طراحی سیستمی که بتواند میلیونها کاربر را پشتیبانی کند، یک فرآیند تکرارپذیر (Iterative) است. هیچ سیستمی از روز اول برای میلیونها کاربر طراحی نمیشود، بلکه به مرور زمان تکامل مییابد.
سفر هزار فرسنگی با اولین قدم آغاز میشود و ساخت یک سیستم پیچیده نیز از این قاعده مستثنی نیست. برای شروعِ کار به شکلی ساده، تمام اجزای سیستم روی یک سرور واحد اجرا میشوند.
در این ساختار، همانطور که در تصویر بالا (مشابه شکل ۱ مقاله) مشاهده میکنید، تمامی بخشها از جمله اپلیکیشن وب (Web App)، پایگاه داده (Database) و حافظه پنهان (Cache) بر روی یک سختافزار قرار دارند.
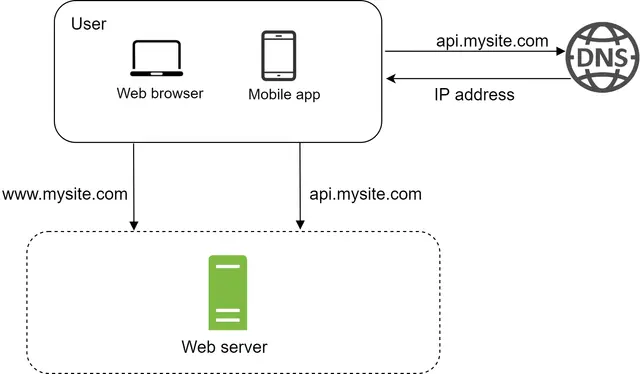
برای درک بهتر این پیکربندی، بررسی جریان درخواست (Request Flow) و منبع ترافیک (Traffic Source) بسیار مفید هستند. بیایید ابتدا نگاهی به جریان درخواست (مطابق شکل ۲ در مقاله) بیندازیم:
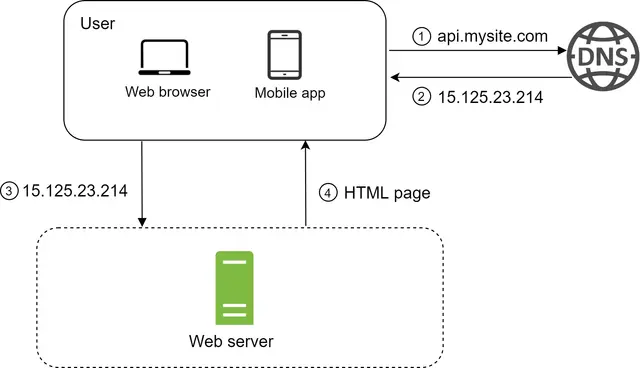
برای درک بهتر این چیدمان، بررسی جریان درخواست و منبع ترافیک مفید است. ابتدا به جریان درخواست نگاهی میاندازیم:
۱. دسترسی از طریق نام دامنه: کاربران از طریق نامهای دامنه (Domain Names) مانند api.mysite.com به وبسایتها دسترسی پیدا میکنند. معمولاً «سامانه نام دامنه» یا همان DNS، یک سرویس پولی است که توسط ارائهدهندگان شخص ثالث (3rd parties) ارائه میشود و روی سرورهای ما میزبانی نمیشود.
۲. دریافت آدرس IP: آدرس پروتکل اینترنت (IP) به مرورگر یا اپلیکیشن موبایل بازگردانده میشود. در این مثال، آدرس IP به صورت 15.125.23.214 بازگردانده شده است.
۳. ارسال درخواست HTTP: به محض دریافت آدرس IP، درخواستهای پروتکل انتقال ابرمتن (HTTP) مستقیماً به وبسرور شما ارسال میشوند.
۴. پاسخ سرور: وبسرور برای نمایش (Rendering)، صفحات HTML یا پاسخهای JSON را بازمیگرداند.
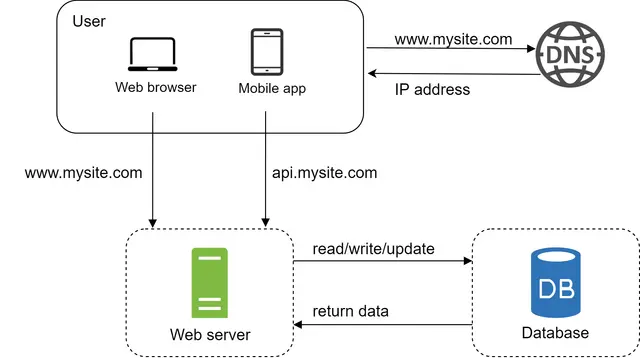
ترافیک ورودی به وبسرور شما از دو منبع اصلی نشأت میگیرد: اپلیکیشن وب و اپلیکیشن موبایل.
اپلیکیشن وب (Web Application): این اپلیکیشن از ترکیبی از زبانهای سمت سرور (مانند Java، Python و غیره) برای مدیریت منطق تجاری (Business Logic)، ذخیرهسازی و... و زبانهای سمت کاربر (HTML و JavaScript) برای ارائه و نمایش محتوا استفاده میکند.
اپلیکیشن موبایل (Mobile Application): پروتکل HTTP، پروتکل ارتباطی بین اپلیکیشن موبایل و وبسرور است. به دلیل سادگی، JSON (نشانهگذاری اشیاء جاوااسکریپت) معمولاً به عنوان قالب پاسخ API برای انتقال دادهها استفاده میشود.
در ادامه، نمونهای از یک پاسخ API در قالب JSON آورده شده است:
GET /users/12 – Retrieve user object for id = 12
{
"id": 12,
"firstName": "Ali",
"lastName": "Dossti",
"address": "Tehran",
"isActivated": true
}
با رشد تعداد کاربران، دیگر یک سرور واحد پاسخگو نیست و ما به چندین سرور نیاز داریم: یکی برای مدیریت ترافیک وب/موبایل و دیگری مختص پایگاه داده (شکل ۳).
جداسازی سرورهای ترافیک وب/موبایل (Web Tier یا لایه وب) از سرور پایگاه داده (Data Tier یا لایه داده)، این امکان را فراهم میکند که هر کدام را بهطور مستقل مقیاسدهی (Scale) کنیم.
وقتی لایه وب و لایه داده را از هم جدا میکنید، در واقع دارید به سیستم خود "فضای تنفس" میدهید:
بهینهسازی منابع: سرور وب معمولاً به پردازنده (CPU) قویتر برای منطق برنامه نیاز دارد، در حالی که سرور پایگاه داده به حافظه (RAM) و سرعت خواندن/نوشتن (I/O) دیسک بالاتری محتاج است. با این تفکیک، میتوانید سختافزار هر کدام را دقیقاً بر اساس نیاز انتخاب کنید.
استقلال در مقیاسدهی: اگر ترافیک وب زیاد شد، میتوانید تعداد سرورهای وب را افزایش دهید، بدون اینکه نگران تنظیمات دیتابیس باشید (و برعکس).
امنیت: میتوانید دیتابیس را در یک شبکه خصوصی (Private Subnet) قرار دهید که مستقیماً از اینترنت قابل دسترسی نباشد، و فقط سرور وب اجازه صحبت با آن را داشته باشد.
نکته: این اولین قدم جدی برای تبدیل شدن از یک "پروژه جانبی" به یک "سیستم حرفهای" است. در واقع شما دارید به سیستم خود یاد میدهید که تخصصی عمل کند!
در ادامه، ترجمه دقیق و علمی بخشهای مربوط به انتخاب پایگاه داده و مفاهیم مقیاسدهی را مطالعه میکنید:
شما میتوانید بین یک پایگاه داده رابطهای (Relational) سنتی و یک پایگاه داده غیررابطهای (Non-relational) انتخاب کنید. بیایید تفاوتهای آنها را بررسی کنیم.
این پایگاههای داده با نامهای RDBMS یا پایگاه داده SQL نیز شناخته میشوند. محبوبترین آنها عبارتند از: MySQL، Oracle و PostgreSQL.
ساختار: دادهها را در قالب جداول (Tables) و سطرها (Rows) نمایش داده و ذخیره میکنند.
عملیات Join: شما میتوانید با استفاده از زبان SQL، عملیات پیوند (Join) را روی جداول مختلف انجام دهید تا دادههای مرتبط را استخراج کنید.
