طبقه بندی (Classification) یکی از روش های یادگیری ماشین است و برای یادگیری چگونگی تخصیص برچسب کلاس به یک نمونه ورودی، استفاده می شود. برای مثال، با طبقه بندی می توان مشخص کرد که یک ایمیل اسپم است یا خیر. برچسب های کلاس در اینجا اسپم و غیر اسپم هستند که باید به مقادیر عددی تبدیل شوند، یعنی اسپم را برابر صفر و غیر اسپم را برابر یک قرار می دهیم. مثال دیگر از طبقه بندی، دسته بندی کاراکترهای دست نویس به کاراکترهای موجود می باشد.
شاید بتوان مسئله طبقه بندی را به چهار دسته تقسیم کرد:
در ادامه به بررسی مختصر هر یک از این موارد می پردازیم.
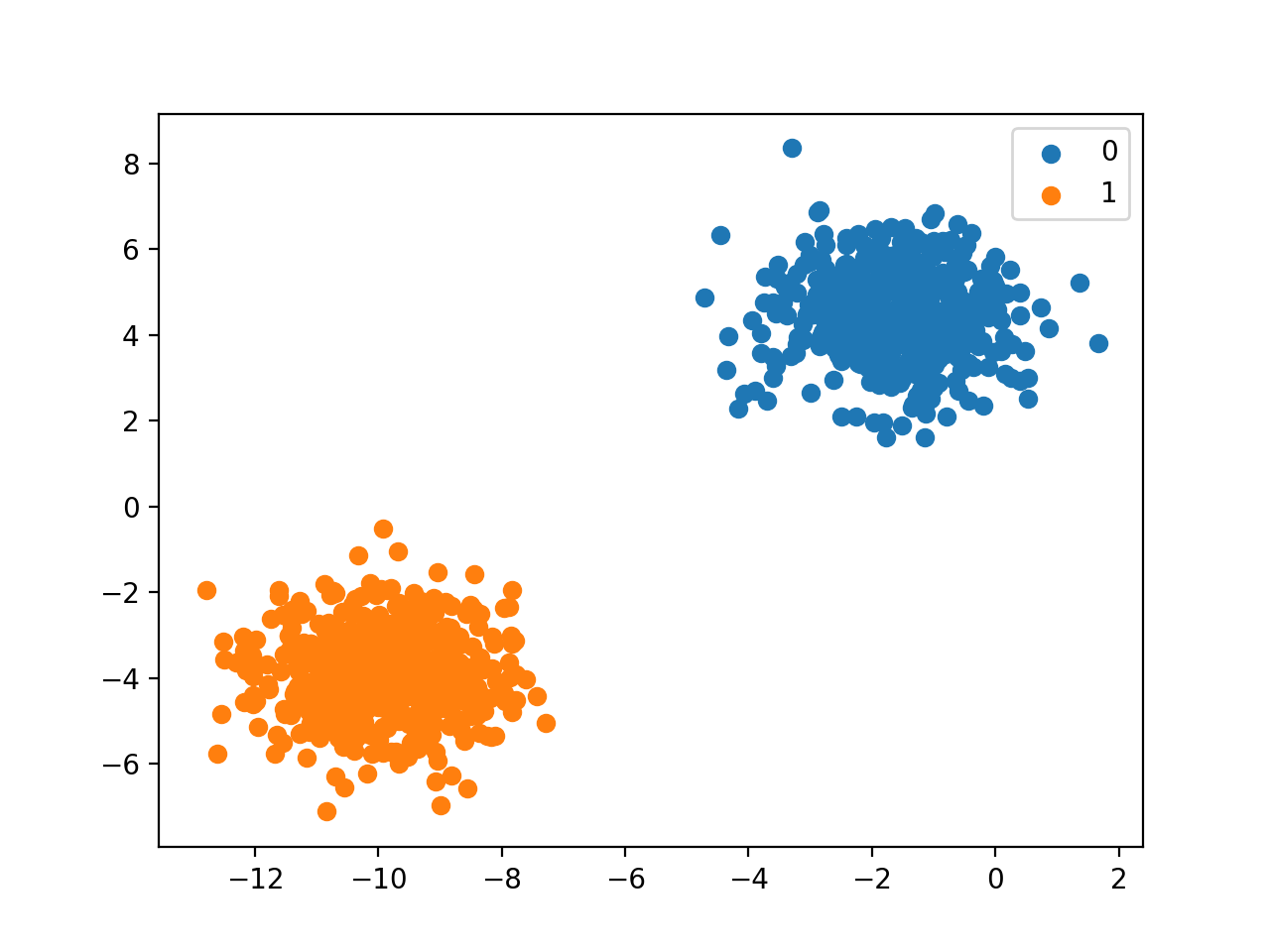
مسائل طبقه بندی که دارای دو برچسب کلاس هستند. مانند مسئله شناسایی ایمیل اسپم که دارای دو برچسب اسپم یا غیر اسپم است یا در آزمایشات پزشکی، مشخص می شود یک بیمار دارای بیماری خاصی است یا خیر، بنابراین دارای دو برچسب بیمار یا غیر بیمار هستیم. در واقع در طبقه بندی دودویی، همانطور که در شکل زیر می بینید، یک کلاس حالت نرمال و کلاس دیگر حالت غیر نرمال را نشان می دهد.
