Chaos Engineering رویکردی در مهندسی نرمافزار است که با ایجاد عمدی و کنترلشدهی اختلال در سیستم، میزان تابآوری و توانایی آن را در مواجهه با شرایط غیرعادی ارزیابی میکند. هدف این رویکرد، شناسایی نقاط ضعف پنهان و افزایش اطمینان از پایداری سیستم در محیطهای واقعی، بهویژه در سامانههای توزیعشده و مبتنی بر ابر است. در این روش، رخدادهایی مانند قطع شبکه، افزایش تأخیر، از کار افتادن سرویسها یا کمبود منابع بهصورت کنترلشده شبیهسازی میشوند تا رفتار سیستم در شرایط بحرانی بررسی شود. اهمیت Chaos Engineering در آن است که برخلاف آزمونهای سنتی، که عمدتاً بر عملکرد صحیح سیستم در شرایط عادی تمرکز دارند، این رویکرد مقاومت سیستم را در برابر خرابیهای واقعی میسنجد و امکان شناسایی و رفع مشکلات زیرساختی و معماری را پیش از بروز بحران فراهم میکند (Gremlin, n.d.).
Backend for Frontend (BFF) یک الگوی معماری در توسعه نرمافزار است که در آن برای هر نوع رابط کاربری، یک بکاند اختصاصی طراحی میشود تا نیازهای همان کلاینت را بهصورت بهینه پاسخ دهد. در این رویکرد، بهجای آنکه همهی کلاینتها مستقیماً با یک backend عمومی در ارتباط باشند، هر frontend مانند وب، موبایل یا پنل مدیریت، از طریق یک لایهی backend مخصوص به خود با سرویسهای اصلی تعامل میکند. هدف اصلی این الگو، سادهسازی منطق سمت کاربر، کاهش حجم دادههای غیرضروری، بهبود کارایی و تطبیق بهتر پاسخها با نیازهای هر رابط کاربری است. استفاده از BFF بهویژه در سامانههایی که چندین نوع client با نیازهای متفاوت دارند، باعث افزایش انعطافپذیری، نگهداشتپذیری و استقلال تیمهای توسعه میشود (Sam Newman, n.d.).
AI4SE مخفف Artificial Intelligence for Software Engineering است و به کاربرد روشها و فناوریهای هوش مصنوعی در فرایندهای مختلف مهندسی نرمافزار اشاره دارد. در این رویکرد، از تکنیکهایی مانند یادگیری ماشین، پردازش زبان طبیعی و مدلهای مولد برای پشتیبانی یا خودکارسازی فعالیتهایی نظیر تحلیل نیازمندیها، تولید کد، تشخیص خطا، تست نرمافزار، بازبینی کد و نگهداری سیستمها استفاده میشود. هدف اصلی AI4SE افزایش بهرهوری، کاهش خطاهای انسانی، بهبود کیفیت نرمافزار و تسهیل تصمیمگیری در چرخه حیات توسعه نرمافزار است. این حوزه در سالهای اخیر، بهویژه با گسترش مدلهای زبانی بزرگ، اهمیت بیشتری یافته و به یکی از موضوعات نوظهور در پژوهش و صنعت نرمافزار تبدیل شده است.
SE4AI مخفف Software Engineering for Artificial Intelligence است و به بهکارگیری اصول، روشها و ابزارهای مهندسی نرمافزار در طراحی، توسعه، آزمون، استقرار و نگهداری سامانههای مبتنی بر هوش مصنوعی اشاره دارد. این حوزه بر این مسئله تمرکز دارد که سیستمهای هوشمند، بهویژه سامانههای مبتنی بر یادگیری ماشین، چگونه میتوانند با استفاده از شیوههای مهندسی نرمافزار بهصورت قابلاعتماد، مقیاسپذیر، قابلآزمون و قابلنگهداری توسعه یابند. اهمیت SE4AI از آنجا ناشی میشود که سامانههای هوش مصنوعی علاوه بر پیچیدگیهای رایج نرمافزار، با چالشهایی مانند وابستگی به داده، تغییر رفتار مدل، ابهام در تصمیمگیری و نیاز به پایش مستمر نیز مواجه هستند. از اینرو، SE4AI تلاش میکند با بهرهگیری از مفاهیمی مانند مدیریت چرخه عمر، تضمین کیفیت، نسخهبندی، تست و استقرار مداوم، توسعهی سامانههای AI را نظاممندتر و قابلکنترلتر سازد.