این پایگاهها با نام NoSQL شناخته میشوند. نمونههای محبوب آنها عبارتند از: CouchDB، Neo4j، Cassandra، HBase و Amazon DynamoDB. این دیتابیسها به چهار دسته کلی تقسیم میشوند:
کلید-مقدار (Key-Value Stores)
گراف (Graph Stores)
ستونمحور (Column Stores)
سندمحور (Document Stores)
نکته: در اکثر پایگاههای داده غیررابطهای، عملیات Join پشتیبانی نمیشود.
برای اکثر توسعهدهندگان، پایگاههای داده رابطهای بهترین گزینه هستند، زیرا بیش از ۴۰ سال قدمت دارند و از نظر تاریخی عملکرد خوبی داشتهاند. با این حال، اگر دیتابیسهای رابطهای برای نیازهای خاص شما مناسب نیستند، بررسی گزینههای دیگر ضروری است. NoSQL ممکن است انتخاب درستی باشد اگر:
اپلیکیشن شما به تأخیر بسیار کم (Super-low latency) نیاز دارد.
دادههای شما بدون ساختار (Unstructured) هستند یا هیچ رابطه منطقی بین آنها وجود ندارد.
فقط نیاز به سریالسازی و حساسیتزدایی دادهها (JSON, XML, YAML و غیره) دارید.
نیاز به ذخیرهسازی حجم انبوهی از دادهها (Massive amount of data) دارید.
که به آن "Scale Up" نیز گفته میشود، فرآیند اضافه کردن قدرت بیشتر (CPU، رم و غیره) به سرورهای فعلی شماست.
مزایا: سادگی در پیادهسازی (بهترین گزینه برای ترافیک کم).
محدودیتهای جدی:
سقف سختافزاری: اضافه کردن نامحدود CPU و حافظه به یک سرور واحد غیرممکن است.
فقدان تابآوری (Failover): در این مدل، افزونگی (Redundancy) وجود ندارد. اگر سرور از کار بیفتد، وبسایت/اپلیکیشن کاملاً از دسترس خارج میشود.
که به آن "Scale Out" گفته میشود، به شما اجازه میدهد با اضافه کردن سرورهای بیشتر به استخر منابع خود، مقیاس سیستم را افزایش دهید. به دلیل محدودیتهای روش عمودی، مقیاسدهی افقی برای اپلیکیشنهای در مقیاس بزرگ بسیار مطلوبتر است.
یک متعادلکننده بار، ترافیک ورودی را بهصورت متوازن میان مجموعهای از سرورهای وب که در یک «گروه متعادلسازی» (Load-balanced set) تعریف شدهاند، توزیع میکند. شکل ۴ نحوه عملکرد یک متعادلکننده بار را نشان میدهد.
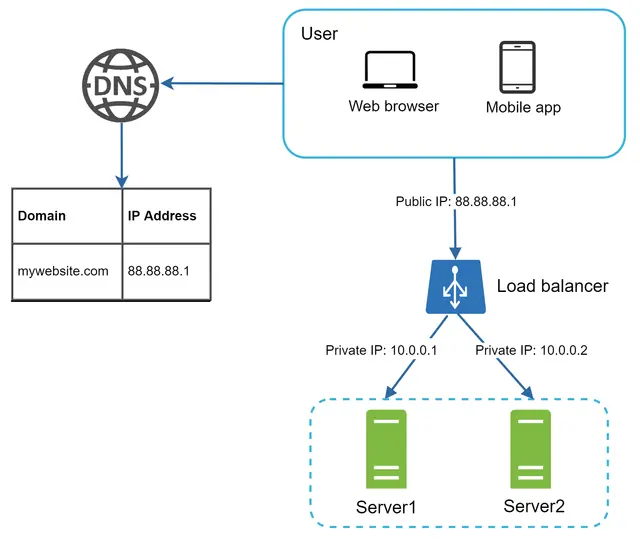
همانطور که در شکل ۴ نشان داده شده است، کاربران مستقیماً به IP عمومی (Public IP) متعادلکننده بار متصل میشوند. با این تنظیمات، سرورهای وب دیگر مستقیماً توسط کلاینتها (کاربران) قابل دسترسی نیستند. برای امنیت بهتر، از IPهای خصوصی (Private IPs) برای ارتباط بین سرورها استفاده میشود. IP خصوصی آدرسی است که فقط بین سرورهای موجود در یک شبکه داخلی قابل دسترسی است و از طریق اینترنت نمیتوان به آن دست یافت. متعادلکننده بار از طریق این IPهای خصوصی با سرورهای وب ارتباط برقرار میکند.
در شکل ۴، پس از اضافه شدن متعادلکننده بار و سرور وب دوم، ما با موفقیت مشکل عدم تابآوری (Failover) را حل کرده و در دسترس بودن (Availability) لایه وب را بهبود بخشیدیم. جزئیات در ادامه توضیح داده شده است:
اگر سرور ۱ از کار بیفتد (آفلاین شود)، تمام ترافیک به سرور ۲ هدایت میشود. این کار از قطع شدن وبسایت جلوگیری میکند. همچنین، ما یک سرور وب سالم جدید به استخر سرورها اضافه میکنیم تا بارِ کاری متعادل شود.
اگر ترافیک وبسایت به سرعت رشد کند و دو سرور برای مدیریت ترافیک کافی نباشد، متعادلکننده بار میتواند این مشکل را به زیبایی مدیریت کند. شما فقط کافی است سرورهای بیشتری به استخر سرورهای وب اضافه کنید و متعادلکننده بار بهطور خودکار ارسال درخواستها به آنها را آغاز میکند.
اکنون لایه وب وضعیت خوبی دارد، اما لایه داده چطور؟ طراحی فعلی دارای یک پایگاه داده است، بنابراین از تابآوری و افزونگی (Redundancy) پشتیبانی نمیکند. تکثیر پایگاه داده (Database Replication) یک تکنیک رایج برای حل این مشکلات است. بیایید نگاهی به آن بیندازیم.
به نقل از ویکیپدیا: «تکثیر پایگاه داده میتواند در بسیاری از سیستمهای مدیریت پایگاه داده استفاده شود که معمولاً دارای یک رابطه Master/Slave (اصلی/ثانویه) بین نسخه اصلی (Master) و کپیها (Slaves) است.»
یک پایگاه داده Master (اصلی) عموماً فقط از عملیات نوشتن (Write) پشتیبانی میکند. پایگاه داده Slave (ثانویه) کپیهای داده را از دیتابیس اصلی دریافت کرده و فقط از عملیات خواندن (Read) پشتیبانی میکند. تمام دستورات تغییر دهنده داده مانند Insert، Delete یا Update باید به پایگاه داده Master ارسال شوند. از آنجایی که اکثر اپلیکیشنها به نسبتِ بسیار بالاتری از خواندن نسبت به نوشتن نیاز دارند، تعداد دیتابیسهای Slave در یک سیستم معمولاً بیشتر از دیتابیسهای Master است. شکل ۵ یک پایگاه داده اصلی را به همراه چندین پایگاه داده ثانویه نشان میدهد.
عملکرد بهتر: در مدل Master-Slave، تمامی عملیات نوشتن و بهروزرسانی در گرههای Master انجام میشود؛ در حالی که عملیات خواندن میان گرههای Slave توزیع میگردد. این مدل عملکرد را بهبود میبخشد، زیرا اجازه میدهد پرسوجوهای (Queries) بیشتری بهطور موازی پردازش شوند.
قابلیت اطمینان (Reliability): اگر یکی از سرورهای پایگاه داده شما بر اثر بلایای طبیعی مانند طوفان یا زلزله نابود شود، دادهها همچنان حفظ میشوند. شما نگران از دست رفتن دادهها نخواهید بود، زیرا دادهها در چندین مکان تکثیر شدهاند.
در دسترس بودن بالا (High Availability): با تکثیر دادهها در مکانهای مختلف، وبسایت شما حتی در صورت آفلاین شدن یک پایگاه داده به فعالیت خود ادامه میدهد، زیرا میتوانید به دادههای ذخیره شده در سرور پایگاه داده دیگر دسترسی داشته باشید.