الگوریتم های رایج برای طبقه بندی دودویی شامل موارد زیر است:
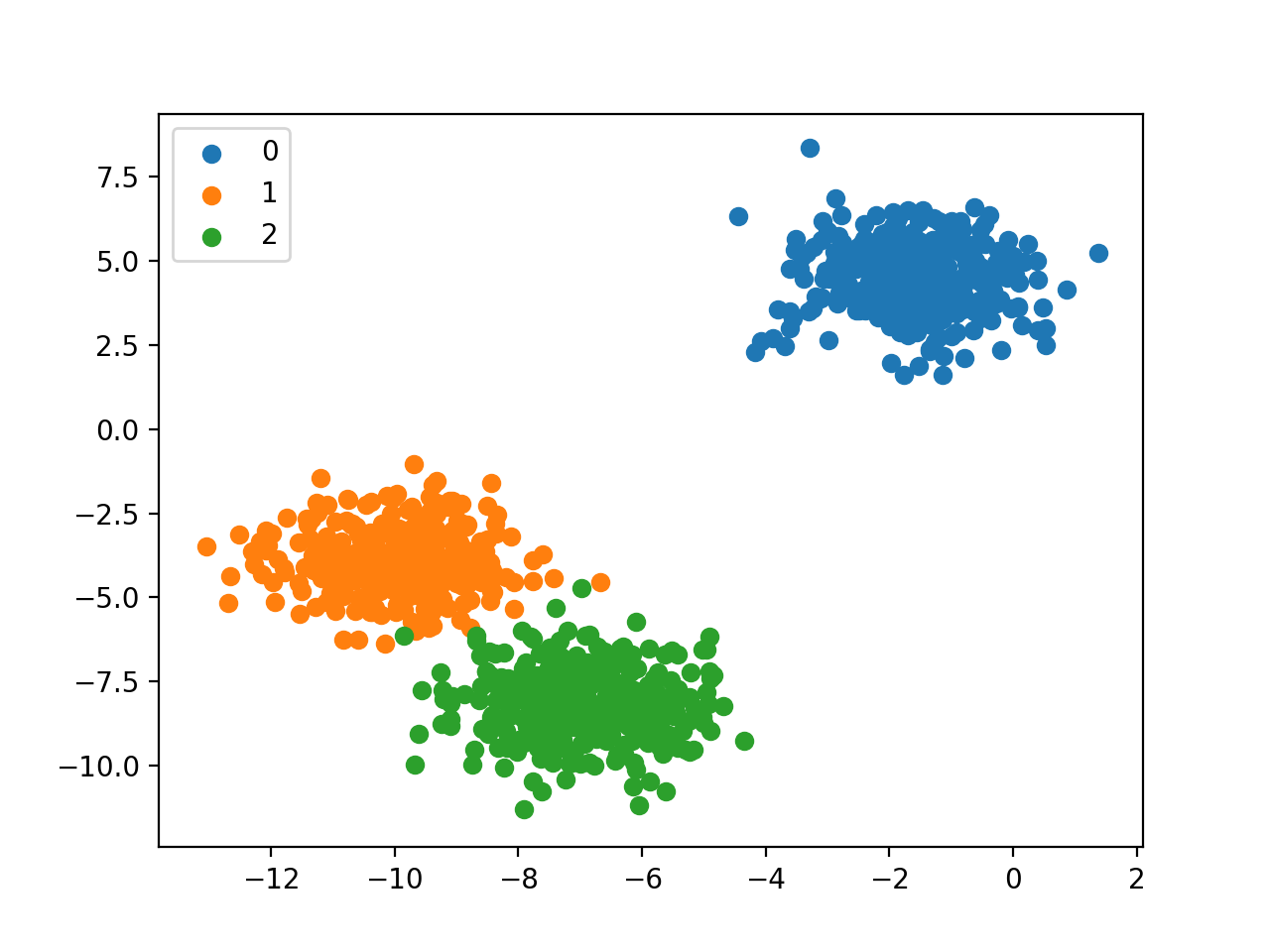
طبقه بندی چند کلاسه، وظایف طبقه بندی هستند که دارای بیش از دو برچسب کلاس هستند. به طور مثال، در شکل زیر دارای سه کلاس مختلف هستیم. مانند طبقه بندی چهره، طبقه بندی گونه های گیاهی و شناسایی کاراکترهای نوری. برخلاف طبقه بندی دودویی، نمونه ها، متعلق به طیف وسیعی از کلاس های شناخته شده می باشند. تعداد برچسب کلاس ها در بعضی از مسائل، ممکن است بسیار زیاد باشند. برای مثال، در سیستم تشخیص چهره، مدل پیش بینی می کند عکسی به یکی از ده ها هزار چهره موجود در سیستم، تعلق دارد یا نه.