MLOps (Machine Learning Operations) مجموعهای از روشها و ابزارها برای استانداردسازی و خودکارسازی چرخهعمر مدلهای یادگیری ماشین در محیط عملیاتی است؛ بهگونهای که فرایندهای آمادهسازی داده، آموزش و ارزیابی، استقرار، پایش و بهروزرسانی مدلها قابلتکرار، قابلردیابی و قابلاعتماد باشند. هدف MLOps کاهش فاصله میان توسعه مدل و بهرهبرداری در تولید، افزایش کیفیت و پایداری سرویسهای مبتنی بر ML و مدیریت چالشهایی مانند افت عملکرد در طول زمان و تغییر توزیع دادهها (drift) است.
Infrastructure as Code (IaC) رویکردی در مهندسی زیرساخت است که در آن منابع زیرساختی (مانند شبکه، ماشینهای مجازی، کانتینرها، Load Balancerها، پایگاهدادهها و سیاستهای دسترسی) بهجای پیکربندی دستی، با کدِ قابلنسخهبندی و قابلاجرا تعریف و مدیریت میشوند. IaC امکان خودکارسازی Provisioning و Configuration، ایجاد محیطهای تکرارپذیر، کاهش خطاهای انسانی، افزایش سرعت استقرار و همراستا شدن مدیریت زیرساخت با شیوههای DevOps/CI/CD را فراهم میکند. با استفاده از IaC میتوان تغییرات زیرساخت را مانند تغییرات نرمافزار بازبینی (review)، تست و ردیابی کرد و در صورت نیاز به وضعیتهای قبلی بازگشت داد.
API Gateway و Service Mesh دو الگوی مهم در معماری سامانههای توزیعشده هستند که هرکدام نقش متفاوتی در مدیریت ارتباطات بین سرویسها ایفا میکنند. API Gateway در لبهی سیستم قرار میگیرد و بهعنوان نقطهی ورود واحد برای درخواستهای خارجی عمل میکند. این مؤلفه وظایفی مانند مسیریابی درخواستها، احراز هویت، محدودسازی نرخ درخواست، تجمیع پاسخها و مدیریت سیاستهای امنیتی را بر عهده دارد. در مقابل، Service Mesh لایهای زیرساختی برای مدیریت ارتباطات داخلی میان سرویسها است و قابلیتهایی مانند کشف سرویس، توازن بار، رمزنگاری ارتباطات، مشاهدهپذیری، کنترل ترافیک و مدیریت خطا را فراهم میکند. در نتیجه، API Gateway بیشتر بر تعامل کلاینتها با سامانه تمرکز دارد، در حالی که Service Mesh برای بهبود کنترل و پایداری ارتباطات میان میکروسرویسها در داخل سیستم به کار میرود.
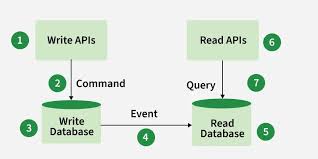
CQRS مخفف Command Query Responsibility Segregation است و یک الگوی معماری است که در آن مسئولیتهای مربوط به تغییر وضعیت سیستم (Commands) از مسئولیتهای مربوط به خواندن دادهها (Queries) جدا میشوند. در این رویکرد، عملیات نوشتن و خواندن میتوانند از مدلها، ساختار دادهها و حتی سرویسهای متفاوتی استفاده کنند تا هر بخش متناسب با نیازهای خاص خود بهینهسازی شود. هدف اصلی CQRS افزایش مقیاسپذیری، بهبود کارایی در سیستمهای پیچیده و سادهسازی مدیریت منطق کسبوکار است. این الگو بهویژه در سامانههایی مفید است که بار خواندن و نوشتن آنها متفاوت است یا نیاز به تفکیک دقیقتر مسئولیتها در معماری دارند.
همان طور که در تصویر مشاهده میکنید، بخش 1 مسئول نوشتن داده و بخش 6 مسئول خواندن داده است. برای جلوگیری از تزاحم این دو بخش در خلال کار یکدیگر، از دو نوع دیتابیس مختلف استفاده شده است که با شماره 3 و 5 نمایش داده شده اند.دستورات command که با شماره 2 نمایش داده شده است برای نوشتن استفاده میشوند و این دو دیتابیس با Event ها که با شماره 4 نمایش داده شده است باهم همگام میشوند و میتوان روی دیتابیس شماره 5 کوئری زد.
