مدلهای R1-Zero و R1 نسل اول مدلهای استدلالی شرکت DeepSeek هستند که در واقع برای رسیدن به قابلیتهای استدلالی پیشرفته، از روشهای خاصی در یادگیری ماشین استفاده کردهاند. این مدلها بهطور خاص از یادگیری تقویتی (Reinforcement Learning) در مقیاس بزرگ استفاده میکنند و بدون نیاز به تنظیم دقیق نظارتی (Supervised Fine-Tuning) در مرحله اولیه آموزش خود، عملکردی چشمگیر از خود نشان دادهاند. به عبارت دیگر، این مدلها بدون استفاده از دادههای برچسبگذاریشده، با یادگیری از طریق تعامل با محیط، به سطح قابل توجهی از استدلال رسیدهاند. مدل R1-Zero بهویژه برای اولین بار در تاریخ آموزش مدلهای زبانی، از یادگیری تقویتی خالص برای آموزش بهره برده است.
برای درک بیشتر نحوه کار این مدلها، ابتدا باید با مدلهای زبانی بزرگ (LLM) آشنا شویم. این مدلها اساساً بر پایه پیشبینی توکن بعدی (Next Token Prediction) طراحی شدهاند. در این فرآیند، مدلها تلاش میکنند تا با توجه به متن موجود، کلمه یا توکن بعدی را پیشبینی کنند. به زبان ساده، مدل با توجه به دادههای ورودی که تا آن لحظه دریافت کرده است، کلمه یا توکن بعدی را بهطور خودکار پیشبینی میکند. این روش مشابه عملکرد جستجوگرهای اینترنتی مانند گوگل است که بر اساس دادههای قبلی، کلمه بعدی را پیشبینی میکنند.
این مدلها بهطور مؤثری برای پیشبینی کلمه بعدی آموزش میبینند. در این روش، دادههای آموزشی نیاز به برچسبگذاری ندارند، زیرا مدل میتواند پیشبینی خود را با مقایسه با متن اصلی ارزیابی کند. این فرآیند یادگیری خودنظارتی (Self-Supervised Learning) نامیده میشود و به مدل اجازه میدهد بدون نیاز به دادههای برچسبگذاریشده، بهطور مؤثر از تجربههای خود یاد بگیرد. برای نمونه، اگر مدل در حال پیشبینی کلمه ۱۰۱ در یک دنباله متنی باشد، میتواند پیشبینی خود را با مقایسه با کلمه ۱۰۱ واقعی ارزیابی کند و از این طریق بهبود یابد.
اما این تنها بخشی از داستان است. اگر هدف ما تنها پیشبینی کلمه بعدی بود، مشکل خاصی پیش نمیآمد. اما زمانی که مدل برای انجام کارهای پیچیدهتر مانند پاسخ به سوالات یا حل مسائل خاص استفاده میشود، پیشبینی کلمه بعدی بهتنهایی کافی نخواهد بود. برای حل چنین مسائلی، آموزش تنظیم دقیق نظارتی (Supervised Fine-Tuning) ضروری است. در این مرحله، مدل با دادههای نظارتی آموزش داده میشود که شامل مجموعهای از سوالات و پاسخهای مناسب است تا بتواند در موقعیتهای واقعی به سوالات پاسخ دهد.
زنجیره تفکر (CoT) یکی از روشهای پیشرفتهای است که در این نوع مدلها بهکار گرفته میشود. در این تکنیک، مدل بهجای اینکه یک پاسخ فوری تولید کند، ابتدا گام به گام مسئله را تجزیه و تحلیل میکند و سپس به حل آن میپردازد. این فرآیند موجب بهبود دقت مدل در حل مسائل پیچیده میشود. استفاده از این تکنیک به مدل این امکان را میدهد که نهتنها به جواب نهایی برسد بلکه مراحل رسیدن به آن را نیز توضیح دهد. این ویژگی بهویژه در حل مسائل ریاضی و برنامهنویسی مفید است.

