تو قسمت دهم از مسیر بلاگ پستهای کوبرنتیز، میریم سراغ مفاهیم فرآیند pod to node و دقیق تر بررسی میکنیم که چجوری اسکجولر تصمیم میگیره که هر کدوم از پادهای ما رو روی کدوم نود کوبرنتیز استقرار بده.

خب یه مروری کنیم پستهای قبلی رو:
دواپس چیه و چرا لازمه؟ اینجا در مورد دواپس و ضرورت استفاده از آن صحبت کردم.
چطور اپلیکیشن مناسب کلاد آماده کنیم؟ و اینجا توضیح دادم که چطور میتونیم یه اپلیکیشن مناسب کلاد توسعه بدیم.
چه عمقی از لینوکس برای دواپس لازمه؟ و اینجا توضیح دادم که کدوم موارد لینوکس برای دواپس الزامی هست که اول سراغ اون موارد بریم.
خودکارش کن,مشکلاتت حل میشه در اینجا در مورد اتومیشن و اینکه انسیبل چیه و چه کمکی به ما میکنه صحبت کردم.
در مسیر دواپس اینبار اجزای اصلی انسیبل تو این پست اجزای انسیبل رو معرفی کردم و آنها را شرح دادم.
در مسیر دواپس به داکر رسیدیم (قسمت اول) تو این پست داکر رو شروع کردیم و اونو معرفی کردیم.
در مسیر دواپس اینبار: پشت داکر چه خبره؟ (قسمت دوم) توی این پست در مورد تکنولوژی هایی که داکر ازشون استفاده میکنه توضیح دادیم.
تست نوشتن و شروع مسیر CI/CD (قسمت اول) توی این پست انواع تست رو بررسی کردیم و با ابزارهای CI/CD آشنا شدیم و یه مقایسه بین گیتلب و جنکینز داشتیم.
در مسیر CI/CD گیت رو بررسی میکنیم (قسمت دوم) توی این پست قبل ورود به گیتلب نیاز بود که گیت و ورژن کنترل سیستم ها رو یه بررسی کنیم.
در مسیر CI/CD شناخت گیتلب (قسمت سوم) توی این پست اجزای گیتلب رو بررسی کردیم و با کامپوننتهای مختلفی که داره بیشتر آشنا شدیم.
در مسیر CI/CD پایپلاین و رانر گیتلب (قسمت چهارم) توی این پست پایپلاین و رانر گیتلب رو بررسی کردیم.
در مسیر CI/CD وریبل، گیتآپس و جمعبندی (قسمت پنجم) توی این پست وریبلهای گیتلب رو بررسی کردیم و یه معرفی کوتاه از گیتآپس و آتودواپس کردیم و در انتها یه مقدار تجربههای خودم رو در گیتلب باهاتون به اشتراک گذاشتم.
در مسیر Observability، الک (قسمت دوم) توی این پست استک قدرتمند ELK رو بررسی کردیم.
در مسیر Observability، جمع بندی استک الک (قسمت سوم) توی این پست بقیه کامپوننتهای استک الک رو بررسی کردیم و fluentd و fluentbit رو مقایسه کردیم و نهایتا یه معرفی هم روی opensearch داشتیم.
در مسیر Observability، استک پرومتئوس (قسمت چهارم) توی این پست یه معرفی اولیه داشتیم روی استک پرومتئوس.
در مسیر Observability، استک پرومتئوس (قسمت پنجم) توی این پست یه مقدار کامپوننت های استک پرومتئوس رو بیشتر بررسی کردیم.
در مسیر Observability، استک ویکتوریا (قسمت ششم) توی این پست استک ویکتوریا رو معرفی کردیم و سعی کردیم با پرومتئوس مقایسهاش کنیم.
در مسیر Observability، میمیر (قسمت هفتم) توی این پست در مورد ابزار میمیر از ابزارهای گرافانا توضیح دادیم و کاربردش رو بررسی کردیم.
در مسیر Observability، لوکی (قسمت هشتم) توی این پست در مورد ابزار گرافانا برای مدیریت لاگ یعنی لوکی توضیح دادیم و آخرشم یه معرفی کوتاه رو graylog داشتیم.
در مسیر Observability، تمپو (قسمت نهم) توی این پست در مورد تریسینگ توضیح دادیم و گرافانا تمپو رو بررسی کردیم و یه معرفی کوتاه روی Jaeger داشتیم
در مسیر Observability، گرافانا (قسمت دهم) توی این پست در مورد گرافانا و HA کردنش و همچنین یه سری از ابزارهاش مثل alloy , incident, on-call توضیح دادیم.