در بخش قبل بحث کردیم که چگونه یک متعادلکننده بار (Load Balancer) به بهبود در دسترس بودن سیستم کمک کرد. در اینجا نیز همان سوال را میپرسیم: اگر یکی از پایگاههای داده آفلاین شود چه اتفاقی میافتد؟ طراحی معماری که در شکل ۵ بررسی شد، میتواند این وضعیت را مدیریت کند:
اگر فقط یک پایگاه داده Slave موجود باشد و آفلاین شود: عملیات خواندن بهطور موقت به پایگاه داده Master هدایت میشود. به محض شناسایی مشکل، یک پایگاه داده Slave جدید جایگزین نسخه قدیمی خواهد شد. در صورتی که چندین پایگاه داده Slave موجود باشد، عملیات خواندن به سایر دیتابیسهای Slave سالم هدایت شده و یک سرور جدید جایگزین سرور معیوب میگردد.
اگر پایگاه داده Master آفلاین شود: یکی از پایگاههای داده Slave به مقام Master جدید ارتقا مییابد (Promote). تمام عملیاتهای پایگاه داده بهطور موقت روی Master جدید اجرا خواهند شد. بلافاصله یک پایگاه داده Slave جدید برای عملیات تکثیر داده جایگزین نسخه قبلی میشود. در سیستمهای عملیاتی (Production)، ارتقای یک Master جدید پیچیدهتر است، زیرا ممکن است دادههای موجود در دیتابیس Slave بهروز نباشند. دادههای مفقود شده باید با اجرای اسکریپتهای بازیابی داده (Data Recovery) بهروزرسانی شوند. اگرچه روشهای تکثیر دیگری مانند Multi-masters (چند اصلی) و Circular replication (تکثیر حلقوی) میتوانند کمککننده باشند، اما این پیکربندیها پیچیدهتر هستند و بحث درباره آنها خارج از حوصله این دوره است.
شکل ۶ طراحی سیستم را پس از اضافه کردن متعادلکننده بار و تکثیر پایگاه داده نشان میدهد.
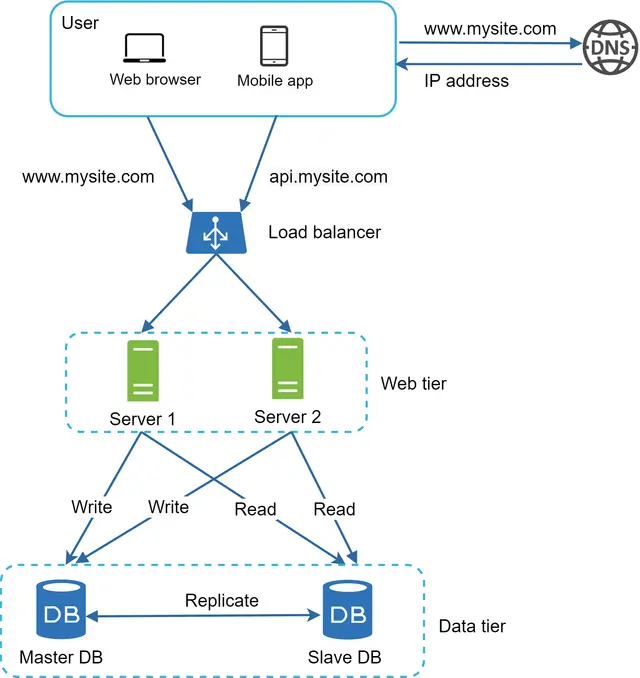
بیایید نگاهی به طراحی سیستم بیندازیم:
۱. کاربر آدرس IP متعادلکننده بار (Load Balancer) را از DNS دریافت میکند. ۲. کاربر با استفاده از این آدرس IP به متعادلکننده بار متصل میشود. ۳. درخواست HTTP به یکی از دو سرور (سرور ۱ یا سرور ۲) هدایت میشود. ۴. وبسرور، دادههای کاربر را از یک پایگاه داده Slave (ثانویه) میخواند. ۵. وبسرور تمامی عملیاتهای تغییر دهنده داده (شامل نوشتن، بهروزرسانی و حذف) را به پایگاه داده Master (اصلی) هدایت میکند.
اکنون که درک درستی از لایههای وب و داده پیدا کردهاید، نوبت به بهبود زمان بارگذاری و پاسخدهی (Response Time) رسیده است. این کار را میتوان با اضافه کردن یک لایه حافظه پنهان (Cache) و انتقال محتوای ایستا (فایلهای JavaScript، CSS، تصاویر و ویدیوها) به شبکه توزیع محتوا (CDN) انجام داد.
کش یک فضای ذخیرهسازی موقت است که نتایج پاسخهای سنگین (از نظر پردازشی) یا دادههایی که مکرراً به آنها دسترسی پیدا میشود را در حافظه (Memory) ذخیره میکند تا درخواستهای بعدی با سرعت بیشتری پاسخ داده شوند. همانطور که در شکل ۶ نشان داده شده است، هر بار که یک صفحه وب جدید بارگذاری میشود، یک یا چند فراخوانی پایگاه داده برای واکشی دادهها اجرا میگردد. عملکرد اپلیکیشن به شدت تحت تأثیر این فراخوانیهای مکرر پایگاه داده قرار میگیرد؛ حافظه پنهان میتواند این مشکل را تعدیل کند.
لایه کش یک لایه ذخیرهسازی موقت داده است که بسیار سریعتر از پایگاه داده عمل میکند. مزایای داشتن یک لایه کش مجزا شامل بهبود عملکرد سیستم، توانایی کاهش حجم کاری پایگاه داده و قابلیت مقیاسدهی مستقلِ لایه کش است. شکل ۷ یک پیکربندی احتمالی از یک سرور کش را نشان میدهد:
پس از دریافت یک درخواست، وبسرور ابتدا بررسی میکند که آیا پاسخ مورد نظر در حافظه پنهان (کش) موجود است یا خیر. اگر موجود باشد، دادهها را به کلاینت بازمیگرداند. در غیر این صورت، از پایگاه داده استعلام میگیرد، پاسخ را در کش ذخیره میکند و سپس آن را به کلاینت میفرستد. این استراتژی حافظه پنهان، Read-through Cache نامیده میشود. استراتژیهای دیگری نیز برای حافظه پنهان وجود دارد که بسته به نوع داده، اندازه و الگوهای دسترسی انتخاب میشوند. یک مطالعه پیشین، چگونگی عملکرد استراتژیهای مختلف حافظه پنهان را توضیح داده است [6].
تعامل با سرورهای حافظه پنهان ساده است، زیرا اکثر آنها رابطهای برنامهنویسی (API) برای زبانهای برنامهنویسی رایج ارائه میدهند. قطعهکد زیر نمونهای از APIهای معمول در Memcached را نشان میدهد:
SECONDS = 1 cache.set('myKey, 'hi there', 3600 * SECONDS) cache.get('myKey')
در ادامه، چندین نکته کلیدی که هنگام استفاده از سیستم حافظه پنهان باید در نظر بگیرید، آورده شده است:
تصمیمگیری برای زمان استفاده از کش: زمانی از حافظه پنهان استفاده کنید که دادهها بهطور مکرر خوانده میشوند اما به ندرت تغییر میکنند. از آنجایی که دادههای کششده در حافظه فرار (Volatile Memory) ذخیره میشوند، سرور کش برای ذخیرهسازی دائمی دادهها مناسب نیست. برای مثال، اگر سرور کش ریاستارت شود، تمام دادههای موجود در حافظه از دست میروند. بنابراین، دادههای مهم باید در ذخیرهسازهای پایدار (Persistent Data Stores) ذخیره شوند.
سیاست انقضا (Expiration Policy): پیادهسازی یک سیاست انقضا تمرین خوبی است. دادههای کششده پس از انقضا، از حافظه حذف میشوند. اگر سیاست انقضا وجود نداشته باشد، دادهها برای همیشه در حافظه باقی میمانند. توصیه میشود زمان انقضا را خیلی کوتاه در نظر نگیرید، زیرا باعث میشود سیستم به دفعات زیاد دادهها را از پایگاه داده بارگذاری کند. در عین حال، طولانی بودن بیش از حد زمان انقضا نیز باعث میشود دادهها کهنه و نامعتبر (Stale) شوند.
هماهنگی (Consistency): این مورد شامل همگام نگهداشتن پایگاه داده و حافظه پنهان است. ناهماهنگی زمانی رخ میدهد که عملیات تغییر داده در پایگاه داده و بهروزرسانی در کش در قالب یک تراکنش واحد (Single Transaction) انجام نشود. حفظ این هماهنگی هنگام مقیاسدهی در چندین منطقه جغرافیایی (Regions) چالشبرانگیز است. برای جزئیات بیشتر، میتوانید به مقاله منتشر شده توسط فیسبوک با عنوان «Scaling Memcache at Facebook» مراجعه کنید.