هرچند این روش بسیار مؤثر است، اما یکی از مشکلات آن افزایش زمان پردازش و استنباط است. به همین دلیل، محققان در تلاش هستند تا با استفاده از الگوریتمهای جستجوی پیشرفته مانند Monte Carlo Tree Search و Beam Search، زمان استنباط را کاهش دهند. این الگوریتمها با بررسی چندین مسیر ممکن، بهترین جواب را پیدا میکنند، اما هنوز نمیتوانند کاملاً زمان پردازش را به حداقل برسانند.
یادگیری تقویتی (Reinforcement Learning) بهعنوان یکی از روشهای مهم در بهبود عملکرد مدلهای زبانی، به کار میرود. در این روش، مدل از طریق تعامل با محیط و دریافت پاداش بهطور مداوم یاد میگیرد. در حقیقت، مدل با تلاش برای انجام کارهای مختلف و دریافت پاداش برای هر اقدام صحیح، به تدریج عملکرد خود را بهبود میبخشد. این فرآیند باعث میشود مدل بهطور مؤثری مشکلات پیچیدهتر را حل کند.
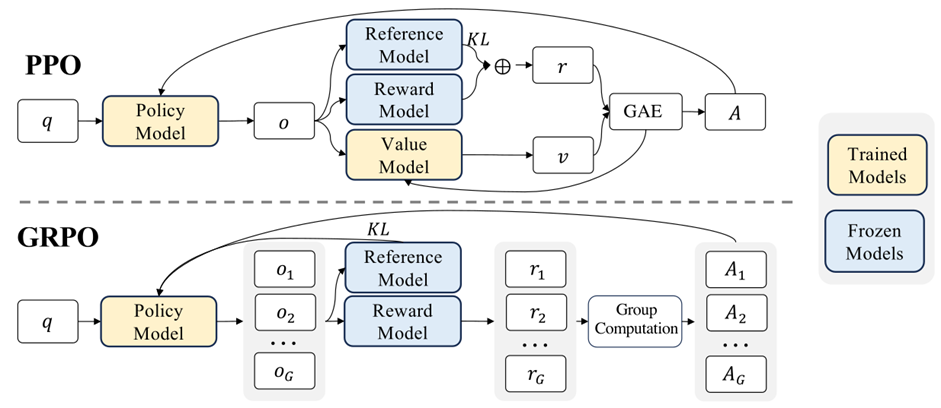
مدلهای DeepSeek مانند R1-Zero و R1 از تکنیک پیشرفتهای به نام Group Relative Policy Optimization (GRPO)استفاده میکنند. در این روش، بهجای ارزیابی مطلق پاسخها، مدلها را بهطور نسبی ارزیابی میکنند. این بدین معنی است که مدل پاسخها را با یکدیگر مقایسه کرده و به آنها امتیاز میدهد. این فرآیند موجب میشود که مدل قادر باشد از تجربیات خود استفاده کرده و پاسخهای بهتری ارائه دهد.
در روش GRPO، چندین خروجی برای هر ورودی تولید میشود و سپس این خروجیها بهطور نسبی با یکدیگر مقایسه میشوند. به این ترتیب، مدل میتواند با توجه به مقایسهها و دریافت پاداشهای نسبی، بهترین انتخاب را انجام دهد. این روش باعث بهبود چشمگیر دقت مدل در حل مسائل پیچیدهتر میشود. در این روش، مدل برای مقایسه خروجیها از پاداشهای نسبی استفاده میکند، به این معنا که بهجای ارزیابی مطلق یک پاسخ، مدلها را نسبت به یکدیگر مقایسه میکند.
در حالت کلی ما دو نوع مدل پاداش داریم:
۱. مدل rule-base که در آن پاسخ مدل با پاسخ مسئله مقایسه می شود اگر همان بود امتیاز می گیرد و اگر نبود نمی گیرد.