آغاز مسیر کوبر (قسمت اول) تو این قدم به معرفی ابزارهای ارکستریشن پرداختیم و مدارک کوبرنتیز رو بررسی کردیم.
کوبر سینگل ( قسمت دوم ) توی این قدم در مورد kubectl , kubeconfig توضیح دادیم و تعدادی ابزار رو معرفی کردیم که به کمک اونها میتونیم یک کوبرنتیز دمهدستی واسه تستهامون داشته باشیم.
کامپوننتهای کوبر ( قسمت سوم ) توی این پست کامپوننتهای مختلف کوبرنتیز رو بررسی کردیم و اجزای نودهای مستر و ورکر رو دونه دونه بررسی کردیم و توضیح دادیم.
پادها و مدیریت اونها در کوبرنتیز (قسمت چهارم) توی این پست در مورد پاد توی کوبرنتیز توضیح دادیم و موارد مربوط به اون رو بررسی کردیم.
ورکلودهای کوبر و مدیریت منابع کوبر (قسمت پنجم) توی این پست در مورد namespaceها توی کوبر توضیح دادیم و انواع ورکلود کوبر رو بررسی کردیم.
اگه لازم شد کوبر خودش گنده میشه! ( قسمت ششم ) توی این پست در مورد سه نوع ورکلود مرتبط با scaling به صورت خودکار در کوبرنتیز توضیح دادیم.
نتورک کوبر (قسمت هفتم) توی این قسمت انواع سرویس توی کوبرنتیز رو بررسی کردیم و در مورد مفاهیم اینگرس و نتورک پالیسی توضیح دادیم.
استورج کوبرنتیز (قسمت هشتم) توی این قسمت در مورد انواع استورج توی کوبرنتیز توضیح دادیم و مفاهیم PV و PVC و Storage Class رو بررسی کردیم.
پراب، ریکوئست و لیمیت (قسمت نهم) توی این قسمت موارد مربوط به محدود کردن منابع کانتینر توی کوبرنتیز رو بررسی کردیم و در مورد انواع probe ها توی کوبرنتیز توضیح دادیم.
پاد تو نود (قسمت دهم) توی این قسمت درمورد فرآیند انتقال پاد به نود مناسب مفاهیم پیشرفتهتری مثل affinity و anti-affinity و taint و toleration رو بررسی کردیم.
اولویت پاد و امنیت (قسمت یازدهم) توی این قسمت در مورد تعیین اولویت برای پادها و جنبههای مختلف امنیت در کوبرنتیز توضیح دادیم.
کنترل دسترسی به کوبر (قسمت دوازدهم) توی این قسمت در مورد مراحل دسترسی به api کوبرنتیز صحبت کردیم و بعدش مفاهیمی مثل سرویس اکانت رو توضیح دادیم.
دیزاین کلاستر (قسمت سیزدهم) توی این قسمت در مورد طراحی و دیزاین یک کلاستر و روشهای مختلفی که داره توضیح دادیم و همچنین تفاوت روشهای مختلف تقسیم منابع در کلاسترها را بررسی کردیم.
مالتی تننسی در کوبر (قسمت چهاردهم) توی این قسمت چالشهای مربوط به داشتن چند مستاجر بر روی کلاستر کوبرنتیز توضیح دادیم.
هلم (قسمت پانزدهم) توی این قسمت پکیج منیجر معروف کوبرنتیز یعنی Helm رو بررسی کردیم و در موردش ویژگیها و کاربردهاش توضیح دادیم.
سی آر دی و اُپراتور (قسمت شانزدهم) توی این قسمت در مورد اینکه چطوری یه ریسورس کاستوم شده به کلاستر اضافه کنیم توضیح دادیم و مفهوم اُپراتور رو توی کوبر بررسی کردیم.
نصب کلاستر با kubeadm (قسمت هفدهم) توی این قسمت قدم به قدم نحوه نصب یک کلاستر کوبرنتیز رو با استفاده از ابزار kubeadm توضیح دادیم.
نصب کلاستر با kubespray (قسمت هجدهم) توی این قسمت نحوه نصب کلاستر با یه پروژه خیلی خوب به نام کیوب اسپری که یه انسیبل خفن برای ستاپ کلاستر رائه میده رو توضیح دادیم.
نصب کلاستر با rancher (قسمت نوزدهم) توی این قسمت توضیح دادیم که چطور با استفاده از ابزار RKE یک کلاستر کوبرنتیز راهاندازی کنیم.
