
اگه تا حالا فکر میکردی مخاطب اصلی محتوای سایتت فقط انسانها هستن، وقتشه یه بار دیگه به قضیه نگاه کنی. توی دنیای وب، اولین کسی که قراره محتوای تو رو ببینه و دربارهش قضاوت کنه، یه آدم نیست؛ یه رباته. کراولرهای وب مثل گوگلبات هر روز بیوقفه از بین میلیونها صفحهی اینترنتی عبور میکنن تا بفهمن چی ارزش دیده شدن داره و چی نه.
این رباتها دنبال محتوایی هستن که ساختار خوبی داره، درست ایندکس میشه و بدون دردسر قابل خوندنه. یعنی اگه سایتت براشون خوشساخت نباشه، حتی اگه بهترین مقالهی دنیا رو نوشته باشی، شانس زیادی برای درخشیدن تو نتایج جستجو نداری. تو این وبلاگ اومدم تا یه دید واضح بهت بدم که چطور سایتت رو جوری بسازی که هم برای کاربر جذاب باشه و هم کراولرها عاشقش بشن.
قبل از اینکه بخوای سایتت رو برای کراولرها بهینهسازی کنی، اول باید بفهمی اصلاً این کراولرها چیان و چطوری کار میکنن. کراولرهای سایت (مثل Googlebot) یه جور ربات نرمافزاریان که اینترنت رو مثل تار عنکبوت میگردن و صفحات مختلف رو پیدا میکنن، بررسی میکنن و اطلاعاتشون رو برای ایندکس شدن میفرستن سمت موتور جستجو. انگار یه پستچی دیجیتالیان که روز و شب، بیوقفه مشغول بررسی محتوای سایتها هستن.
اما این فقط یه گشتوگذار ساده نیست. این رباتها از یه مسیر کاملاً هدفمند عبور میکنن: از یه لینک به لینک بعدی میرن، صفحات جدید رو کشف میکنن، محتوای قدیمی رو دوباره بررسی میکنن و تو هر لحظه تصمیم میگیرن کدوم صفحه ارزش ایندکس شدن و دیده شدن داره و کدوم نه. یعنی هر خط کد و هر ساختار در HTML توی سایتت، میتونه توی تصمیمگیری این رباتها تاثیرگذار باشه.
کراولرهای وب که بهشون میگن اسپایدر یا رباتهای عنکبوتی دقیقاً همون موجودات دیجیتالی هستن که بیصدا و بیوقفه توی تارهای اینترنت میچرخن. کارشون پیدا کردن، خوندن و ذخیرهی محتواست. از متن گرفته تا تصاویر، ویدیوها و حتی فایلهای PDF؛ هر چی قابل خوندن باشه رو جمع میکنن و برای موتور جستجو میفرستن.
این کراولرها خودکارن، یعنی نیازی به دخالت آدمیزاد ندارن. یکی از معروفترینهاشون Googlebot هست، که خودش هم به چند نسخه تقسیم میشه: مثلاً Googlebot Desktop مخصوص بررسی نسخهی دسکتاپ سایته، و Googlebot Smartphone هم نسخهی موبایل رو میسابه . نکتهی مهم اینه که گوگل حالا دیگه نسخهی موبایل رو تو اولویت قرار میده، پس اون ربات موبایل، بیشتر به سایتت سر میزنه. اگه محتوای موبایلت درست لود نشه یا ساختار درستی نداشته باشه، Googlebot خیلی راحت ازش میگذره و به صفحهی بعدی میره.
بیشتر بخوانید: انقلاب جدید در جستجوی گوگل | Query Fan-Out پایان دوران کلمات کلیدی
تصور کن موتورهای جستجو مثل کتابخونههای عظیمان، اما بدون قفسهبندی و فهرستبندی. حالا این کراولرها همون کتابدارهای شبانهروزیان که کل اینترنت رو میگردن، صفحهها رو پیدا میکنن، اطلاعاتشون رو ثبت میکنن و میذارن توی قفسههای درست.
بدون حضور این رباتها، گوگل یا هر موتور جستجوی دیگه هیچ ایدهای نداره که سایت تو دربارهی چیه، چه محتوایی داره یا حتی وجود داره یا نه. یعنی اگه کراولرها نیان سراغ سایتت، انگار اصلاً وجود خارجی نداری! پس نقش اصلیشون اینه که محتوا رو کشف کنن، بفرستن به سرورهای موتور جستجو و اون اطلاعات رو وارد شاخص (Index) کنن؛ جایی که همهچیز برای ایندکس در نتایج جستجو آماده میشه.
اگه میخوای تو اون فهرست باشی، باید اول مطمئن شی که کراولرها راحت و بیدردسر میتونن بهت سر بزنن، محتوای تو رو درک کنن و با خودشون ببرن.
هر صفحهای که توی سایتت منتشر میکنی، یه سفر طولانی رو شروع میکنه. سفری که اگه درست پیش بره، میتونه اون صفحه رو به صدر نتایج گوگل برسونه. اما اگه جایی از مسیر گیر کنه یا درست آماده نشده باشه، ممکنه برای همیشه توی سایه بمونه، حتی اگه محتوای عالی داشته باشه.
