گاهی وقتها، در میانهی یک روز کاری عادی، همهچیز با یک لاگ قرمز رنگ در کنسول سرور یا داشبود مانیتورینگ عوض میشه. اگر تا به حال پیامهایی مثل blk_update_request: critical medium error یا Buffer I/O error را دیده باشین، حتماً حس کردین که یکی از دیسکها دیگه روزهای آخر عمرش را میگذرونه. این سناریو برای خیلی از تیمهای SRE و دواپس آشناست. در این نوشته میخوام تجربهای واقعی از یک سرور با دیسکهای NVMe خراب را مرور کنم و قدمبهقدم راه انتقال امن دیتا را توضیح بدم.
سرور ما دو دیسک NVMe دارد:
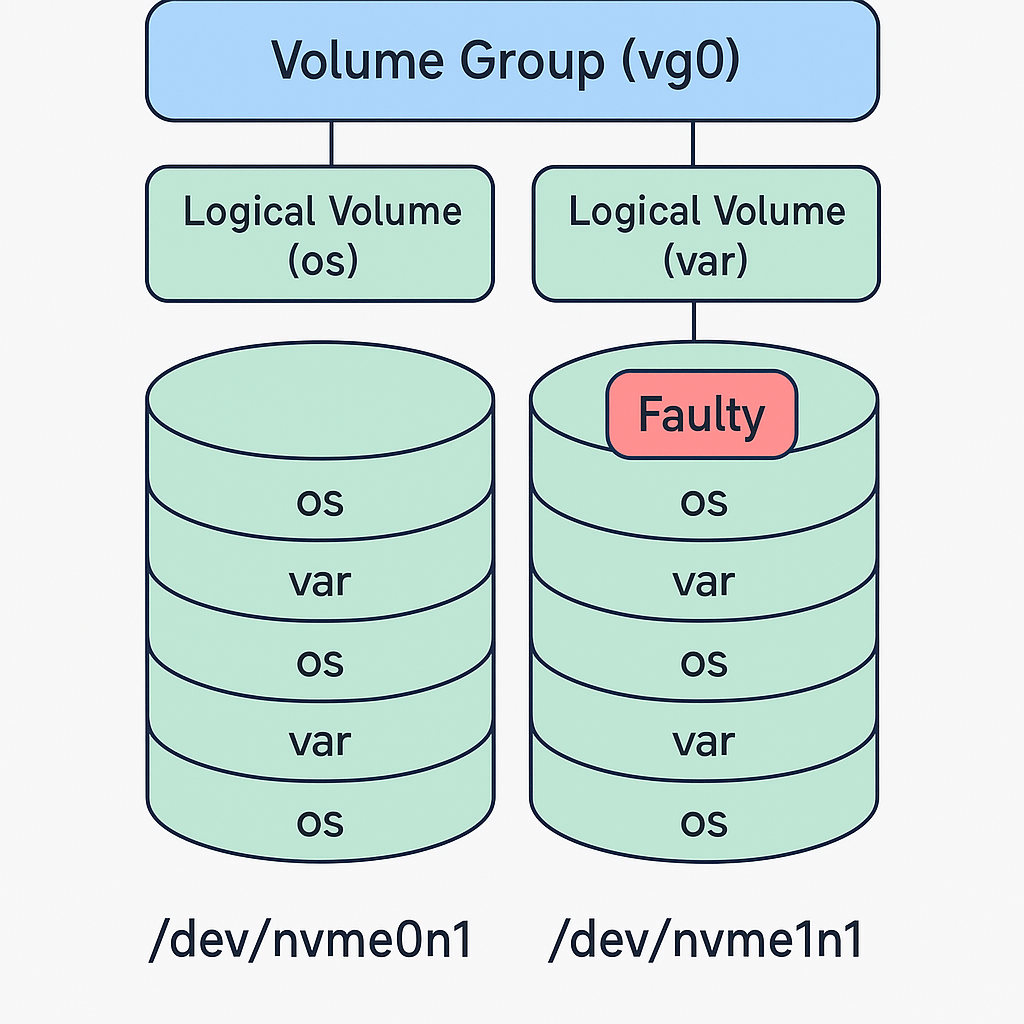
nvme0n1 → دیسک خراب (خطاهای SMART زیاد و Critical Warning فعال)
nvme1n1 → دیسک سالم
هر دو دیسک به عنوان Physical Volume (PV) در یک Volume Group (VG) مشترک به نام vg0 استفاده شدهاند. دو Logical Volume (LV) داریم:
vg0/os (برای سیستمعامل)
vg0/var (برای دیتا و لاگها)
VG تقریباً پر هست و اکستنتها بین هر دو دیسک پخش شدهاند. بنابراین اگر یک PV را از دست بدیم، عملاً کل دیتا دچار مشکل میشود.