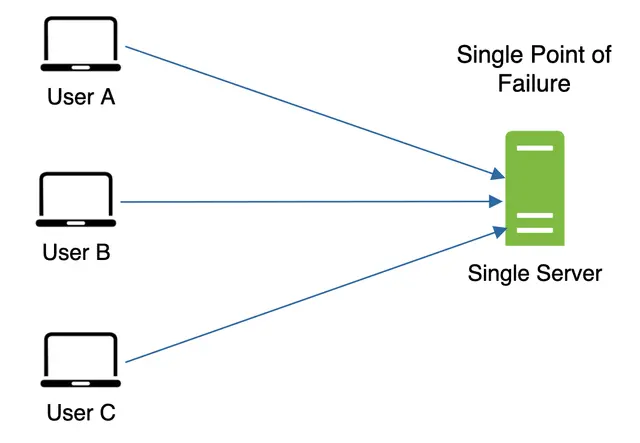
کاهش اثرات شکست (Mitigating failures): وجود تنها یک سرور کش میتواند باعث ایجاد «نقطه شکست واحد» (SPOF) شود. طبق تعریف ویکیپدیا: «نقطه شکست واحد، بخشی از سیستم است که در صورت از کار افتادن، کل سیستم را از کار میاندازد». در نتیجه، برای جلوگیری از SPOF، استفاده از چندین سرور کش در مراکز داده مختلف توصیه میشود. رویکرد پیشنهادی دیگر، اختصاص حافظه بیش از حد نیاز (Overprovisioning) با یک درصد مشخص است تا هنگام افزایش مصرف حافظه، یک فضای رزرو (Buffer) وجود داشته باشد.
زمانی که ظرفیت حافظه پنهان (کش) پر میشود، هر درخواستی برای اضافه کردن آیتمهای جدید ممکن است باعث حذف آیتمهای موجود شود؛ این فرآیند تخلیه کش (Cache Eviction) نامیده میشود.
LRU (Least-Recently-Used): محبوبترین سیاست تخلیه کش است که در آن آیتمهایی که در طولانیترین زمان اخیر استفاده نشدهاند، حذف میشوند.
LFU (Least Frequently Used): در این روش آیتمهایی که کمترین دفعات استفاده را داشتهاند حذف میشوند.
FIFO (First In First Out): در این مدل، اولین آیتمی که وارد کش شده است، اولین آیتمی خواهد بود که تخلیه میشود.
بسته به نوع کاربری و سناریوهای مختلف، میتوان هر یک از این سیاستها را اتخاذ کرد.
شبکه توزیع محتوا یا CDN، شبکهای از سرورهای پراکنده از نظر جغرافیایی است که برای تحویل محتوای ایستا (Static) استفاده میشود. سرورهای CDN محتواهایی نظیر تصاویر، ویدیوها، فایلهای CSS، جاوااسکریپت و غیره را در خود ذخیره (Cache) میکنند.
ذخیرهسازی محتوای پویا (Dynamic content caching) مفهومی نسبتاً جدید است که از محدوده این دوره خارج است. این قابلیت اجازه میدهد صفحات HTML که بر اساس مسیر درخواست (Path)، رشتههای پرسوجو (Query strings)، کوکیها و هدرهای درخواست ساخته میشوند نیز کش شوند. برای اطلاعات بیشتر در این زمینه میتوانید به مقاله شماره [9] در منابع مراجعه کنید. تمرکز این دوره بر چگونگی استفاده از CDN برای ذخیره محتوای ایستا است.
در ادامه، نحوه عملکرد CDN در سطح کلان (High-level) آمده است: وقتی کاربری از یک وبسایت بازدید میکند، سرور CDN که از نظر جغرافیایی به او نزدیکتر است، محتوای ایستا را تحویل میدهد. به طور منطقی، هرچه کاربر از سرورهای CDN دورتر باشد، وبسایت کندتر بارگذاری میشود. برای مثال، اگر سرورهای CDN در سانفرانسیسکو باشند، کاربران در لسآنجلس محتوا را سریعتر از کاربران ساکن در اروپا دریافت میکنند.
شکل ۹ نمونهای عالی است که نشان میدهد چگونه CDN زمان بارگذاری را بهبود میبخشد.
شکل ۱۰ گردش کار (Workflow) یک CDN را نشان میدهد.
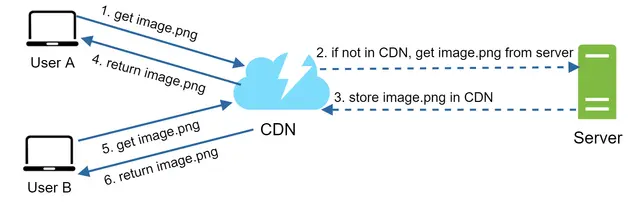
۱. درخواست کاربر A: کاربر A سعی میکند با استفاده از یک URL، فایل image.png را دریافت کند. دامنه این URL توسط تأمینکننده CDN ارائه میشود. دو آدرس زیر نمونههایی هستند که نشان میدهند URL تصاویر در CDNهای آمازون (Cloudfront) و Akamai چگونه به نظر میرسند:
https://mysite.cloudfront.net/logo.jpg
https://mysite.akamai.com/image-manager/img/logo.jpg
۲. عدم وجود در کش (Cache Miss): اگر سرور CDN فایل image.png را در حافظه پنهان خود نداشته باشد، آن را از منبع اصلی (Origin) درخواست میکند. این منبع میتواند یک وبسرور یا یک فضای ذخیرهسازی آنلاین مانند Amazon S3 باشد.
۳. پاسخ منبع اصلی: منبع اصلی فایل image.png را به سرور CDN بازمیگرداند. این پاسخ شامل یک هدر اختیاری HTTP به نام Time-to-Live (TTL) است که مشخص میکند تصویر تا چه زمانی باید در کش باقی بماند.
۴. ذخیرهسازی و تحویل: CDN تصویر را کش کرده و آن را به کاربر A بازمیگرداند. تصویر تا زمانی که TTL منقضی نشده باشد، در CDN باقی میماند.
۵. درخواست کاربر B: کاربر B درخواستی برای دریافت همان تصویر ارسال میکند.
۶. تحویل از کش (Cache Hit): تا زمانی که TTL منقضی نشده باشد، تصویر مستقیماً از حافظه پنهان CDN بازگردانده میشود.
هزینه: CDNها توسط شرکتهای ثالث اداره میشوند و شما بابت انتقال دادهها (ورودی و خروجی) هزینه پرداخت میکنید. ذخیره داراییهایی که به ندرت استفاده میشوند سود قابل توجهی ندارد، بنابراین باید خروج آنها از CDN را در نظر بگیرید.
تنظیم انقضای مناسب برای کش: برای محتوای حساس به زمان، تنظیم زمان انقضای کش حیاتی است. این زمان نباید خیلی طولانی یا خیلی کوتاه باشد. اگر خیلی طولانی باشد، محتوا دیگر تازه نخواهد بود؛ و اگر خیلی کوتاه باشد، باعث بارگذاری مکرر محتوا از سرورهای اصلی به CDN میشود.
جایگزینی در صورت خرابی (CDN Fallback): باید در نظر بگیرید که وبسایت یا اپلیکیشن شما چگونه با خرابی احتمالی CDN مقابله میکند. اگر قطعی موقتی در CDN رخ دهد، کلاینتها باید بتوانند مشکل را شناسایی کرده و منابع را مستقیماً از سرور اصلی درخواست کنند.
ابطال فایلها (Invalidating files): شما میتوانید یک فایل را قبل از تاریخ انقضا با استفاده از روشهای زیر از CDN حذف کنید: ۱. ابطال شیء (Object) در CDN با استفاده از APIهایی که فروشندگان CDN ارائه میدهند. ۲. استفاده از نسخهبندی اشیاء (Object Versioning) برای ارائه نسخهای متفاوت. برای این کار میتوانید پارامتری مانند شماره نسخه را به URL اضافه کنید (مثلاً image.png?v=2).
شکل ۱۱ طراحی سیستم را پس از اضافه شدن CDN و لایه حافظه پنهان (Cache) نشان میدهد.