موتور جستجو بهخصوص گوگل برای اینکه بتونه محتوای یه صفحه رو نشون بده، باید اول اون صفحه رو پیدا کنه، بعد تحلیلش کنه و نهایتاً توی نتایج جستجو به نمایش بذاره. این فرایند چهار مرحلهای بهشدت مهمه و هر کدوم از مراحلش یه نقش کلیدی دارن. اگه یه جایی این زنجیره قطع بشه، محتوای تو هیچوقت به چشم مخاطب نمیرسه.

همهچی از اینجا شروع میشه: وقتی گوگلبات همون ربات پرکار و دقیق گوگل وارد عمل میشه تا صفحهی سایت تو رو پیدا کنه. به این فرآیند میگن «کراول سایت»؛ یعنی گوگلبات میاد سراغ سایتت، آدرسها (URLها) رو بررسی میکنه و شروع میکنه به دریافت اطلاعات از صفحهها. انگار یه پستچی هوشمند باشه (پسر غدیر) که همهچیز رو اسکن میکنه و میبره تحویل مرکز پردازش میده.
این کراولر از پروتکلهای مختلفی مثل HTTP/1.1 و HTTP/2 استفاده میکنه، و حتی اگه لازم باشه از FTP یا FTPS هم کمک میگیره. نکته جالب اینه که گوگلبات از جاهای مختلف دنیا صفحهها رو بررسی میکنه، ولی بیشتر آدرسهای IPش از آمریکا هستن. پس اگه توی لاگهای سرورت ردپایی از یه کاربر ناشناس با آیپی آمریکایی دیدی، شاید یه گوگلبات مهمونت بوده!
تا اینجای کار، گوگلبات فقط یه سری اطلاعات خام از سایتت جمع کرده؛ اما حالا نوبت به تحلیل محتوا میرسه. این مرحله رو بهش میگن «ایندکسینگ». یعنی محتوا و متادیتاهایی مثل عنوان صفحه، تگها، توضیحات متا، ساختار هدینگها و حتی جایگذاری تصاویر توسط الگوریتمها بررسی میشن تا بفهمن این صفحه دقیقاً دربارهی چیه.
انگار که گوگل میشینه و صفحهی تو رو ورق میزنه، نکات مهم رو هایلایت میکنه و بعد میذاره توی یه قفسهی دیجیتال مخصوص، جایی که بعداً بشه راحت پیداش کرد. اگه ساختار صفحهت بههمریخته باشه، محتوای اصلی گم باشه یا متا دیتا ناقص باشه، ممکنه این مرحله اصلاً موفق انجام نشه و صفحهت به آرشیو بزرگ گوگل راه پیدا نکنه. یعنی اصلاً انگار وجود خارجی نداره.
حالا که صفحهت وارد شاخص گوگل شده، نوبت میرسه به رقابت اصلی. یعنی قراره توی یه صف طولانی از محتواهای مشابه، گوگل تصمیم بگیره که صفحهی تو باید کجای نتایج جستجو ظاهر بشه. این همون لحظهایه که رتبهبندی اتفاق میافته.
گوگل صدها فاکتور رو بررسی میکنه: از کیفیت محتوا و سرعت لود گرفته تا میزان تطابق با کلمه کلیدی، تجربه کاربری، نسخه موبایل، امنیت سایت، موقعیت مکانی کاربر و حتی نوع دستگاهی که داره ازش استفاده میکنه. یعنی دو نفر با یه جستجوی مشابه ممکنه دو نتیجهی متفاوت ببینن، چون شرایطشون فرق داره.
در این مرحله، الگوریتمهای پیچیدهی گوگل وارد عمل میشن تا از بین میلیاردها صفحه، دقیقاً همونی رو نشون بدن که برای اون کاربر خاص بهترینه. اگه صفحهت ساختار مناسبی داشته باشه و محتوای باکیفیت ارائه بده، شانس این رو داری که درست همون جایی دیده بشی که کاربر دنبالش میگرده: صفحهی اول.
وقتی یه صفحه ایندکس شد و یه جایگاه اولیه توی نتایج گرفت، داستان تموم نمیشه. اتفاقاً تازه گوگل میخواد ببینه واقعاً لیاقت رتبه رو داری یا نه. چطوری؟ با تست کردن.
گوگل دائم رفتار کاربران رو نسبت به اون صفحه بررسی میکنه. مثلاً آیا کسی که رو لینک صفحه کلیک کرده، تو سایت مونده یا سریع برگشته به صفحه نتایج؟ چند نفر تا آخر صفحه رو خوندن؟ آیا روی چیز دیگهای هم کلیک کردن؟ این رفتارها به گوگل کمک میکنه بفهمه صفحهت چقدر واقعاً به درد مخاطب میخوره.
