مهدی علیزاده − ۹۹
مدت زمان خواندن متن به دقیقه: ۵ دقیقه
روزی روزگاری در زمانهای قدیم، مهندسهای عزیز دوست داشتند شبکههای کامپیوتری را کنترل کنند. حالا یعنی چی؟ یعنی اینکه بدونیم چه کسی چهقدر از پهنای باند رو استفاده میکنه؟ چند عدد پکت دارند در لحظه فرستاده میشوند؟ به کجا فرستاده میشوند؟ و ... . حالا خب چه مرگشون بوده که دوست داشتند این کار رو انجام بدهند؟ فرض کنید ما یک شبکهی داخلی مثل شبکهی دانشگاه داریم و میخواهیم اگر مورد حملهی آدمهای بد قرار گرفتیم بتونیم یک جوری اونها رو بلاک کنیم. برای این کار طبعا باید بتونیم تعداد پکتهایی که از هر source ip به دست ما میرسند رو یک جا ذخیره کنیم تا در صورتی که یکی داشت زیاد پکت میفرستاد بتوانیم تشخیص بدهیم و مثلا دسترسی فرستادن پکت رو ازش بگیریم.
خب، حالا بریم ببینم برای اینچه کارهایی کردهاند؟
اولین و سادهترین راه اینه که یک جایی توی سوییچ جدولی از اینکه هر کدوم از ipها چندتا پکت برامون فرستاده رو نگه داریم و هر بار که یک پکت جدید برامون فرستاده میشه، اون خونه از جدول مربوط به اون ip رو یک واحد زیاد کنیم. حال یک سیستم مانیتورینگ کوچک از شبکه خواهیم داشت که میتونیم اطلاعات بهدردبخوری ازش بهدست بیاریم.
مشکل این راه چیه؟ تا زمانی که برای مثال قرار باشه شبکهی دانشگاه رو مانیتور کنیم (که به نسبت شبکهی کوچکی حساب میشه) این راهحل مشکلی نداره. ولی فرض کنید شما یک شرکت بزرگ در حد Google یا Microsoft هستید و یک سری پایگاهدادهی بزرگ دارید و تریلیونتریلیون پکت در هر ثانیه به دست سوییچهاتون میرسن. توی این حالت انقدر تعداد پکتهایی که به دستمون میرسه زیاد هست که نمیتونیم به ازای هر جفت فرستنده و گیرنده پکتها رو آنالیز کنیم و تعدادشون رو توی حافظه نگه داریم. اینجاست که از ساختمان دادهها و الگوریتمهای احتمالاتی استفاده میکنیم.
توی خیلی از کارهای زندگی روزمرهمون ما نیازی نداریم که به یک سوال خیلی دقیق جواب بدیم. مثلا حتی اگه با ۱۰ درصد خطا هم به اون سوال جواب بدیم نیازمون برطرف میشه. تو مسئلهای که اینجا داریم هم همینطوره. مثلا من اگر تعداد پکتهای بین دو تا نقطه رو با ۵ درصد خطا هم گزارش کنم در خیلی از کاربردهایی که از این سیستم انتظار داریم اختلالی پیش نمیاد. اینجاست که سر و کلهی الگوریتمهای bloom filter و count-min sketch یا به اختصار CM sketch (که از اینجا به بعد با اسم اسکچ ازش یاد میکنیم) پیدا میشه.
به طور کلی اسکچها ساختماندادههایی احتمالاتی هستند که از نظر مصرف حافظه در تعداد دادهی بالا به شدت خوب عمل میکنن و خوبیشون اینه که وابسته به محیطی که برای این ساختمان داده تعریف میکنید، کران بالایی از خطایی که میتونن داشته باشن فراهم میکنن. خب حالا این اسکچها چی هستند؟
هر اسکچ از چند جدول هش و تابع هش متناظرشون تشکیل شده. در اینجا فرض میکنیم d تا جدول هش و متناظر اونها تابع هش داریم و سایز هر جدول هش هم w هست.
عملیات update برای هر جفت (key, value) اینطور تعریف میشه که مقدار کلید هش رو با استفاده از تمام توابع هش محاسبه میکنیم و به خونهی متناظر با خروجی هر تابع هش، مقدار value رو اضافه میکنیم. عملیات read هم اینطوری تعریف میشه که اول مقدار تابع هش برای کلیدی که قراره value متناظر با اون رو برگردونیم محاسبه میکنیم و کمینهی خونههای متناظر با خروجی توابع هش رو به عنوان خروجی برمیگردونیم؛ یا به صورت فرمال داریم:
update: table[j, hj(key)] += value ∨ j
read:min(table[0, h0(key)], ... , table[d-1, hd-1(key)])
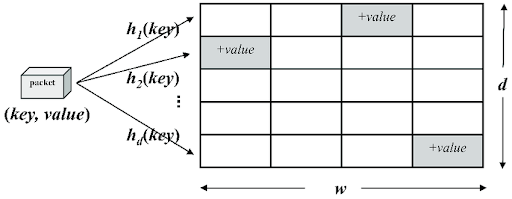
خب حالا با توجه به تعریف اسکچ میتونید حدس بزنید که اینجا برخوردهای زیادی میتونن رخ بدن و تقریب ما از جواب، از حالت واقعی خیلی دور بشه. ولی خبر خوب اینه که میشه با توجه به اندازهی مسئله و کران بالای خطایی که مد نظر داریم، پارامترهای مسئله شامل اندازه و تعداد جدولهای هش رو جوری تنظیم کرد که نیازهای ما در مسئلهی مورد نظر برآورده بشن (به عنوان یک تمرین سادهی درس ساختمانداده هم میتونید فکر کنید که چهجوری w و d رو تنظیم کنیم و کران بالای خطا رو هم در بیارید:دی).
در نهایت در دنیای شبکهها، دوتایی (source ip , destination ip) رو به عنوان کلید در نظر میگیرن (گاهی وقتها هم به این دوتایی، دو تا پارامتر source port و destination port رو اضافه میکنن) و با استفاده از اسکچهایی که روی سوییچها وجود دارن اقدام به مانیتور کردن یا تنظیم شبکه برای بهدست آوردن بیشترین کارآیی ممکن میکنن.
در نهایت لازم به ذکره که کاربرد اسکچها به مانیتورینگ شبکه محدود نمیشه، بلکه کاربردهای وسیع دیگهای مانند caching هم دارند. اگه علاقهمند بودید بیشتر درمورد این مسائل بخونید میتونید دنبال کلیدواژههایی مانند netcache و netflow بگردید و مقالههای مرتبط با این مسئله رو مطالعه کنید.