توصیه میکنم که حتما این پستها رو هم مطالعه کنید. بریم که ادامه بدیم.
قبلتر دیدیم که اسکجولر پادهایی که جدیدا درست شدن رو بررسی میکنه و برای هرپاد جدیدی که اسکجولر اونو بررسی میکنه، یک نود مناسب پیدا میکنه. در واقع اسکجولر مسئول پیدا کردن بهترین نود برای پاد هست تا روی اون نود ران بشه. اسکجولر این کار رو بر اساس قوانینی که قبلا توضیح دادیم انجام میده در ادامه یه مقدار بیشتر در مورد این فرآیند توضیح میدیم.
راههای مختلفی برای انجام این فرآیند هست اما تمام راه حل هایی که توصیه شده هستند از Label و Selector ها استفاده میکنند برای آسان کردن این فرآیند.

سادهترین و توصیهشدهترین روش برای اعمال محدودیت انتخاب نود nodeSelector است.
یک فیلد در PodSpec است که یک Map از جفتهای کلید-مقدار (key-value) را مشخص میکند.
برای اینکه یک پاد واجد شرایط اجرا روی یک نود باشد، نود باید تمام جفتهای کلید-مقداری که در nodeSelector مشخص شده است را به عنوان برچسب (Label) داشته باشد (نود میتواند برچسبهای اضافی دیگری نیز داشته باشد). رایجترین استفاده از nodeSelector شامل یک جفت کلید-مقدار است.

استفاده از nodeName سادهترین روش برای اعمال محدودیت انتخاب نود است، اما به دلیل محدودیتهایی که دارد معمولاً استفاده نمیشود. nodeName یک فیلد در PodSpec است. اگر این فیلد خالی نباشد، Scheduler پاد را نادیده میگیرد و kubelet در نود مشخصشده سعی میکند پاد را اجرا کند.
بنابراین، اگر nodeName در PodSpec مشخص شده باشد، نسبت به روشهای دیگر برای انتخاب نود اولویت دارد.
تا اینجا متوجه شدیم که اسکجولر میشینه حساب کتاب میکنه که مثلا پاد رو نفرسته جایی که منابع مورد نیازش وجود نداشته باشه و اگه یادتون باشه گفتیم که یه بار فیلترینگ انجام میده که ببینه اصلا روی کدوم نود ها میشه این پاد رو برد و بعدش فرآیند Scoring رو انجام میده که پیدا کنه حالا از بین اینهایی که میشه کدومش بهتر هستند برای این پاد. این مباحث رو تو قسمت اسکجولر توضیح دادم.
آیا اینکه cpu و ram کافی برای اون پاد روی نود باشه کافیه؟ آیا ما میتونیم با جزئیات بیشتری از اسکجولر بخوایم که مقصد پاد رو مشخص کنه؟ مثلا میشه بگیم هرجا یه پاد از backend هست یه پاد از redis هم باشه؟ یا مثلا میتونیم بگیم که تا جای ممکن پادهای فلان سرویس رو پخششون کن که کنار هم توی یک نود نباشن؟

دیدیم که nodeSelector یک روش بسیار ساده برای محدود کردن پادها به نودهایی با برچسبهای خاص فراهم میکند. ویژگی affinity/anti-affinity به طور قابل توجهی انواع محدودیتهایی که میتوانید بیان کنید را گسترش میدهد.
مفهوم affinity شامل دو نوع وابستگی است:
Node Affinity (وابستگی به نود)
Inter-Pod Affinity/Anti-Affinity (وابستگی/ضد وابستگی بین پادها)
نوع اول یعنی Node Affinity از نظر مفهومی مشابه nodeSelector است و به شما اجازه میدهد که مشخص کنید پاد شما با توجه به برچسبهای نود، روی کدام نودها واجد شرایط اجرا باشد.
در حال حاضر دو نوع Node Affinity وجود دارد:
1. RequiredDuringSchedulingIgnoredDuringExecution
این نوع به این معناست که پاد فقط در زمان اسکجولینگ باید قوانین وابستگی را رعایت کند، اما در زمان اجرا نادیده گرفته میشود. یعنی وقتی که پاد دلیور شد روی نود اگر شرط دیگه برقرار نباشه مهم نیست و تنها در زمان اسکجول شدن مهمه که شرط برقرار باشه. دقت کنید اگر اسکجولر نتونه نود مورد نظر رو برای پاد پیدا کنه پاد در حالت pending باقی میمونه تا اسکجولر بتونه نود مورد نظر برای برقراری شرط رو پیدا کنه.