شاید اولین ایده این باشه که کل دیسک خراب را با ابزارهایی مثل ddrescue به دیسک سالم کلون کنیم. این روش وقتی جواب میده که هر دیسک مستقل باشه. اما وقتی LVM دادهها را بین دو PV تقسیم کرده، کلون کردن یک دیسک روی دیگری یا جایگزینی دستی، مشکلاتی مثل تکرار UUID و ناسازگاری LVM ایجاد میکنه.
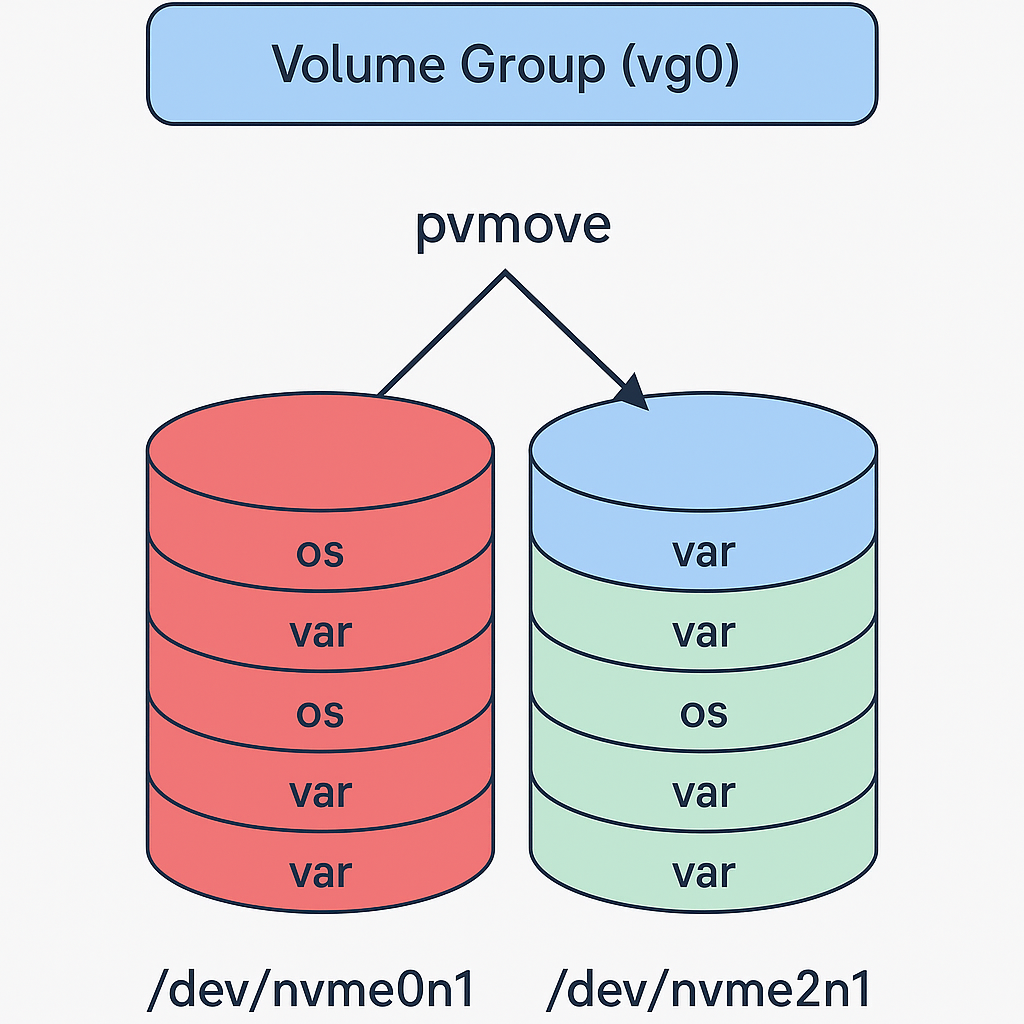
در چنین شرایطی بهترین و ایمنترین روش این است که یک دیسک جدید (همظرفیت یا بزرگتر) به سرور اضافه کنیم و با ابزارهای خود LVM دادههای روی دیسک خراب را به دیسک جدید منتقل کنیم. به این روش در دنیای استوریج pvmove migration میگیم.