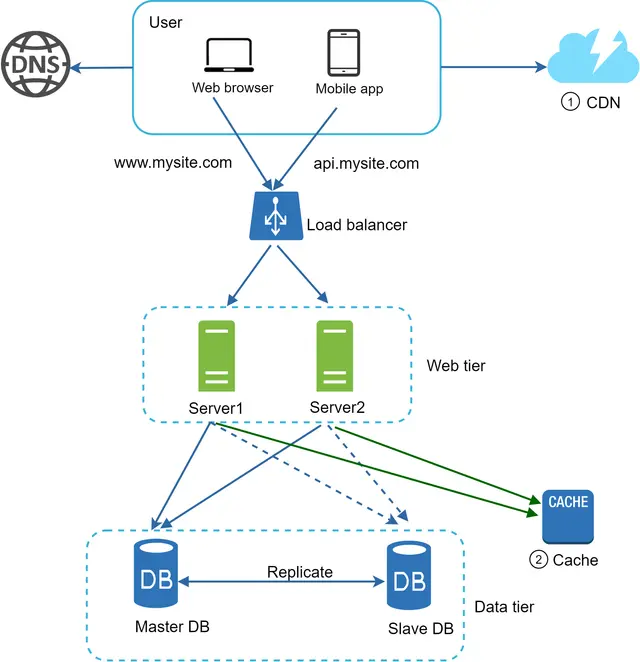
۱. داراییهای ایستا (JS، CSS، تصاویر و غیره) دیگر توسط وبسرورها ارائه نمیشوند، بلکه برای عملکرد بهتر از CDN فراخوانی میشوند. ۲. بار پایگاه داده با استفاده از کش کردن دادهها (Caching) کاهش یافته است.
اکنون نوبت به بررسی مقیاسدهی افقی لایه وب رسیده است. برای این منظور، باید «وضعیت» (State) - برای مثال دادههای نشست یا همان Session کاربر - را از لایه وب خارج کنیم. یک رویکرد مناسب، ذخیره دادههای نشست در یک فضای ذخیرهسازی پایدار مانند پایگاه داده رابطهای یا NoSQL است. با این کار، هر وبسرور در کلاستر (خوشه) میتواند به دادههای وضعیت از طریق پایگاه داده دسترسی داشته باشد. این ساختار، لایه وب بدون وضعیت نامیده میشود.
یک سرور «باوضعیت» (Stateful) و یک سرور «بدون وضعیت» (Stateless) تفاوتهای کلیدی با هم دارند. سرور باوضعیت، دادههای کلاینت (وضعیت) را از یک درخواست تا درخواست بعدی به خاطر میسپارد؛ اما سرور بدون وضعیت، هیچ اطلاعاتی از وضعیت را نزد خود نگه نمیدارد.
شکل ۱۲ نمونهای از یک معماری باوضعیت را نشان میدهد.
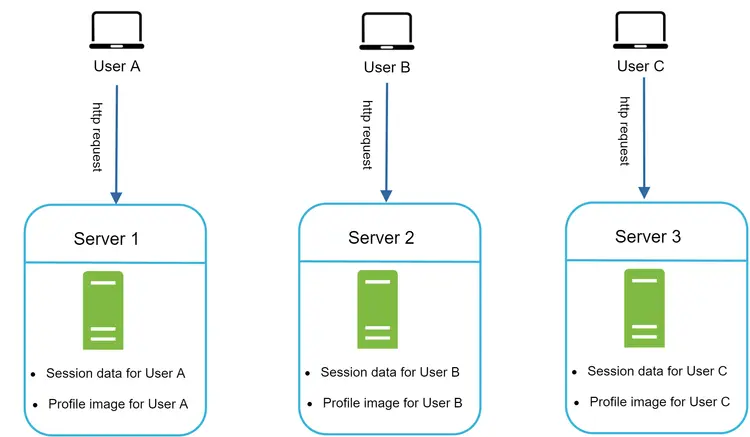
در شکل ۱۲، دادههای نشست (Session) و تصویر پروفایل کاربر A در «سرور ۱» ذخیره شده است. برای احراز هویت کاربر A، تمام درخواستهای HTTP او باید حتماً به «سرور ۱» هدایت شوند. اگر درخواستی به سرورهای دیگر مانند «سرور ۲» ارسال شود، احراز هویت با شکست مواجه میشود، زیرا «سرور ۲» حاوی دادههای نشست کاربر A نیست. به همین ترتیب، تمام درخواستهای HTTP کاربر B باید به «سرور ۲» و تمام درخواستهای کاربر C باید به «سرور ۳» هدایت شوند.
مشکل اینجاست که هر درخواست از یک کلاینت مشخص، باید دقیقاً به همان سرور قبلی هدایت شود. این کار در اکثر متعادلکنندههای بار (Load Balancers) از طریق قابلیت Sticky Sessions (نشستهای چسبنده) قابل انجام است؛ اما این روش بار اضافی (Overhead) به سیستم تحمیل میکند. علاوه بر این، با این رویکرد، اضافه یا حذف کردن سرورها بسیار دشوارتر میشود و مدیریت خرابی سرورها نیز به چالشی جدی تبدیل میگردد.
شکل ۱۳ معماری بدون وضعیت را نشان میدهد.
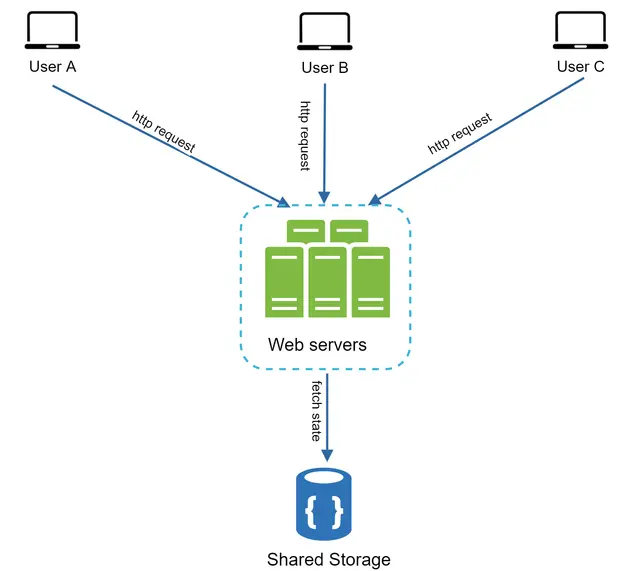
در این معماری بدون وضعیت (Stateless)، درخواستهای HTTP کاربران میتواند به هر یک از سرورهای وب ارسال شود؛ این سرورها دادههای وضعیت (State) را از یک ذخیرهساز دادهی مشترک واکشی میکنند. در این حالت، دادههای وضعیت در یک منبع مشترک ذخیره شده و خارج از سرورهای وب نگه داشته میشوند. یک سیستم بدون وضعیت، سادهتر، مقاومتر و مقیاسپذیرتر است.
شکل ۱۴ طراحی بهروزرسانیشده را با یک لایه وب بدون وضعیت نشان میدهد.
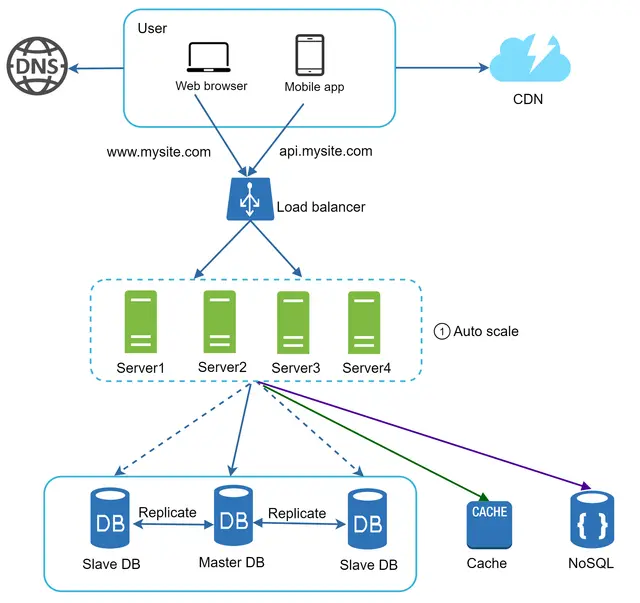
در شکل ۱۴، ما دادههای نشست (Session) را از لایه وب خارج کرده و آنها را در یک ذخیرهساز داده پایدار ذخیره میکنیم. این ذخیرهساز مشترک میتواند یک پایگاه داده رابطهای، Memcached/Redis، NoSQL و غیره باشد. در اینجا پایگاه داده NoSQL انتخاب شده است زیرا مقیاسدهی آن آسان است. مقیاسدهی خودکار (Autoscaling) به معنای اضافه یا حذف کردن خودکار سرورهای وب بر اساس حجم ترافیک است. پس از خارج کردن دادههای وضعیت از سرورهای وب، مقیاسدهی خودکار لایه وب با افزودن یا حذف سرورها بسته به بار ترافیکی، به راحتی قابل دستیابی است.