اگه تعامل خوب باشه، کمکم رتبهت بهتر میشه؛ ولی اگه نشون بدی فقط ظاهر قشنگ داری و مخاطب راضی نیست، گوگل بدون تعارف رتبهت رو پایین میکشه. پس بعد از انتشار محتوا، ماجرا تموم نمیشه؛ تازه شروع مرحلهی آزمون و خطاست.
وقتی حرف از کراولر سایت میزنیم، ذهن خیلیها فقط میره سمت Googlebot. اما واقعیت اینه که پشت پردهی اینترنت، یه لشگر واقعی از رباتها وجود دارن که هرکدوم وظیفهی خاصی دارن و از طرف شرکتهای مختلف فرستاده میشن. این رباتها، بعضی وقتا بدون اینکه تو حتی متوجه شی، دارن با سرعت باورنکردنی از سایتت بازدید میکنن و همهچیز رو بررسی میکنن.
گوگل خودش کراولرهاش رو به سه دستهی اصلی تقسیم کرده:

این دسته وظیفهی بررسی عمومی صفحات و جمعآوری داده رو دارن. اونا میان، صفحهها رو میخونن و اطلاعاتشون رو برای ایندکس شدن ارسال میکنن. Googlebot که معروفترینشونه، همین دستهست. معمولاً از همینها بیشترین ترافیک کراولی رو داریم.
اینها برای سایتهایی هستن که توافقات خاص با گوگل دارن. مثلاً ممکنه یه پلتفرم خاص محتوایی توافق کرده باشه که بخشی از اطلاعاتش به شکل متفاوتی بازنگری بشه. این کراولرها فقط روی همون موارد خاص تمرکز دارن و رفتارشون خیلی هدفمند و محدودتره.
این نوع کراولرها زمانی فعال میشن که یه کاربر کاری انجام بده. مثلاً توی ابزارهایی مثل سرچ کنسول گوگل، وقتی دستی یه URL رو میفرستی برای بررسی، همون لحظه یه Fetcher فعال میشه و اون صفحه رو بازنگری میکنه.
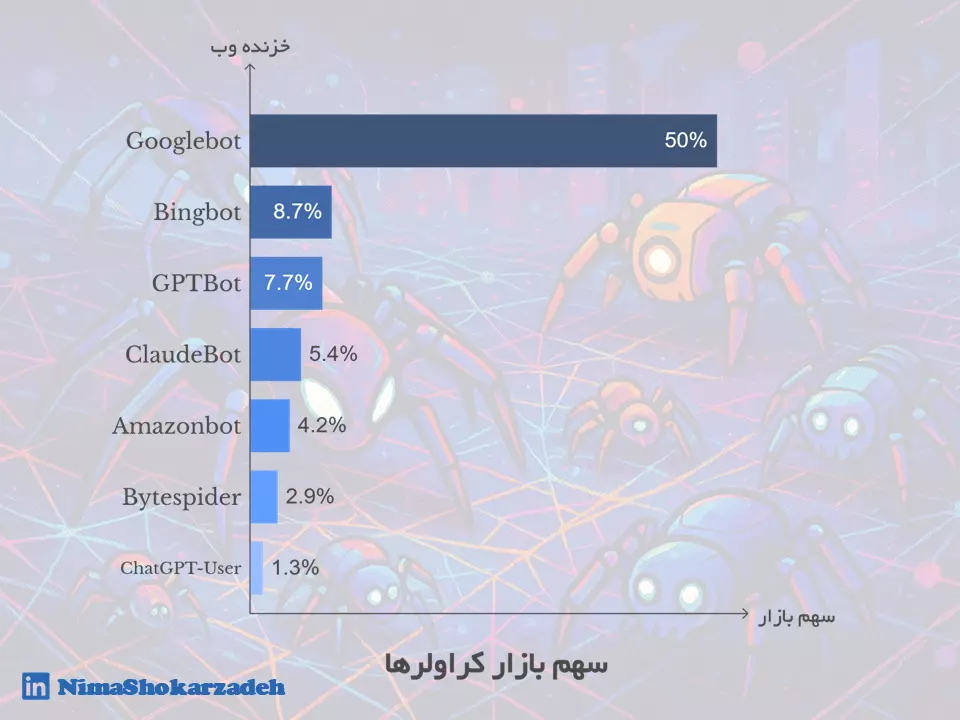
اگه بخوای یه نگاه آماری به داستان بندازی، اوضاع از می ۲۰۲۴ تا می ۲۰۲۵ خیلی تغییر کرده. کراولرهای سنتی هنوزم فعالترینان، اما یه رشد عجیب توی کراولرهای مبتنی بر هوش مصنوعی مثل GPTBot و ChatGPT-User دیده میشه که باید حسابی جدیشون بگیری.
Googlebot: همچنان پادشاه بیرقیب دنیای کراولرهاست. سهمش از ۳۰٪ در می ۲۰۲۴ به ۵۰٪ در می ۲۰۲۵ رسید؛ یعنی نیمی از تمام کراولها!
Bingbot: یه افت کوچیک داشته؛ از ۱۰٪ به ۸.۷٪. هنوز فعاله ولی دیگه اون قدرت قبلی رو نداره.