ابتدا دیسک جدید (مثلاً nvme2n1) را پارتیشنبندی و به عنوان PV معرفی میکنیم:
parted /dev/nvme2n1 -- mklabel gpt parted /dev/nvme2n1 -- mkpart pv lvm 1MiB 100% # Create PV on new disk pvcreate /dev/nvme2n1p1 # Activate VG vgchange -ay # Add new PV to VG vgextend vg0 /dev/nvme2n1p1
نکته: میتوان کل دیسک را بدون پارتیشن هم به PV تبدیل کرد. در این صورت به جای
nvme2n1p1باید از/dev/nvme2n1استفاده کنید.
اینجا اتفاق اصلیه میفته. pvmove دادههای LVM را بلوکبهبلوک از PV خراب به PV سالم/جدید منتقل میکند.
# Show LV to PV mapping lvs -a -o name,lv_size,seg_count,devices # Move all extents from bad disk to new disk pvmove -i 5 /dev/nvme0n1 /dev/nvme2n1p1
گزینه -i 5 باعث میشه هر ۵ ثانیه یک بار وضعیت کار نمایش داده شود.
اگر خطا داد، میتوانید فقط بخشی از یک LV خاص را منتقل کنید:
pvmove -i 5 -n var /dev/nvme0n1 /dev/nvme2n1p1
بعد از اینکه همه دادهها منتقل شد، دیسک خراب را از VG خارج کنید:
vgreduce vg0 /dev/nvme0n1 pvremove /dev/nvme0n1
حالا دیگر LVM هیچ وابستگیای به دیسک خراب ندارد و میتوانید آن را از سرور جدا کنید.
برای اینکه سیستم بدون مشکل بوت شود، لازم است بوتلودر (GRUB) روی دیسکهای سالم نصب و بهروز شود:
mount /dev/vg0/os /mnt mount /dev/nvme1n1p1 /mnt/boot # اگر /boot جداست mount --bind /dev /mnt/dev mount --bind /proc /mnt/proc mount --bind /sys /mnt/sys chroot /mnt # Install GRUB grub-install /dev/nvme1n1 grub-install /dev/nvme2n1 update-grub update-initramfs -u # or dracut -f, depending on distro exit umount -R /mnt
بکاپ اولویت اول است. قبل از هر اقدامی از دیتای حیاتی با rsync یا snapshot بکاپ بگیرید.
مانیتورینگ SMART جدی گرفته شود. بیشتر NVMeها شاخصهایی مثل Available Spare یا Media Errors دارند. وقتی اینها شروع به هشدار میکنند، منتظر خرابی نشوید.
پایداری از طراحی شروع میشود. اگر دیتا حیاتی است، از اول باید به سراغ RAID1 یا RAID10 بروید تا چنین مشکلاتی به مایگریتهای اضطراری ختم نشود.
وقتی یک دیسک NVMe در محیط LVM خراب میشود، کل VG در معرض خطر است. بهترین راه نجات، اضافه کردن یک دیسک جدید و مایگریت دادهها با ابزارهای LVM است. این روش، دادهها را بلوکبهبلوک به مقصد سالم میبرد و در نهایت اجازه میدهد دیسک خراب را بدون از دست رفتن سرویس کنار بگذاریم.