Event-Driven Architecture (EDA) یک سبک معماری نرمافزار است که در آن اجزای سیستم از طریق رویدادها با یکدیگر تعامل میکنند. در این رویکرد، هر زمان تغییری در وضعیت یک مؤلفه یا وقوع یک عمل مهم رخ دهد، یک event تولید میشود و سایر اجزا میتوانند بدون وابستگی مستقیم به تولیدکننده، به آن واکنش نشان دهند. این معماری باعث کاهش coupling بین سرویسها، افزایش مقیاسپذیری، بهبود انعطافپذیری و پشتیبانی بهتر از پردازشهای asynchronous میشود. EDA بهویژه در سامانههای توزیعشده، میکروسرویسها و سیستمهایی که نیاز به واکنش سریع به رخدادهای مختلف دارند، کاربرد گستردهای دارد.
Serverless Architecture یک رویکرد در طراحی و اجرای نرمافزار است که در آن توسعهدهندگان بدون مدیریت مستقیم سرورها، خدمات و برنامههای خود را بر بستر زیرساخت ابری اجرا میکنند. در این معماری، فراهمکنندهی سرویس ابری مسئولیتهایی مانند تخصیص منابع، مقیاسپذیری، نگهداری و مدیریت زیرساخت را بر عهده دارد و توسعهدهنده میتواند تمرکز خود را بر منطق کسبوکار و کدنویسی قرار دهد. این رویکرد باعث کاهش پیچیدگی عملیاتی، افزایش سرعت توسعه و پرداخت بر اساس میزان مصرف میشود. Serverless Architecture بهویژه برای برنامههای event-driven، APIها، پردازشهای مقطعی و بارهای کاری متغیر مناسب است.
API-first Approach رویکردی در توسعه نرمافزار است که در آن طراحی و تعریف رابطهای برنامهنویسی کاربردی (API) پیش از پیادهسازی اجزای داخلی سیستم انجام میشود. در این روش، API بهعنوان قرارداد اصلی بین بخشهای مختلف سامانه در نظر گرفته میشود و توسعهدهندگان ابتدا ساختار درخواستها، پاسخها، منابع و قوانین تعامل را مشخص میکنند. این رویکرد باعث بهبود هماهنگی میان تیمها، افزایش قابلیت استفاده مجدد، تسهیل یکپارچهسازی و کاهش وابستگی میان frontend و backend میشود. API-first بهویژه در سامانههای توزیعشده، میکروسرویسها و محصولاتی که نیاز به پشتیبانی از چندین client یا سرویس مختلف دارند، اهمیت زیادی دارد.
Domain-Driven Design یا طراحی دامنهمحور یک رویکرد برای تحلیل و طراحی نرمافزار است که میگوید هستهی طراحی باید بر اساس مسئلهی واقعی کسبوکار شکل بگیرد، نه صرفاً بر اساس ساختار دیتابیس، فناوری یا لایههای فنی. منظور از Domain همان حوزهی مسئله است؛ مثلاً در یک سامانه فروش آنلاین، مفاهیمی مانند سفارش، مشتری، پرداخت، سبد خرید و ارسال، اجزای دامنه را تشکیل میدهند. در DDD تلاش میشود نرمافزار دقیقاً با منطق و قواعد همین مفاهیم ساخته شود.
در این رویکرد، توسعهدهندگان و کارشناسان کسبوکار باید با یک زبان مشترک کار کنند که به آن Ubiquitous Language گفته میشود. یعنی اصطلاحاتی که در جلسات، مستندات، کد و طراحی استفاده میشوند باید یکسان باشند. این کار باعث میشود فاصلهی بین فهم کسبوکار و پیادهسازی فنی کمتر شود و ابهامها کاهش یابند.
DDD همچنین تأکید میکند که در سیستمهای پیچیده، نباید همهچیز را در یک مدل واحد و سراسری قرار داد. به همین دلیل مفهوم Bounded Context مطرح میشود؛ یعنی هر بخش از سیستم، مرز مفهومی و مدل مخصوص به خود را داشته باشد. برای مثال، مفهوم «مشتری» در بخش فروش ممکن است با مفهوم «مشتری» در بخش پشتیبانی یا حسابداری یکسان نباشد. DDD کمک میکند این تفاوتها بهصورت شفاف در طراحی لحاظ شوند.