تعدادی از الگوریتم ها محبوب برای مسائل طبقه بندی عبارتند از:
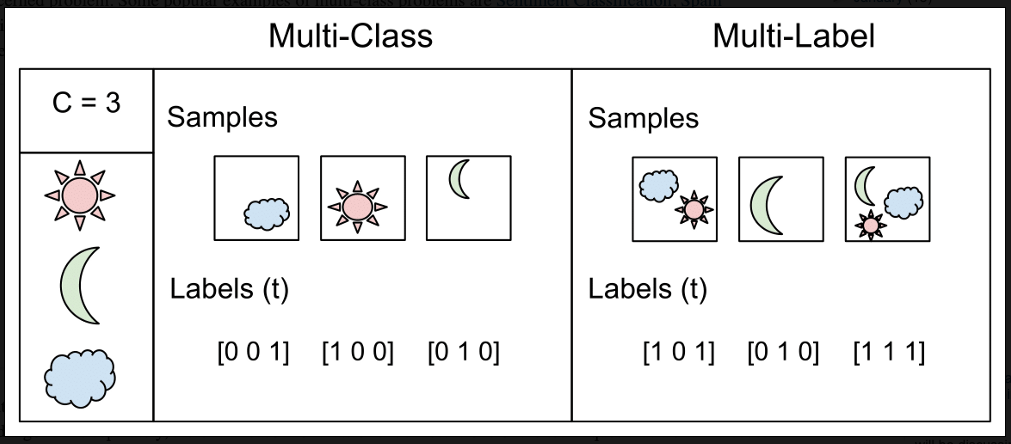
طبقه بندی چند برچسبی، وظایفی هستند که در آن برای هر نمونه دو یا چند برچسب کلاس قابل پیش بینی است. در مثال طبقه بندی عکس، زمانی که یک عکس می تواند شامل چند جزء در تصویر باشد، یک مدل می تواند به پیش بینی چندین برچسب در عکس بپردازد مانند افراد، دوچرخه، سیب و غیره. در شکل زیر تفاوت بین طبقه بندی چندکلاسه و چند برچسبی را مشاهده می کنید.