GPTBot: این یکی ستارهی نوظهوره! از ۲.۲٪ به ۷.۷٪ رسیده؛ یعنی رشد ۳۰۵ درصدی. نشون میده چقدر تولید و تحلیل محتوا با هوش مصنوعی داغ شده.
ClaudeBot: برخلاف انتظار، افت کرده. از ۱۱.۷٪ به ۵.۴٪؛ یعنی داره سهمش رو از دست میده.
Amazonbot: از ۷.۶٪ اومده پایین به ۴.۲٪. شاید چون تمرکز آمازون بیشتر روی محصولات و تحلیل داخلیه.
Bytespider: یه سقوط آزاد واقعی داشته؛ از ۲۲.۸٪ به ۲.۹٪. دلیلش هنوز مشخص نیست، ولی روندش نزولی بوده.
ChatGPT-User: رشدش خیرهکنندهست! از فقط ۰.۱٪ به ۱.۳٪ رسیده. یعنی یه رشد عجیب ۲۸۲۵ درصدی. این نشون میده که استفاده از رابطهای گفتوگویی برای جستجو داره به سرعت افزایش پیدا میکنه.
اگه تا دیروز فقط نگران این بودی که گوگلبات بیاد سراغت، حالا باید بدونی یه لشگر از کراولرهای جورواجور منتظرن که ببینن تو چی برای عرضه داری. از باتهای کلاسیک تا رباتهای هوش مصنوعیمحور، هرکدوم سهمی از فضای وب دارن و ممکنه همین حالا در حال کراول تو سایت تو باشن.
کراولرها، هرچقدر هم باهوش و پیشرفته باشن، همیشه نمیتونن راحت و بیدردسر توی سایتت گردش کنن. انگار وسط یه سفر کاری باشی، اما توی هر خیابون یه مانع یا تابلوی ورود ممنوع جلوت سبز بشه. این موانع نهتنها جلوی کراول درست محتوا رو میگیرن، بلکه ممکنه باعث شن صفحات کلیدی سایتت اصلاً وارد ایندکس نشن.
یکی از چیزایی که میتونه تجربهی کراولر رو از سایتت تلخ کنه، لینکهای شکستهست. فرض کن گوگلبات مثل یه بازرس باهوشه که داره از سایتت بازدید میکنه، ولی هر بار که میخواد وارد یه اتاق (صفحه) بشه، در قفل یا مسیر قطع شده. اینجا دقیقاً همون جاییه که بحث اعتبارسنجی لینکها یا Robust Link Validation مطرح میشه.
باید به صورت منظم لینکهای داخلی و خارجی سایتت رو اسکن کنی و هر لینکی که منقضی یا اشتباه شده رو یا اصلاح کنی یا حذف. این فقط برای سئو نیست، بلکه باعث میشه کراولرها منابعشون رو الکی روی صفحات بیارزش هدر ندن و بهجاش سراغ جاهای مهم برن.
حالا برسیم به یه چالش ظریفتر: تفسیر هوشمند لینکها (Smart Link Interpretation). همهی لینکها ارزش یکسان ندارن. بعضی از لینکها رو عمداً با nofollow میذاری تا به موتور جستجو بگی «دنبالش نرو». اما اگر این ویژگی بیشازحد یا بیمورد استفاده شه، ممکنه فرصتهای انتقال اعتبار از دست برن. کراولرها امروز دیگه فقط به کد نگاه نمیکنن، بلکه سعی میکنن بفهمن لینک تو چه زمینهایه و آیا باید اون nofollow رو واقعاً جدی بگیرن یا نه.
در کنار همهی اینها، وجود مکانیزمهای هوشمند مدیریت خطا (Advanced Error Handling Mechanisms) مثل گزارشگیری منظم، ثبت لاگهای خطای ۴۰۴، هشدارهای خودکار برای لینکهای ازکارافتاده و حتی ریدایرکتهای هوشمند، بهت کمک میکنه تا شبکهی لینکهات همیشه سالم و سرحال باقی بمونه.
وبسایتها هر روز در حال رشدن، محتوا مثل سیل داره اضافه میشه و اگه قراره کراولرها همهشو کراول کنن، نه فقط منابعشون ته میکشه، بلکه به کیفیت هم لطمه میزنن. برای همین، بازی امروز دیگه فقط سرعت و تعداد نیست؛ بحث هوشمندی و هدفگذاری دقیقه. اینجاست که استراتژیهای پیشرفته در کراول سایت وارد میشن.
ایده اصلی اینه که بهجای اینکه یه ربات بیهدف توی هر گوشهی اینترنت پرسه بزنه، منابع کراول اش رو بذاره روی صفحاتی که احتمال ارزش بالا، بهروزرسانی مداوم یا تعامل بیشتر دارن. یعنی از یه مدل کراول "خطی و کورکورانه"، بریم سمت یه الگوریتم کراول "انتخابگر و تحلیلگر".