2. PreferredDuringSchedulingIgnoredDuringExecution
این نوع به Scheduler پیشنهاد میدهد که قوانین وابستگی را رعایت کند، اما تضمینی برای رعایت آنها وجود ندارد. یه جورایی میگیم که بهتره که این پاد مثلا این طوری اسکجول بشه اما اگر شرایط برقرار نبود جای دیگهای هم اومد بالا مشکلی نیست. یه جورایی میگیم بهش که ترجیح میدیم که این طوری پیش بره اما اگر نشد مشکلی نیست.
بخش IgnoredDuringExecution در نام این قوانین نشان میدهد که مشابه nodeSelector، اگر در زمان اجرا برچسبهای یک نود تغییر کنند بهطوری که قوانین وابستگی دیگر رعایت نشوند، پاد همچنان به اجرای خود روی آن نود ادامه میدهد.
مثلا ممکنه پادهایی داشته باشیم که میخوایم فقط روی نودهایی از کلاستر دیپلوی بشن که اونجا gpu هم وجود داشته باشه.

در مثال بالا از required label استفاده شده بنابراین حتما پاد اگر دیپلوی بشه روی نودی که لیبل gpu=true داره، دیپلوی میشه.

در مثال بالا میبینیم که از Preferred labels استفاده شده، یعنی به نوعی ترجیح ما این هست که این پاد روی نودهایی بره که توی zone1 هستند و share اونها به صورت dedicated لیبل زده شده اما اگر به هردلیلی این اتفاق نیافتد کوبرنتیز از اینکه این پاد روی نود دیگری دیپلوی شود جلوگیری نمیکند.
سینتکس جدید Node Affinity از عملگرهای زیر پشتیبانی میکند:
In (در لیست بودن)
این عملگر بررسی میکند که آیا مقدار برچسب نود در لیستی از مقادیر مشخصشده وجود دارد یا نه.
مثال:
key: "environment" operator: "In" values: ["production", "staging"]
این تنظیم به پاد اجازه میدهد فقط روی نودهایی اجرا شود که مقدار برچسب environment برابر با production یا staging باشد.
NotIn (در لیست نبودن)
بررسی میکند که مقدار برچسب نود در لیستی از مقادیر مشخصشده نباشد.
مثال:
key: "environment" operator: "NotIn" values: ["development", "test"]
این تنظیم به پاد اجازه میدهد روی نودهایی اجرا شود که مقدار برچسب environment برابر با development یا test نباشد.
Exists (وجود داشتن)
بررسی میکند که آیا برچسب مشخصشده روی نود وجود دارد یا خیر.
مثال:
key: "region" operator: "Exists"
این تنظیم به پاد اجازه میدهد روی نودهایی اجرا شود که برچسب region داشته باشند (بدون توجه به مقدار آن).
DoesNotExist (وجود نداشتن)
بررسی میکند که آیا برچسب مشخصشده روی نود وجود ندارد.
مثال:
key: "region" operator: "DoesNotExist"
این تنظیم به پاد اجازه میدهد فقط روی نودهایی اجرا شود که برچسب region نداشته باشند.
Gt (بزرگتر بودن)
بررسی میکند که آیا مقدار برچسب نود بزرگتر از مقدار مشخصشده است یا خیر.
مثال:
key: "cpu-count" operator: "Gt" values: ["4"]
این تنظیم به پاد اجازه میدهد روی نودهایی اجرا شود که مقدار برچسب cpu-count بیشتر از 4 باشد.
Lt (کوچکتر بودن)
بررسی میکند که آیا مقدار برچسب نود کوچکتر از مقدار مشخصشده است یا خیر.
مثال:
key: "cpu-count" operator: "Lt" values: ["8"]
این تنظیم به پاد اجازه میدهد روی نودهایی اجرا شود که مقدار برچسب cpu-count کمتر از 8 باشد.
این عملگرها انعطافپذیری بالایی در تعریف وابستگیها و محدودیتهای زمانبندی پادها فراهم میکنند. یه جورایی داره بهمون کمک میکنه و دستمون رو باز میگذاره که با این لیبلها بازی کنیم تا بتونیم به خوبی چیزی که میخواهیم رو پیاده کنیم.