وبسایت شما به سرعت رشد کرده و تعداد قابل توجهی کاربر بینالمللی جذب میکند. برای بهبود در دسترس بودن (Availability) و ارائه تجربه کاربری بهتر در مناطق جغرافیایی وسیعتر، پشتیبانی از مراکز داده متعدد (Data Centers) حیاتی است.
شکل ۱۵ یک نمونه پیکربندی با دو مرکز داده را نشان میدهد. در وضعیت عادی، کاربران از طریق geoDNS (که به آن مسیریابی جغرافیایی یا geo-routed نیز گفته میشود) به نزدیکترین مرکز داده هدایت میشوند؛ به طوری که برای مثال $x\%$ ترافیک به منطقه شرق آمریکا (US-East) و $(100 - x)\%$ به غرب آمریکا (US-West) ارسال میشود. geoDNS یک سرویس DNS است که اجازه میدهد نامهای دامنه بر اساس موقعیت مکانی کاربر، به آدرسهای IP مشخصی ترجمه شوند.
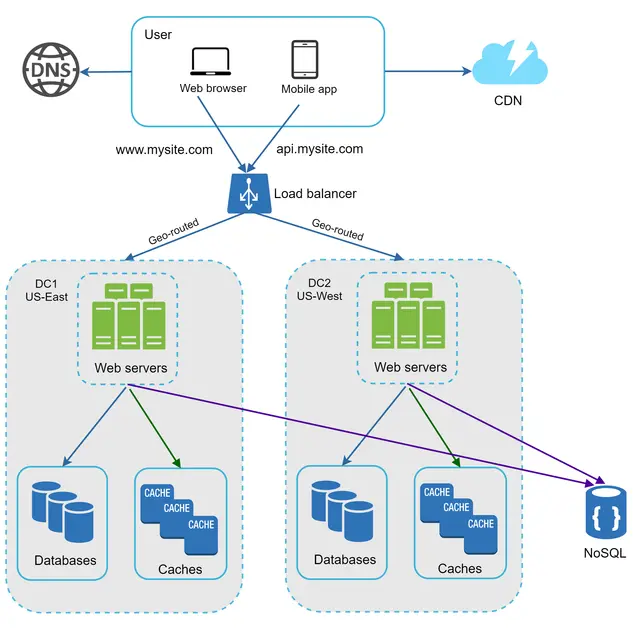
در صورت بروز هرگونه قطعی گسترده در مرکز داده، تمام ترافیک را به سمت یک مرکز داده سالم هدایت میکنیم. در شکل ۱۶، مرکز داده شماره ۲ (غرب آمریکا - US-West) آفلاین شده است و ۱۰۰٪ ترافیک به سمت مرکز داده شماره ۱ (شرق آمریکا - US-East) مسیریابی میشود.
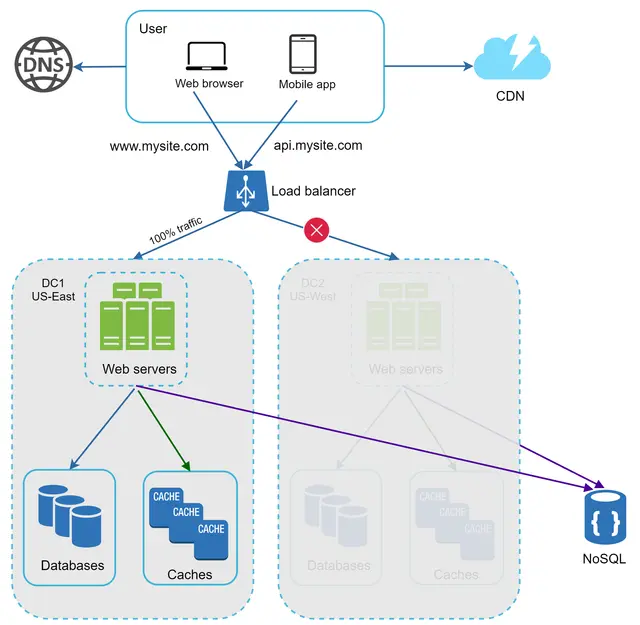
برای دستیابی به ساختار چند مرکز دادهای (Multi-data center)، باید چندین چالش فنی حل شود:
هدایت مجدد ترافیک (Traffic redirection): ابزارهای مؤثری برای هدایت ترافیک به مرکز داده صحیح مورد نیاز است. میتوان از GeoDNS برای هدایت ترافیک به نزدیکترین مرکز داده بر اساس محل استقرار کاربر استفاده کرد.
همگامسازی دادهها (Data synchronization): کاربران مناطق مختلف ممکن است از پایگاههای داده یا کشهای محلی متفاوتی استفاده کنند. در موارد خرابی و انتقال ترافیک (Failover)، ممکن است ترافیک به مرکز دادهای هدایت شود که دادههای مورد نظر در آن موجود نیست. یک استراتژی رایج، تکثیر دادهها (Replication) در چندین مرکز داده است. یک مطالعه پیشین نشان میدهد که نتفلیکس چگونه تکثیر ناهمگام (Asynchronous) دادهها را در چندین مرکز داده پیادهسازی میکند.
تست و استقرار (Test and deployment): در تنظیمات چند مرکز دادهای، آزمایش وبسایت/اپلیکیشن در مکانهای مختلف اهمیت حیاتی دارد. ابزارهای استقرار خودکار (Automated deployment) برای حفظ یکپارچگی سرویسها در تمام مراکز داده ضروری هستند.
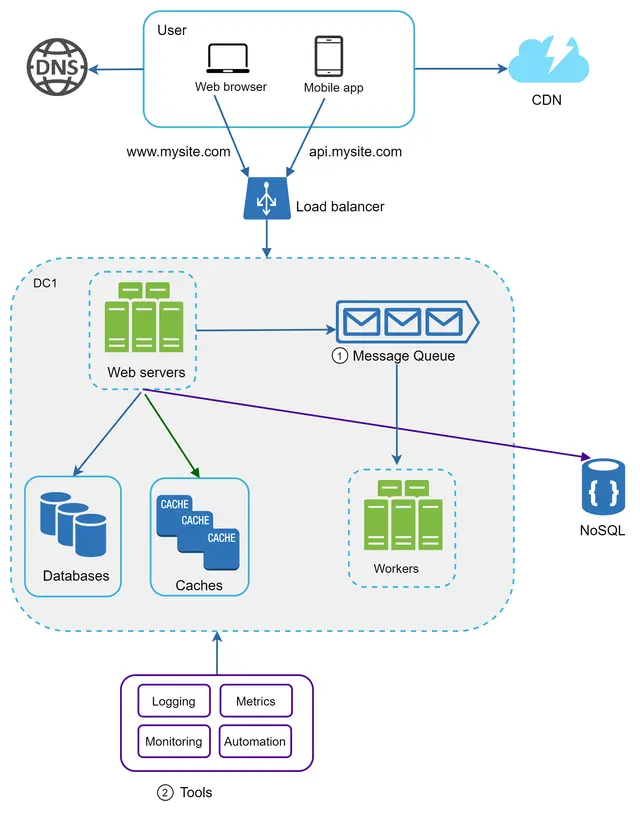
برای مقیاسدهی بیشتر سیستم، نیاز داریم تا اجزای مختلف سیستم را از هم جدا (Decouple) کنیم تا بتوانند بهطور مستقل مقیاسپذیر شوند. صف پیام (Message Queue) یک استراتژی کلیدی است که در بسیاری از سیستمهای توزیعشده واقعی برای حل این مشکل به کار گرفته میشود.