بهطور کلی، هدف DDD این است که نرمافزار فقط یک پیادهسازی فنی نباشد، بلکه بازتابی دقیق از منطق دامنه و نیازهای واقعی کسبوکار باشد. این رویکرد بهویژه در سیستمهای بزرگ و پیچیده مفید است، زیرا باعث بهبود فهم مسئله، کاهش پیچیدگی، افزایش انسجام طراحی و نگهداری بهتر سیستم در طول زمان میشود.
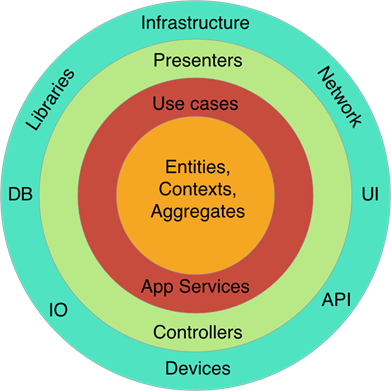
یکی از نمونه های این روش، مثالی است که آنکل باب در کتاب Clean Architecture استفاده کرده است و نشان میدهد چگونه دامنه های مختلف از هم جدا میشوند
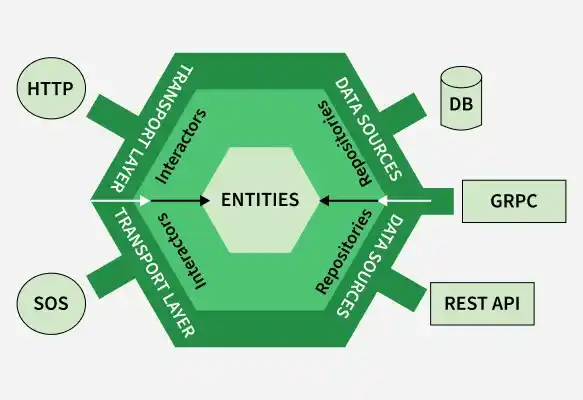
Hexagonal Architecture یا معماری ششضلعی یک الگوی معماری نرمافزار است که هدف آن جدا کردن منطق اصلی کسبوکار از وابستگیهای خارجی مانند پایگاهداده، رابط کاربری، APIها و سرویسهای بیرونی است. در این رویکرد، هستهی سیستم شامل منطق دامنه و قوانین کسبوکار است و از طریق مجموعهای از Portها با دنیای بیرون ارتباط برقرار میکند. اجزای خارجی مانند دیتابیس، پیامبر، وبسرویس یا رابط کاربری، از طریق Adapterها به این Portها متصل میشوند. این ساختار باعث میشود منطق اصلی برنامه مستقل از فناوریهای پیرامونی باقی بماند و در نتیجه، تستپذیری، نگهداشتپذیری و انعطافپذیری سیستم افزایش یابد.
در Hexagonal Architecture، هستهی برنامه نباید بداند که دادهها از کجا میآیند یا به کجا میروند؛ فقط باید بداند چه عملیاتی لازم است انجام شود. این معماری بهویژه در سیستمهایی مناسب است که نیاز به تغییر آسان در زیرساخت، جایگزینی فناوریها یا توسعهی تدریجی دارند.
Event Sourcing یک الگوی معماری برای مدیریت وضعیت در سیستمهای نرمافزاری است که در آن بهجای ذخیرهسازی آخرین وضعیتِ یک موجودیت، تمام تغییرات اعمال شده بر آن بهصورت دنبالهای از رویدادهای تغییرناپذیر (Immutable Events) در یک بانک داده مخصوص ذخیره میشود. در این رویکرد، وضعیت فعلی سیستم در هر لحظه از طریق بازپخشِ (Replay) این رویدادها بهترتیب وقوع بهدست میآید. این روش امکان داشتن تاریخچه کامل و دقیق از تمامی تراکنشها (Audit Trail)، قابلیت بازسازی وضعیت سیستم در هر نقطه زمانی گذشته و سهولت در عیبیابی و گزارشگیریهای زمانی را فراهم میکند. اگرچه Event Sourcing باعث افزایش دقت و انعطافپذیری در سیستمهای پیچیده میشود، اما پیادهسازی آن نیازمند مدیریت دقیق نسخهبندی رویدادها و استفاده از راهکارهایی مانند Snapshot برای بهینهسازی سرعت بازسازی وضعیت است. این الگو معمولاً در کنار معماریهای رویدادمحور و الگوی CQRS برای جداسازی مدلهای نوشتن و خواندن به کار میرود.