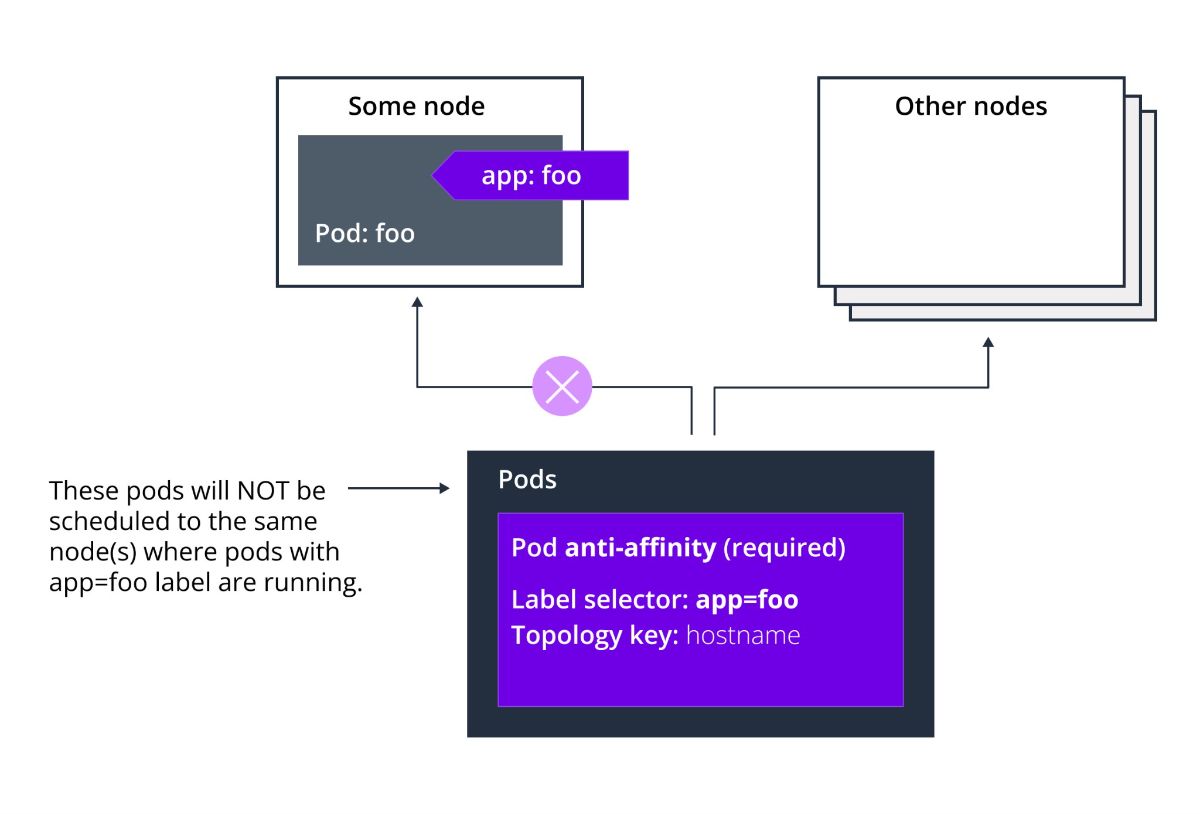
وابستگی (Affinity) و ضد وابستگی (Anti-Affinity) بین پادها به شما اجازه میدهد که مشخص کنید پادهای شما با توجه به برچسبهای پادهایی که قبلاً روی یک نود اجرا میشدند (به جای برچسبهای خود نود)، روی کدام نودها اجرا شوند.
قوانین وابستگی و ضد وابستگی بین پادها به این شکل عمل میکنند:
«این پاد باید (یا در مورد ضد وابستگی، نباید) در X اجرا شود، اگر X از قبل یک یا چند پاد را که قوانین Y را برآورده میکنند، اجرا کرده باشد.»
در اینجا:
X:
یک دامنه توپولوژی است، مانند نود، رک، Cloud Provider Zone یا Region و موارد مشابه.
Y:
قانونی است که Kubernetes سعی میکند آن را برآورده کند.
این قابلیت به شما کمک میکند زمانبندی پادها را با توجه به روابط و وابستگیهای بین آنها دقیقتر مدیریت کنید.
وابستگی (Affinity) و ضد وابستگی (Anti-Affinity) بین پادها نیازمند پردازش قابل توجهی است که میتواند زمانبندی (اسکجولینگ) را در کلاسترهای بزرگ به طور قابل توجهی آهسته کند. استفاده از این ویژگیها در کلاسترهایی با بیش از چند صد نود توصیه نمیشود. کلا توصیه اینه تا زمانی که مجبور نشدیم از این قابلیتها استفاده نکنیم چون تو کوبرنتیزمون هزینه ایجاد میکنه. اما اگر بهش نیاز داشتیم حتما ازشون استفاده میکنیم که خیلی کمک میکنه که فرآیند اسکجولینگمون هوشمندانهتر باشه.