چنین استراتژیهایی مثل هایپرکیوب، منو، مدل آماری و ترکیبی از همهی اینها به کراولرها اجازه میدن دقیقتر، سریعتر و با هزینهی کمتر به نتایج بهتری برسن. این موضوع برای موتورهای جستجو مفیده و برای مدیران سایتها هم یه هشدار و یه فرصت بزرگه. اگر سایتت ارزشمند باشه و ساختار درستی داشته باشه، زودتر دیده میشی.

تو سال ۲۰۱۱، گوگل یه مدل هوشمندانه معرفی کرد به اسم Hypercube Strategy. پشت اسم عجیبش، یه منطق خیلی ساده ولی هوشمند خوابیده بود: فرض کن یه سایت بزرگ مثل یه مکعب پیچیدهست که هر بُعدش یه ویژگی داره؛ مثل نوع محتوا، زمان انتشار، سطح محبوبیت، نوع لینکسازی و غیره. حالا گوگل میگه به جای اینکه همهی این مکعب رو کامل اسکن کنیم، بیایم فقط روی بخشهایی تمرکز کنیم که قبلاً نشون دادن ارزش بالاتری دارن.
تو این مدل، رفتار کراولرها به شکلقابل پیشبینی تنظیم میشه. یعنی اگر گوگل ببینه دستهای از صفحات سایتت همیشه باکیفیت، بهروز و مفید هستن، اون بخش رو توی اولویت میذاره برای کراول سایت مکرر. برعکس، صفحاتی که تغییر خاصی نمیکنن یا کمارزشترن، توی صف عقبتر میمونن.
بهزبان ساده، گوگل با این استراتژی میخواد منابع محدود کراولرهاش رو هوشمند خرج کنه و تمرکز رو بذاره روی جایی که بیشترین بازدهی رو داره. پس اگه بخوای وارد این مکعب جذاب بشی، باید نشون بدی بخشی از سایتت هستی که همیشه فعال، مفید و ارزشمند باقی میمونه.
سال ۲۰۱۲ گوگل یه استراتژی دیگه به بازی آورد به اسم Menu Strategy. این بار هدف سادهتر از همیشه بود: گاهی توی ساختار بعضی از سایتها، یه رویداد یا عمل همیشه به یه نتیجهی مشخص منجر میشه، فارغ از اینکه اون رویداد از کجا یا چطور شروع شده. گوگل با این نگاه تصمیم گرفت الگوریتم کراولش رو برای این سناریوها بهینه کنه.
توی این استراتژی، گوگل مثل یه منو رفتار میکنه. یعنی بهجای اینکه دنبال مسیرهای پیچیده باشه که از یه حالت خاص شروع میشن، فقط به این نگاه میکنه که خروجی نهایی چیه. وقتی مطمئنه یه اتفاق (مثلاً کلیک روی یه دکمه یا بارگذاری یه دسته صفحه خاص) همیشه به یه محتوای مشخص ختم میشه، اون حالتهای اولیه براش اهمیت خاصی ندارن و مستقیم سراغ همون خروجی میره.
این باعث میشه کراولرها وقتشون رو برای بررسی مسیرهای تکراری هدر ندن و سریعتر به محتوای نهایی برسن. توی عمل یعنی گوگل هوشمندتر و سریعتر شده؛ و برای تو یعنی بهتره مطمئن شی که خروجیهای کلیدی سایتت، همیشه دسترسپذیر و با ساختار مناسب باشن، چون گوگل خیلی مستقیمتر سراغشون میره.
این یکی از اون استراتژیهاست که گوگل باهاش نشون داد چقدر کراولرهاش دارن به سمت "هوشمند شدن" حرکت میکنن. استراتژی مبتنی بر مدل آماری (Statistical Model-Based Strategy) درست مثل یه تحلیلگر خبره رفتار میکنه؛ یعنی به جای اینکه کورکورانه همه صفحات رو کراول کنه، از آمار استفاده میکنه تا تصمیم بگیره کجا بره، چی بخونه و چه زمانی.
فرض کن گوگل داره نگاه میکنه که کدوم مسیرها تو سایت، بیشتر از بقیه احتمال دارن کاربر رو به یه محتوای جدید یا ارزشمند برسونن. مثلاً اگه ۸۰٪ کاربران از صفحه A به صفحه B میرن و اون صفحه B اغلب آپدیت میشه یا تعامل خوبی داره، کراولرها اون مسیر رو توی اولویت میذارن.
این مدل با تحلیل رفتار گذشتهی کاربران، ساختار لینکها، نرخ تعامل و حتی تغییرات قبلی سایت، الگوی احتمالی میسازه تا مشخص کنه کدوم مسیرها باارزشترن. در نتیجه، کراول سایت خیلی هدفمندتر و موثرتر انجام میشه و صفحههایی که «احتمال» موفقیتشون بیشتره، سریعتر دیده میشن.
اگر میخوای تو اولویت کراول سایت بمونی، باید ساختار سایتت رو طوری بچینی که گوگل بتونه این الگوها رو واضح ببینه: لینکسازی منطقی، صفحات پربازدید، مسیرهای قابل پیشبینی و محتوای پویا کلید کارتن.
