
اگه با PostgreSQL کار میکنی و برات مهمه بدونی یه کوئری چقدر خوب یا بد اجرا میشه، باید دستورهای EXPLAIN و EXPLAIN ANALYZE رو بشناسی. این دوتا دقیقاً بهت نشون میدن پشتصحنه کوئریهات چه خبره؛ از اینکه چطور دادهها خونده میشن، تا اینکه از ایندکس استفاده شده یا نه. اگه میخوای کوئریهات سریعتر بشن یا بفهمی چرا یه کوئری کنده، اینا دقیقاً همون ابزارهاییان که باید بلد باشی. توی این مقاله قراره همینا رو کامل و بیدردسر یاد بگیری.
پستگرس قبل از اجرای یک کوئری باید یک نقشه راه و برنامه ریز برای اجرای اون تهیه کنه. برنامهریز کوئری تو پستگرس یه جور مغز متفکره که قبل از اجرای هر کوئری، میره بررسی میکنه ببینه بهترین و سریعترین راه برای گرفتن دادهها چیه. مثلاً تصمیم میگیره از ایندکس استفاده کنه یا نه، یا اینکه جدول رو کامل اسکن کنه. هدفش اینه که کوئریت رو با کمترین هزینه و بیشترین سرعت اجرا کنه. با استفاده از EXPLAIN , EXPLAIN ANALYSE میتونی ببینی چه مسیری رو انتخاب کرده و اگر دیدی کوئریات چرا کند هست دقیقا بفهمی کدام قسمت باعث کندی شده.
دستور EXPLAIN بدون اجرای کوئری، فقط به شما میگه که پستگرس چطوری میخواد کوئری رو اجرا کنه. یعنی:
قبل از اینکه وارد جزییاتش بشیم بیایید برای جدول tasks با ساختار
create table tasks( id bigserial primary key, title varchar(255), user_id bigint not null constraint tasks_user_id_foreign references public.users, assign_to bigint constraint tasks_assign_to_foreign references public.users, created_by bigint constraint tasks_created_by_foreign references public.users, due_date timestamp(0), done_at timestamp(0), status smallint not null, priority smallint, description text, deleted_at timestamp(0), created_at timestamp(0), updated_at timestamp(0) );
دستور Explain رو در کوئری زیر اجرا کنیم:
EXPLAIN SELECT * FROM tasks WHERE status = 1;
دستور Explain کوئری رو واقعا اجرا نمیکنه فقط بهتون میگه که پستگرس قراره چیکار کنه. بعد از اینکه این دستور اجرا کنید، خروجیای مشابه این بهتون میده:

این خروجی این اطلاعات رو به ما میده:
حالا اگر همون کوئری رو به صورت زیر اجرا کنیم:
EXPLAIN ANALYSE SELECT * FROM tasks WHERE status = 1;
خروجی زیر میبینیم
Seq Scan on tasks (cost=0.00..45109.38 rows=1069470 width=193) (actual time=0.014..175.382 rows=1072482 loops=1)
Filter: (status = 1)
Rows Removed by Filter: 170028
Planning Time: 0.092 ms
Execution Time: 197.535 ms
اینجا هم همون اسکن تک تک ردیفها رو داریم، اما اطلاعات اضافه دیگهای هم داده. مثلا میگه که 170028تا رکورد بخاطرفیلتر حذف شدند، زمان صرف شده برای برنامه ریزی کوئری و زمان اجرای واقعی اون رو هم میده.
وقتی یه کوئری مینویسیم، پستگرس باید از یه جایی دادهها رو بخونه. این خوندن از جدول (یا از ایندکس)، میتونه با روشهای مختلفی انجام بشه که بهشون میگن روشهای اسکن (Scan Methods). مثلا وقتی نوشتیم
SELECT * FROM tasks WHERE status = 1;
پستگرس میپرسه: خب، حالا این status=1 رو چطوری چک کنم؟ کل جدولو خط به خط بخونم؟ ایندکس دارم؟ اونو چک کنم؟ فقط از ایندکس جواب میگیرم یا باید برم از جدول هم بخونم؟
انتخاب نوع اسکن مشخص میکنه که چطوری باید دادهها از دیتابیس واکشی بشن. بریم ببینیم انواع اسکن چیا هستند و کی استفاده میشن.
