
فایل کانفیگ vector.toml:
[sources.docker_labeld_logs] type = "docker_logs" docker_host = "unix:///var/run/docker.sock" include_labels = ["log.include=true"] [transforms.parse_message_vrl] type = "remap" inputs = ["docker_labeld_logs"] source = ''' .message = parse_json!(.message) ''' [transforms.only_message] type = "remap" inputs = ["parse_message_vrl"] source = ''' . = .message ''' [sinks.kafka] type = "kafka" inputs = ["only_message"] bootstrap_servers = "ip:port" topic = "logs.consumers" sasl.enabled = true sasl.mechanism = "PLAIN" sasl.username = "log-producer" sasl.password = "pass" encoding.codec = "json"
راهاندازی Vector Consumer روی Kubernetes
برای راهاندازی Vector Consumer روی Kubernetes به صورت زیر عمل کنید:
فایل vector-consumer-config.yaml:
apiVersion: v1
kind: ConfigMap
metadata:
name: vector-consumer-config
data:
vector.toml: |
[sources.kafka_in]
type = "kafka"
bootstrap_servers = "ip:port"
topics = ["logs.consumers"]
group_id = "log-group"
sasl.enabled = true
sasl.mechanism = "PLAIN"
sasl.username = "log-consumer"
sasl.password = "pass"
[transforms.parse_message_json]
type = "remap"
inputs = ["kafka_in"]
source = '''
. = parse_json!(.message)
'''
[sinks.my_elasticsearch_sink]
type = "elasticsearch"
inputs = ["parse_message_json"]
endpoints = ["https:{//}ip:port"]
auth.strategy = "basic"
auth.user = "log"
auth.password = "pass"
pipeline = "logs_dynamic_pipeline"
tls.verify_certificate = false
فایل vector-consumer-deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: vector-consumer
labels:
app: vector-consumer
spec:
replicas: 1
selector:
matchLabels:
app: vector-consumer
template:
metadata:
labels:
app: vector-consumer
spec:
containers:
- name: vector
image: timberio/vector:nightly-distroless-libc
env:
- name: VECTOR_LOG
value: "debug" # <- change here
imagePullPolicy: IfNotPresent
args: ["--config", "/etc/vector/vector.toml"]
volumeMounts:
- name: config
mountPath: /etc/vector
volumes:
- name: config
configMap:
name: vector-consumer-config
items:
- key: vector.toml
path: vector.toml
برای مدیریت بهینه لاگها در Elasticsearch و Kibana به صورت زیر عمل کنید:
وارد Kibana شوید و به بخش Management → Stack Management → Index Patterns بروید.
روی دکمه Create Index Pattern کلیک کنید.
در قسمت index pattern عبارت log.* را وارد کرده و روی Next کلیک کنید.
فیلد @timestamp را به عنوان فیلد زمانی (Time field) انتخاب کنید و روی Create Index Pattern کلیک کنید.
مرحله 2: ساخت Pipeline در Elasticsearch برای تبدیل تایم استمپ
یک pipeline در Elasticsearch ایجاد کنید تا timestamp لاگها را تبدیل کند و نام سرویس را برای ساخت ایندکسها استفاده کند:
PUT _ingest/pipeline/logs_dynamic_pipeline { "processors": [ { "date": { "field": "time", "formats": ["yyyy-MM-dd HH:mm:ss,SSS"], "target_field": "@timestamp", "timezone": "UTC" } }, { "remove": { "field": "time" } }, { "set": { "field": "_index", "value": "log.{{service}}" } } ] }
4. اعمال تغییرات در Kubernetes
برای دیپلوی کردن این سرویسها، دستورات زیر را اجرا کنید:
kubectl apply -f vector-consumer-config.yaml kubectl apply -f vector-consumer-deployment.yaml
اکنون لاگهای شما به صورت خودکار از Kafka به Elasticsearch منتقل میشوند و میتوانید به راحتی لاگها را تحلیل و مانیتور کنید.