۲.مدل یادگیری ماشین که در آن با توجه به داده های قبلی نمره ای بین ۰ تا ۱ به خروجی مدل می دهد.
در DeepSeek از مدل rule-base استفاده شده که دو نوع دارد.
در ارزیابی دقت، پاسخ مدل با جواب صحیح مقایسه میشود. برای مثال:
.در مسائل ریاضی، عدد تولیدشده توسط مدل با پاسخ درست مسئله سنجیده میشود.
.در مسائل کدنویسی مثلاً نمونههای مشابه سوالات (LeetCode)، کد خروجی مدل ابتدا کامپایل و سپس تستهای ازپیشتعریف شده روی آن اجرا میشود تا صحت عملکردش سنجیده شود.
.ارزیابی قالب: که در آن بررسی می شود که مدل وقتی در حال تفکر است آن را درون تگ <think> و <think/> بگذارد.
یکی از ویژگیهای جالب روشGPRO ، استفاده از جریمه برای دور شدن از مدل مرجع است. در اینجا، به مدل گفته میشود که در صورتی که به نظر برسد یک پاسخ بهتر از دیگر پاسخها وجود دارد، میتواند به سمت آن حرکت کند، اما نباید بیش از حد از مدل مرجع خود دور شود. این روش به مدل کمک میکند که در فرآیند بهینهسازی، بیش از حد تغییر نکند و همچنان در چهارچوب مدل اصلی باقی بماند.
در نهایت، GRPO با استفاده از KL Divergence به مقایسه مدلهای مرجع و مدل در حال آموزش میپردازد. این مقایسه کمک میکند تا مدل در مسیر درست حرکت کند و عملکرد خود را بهبود بخشد. سپس با استفاده از backpropagation، مدل وزنهای خود را بهروزرسانی میکند تا عملکرد خود را بهبود دهد. این روش باعث میشود که مدلهای R1-Zero و R1 بتوانند با استفاده از تکنیکهای پیشرفته یادگیری، بهطور مؤثری به حل مسائل پیچیده بپردازند.
نتایج بهدستآمده از مدل R1-Zero در تستهای AIME، که شامل سوالات سطح بالای ریاضی دبیرستان است، نشاندهنده پیشرفتهای قابل توجه در حل مسائل پیچیده است. با این حال، در مراحل اولیه، مدل قادر به تولید توکنهای کوتاه و پاسخهای سریع بود، اما با گذشت زمان و افزایش طول زنجیره تفکر، توانایی مدل در حل مسائل پیچیدهتر بهبود یافت. این پیشرفتها نشاندهنده فرآیند خودتکاملی مدل هستند که به آن این امکان را میدهند که مسائل دشوارتر را حل کند.