ضد وابستگی پادها (Pod Anti-Affinity) نیازمند این است که نودها به طور مداوم برچسبگذاری شوند. به عبارت دیگر، تمام نودهای کلاستر باید دارای یک برچسب مناسب مطابق با topologyKey باشند. اگر برخی یا همه نودها فاقد برچسب topologyKey مشخصشده باشند، ممکن است رفتارهای غیرمنتظرهای رخ دهد. البته اگر از این قابلیت استفاده کنیم همچین نیازمندی خواهیم داشت.

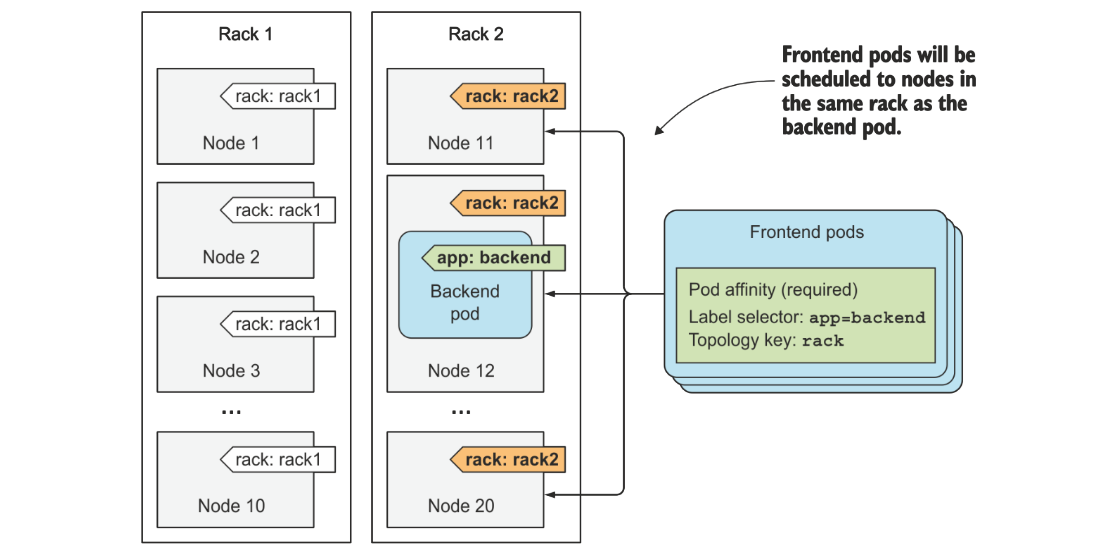
در مثال بالا میبینیم که میتونیم با استفاده از لیبلها و pod affinity کانتینرهای backend و frontend رو در کنار هم دیپلوی کنیم. یا حتی میتونیم به شکلی روی نودهای کلاستر لیبل بزنیم و با استفاده ازین مفاهیم تنظیمات رو به شکلی انجام بدیم که این کانتینرها در یک رک توی دیتاسنتر در کنار هم باشند.
مفهوم دیگه ای که در کلاستر کوبرنتیز داریم Taints و Tolerations هست که با هم کار میکنند تا اطمینان حاصل شود که پادها روی نودهای نامناسب زمانبندی نمیشوند.