صف پیام یک جزء بادوام (Durable) است که در حافظه ذخیره شده و از ارتباطات ناهمگام (Asynchronous) پشتیبانی میکند. این جزء به عنوان یک بافر عمل کرده و درخواستهای ناهمگام را توزیع میکند. معماری پایه یک صف پیام ساده است: سرویسهای ورودی که تولیدکننده (Producers/Publishers) نامیده میشوند، پیامها را ایجاد کرده و در صف پیام منتشر میکنند. سرویسها یا سرورهای دیگر که مصرفکننده (Consumers/Subscribers) نامیده میشوند، به صف متصل شده و عملیات تعریفشده در پیامها را انجام میدهند. این مدل در شکل ۱۷ نشان داده شده است.
جداسازی اجزا (Decoupling)، صف پیام را به معماری محبوبی برای ساخت اپلیکیشنهای مقیاسپذیر و قابلاطمینان تبدیل میکند. با استفاده از صف پیام، تولیدکننده میتواند زمانی که مصرفکننده برای پردازش در دسترس نیست، پیام را در صف قرار دهد. همچنین مصرفکننده میتواند پیامها را از صف بخواند، حتی اگر تولیدکننده در آن لحظه در دسترس نباشد.
مورد کاربری (Use case) زیر را در نظر بگیرید: اپلیکیشن شما از قابلیتهای سفارشیسازی عکس، از جمله برش (Cropping)، افزایش وضوح (Sharpening)، محو کردن (Blurring) و غیره پشتیبانی میکند. انجام این وظایف زمانبر است. در شکل ۱۸، وبسرورها وظایف پردازش عکس را در صف پیام منتشر میکنند. سپس، کارگرهای پردازش عکس (Photo processing workers) وظایف را از صف پیام برداشته و عملیات سفارشیسازی عکس را بهصورت ناهمگام (Asynchronous) انجام میدهند.
در این ساختار، تولیدکننده و مصرفکننده میتوانند بهطور مستقل مقیاسدهی شوند. وقتی حجم صف بزرگ میشود، میتوان کارگرهای (Workers) بیشتری اضافه کرد تا زمان پردازش کاهش یابد. با این حال، اگر صف در بیشتر مواقع خالی باشد، میتوان تعداد کارگرها را کاهش داد.
هنگام کار با یک وبسایت کوچک که روی چند سرور محدود اجرا میشود، استفاده از گزارشگیری، معیارها و ابزارهای اتوماسیون یک «رویکرد خوب» است اما ضرورت حیاتی ندارد. با این حال، اکنون که سایت شما برای خدماترسانی به یک کسبوکار بزرگ رشد کرده است، سرمایهگذاری روی این ابزارها الزامی است.
گزارشگیری (Logging): پایش گزارشهای خطا (Error Logs) اهمیت زیادی دارد، زیرا به شناسایی خطاها و مشکلات سیستم کمک میکند. شما میتوانید گزارشهای خطا را در سطح هر سرور بررسی کنید یا از ابزارهایی برای تجمیع آنها در یک سرویس متمرکز استفاده کنید تا جستجو و مشاهده آنها آسانتر شود.
معیارها (Metrics): جمعآوری انواع مختلف معیارها به ما کمک میکند تا بینشهای تجاری کسب کرده و از وضعیت سلامت سیستم آگاه شویم. برخی از معیارهای زیر مفید هستند:
معیارهای سطح میزبان (Host level): مانند CPU، حافظه (Memory)، ورودی/خروجی دیسک (Disk I/O) و غیره.
معیارهای سطح تجمیعی (Aggregated level): برای مثال، عملکرد کل لایه پایگاه داده، لایه حافظه پنهان و غیره.
معیارهای کلیدی کسبوکار: مانند کاربران فعال روزانه (DAU)، نرخ بازگشت کاربر (Retention)، درآمد و غیره.
اتوماسیون (Automation): وقتی سیستم بزرگ و پیچیده میشود، برای افزایش بهرهوری نیاز به ساخت یا بهرهگیری از ابزارهای اتوماسیون داریم. یکپارچگی مداوم (Continuous Integration) یک تمرین مناسب است که در آن هر بار ثبت کد (Code check-in) از طریق اتوماسیون تایید میشود و به تیمها اجازه میدهد مشکلات را زودتر شناسایی کنند. علاوه بر این، خودکارسازی فرآیندهای ساخت (Build)، تست، استقرار (Deploy) و غیره میتواند بهرهوری توسعهدهندگان را به شکل قابل توجهی افزایش دهد.
شکل ۱۹ طراحی بهروزرسانیشده را نشان میدهد. به دلیل محدودیت فضا، تنها یک مرکز داده در تصویر نمایش داده شده است.
۱. این طراحی شامل یک صف پیام (Message Queue) است که به سیستم کمک میکند تا اجزای آن وابستگی کمتری به هم داشته باشند (Loosely coupled) و در برابر خرابیها مقاومتر شود. ۲. ابزارهای گزارشگیری، پایش (Monitoring)، معیارها و اتوماسیون به سیستم اضافه شدهاند.
با افزایش روزافزون دادهها، پایگاه داده شما بیش از پیش تحت فشار قرار میگیرد. اکنون زمان آن فرا رسیده است که لایه داده را مقیاسدهی کنید.
بهطور کلی دو رویکرد برای مقیاسدهی پایگاه داده وجود دارد: مقیاسدهی عمودی و مقیاسدهی افقی.
مقیاسدهی عمودی که با نام Scaling Up نیز شناخته میشود، به معنای افزودن قدرت بیشتر (CPU، رم، دیسک و غیره) به یک ماشین موجود است. سرورهای پایگاه داده بسیار قدرتمندی وجود دارند؛ به عنوان مثال، طبق مستندات سرویس پایگاه داده رابطهای آمازون (RDS)، شما میتوانید سروری با ۲۴ ترابایت رم تهیه کنید. این نوع سرورهای قدرتمند میتوانند حجم عظیمی از داده را ذخیره و مدیریت کنند. برای مثال، سایت stackoverflow.com در سال ۲۰۱۳ با وجود داشتن بیش از ۱۰ میلیون بازدیدکننده منحصربهفرد ماهانه، تنها از یک پایگاه داده اصلی (Master) استفاده میکرد. با این حال، مقیاسدهی عمودی با معایب جدی همراه است:
شما میتوانید CPU و رم بیشتری اضافه کنید، اما محدودیتهای سختافزاری وجود دارد. اگر پایگاه کاربران شما بسیار بزرگ باشد، یک سرور واحد پاسخگو نخواهد بود.
ریسک بالاتری برای ایجاد نقطه شکست واحد (SPOF) وجود دارد.
هزینه کلی مقیاسدهی عمودی بالاست؛ سرورهای فوققدرتمند بسیار گرانتر هستند.
مقیاسدهی افقی که با عنوان شاردینگ (Sharding) نیز شناخته میشود، روشی است که در آن سرورهای بیشتری به سیستم اضافه میگردد.
شکل ۲۰ تفاوت بین مقیاسدهی عمودی و افقی را با هم مقایسه میکند.
شاردینگ (Sharding) پایگاههای داده بزرگ را به بخشهای کوچکتر و قابلمدیریتتری به نام شارد (Shard) تقسیم میکند. هر شارد از طرحواره (Schema) یکسانی بهره میبرد، اما دادههای واقعی موجود در هر شارد، منحصر به همان بخش است.
شکل ۲۱ نمونهای از پایگاههای داده شاردشده را نشان میدهد. دادههای کاربران بر اساس شناسه کاربری (User ID) به یک سرور پایگاه داده اختصاص مییابند. هر زمان که بخواهید به دادهای دسترسی پیدا کنید، از یک تابع هش (Hash Function) برای یافتن شارد مربوطه استفاده میشود. در این مثال، از فرمول $user\_id \pmod 4$ به عنوان تابع هش استفاده شده است. اگر باقیمانده برابر با ۰ باشد، از «شارد ۰» برای ذخیره و واکشی دادهها استفاده میشود؛ اگر برابر با ۱ باشد، از «شارد ۱» استفاده خواهد شد و همین منطق برای سایر شاردها نیز اعمال میگردد.
شکل ۲۲ جدول کاربران را در پایگاههای داده شاردشده (Sharded Databases) نشان میدهد.
در این ساختار، به جای اینکه تمام دادههای کاربران در یک جدول عظیم ذخیره شوند، دادهها در چندین سرور (شارد) توزیع شدهاند. هر سطر بر اساس مقدار تابع هش (در اینجا شناسه کاربر) در شارد مشخصی قرار میگیرد تا بار پردازشی و حجم ذخیرهسازی بین سرورها تقسیم شود.