پلتفرمهای Low-code و No-code محیطهایی برای توسعه نرمافزار هستند که با استفاده از رابطهای بصری، drag-and-drop، قالبهای آماده و اجزای از پیشساخته، نیاز به برنامهنویسی دستی را کاهش میدهند یا در برخی موارد حذف میکنند.
در Low-code معمولاً هنوز مقداری کدنویسی برای سفارشیسازی، منطق پیچیده یا یکپارچهسازی لازم است؛ اما در No-code هدف این است که کاربران با کمترین یا بدون دانش برنامهنویسی بتوانند برنامهها، گردشکارها یا فرمهای دیجیتال ایجاد کنند.
این پلتفرمها با هدف افزایش سرعت توسعه، کاهش هزینه، توانمندسازی کاربران غیرمتخصص، و کوتاه کردن فاصله بین نیاز کسبوکار و پیادهسازی فنی بهکار میروند. با این حال، ممکن است در سناریوهای بسیار پیچیده از نظر سفارشیسازی، مقیاسپذیری یا کنترل فنی محدودیتهایی داشته باشند.
Business Process Management Systems (BPMS) به سامانهها یا پلتفرمهایی گفته میشود که برای مدلسازی، طراحی، اجرا، پایش و بهبود فرایندهای کسبوکار بهکار میروند. این سیستمها به سازمان کمک میکنند تا فرایندهای کاری خود را بهصورت ساختیافته، استاندارد و قابلکنترل مدیریت کند.
BPMS معمولاً امکاناتی مانند مدلسازی فرایندها، خودکارسازی گردشکارها، تخصیص وظایف، یکپارچهسازی با سایر سامانهها، پایش عملکرد، و تحلیل و بهینهسازی فرایندها را فراهم میکنند. هدف اصلی آنها افزایش کارایی، کاهش خطاهای انسانی، بهبود شفافیت، استانداردسازی عملیات، و افزایش چابکی سازمان در پاسخ به تغییرات است.
این سامانهها اغلب از نمادگذاریها و استانداردهایی مانند BPMN (Business Process Model and Notation) برای نمایش فرایندها استفاده میکنند و در حوزههایی مانند مدیریت درخواستها، فرایندهای مالی، منابع انسانی، خدمات مشتری و زنجیره تأمین کاربرد گسترده دارند.
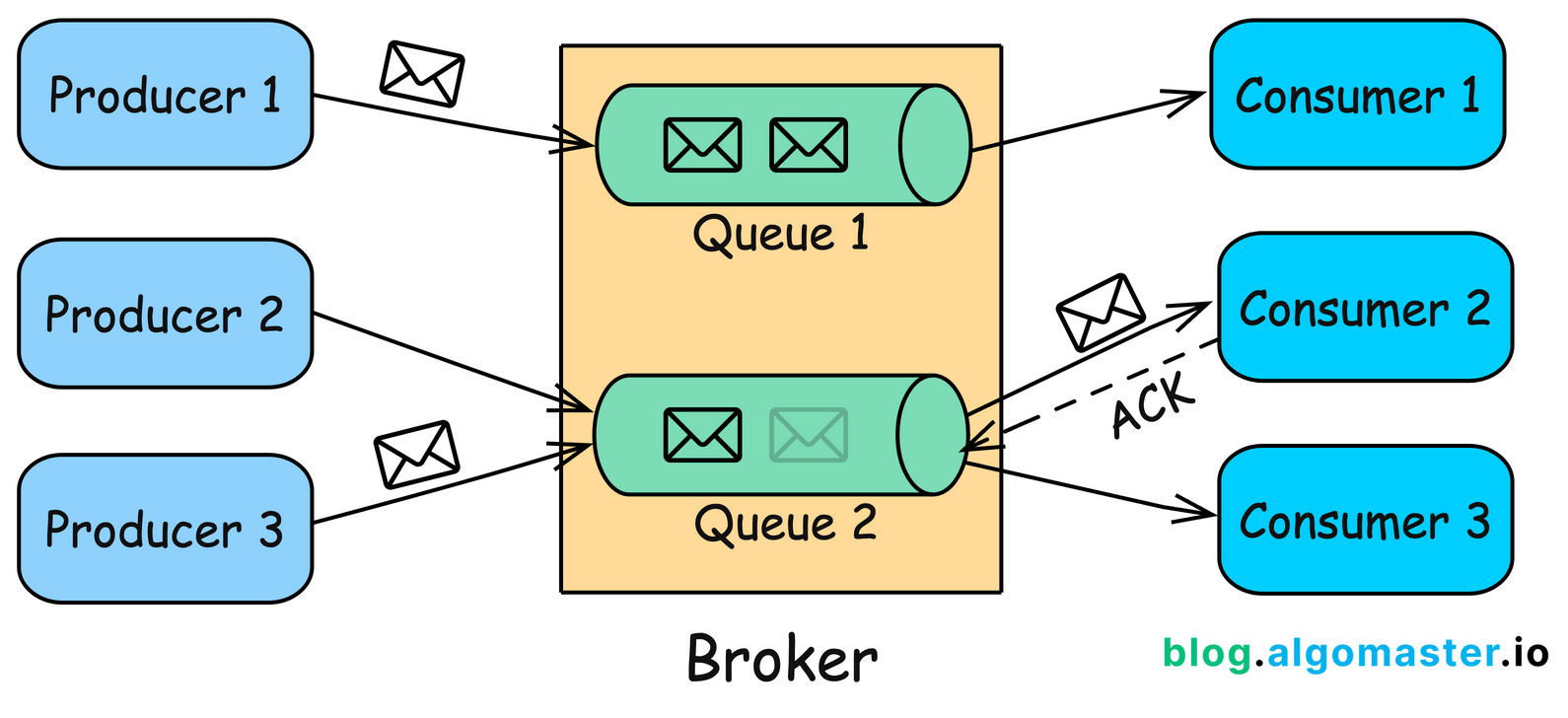