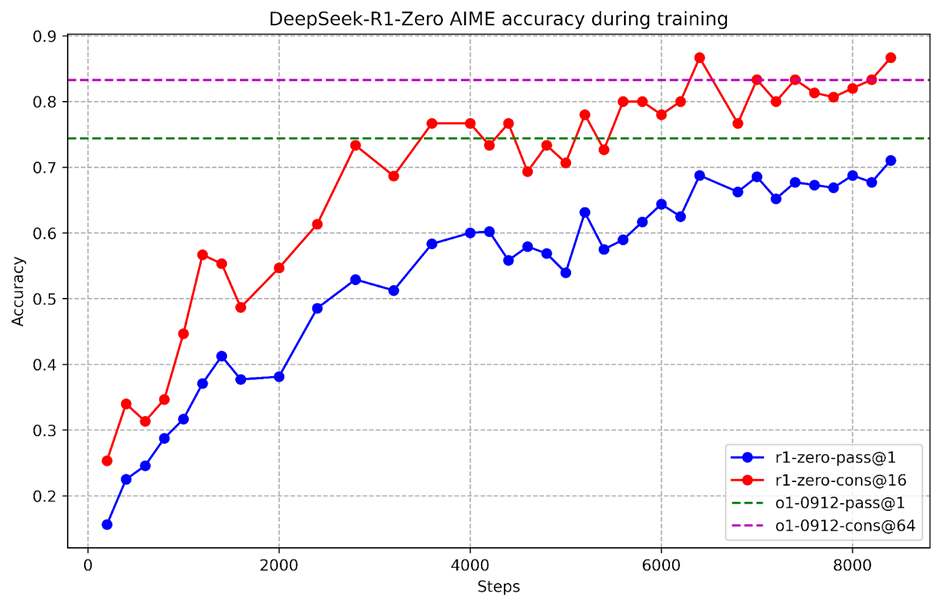
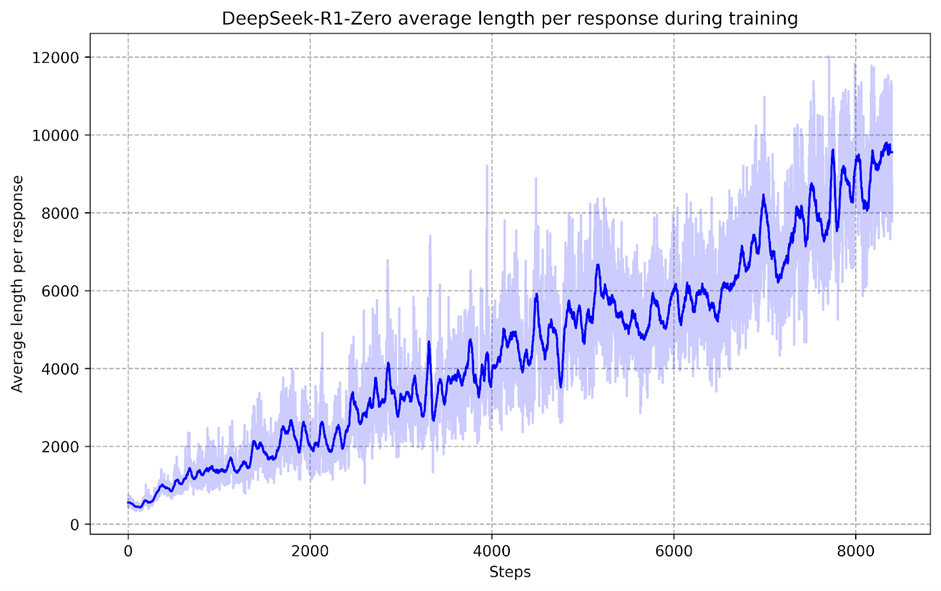
یکی از ویژگیهای منحصربهفرد این مدلها، ظهور رفتارهایی مانند بازتاب (Reflection) است. این ویژگی باعث میشود که مدل به اشتباهات خود پی ببرد و تلاش کند تا آنها را اصلاح کند. این نوع از بازتاب و اصلاح خطا مشابه لحظات “آهان” در تفکر انسانها است، که در آن فرد به اشتباه خود پی میبرد و بهطور مداوم تلاش میکند تا آن را اصلاح کند.
در نتیجه، استفاده از یادگیری تقویتی (RL)، GRPO و زنجیره تفکر (CoT) در مدلهای DeepSeek مانند R1-Zero و R1 موجب شده که این مدلها تواناییهای چشمگیری در حل مسائل پیچیده، تحلیل گام به گام و پیشبینیهای دقیق پیدا کنند. این مدلها با استفاده از روشهای نوآورانه یادگیری، عملکرد خود را بهطور مداوم بهبود میدهند و قادر به حل مسائل چالشبرانگیز هستند.
مهدی وجهی؛ مهندسی کامپیوتر۰۱
برای مطالعه کامل این نوشته، ECE_Trends را دنبال کنید.