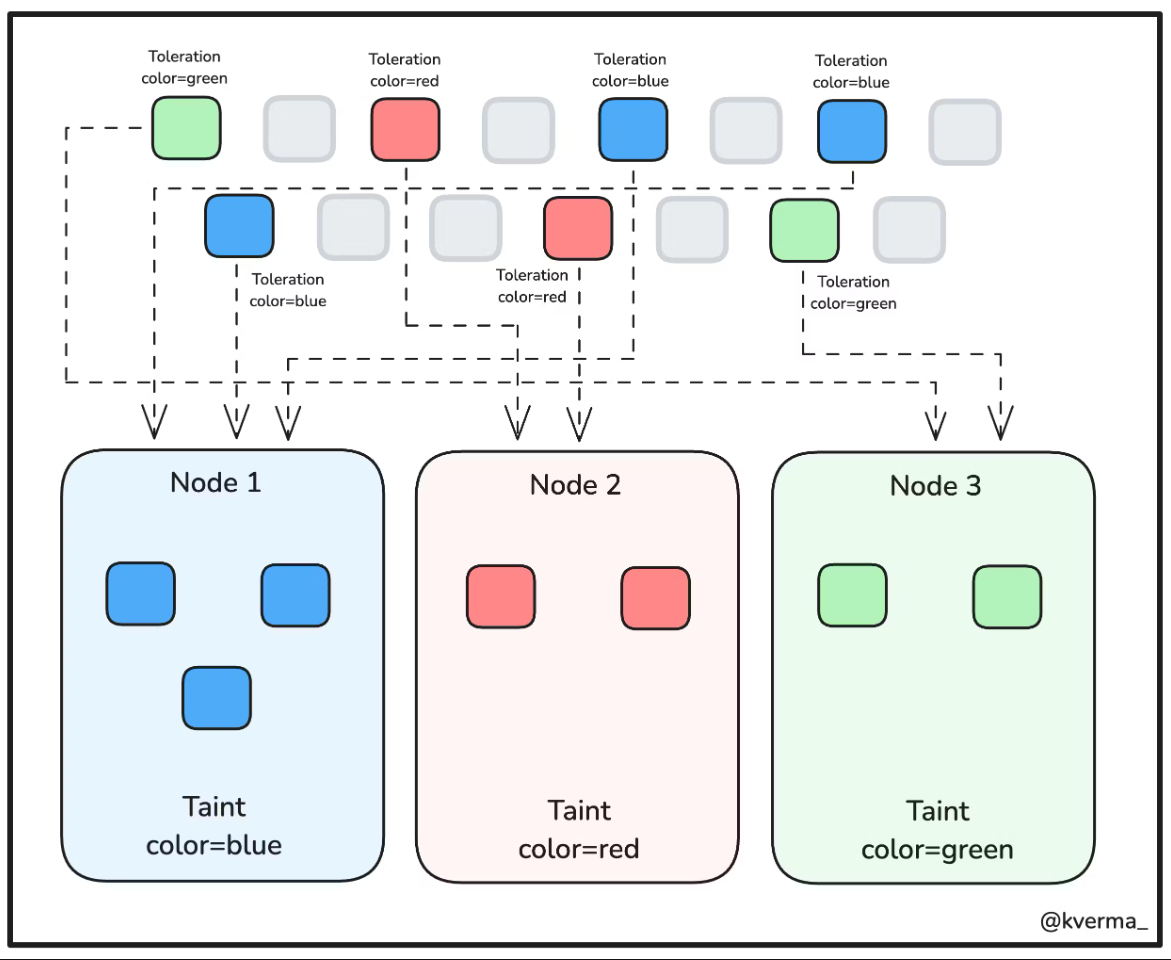
یک یا چند Taint به یک نود اعمال میشود؛ این کار نشان میدهد که نود نباید هیچ پادی را که تحمل (Toleration) آن Taint را ندارد، بپذیرد. از این قابلیت برای ارائهی نود اختصاصی استفاده میکنیم. یا به عبارتی برای اینکه مدیریت کنیم که پادهای دیگه که نباید روی نودهای ما که taint دارند قرار نگیرند.
تا الان مواردی که معرفی کردیم به این صورت بود که محدودیتها رو از سمت پاد اعمال میکردیم حالا با استفاده از taint و toleration میتونیم از سمت نودهای کلاستر این محدودیت رو اعمال کنیم، مثلا یک نود کلاستر رو با taint مربوط به دیسکهای پرسرعت و گرون قیمتتر مشخص میکنیم، اونوقت تنها پادهایی میتونن روی این نود بیان که toleration متناسب باهاش رو داشته باشند.

در ادامه برخی از کاربردها و یوز کیسهای taint و toleration رو بررسی میکنیم.
1. Dedicated Nodes (نودهای اختصاصی):
از Taints و Tolerations میتوان برای اختصاص نودهای خاص به پادهای خاص استفاده کرد.
مثال: شما میخواهید نودهای خاصی را فقط برای اجرای پادهای مربوط به یک تیم یا پروژه خاص استفاده کنید.
پیادهسازی:
نود را با یک Taint مشخص کنید:
kubectl taint nodes <node-name> dedicated=teamA:NoSchedule
پادهای تیم A باید با این Toleration تنظیم شوند:
tolerations:- key: "dedicated"operator: "Equal"value: "teamA"effect: "NoSchedule"
2. Nodes with Special Hardware (نودهای با سختافزار خاص):
برای نودهایی که سختافزار خاصی مانند GPU یا SSD دارند، از Taints و Tolerations استفاده میشود تا فقط پادهایی که به این سختافزار نیاز دارند روی این نودها اجرا شوند.
مثال: نودهایی که کارت گرافیک دارند فقط برای پادهایی که نیاز به GPU دارند در دسترس باشند.