سئو فقط داستان کلمه کلیدی و تولید محتوا نیست؛ بخش بزرگی از سئو، توی پشتصحنهی فنی اتفاق میافته؛ جایی که کراولرهای وب میان و میخوان بفهمن سایتت دقیقاً چطوری کار میکنه. اگه راه رو براشون باز نذاری، نه میتونن کراول کنن، نه ایندکس کنن و نه حتی بفهمن چی داری میگی!
استراتژیهای سئو تکنیکال مثل فانوس دریایی برای کراولرها هستن. کمکشون میکنن که صفحات مهم رو پیدا کنن، بدون سردرگمی توی ساختار سایت بچرخن و دقیقترین دادهها رو از صفحات دریافت کنن. یه کد سادهی اشتباه یا یه مسیر لینکسازی ناقص میتونه کل نقشهی راه کراولر رو بههم بریزه.
پس اگر میخوای کراولرها نه فقط وارد سایتت بشن، بلکه باهاش ارتباط مؤثر بگیرن، باید یه سری اصول مشخص رو رعایت کنی. از ساختار URL گرفته تا نقشه سایت، از تگهای متا تا سرعت لود صفحات، همه چیز باید در بهترین حالت ممکن باشه.

فرض کن یه مهمون خاص (مثلاً گوگلبات!) اومده توی خونهت و تو نمیخوای هر اتاقی رو بهش نشون بدی. یا شاید بعضی اتاقها رو داری تمیز میکنی و فعلاً نمیخوای کسی سر بزنه. توی دنیای وب، این وظیفهی ظریف بر عهدهی یه فایل کوچیکه به اسم robots.txt عه.
این فایل یه جور دفترچه راهنما برای کراولرهاست؛ میگه کجاها رو میتونن ببینن و کجاها رو باید دور بزنن. مثلاً میتونی بگی «به صفحه مدیریت سایت نیا» یا «دستهبندی خاصی رو نادیده بگیر». خیلی کاربردیه، اما باید با احتیاط باهاش برخورد کرد؛ یه اشتباه کوچیک توی دستور Disallow ممکنه باعث شه کل سایت از دید کراولر پنهون بمونه.
از اون طرف، بحث بودجهی کراول سایت (Crawl Budget) هم خیلی مهمه. موتورهای جستجو برای هر سایت یه سقف مشخص از بازدیدهای روزانه یا هفتگی در نظر میگیرن. اگه منابع کراولر صرف صفحات بیارزش یا تکراری بشه، ممکنه صفحات مهم از قلم بیفتن. اینجاست که robots.txt بهت کمک میکنه نرخ کراول رو هدایت کنی؛ یعنی کاری کنی کراولرها وقتشون رو روی صفحات درست خرج کنن، نه روی سطل زبالهی دیتای سایت.
اما یه نکتهی مهم این وسط وجود داره که خیلی از مدیران سایت بهش دقت نمیکنن: مسدود کردن گوگلبات با استفاده از noindex فقط جلوی کراول صفحه رو میگیره، نه حضور اون صفحه در نتایج جستجو رو! یعنی ممکنه یه صفحه رو توی noindex کرده باشی، ولی اگه یه لینک از جای دیگه بهش وجود داشته باشه، گوگل اون لینک رو میبینه و ممکنه خودِ URL رو توی نتایج نشون بده – بدون اینکه بتونه محتوای داخلش رو بخونه.
پس اگه واقعاً میخوای یه صفحه از نتایج گوگل حذف بشه، باید از علاوه بر تگnoindex از robots.txt استفاده کنی. یعنی اگه با robots.txt بلاکش کرده باشی، اصلاً نمیتونه بره تگ noindex رو ببینه.
این یعنی باید بین این دو ابزار تعادل برقرار کنی: robots.txt برای مدیریت مسیرها و بودجهی کراول سایت، noindex برای حذف هدفمند صفحات از ایندکس گوگل.
اگه تو سایتت چند تا صفحه داشته باشی که محتوای تقریباً یکسان دارن، از نگاه گوگل ممکنه دچار یه مشکل جدی بشی و اون مشکل چیی نیست جز محتوای تکراری. یعنی رباتها سرگردون میشن که کدوم صفحه باید توی ایندکس باشه و کدوم یکی رو نادیده بگیرن. این اتفاق نهتنها بودجهی کراول رو هدر میده، بلکه میتونه سیگنالهای رتبهبندی رو هم پخش و نامفهوم کنه.
اینجاست که مفهوم Canonicalization URL وارد میشه. یعنی تعیین اینکه بین چند URL مشابه، کدوم یکی نمایندهی اصلی اون محتواست. مثلاً اگر یه مقاله رو با آدرسهای مختلفی مثل /article, /article?ref=facebook, یا /article?page=1 نشون میدی، باید یه URL اصلی رو انتخاب کنی و به گوگل اعلام کنی که همون باید مرجع باشه.