مهمترین عاملی که باید هنگام پیادهسازی استراتژی شاردینگ در نظر گرفت، انتخاب کلید شاردینگ (Sharding Key) است. کلید شاردینگ (که به آن کلید پارتیشن نیز میگویند) از یک یا چند ستون تشکیل شده است که نحوه توزیع دادهها را تعیین میکنند. همانطور که در شکل ۲۲ نشان داده شد، user_id همان کلید شاردینگ است. یک کلید شاردینگ به شما اجازه میدهد تا با مسیریابی پرسوجوها (Queries) به پایگاه داده صحیح، دادهها را بهطور کارآمد بازاریابی کرده و تغییر دهید. هنگام انتخاب کلید شاردینگ، یکی از مهمترین معیارها انتخاب کلیدی است که بتواند دادهها را بهطور یکنواخت توزیع کند.
شاردینگ تکنیک فوقالعادهای برای مقیاسدهی پایگاه داده است، اما اصلاً راهکار بینقصی نیست؛ چرا که پیچیدگیها و چالشهای جدیدی را به سیستم تحمیل میکند:
تغییر شاردبندی دادهها (Resharding): این کار زمانی لازم است که: ۱) یک شارد واحد به دلیل رشد سریع دیگر نتواند داده بیشتری را در خود جای دهد. ۲) برخی شاردها به دلیل توزیع نامتوازن داده، زودتر از بقیه دچار ظرفیتزدگی (Exhaustion) شوند. وقتی ظرفیت یک شارد تمام میشود، باید تابع شاردینگ بهروزرسانی شده و دادهها جابهجا شوند. هشینگ سازگار (Consistent Hashing) تکنیکی رایج برای حل این مشکل است.
مشکل سلبریتیها (Celebrity problem): به این مسئله، مشکل «کلید داغ» (Hotspot key) نیز میگویند. دسترسی بیش از حد به یک شارد خاص میتواند باعث اضافهبار سرور شود. تصور کنید دادههای کتی پری، جاستین بیبر و لیدی گاگا همگی در یک شارد قرار بگیرند؛ در اپلیکیشنهای اجتماعی، آن شارد تحت فشار شدید عملیات خواندن قرار خواهد گرفت. برای حل این مشکل، ممکن است مجبور شویم برای هر سلبریتی یک شارد اختصاصی در نظر بگیریم و یا هر شارد را دوباره بخشبندی کنیم.
جوئین و غیرنرمالسازی (Join and de-normalization): وقتی یک پایگاه داده در چندین سرور شارد میشود، انجام عملیات Join روی شاردهای مختلف دشوار خواهد بود. یک راهکار رایج، غیرنرمالسازی (De-normalization) پایگاه داده است تا پرسوجوها بتوانند تنها در یک جدول واحد انجام شوند.
در شکل ۲۳، ما پایگاههای داده را برای پشتیبانی از ترافیکِ دادهای که به سرعت در حال افزایش است، شارد میکنیم. همزمان، برخی از قابلیتهای غیررابطهای را به یک ذخیرهساز داده NoSQL منتقل میکنیم تا بار پایگاه داده کاهش یابد.
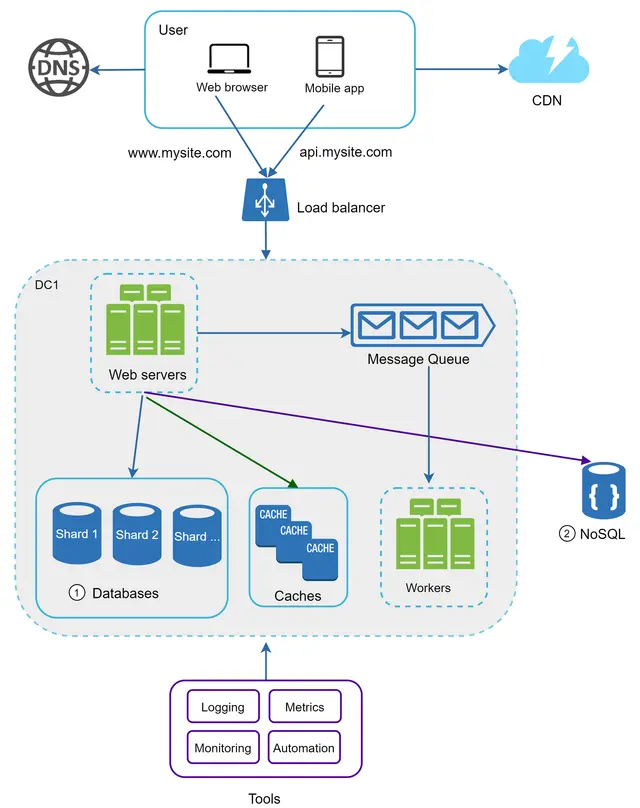
مقیاسدهی یک سیستم یک فرآیند تکرارپذیر (Iterative) است. تکرار و تمرین بر اساس آنچه در این فصل آموختهایم، میتواند ما را تا مسیر زیادی پیش ببرد. برای فراتر رفتن از مرز میلیونها کاربر، به بهینهسازیهای دقیقتر و استراتژیهای جدیدی نیاز است. به عنوان مثال، ممکن است نیاز باشد سیستم خود را بهینهسازی کرده و آن را به سرویسهای کوچکتر (Microservices) تجزیه کنید. تمام تکنیکهای آموختهشده در این فصل، پایه و اساس خوبی برای مقابله با چالشهای جدید فراهم میکند.
در پایان این فصل، خلاصهای از چگونگی مقیاسدهی سیستم برای پشتیبانی از میلیونها کاربر ارائه میدهیم:
لایه وب را بدون وضعیت (Stateless) نگه دارید.
در هر لایه، قابلیت افزونگی (Redundancy) ایجاد کنید.
تا حد امکان دادهها را کش (Cache) کنید.
از چندین مرکز داده (Data Centers) پشتیبانی کنید.
داراییهای ایستا را در CDN میزبانی کنید.
لایه دادههای خود را با استفاده از شاردینگ (Sharding) مقیاسدهی کنید.
لایه ها را به سرویسهای مجزا تقسیم کنید.
سیستم خود را پایش (Monitor) کرده و از ابزارهای اتوماسیون استفاده کنید.
تبریک میگویم که تا اینجا پیش آمدید! حالا میتوانید به خودتان افتخار کنید. کارتان عالی بود!
[۱] پروتکل انتقال ابرمتن (HTTP): https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
[۲] آیا باید فراتر از پایگاههای داده رابطهای رفت؟: https://blog.teamtreehouse.com/should-you-go-beyond-relational-databases
[۳] تکثیر (Replication): https://en.wikipedia.org/wiki/Replication_(computing
[۴] تکثیر چند-اصلی (Multi-master replication): https://en.wikipedia.org/wiki/Multi-master_replication
[۵] تکثیر کلاستر NDB: تکثیر دوطرفه و حلقوی: https://dev.mysql.com/doc/refman/8.4/en/mysql-cluster-replication-multi-source.html
[۶] استراتژیهای حافظه پنهان و نحوه انتخاب گزینه مناسب: https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/
[۷] نیشتالا و همکاران، "مقیاسدهی Memcache در فیسبوک،" دهمین سمپوزیوم USENIX در طراحی و پیادهسازی سیستمهای شبکهای (NSDI ’13): https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf
[۸] نقطه شکست واحد (SPOF): https://en.wikipedia.org/wiki/Single_point_of_failure
[۹] تحویل محتوای پویا در Amazon CloudFront: https://aws.amazon.com/cloudfront/dynamic-content/
[۱۰] پیکربندی Sticky Sessions برای Load Balancer کلاسیک: https://docs.aws.amazon.com/elasticloadbalancing/latest/classic/elb-sticky-sessions.html
[۱۱] معماری Active-Active برای تابآوری چند-منطقهای: https://netflixtechblog.com/active-active-for-multi-regional-resiliency-c47719f6685b
[۱۲] نمونههای Amazon EC2 با حافظه بالا (High Memory Instances): https://aws.amazon.com/ec2/instance-types/high-memory/
[۱۳] آنچه برای اجرای Stack Overflow لازم است: http://nickcraver.com/blog/2013/11/22/what-it-takes-to-run-stack-overflow
[۱۴] واقعاً برای چه کارهایی از NoSQL استفاده میکنید؟: http://highscalability.com/blog/2010/12/6/what-the-heck-are-you-actually-using-nosql-for.html