Message Queue یا صف پیام، روشی برای ارتباط غیرهمزمان بین اجزای یک سیستم است که در آن یک تولیدکننده (Producer) پیام را به یک واسط میانی (Broker) میفرستد و مصرفکنندهها (Consumers) پیامها را با سرعت و زمانبندی خودشان دریافت و پردازش میکنند. این کار باعث میشود سرویسها بهجای وابستگی مستقیم و همزمان، بهصورت جدا از هم کار کنند و در نتیجه coupling کاهش پیدا کند، مقیاسپذیری بهتر شود و سیستم در برابر نوسان بار یا قطعیهای مقطعی مقاومتر باشد. این الگو معمولاً برای پردازشهای پسزمینه مانند ارسال اعلان، پردازش سفارش، یکپارچهسازی سرویسها در معماری رویدادمحور و همچنین بافر کردن بار برای جلوگیری از overload شدن سرویسهای پاییندست استفاده میشود.
در عمل ابزارهایی مثل Kafka و RabbitMQ هر دو برای پیامرسانی و انتقال رویدادها بهکار میروند، اما تأکیدشان متفاوت است. Kafka بیشتر شبیه یک لاگ توزیعشده و پلتفرم پردازش جریانی است که پیامها را در قالب topic نگه میدارد و امکان نگهداری برای یک بازه زمانی و بازپخش (replay) رویدادها را فراهم میکند، بنابراین برای حجم بالای داده و سناریوهای streaming مناسبتر است. RabbitMQ بیشتر یک message broker کلاسیک مبتنی بر queue است که برای الگوهای صفمحور و توزیع وظایف، تحویل پیام و مسیریابی پیامها در سناریوهای عملیاتی رایجتر استفاده میشود.
Containers فناوریای برای بستهبندی و اجرای نرمافزار بههمراه وابستگیهای آن در محیطی ایزوله و قابلحمل هستند. در این رویکرد، برنامه و کتابخانهها، تنظیمات و اجزای لازم برای اجرا در قالب یک container قرار میگیرند تا همان نرمافزار بتواند در محیطهای مختلف با رفتار یکسان اجرا شود. این ویژگی باعث میشود مشکل «روی سیستم من کار میکرد» کاهش پیدا کند، فرایند استقرار سادهتر شود و استفاده از منابع نسبت به ماشینهای مجازی سبکتر و کارآمدتر باشد. Docker یکی از شناختهشدهترین ابزارها در این حوزه است که ساخت، توزیع و اجرای containerها را ساده میکند.