این در خروجی با Seq Scan مشخص میشه و یعنی جدول از اول تا آخر خط به خط و رکورد به رکورد خونده شده. این وقتایی استفاده میشه که
برای اینکه از این اسکن استفاده نشه ستونهای توی where باید ایندکس بشن.
این اسکن زمانی استفاده میشه که قسمت شرط میتونه با بررسی ایندکس برطرف بشه. بعد برای هر رکورد، اطلاعات از جدول هم خونده میشه که بهش heap access میگن. این وقتی استفاده میشه که روی ستون های شرط ایندکس داشته باشیم و کوئری هم یه طوری نباشه که دیتای خیلی زیادی رو بخواد برگردونه. توجه کنید هنوز برای هر ردیف جدول اصلی هم باید خونده بشه. مثلا کوئری
EXPLAIN SELECT title FROM tasks WHERE user_id=445972;
خروجیش میشه

که مشخص کرده از کدام ایندکس خونده و شرطش چی بوده.
این خیلی سریع هست و نیاز به رجوع به جدول اصلی نیست، یعنی همه رو از ایندکس میخونه. وقتی استفاده میشه که هم شرط و هم چیزهایی که داره select میشه همشون توی ایندکس هستند. وقتی از این استفاده میشه که ایندکسهای ترکیبی بسازید. مثلا برای tasks اینجوری ایندکس ساختم:
CREATE INDEX idx_tasks_status_user ON tasks(status, user_id);
بعد vacuum کردم
vacuum analyse tasks;
وقتی کوئری
EXPLAIN SELECT user_id, status FROM tasks WHERE status = 1;
نوشتم خروجی شد
Index Only Scan using idx_tasks_status_user on tasks (cost=0.43..26295.26 rows=1072162 width=10)
این نوع اسکن هم وقتی استفاده میشه که
در این نوع اسکن، حتماً از ایندکس استفاده میشه. اما باهاش رکوردها رو مستقیم نمیخونه، بلکه فقط ردیفهای مورد نیاز رو علامتگذاری میکنه.
این اسکن شامل دو مرحله است:
۱) مرحله اول (اسکن ایندکس) به ازای هر ایندکس، اسکن انجام میشه، یعنی آدرس رکوردهایی که در شرط صدق میکنند در یک بیتمپ ذخیره میشه
۲) در مرحله دوم که اسکن جدول یا اسکن هیپ هست اون رکوردها از جدول اصلی (یا heap) که آدرسشون در مرحله قبل بدست اومد، واکشی میشه.
اطلاعات در بیتمپ مشابه زیر هست، هر رکورد یا هست (۱) یا نیست (۰):
Row 1 → 1
Row 2 → 0
Row 3 → 1
...
پستگرس برای شرطهایی که تعداد رکوردهاش کم هست از ایندکس استفاده میکنه (چون خواندن از ایندکس و جدول رفت و برگشت داره) و شرطی که تعداد رکوردش زیاد هست از Filter (چک کردن شرط روی خود رکورد) استفاده میکنه.
بذارید چند تا مثال جالب برای این بزنم:
EXPLAIN SELECT user_id, status FROM tasks WHERE status = 1 and created_by = 387880;
خروجیش میشه
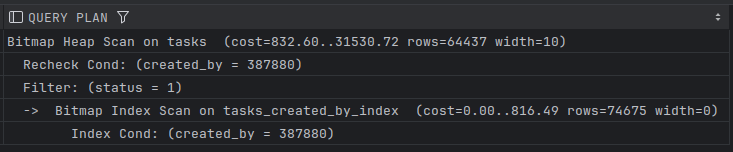
از برگ و آخرین سطح شروع میشه. چون شرط created_by = 387880 تعداد رکوردهاش خیلی کمتر هست از ایندکس میخونه، بعد status = 1 که صدهاهزار رکورد داره رو مستقیم از جدول میخونه.
حالا من تنها یک رکورد با status = 4 به جدول اضافه میکنم و این کوئری رو ببینید
EXPLAIN SELECT user_id, status FROM tasks WHERE status = 4 and created_by = 387880;
نتیجه میشه

همونطوری که میبینید، چون status = 4 تنها یک رکورد داره، اون از ایندکس استفاده میکنه و created_by که حدود ۷۰هزار رکورد داره از Filter استفاده میشه.