برای این کار از تگ <link rel="canonical" href="URL اصلی"> توی بخش <head> صفحه استفاده میشه. گوگل وقتی این تگ رو ببینه، میفهمه که حتی اگه به اون صفحه سر زده، باید اعتبار رو به URL اصلی بده. این کار رو حتی میشه از طریق هدر HTTP Canonical هم انجام داد، مخصوصاً برای صفحات غیر HTML یا API.
پس اگه نمیخوای کراولرها بین چند نسخهی یک محتوا سرگردون بشن، همیشه نسخهی اصلی رو مشخص کن و بهش سیگنال درست بده. اینطوری هم بودجهی کراول سایت رو حفظ میکنی، هم رتبه ات رو از دست نمیدی.
وقتی از سایتهایی حرف میزنیم که محتوایشون به کمک جاوااسکریپت تولید میشه، قضیه برای کراولرها یه کم پیچیدهتر میشه. چرا؟ چون برخلاف HTML معمولی که سریع و راحت توسط رباتها خونده میشه، محتوای پویا (Dynamic Content) اغلب بعد از بارگذاری اولیه صفحه تولید میشه؛ یعنی دقیقاً همون لحظهای که کاربر اسکرول میکنه یا روی یه دکمه کلیک میکنه.
مشکل اینجاست که همهی کراولرها توانایی کامل پردازش جاوااسکریپت رو ندارن. حتی Googlebot هم اگرچه میتونه JS رو رندر کنه، ولی این کار زمانبرتره و ممکنه در اولویت پایینتری قرار بگیره. مخصوصاً وقتی با تکنیکهایی مثل Lazy Loading طرف باشیم که محتوا تا زمان اسکرول کاربر اصلاً ظاهر نمیشه، احتمال نادیده گرفتن اون محتوا بالا میره.
یکی از راهحلهای موقت که گوگل هم تا حدی قبولش داره، Dynamic Rendering هست. تو این روش، نسخهای از صفحه بهصورت استاتیک (بدون جاوااسکریپت) برای کراولرها نمایش داده میشه، در حالی که کاربر نسخهی کامل و تعاملی رو میبینه. این تکنیک کمک میکنه که رباتها اطلاعات لازم رو سریعتر دریافت کنن، ولی برای آیندهی بلندمدت توصیه نمیشه، چون منابع سرور رو هم مصرف میکنه و فقط یه راهحل موقت به حساب میاد.
یه نکتهی دیگه هم اینه که بعضی ابزارهای کراول مثل HTTrack یا Screaming Frog نسخههایی دارن که میتونن JS رو حدی رندر کنن یا حتی لینکهایی که از طریق فلش یا اسکریپت ساخته شدن رو دنبال کنن. اما همچنان بهترین راهحل، سادهسازی ساختار لود محتوا و استفاده از HTML برای اجزای کلیدی صفحاته.
اگر جاوااسکریپت توی سایتت نقش مهمی داره، باید مطمئن شی که موتورهای جستجو بتونن بدون دردسر به محتوای مهمت دسترسی داشته باشن؛ وگرنه انگار اصلاً اون محتوا وجود نداره.
وقتی یک کراولری مثل گوگلبات وارد صفحهات میشه، اولین چیزی که میخونه محتوای اصلی نیست؛ بلکه سراغ «متادیتا»ها و ساختار HTML صفحه میره. این اطلاعات پشتصحنه، برای کراولر مثل نقشهی گنج عمل میکنه؛ بهش میگه این صفحه دربارهی چیه، کجاها مهمتره، چی رو بخونه، چی رو دنبال کنه و چی رو ایندکس نکنه.
اگه این متادیتا درست و اصولی تنظیم شده باشه، کراولرها سریعتر، دقیقتر و با اعتماد بیشتری محتوای سایتت رو تحلیل میکنن. اما اگه این بخشها ناقص، تکراری یا بیکیفیت باشن، نهتنها کراولر گیج میشه، بلکه ممکنه کل محتوای خوبت هم به چشم نیاد.
بیایم یه نگاه دقیقتر بندازیم به اجزای کلیدی این بخش:
اولین چیزی که کراولر و کاربر هر دو میبینن، عنوان صفحهست. این عنوان باید منحصربهفرد، مرتبط با محتوا، حاوی کلمه کلیدی اصلی و ترجیحاً بین ۵۰ تا ۶۵ کاراکتر باشه.
مشکلات رایج:
از دست رفته (Missing): هیچ عنوانی وجود نداره! یعنی انگار سایت حرفی برای گفتن نداره.
تکراری (Duplicate): چند صفحه با یه عنوان. این یعنی گوگل نمیفهمه کدوم صفحه مهمتره.
طولانی (Over 65 characters): ممکنه تو نتایج جستجو نصفه نیمه و بریده شده نمایش داده بشه.
خیلی کوتاه یا عمومی: مثلاً فقط «خانه» یا «محصول». اینا هیچ کمکی به کراولر برای درک موضوع نمیکنن.
مثل خلاصه پشت جلد یه کتابه. باید جذاب، دعوتکننده، حاوی کلمه کلیدی و زیر ۱۵۶ کاراکتر باشه.