Container orchestration به مدیریت خودکار تعداد زیادی container در مقیاس عملیاتی اشاره دارد. وقتی یک سامانه از چندین container تشکیل شده باشد، لازم است فرایندهایی مانند استقرار، زمانبندی اجرا، مقیاسدهی، بازیابی در صورت خطا، توزیع بار، کشف سرویس و بهروزرسانی بدون اختلال بهصورت خودکار انجام شوند. Kubernetes یکی از مهمترین پلتفرمهای orchestration است که این قابلیتها را فراهم میکند و به سازمانها اجازه میدهد برنامههای containerized را بهشکل پایدار، مقیاسپذیر و قابلمدیریت اجرا کنند. در نتیجه، containerها واحد بستهبندی و اجرای نرمافزار را فراهم میکنند و orchestration مدیریت هماهنگ و خودکار این واحدها را در محیطهای واقعی بر عهده میگیرد.
Multi-Tenancy Architecture یک الگوی معماری است که در آن یک نمونه (instance) از نرمافزار یا سرویس به چندین مشتری/سازمان (tenant) بهصورت همزمان خدمت میدهد، در حالی که دادهها و تنظیمات هر tenant بهصورت منطقی از دیگران جدا نگه داشته میشود. هدف اصلی این معماری کاهش هزینه و پیچیدگی عملیاتی از طریق اشتراکگذاری زیرساخت و کد، سادهسازی نگهداری و بهروزرسانی، و فراهم کردن مقیاسپذیری برای ارائه سرویس به تعداد زیادی مشتری است؛ به همین دلیل در سامانههای SaaS بسیار رایج است.
در معماری چندمستاجری، چالشهای اصلی معمولاً حول محور جداسازی (isolation) داده و امنیت، کنترل دسترسی، مدیریت منابع و جلوگیری از اثرگذاری یک tenant روی کیفیت سرویس دیگران (noisy neighbor)، و همچنین سفارشیسازی رفتار یا پیکربندی برای tenantهای مختلف شکل میگیرد. پیادهسازی آن میتواند شکلهای متفاوتی داشته باشد؛ مثلاً جداسازی در سطح دیتابیس (پایگاهداده جدا برای هر tenant)، جداسازی در سطح schema، یا اشتراکگذاری یک دیتابیس با جداسازی منطقی رکوردها از طریق tenant_id، که هرکدام بین هزینه، سادگی، کارایی و سطح ایزولیشن trade-off دارند.
Data Migration فرایند انتقال داده از یک سامانه، قالب، یا محیط ذخیرهسازی به سامانه یا محیط دیگر است؛ برای مثال مهاجرت از یک پایگاهداده قدیمی به یک پایگاهداده جدید، انتقال داده از on‑premise به cloud، یا تغییر ساختار و مدل داده در یک سیستم. هدف آن معمولاً نوسازی زیرساخت، یکپارچهسازی سامانهها، بهبود کارایی و مقیاسپذیری، کاهش هزینه، یا پشتیبانی از نیازمندیهای جدید کسبوکار است.
مهاجرت داده معمولاً فقط «کپی کردن» نیست و شامل مراحلی مثل استخراج داده از منبع، تبدیل و پاکسازی (مثلاً نگاشت فیلدها، تغییر نوع داده، حذف ناسازگاریها یا دادههای تکراری) و سپس بارگذاری در مقصد است؛ به همین دلیل اغلب با عنوان ETL شناخته میشود. ریسکهای مهم در Data Migration شامل از دست رفتن یا خراب شدن داده، ناسازگاری معنایی بین مدلهای داده قدیم و جدید، downtime، و مشکلات کیفیت داده است؛ بنابراین معمولاً به برنامهریزی، اجرای آزمایشی، اعتبارسنجی (reconciliation) و طرح بازگشت (rollback) نیاز دارد. از نظر اجرایی نیز ممکن است مهاجرت بهصورت یکباره (big-bang) انجام شود یا بهصورت تدریجی و مرحلهای، و گاهی برای کاهش اختلال از روشهایی مثل همگامسازی دوطرفه یا اجرای موازی استفاده میشود.