پستگرس ترجیح میده از یک ایندکس و در چند شرطی ایندکسدار استفاده کنه
این جوین سادهترین و ابتداییترین نوع جوین هست. مناسب زمانی هست که تعداد دادهها کم باشه یا شرطها به خوبی از ایندکس استفاده میکنند. تقریبا بخواهیم اون رو کد کنیم میشه این
for row1 in table1: for row2 in table2: if row1.x == row2.x: return row1 + row2
و بدیهی هست که اگر تعداد رکوردهای دو تا جدول M,N باشه زمان اجراش O(MN) هست که افتضاحه!
در این روش پستگرس اول یکی از جدولها (معمولاً کوچیکتره) رو میخونه و یه Hash Map ازش میسازه. بعد رکوردهای جدول دیگه رو با اون مقایسه میکنه.
این روش برای دیتا بزرگ مناسب هست و نیازی به ایندکس نداره اما منابع سختٰافزاری زیادی رو مصرف میکنه.
hashmap = {row.x: row for row in table2} for row in table1: if row.x in hashmap: return row + hashmap[row.x]
این زمانی استفاده میشه که هر دو جدول بر اساس ستون جوین مرتب باشن، اگر هم مرتب نباشن خود پستگرس مرتب میکنه. مبنای این روی مرتب سازی است و زمانی استفاده میشه که:
while row1 and row2: if row1.x == row2.x: return row1 + row2 elif row1.x < row2.x: row1++ else: row2++
چند تا مثال بزنیم:
EXPLAIN SELECT user_id, status FROM tasks t join users u on u.id = t.user_id WHERE status = 4 and t.created_by = 387880 and u.deleted_at isnull;
خروجیش شد
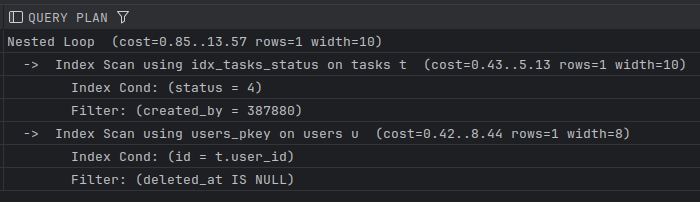
علتش هم مشخصه، چون تعداد رکوردها خیلی کم هست (فقط یکی) از Nested Loop استفاده کرده. بعدش نوشته
Index Scan using idx_tasks_status on tasks t
یعنی داره از ایندکس ستون status استفاده میکنه، ولی چون created_by = 387880 توی این ایندکس نیست، توی Filter بعد از اسکن اعمال میشه (تعدادش زیادتر از status = 4 هست). حالا برای هر نتیجه باید بره دنبال user بگرده:
Index Only Scan using users_pkey on users u
این نشون میده داره از ایندکس کلیداصلی user استفاده میکنه و از جدول اصلی هم استفاده نکرده.
حالا اگر اون دو تا شرط رو بردارم
EXPLAIN SELECT user_id, status FROM tasks t join users u on u.id = t.user_id WHERE u.deleted_at isnull;
میشه
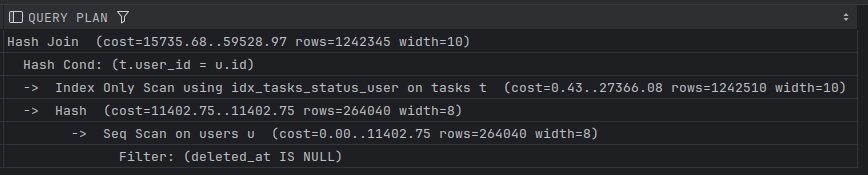
ستون deleted_at ایندکس نشده از اسکن ترتیبی استفاده شده، تعداد رکوردها زیاده (۱۲۴۲۵۱۰) و ستون جوین هم مرتب نیست پس از هش جوین داره استفاده میکنه. جدول وظایف بیشتر از کاربرا هست (هر کاربر چندین وظیفه داره)، پس از جدول کوچک که users باشه یک هش میسازه:
Hash (cost=11402.75..11402.75 rows=264040 width=8)
چون من قبلا ایندکس ترکیبی
CREATE INDEX idx_tasks_status_user ON tasks(status, user_id);
ساخته بودم پس برای گرفتن آی دی کاربر و status از فقط این ایندکس میتونه استفاده کنه، بنابراین خط
Index Only Scan using idx_tasks_status_user on tasks t
برای اون هست و در نهایت هم Hash join میشه.