الگوریتم های طبقه بندی دودویی و چند کلاسه نمی تواند به طور مستقیم در این مسائل به کار گرفته شوند، بنابراین باید از نسخه های الگوریتم های چند برچسبی استفاده کرد. مانند:
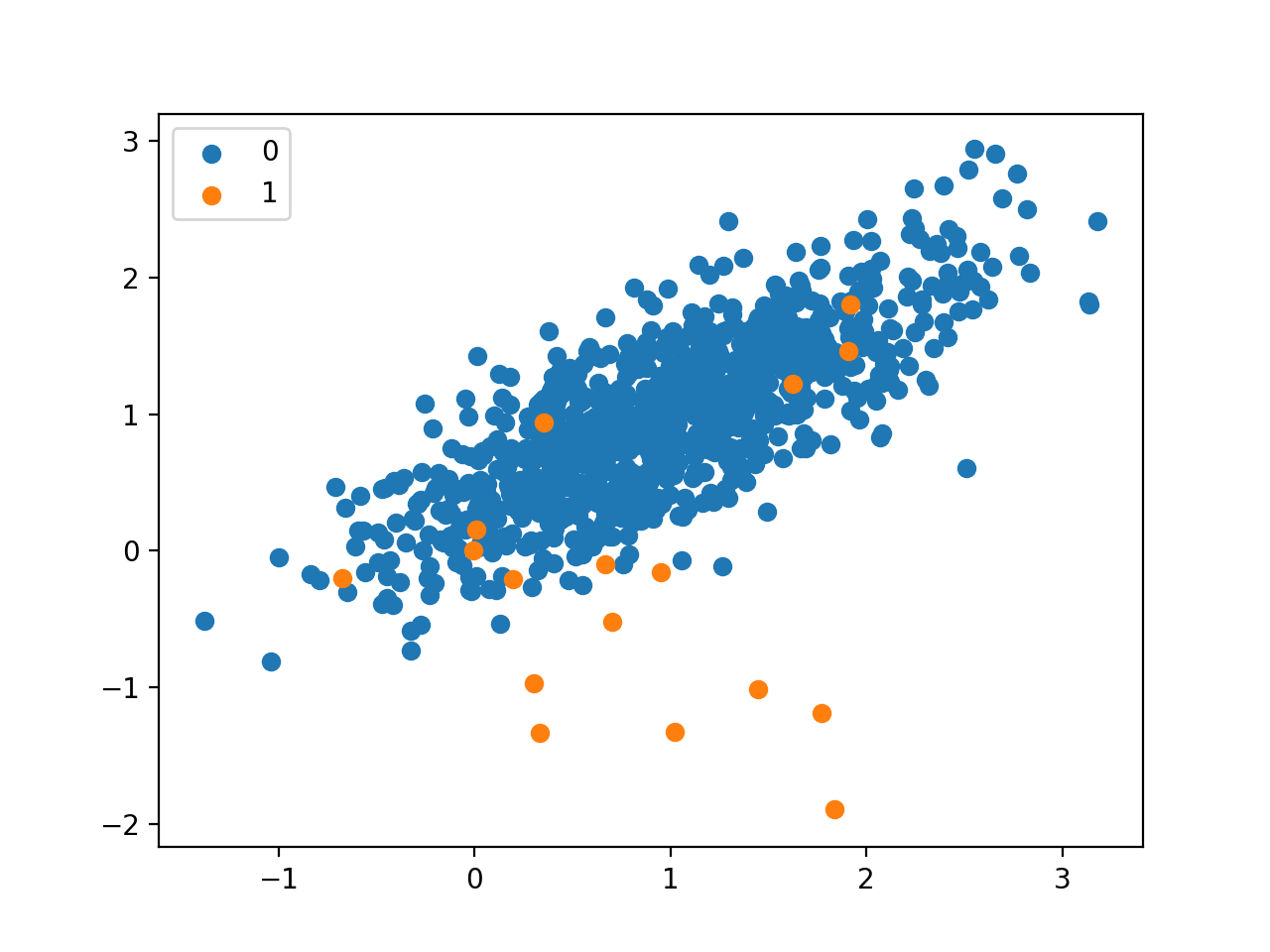
طبقه بندی نامتوازن، وظایف طبقه بندی هستند که در آن تعداد نمونه ها در هر کلاس به صورت نابرابر توزیع شده اند. معمولا وظایف طبقه بندی نامتوازن، وظایف طبقه بندی دودویی هستند که اکثریت نمونه ها در مجموعه آموزشی متعلق به کلاس نرمال هستند و حداقل نمونه ها متعلق به کلاس غیر نرمال هستند. همانطور که در شکل زیر می بینید، اکثریت نقاط به رنگ آبی و تعداد اندکی نقطه به رنگ زرد وجود دارند. مانند تشخیص تقلب، تشخیص داده پرت و تست های تشخیصی پزشکی. مثلا در تست های تشخیص سرطان تعداد بسیار زیادی از افراد سالم و تعداد اندکی دارای بیماری سرطان هستند. این مسائل به عنوان مسائل طبقه بندی دودویی مدل سازی می شوند اما نیاز به تکنیک های خاصی دارد.
از الگوریتم های مدل سازی خاصی که الگوریتم های یادگیری ماشین حساس به هزینه (cost-sensitive) نامیده می شوند، می توان برای داده های نامتوازن استفاده کرد. برای مثال:
همچنین ممکن است به معیارهای کارایی جایگزینی مانند Precision، Recall و F-Measureنیاز داشته باشیم زیرا گزارش دقت طبقه بند ممکن است گمراه کننده باشد.