مشکلات رایج:
نداشتن (Missing): گوگل خودش یه تیکه متن تصادفی از صفحه رو میذاره.
تکراری: انگار دهتا کتاب با یه پشتجلد نوشتی!
خیلی بلند یا خیلی کوتاه: باعث میشه توی نتایج نصفه نشون داده شه یا اصلاً جذاب نباشه.
یه زمانی فکر میکردیم خیلی مهمه، اما الان گوگل، بینگ و یاهو تقریباً هیچ اهمیتی بهش نمیدن. بیشتر نقش دکور داره. پس اگه میخوای استفاده کنی، در حد نمادین باشه، نه کلید سئو!
اینها ستون فقرات محتوای صفحهن. H1 فقط یکبار باید استفاده شه و معرف عنوان اصلی صفحه باشه. H2ها برای تقسیم موضوعات فرعی کاربرد دارن.
مشکلات رایج:
عدم وجود: کراولر نمیفهمه ساختار صفحه چیه.
تکراری بودن H1: گوگل فکر میکنه چند تا صفحه یه موضوع یکسان دارن.
طولانی بودن (بیش از ۷۰ کاراکتر): ساختار صفحه رو شلخته نشون میده و فهم رو سخت میکنه.
اینجاست که به رباتها دستور میدی چی کار کنن. دستوراتی مثل:
index / noindex: آیا صفحه باید ایندکس شه یا نه؟
follow / nofollow: آیا لینکهاش دنبال شن یا نه؟
noarchive: از نسخه کششده تو نتایج استفاده نشه.
nosnippet: تو نتایج، خلاصهای از صفحه نمایش داده نشه.
استفادهی درست از اینا یعنی کنترل کامل روی دیده شدن یا نشدن صفحه.
هر چی حجم صفحه و تصاویر بالاتر باشه، بارگذاری سختتر و کراول کندتر میشه. گوگل برای صفحات سنگین، منابع کمتری میذاره.
گوگل عاشق سایتهای سریعه. هر میلیثانیه تاخیر، ممکنه یه رتبه کمتر تو نتایج باشه. سرعت پایین نه فقط تجربه کاربری رو خراب میکنه، بلکه کراول مؤثر رو هم مختل میکنه.
صفحاتی که خیلی توی عمق سایت دفن شدن (مثلاً بعد از ۵ کلیک)، احتمال کراول سایت کمتری دارن. کراولرها عاشق مسیرهای ساده و دسترسی سریعان.
اگر یه صفحه کمتر از ۳۰۰ کلمه داشته باشه، گوگل ممکنه اصلاً جدی نگیرتش. مخصوصاً برای صفحات محتوایی. کراولر دنبال صفحاتیه که واقعاً حرفی برای گفتن دارن.
Inlinks: لینکهایی که از صفحات دیگه سایتت به این صفحه داده میشن. هر چی بیشتر، ارزش اون صفحه بیشتر.
Outlinks: لینکهایی که از این صفحه به جاهای دیگه (داخل یا خارج سایت) داده میشن.
Anchor Text: متن لینکها باید توصیفی و مرتبط باشن، نه کلیشهای مثل "اینجا کلیک کنید".

دنیای سئو فقط پر از فرمولها و الگوریتمهای پیچیده نیست؛ یه بازیه بین انسان و ماشین، بین تولید محتوای باکیفیت و ساختار فنی دقیق. توی این مقاله، قدمبهقدم دیدیم که چطور کراولرهای وب دنیای اینترنت رو میگردن، صفحات رو تحلیل میکنن و تصمیم میگیرن چه چیزی ارزش دیده شدن داره.
از شناخت دقیق کراولر سایت و نقش حیاتیشون شروع کردیم، تا چرخهی کامل کراول، ایندکسگذاری و رتبهبندی. بعد رفتیم سراغ چالشها؛ مثل لینکهای شکسته، محتوای تکراری، محتوای جاوااسکریپتی یا مدیریت هوشمند robots.txt و متا تگها. با بررسی استراتژیهای پیشرفتهی کراول مثل Hypercube یا مدل آماری، فهمیدیم که دیگه زمان کراول کورکورانه گذشته؛ حالا دورهی هدفگیری و تحلیل دقیق رسیده.
در نهایت رسیدیم به جایی که همهچیز به هم گره میخوره: ساختار صفحه، متادیتا، لینکسازی و تجربه کاربری. اگه همهی اینها با هم هماهنگ باشن، نهتنها کاربران عاشق سایتت میشن، بلکه کراولرها هم از دیدن صفحههات لذت میبرن و خب، همین یعنی افزایش شانس دیده شدن تو نتایج جستجو.
درسته که گوگلبات یه رباته و هیچ احساسی نداره، اما با درک درست سازوکارش، میتونی رفتارشو تا حد زیادی "هدایت" کنی. هدف نهایی سئو اینه که محتوای تو هم برای آدمها قابل استفاده باشه، هم برای ماشینها قابل فهم. وقتی این تعادل رو پیدا کنی، سئو دیگه یه دغدغه نیست، بلکه یه فرصت فوقالعادهست.