پیادهسازی:
Taint کردن نود:
kubectl taint nodes <node-name> hardware=gpu:NoSchedule
تعریف Toleration در پاد:
tolerations: - key: "hardware" operator: "Equal" value: "gpu" effect: "NoSchedule"
3. Taint Based Evictions (خروج اضطراری بر اساس Taint):
برای مدیریت خودکار منابع و پایداری کلاستر، Taints میتوانند در صورت وقوع شرایط خاص، خروج اضطراری پادها را اعمال کنند. بنا به دلایل مختلف یا ما یا خود کوبرنتیز نیاز داریم که یه نود رو خالی کنیم و دیگه پادی داخلش نباشه یا دیگه پادی روش اسکجول نشه.
مثال: زمانی که یک نود در حال کمبود منابع است یا در حال خاموش شدن است، پادها به طور خودکار به نودهای دیگر منتقل شوند.
پیادهسازی:Kubernetes به صورت خودکار Taints خاصی مانند node.kubernetes.io/memory-pressure یا node.kubernetes.io/disk-pressure را اعمال میکند.
پادها میتوانند Toleration برای این شرایط تعریف کنند:
tolerations:- key: "node.kubernetes.io/memory-pressure"operator: "Exists"effect: "NoSchedule"
این ویژگیها انعطافپذیری و کنترل دقیقتری روی اسکجولینگ و اجرای پادها در Kubernetes فراهم میکنند.
همونطور که برای محدودیتهای از سمت پاد سطوح مختلفی رو میتونستیم تعیین کنیم مثل required و preferred برای اعمال محدودیت از سمت نود هم میتونیم effectهای مختلفی رو برای taint تعریف کنیم:
NoSchedule:
پاد بدون داشتن Toleration مطابق با Taint، روی نود مورد نظر اسکجول نمیشود.
NoExecute:
این حالت بلافاصله تمام پادهایی که Toleration مطابق با Taint ندارند را از نود خارج میکند.
PreferNoSchedule:
نسخه نرمتر NoSchedule است که در آن کنترلر تلاش میکند پاد را روی نود دارای Taint اسکجول نکند، اما این یک الزام سختگیرانه نیست.
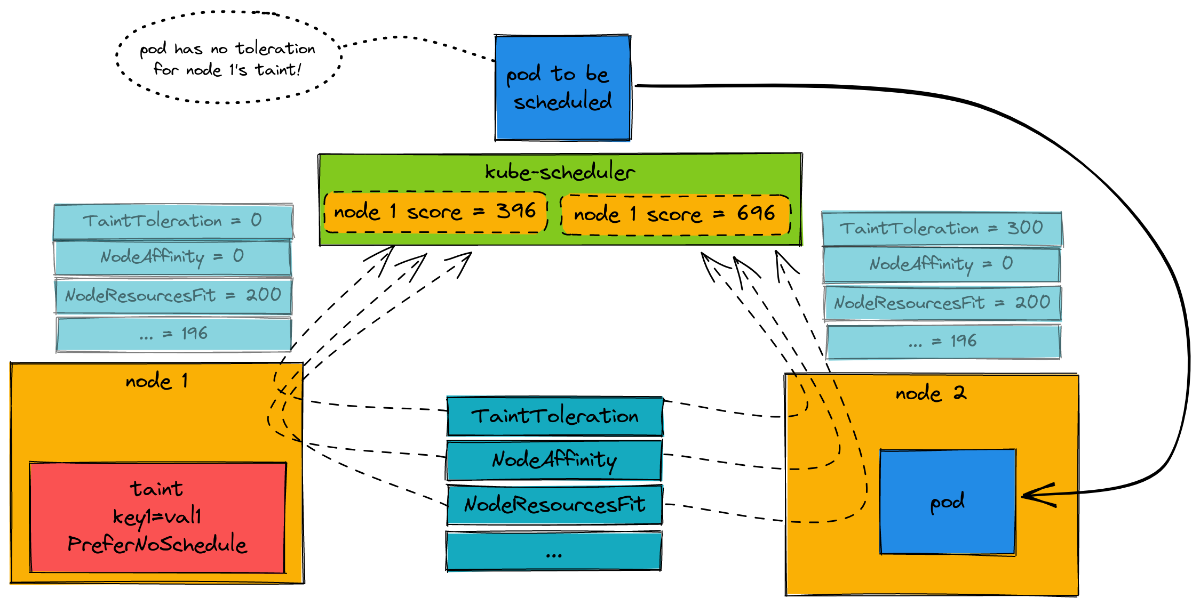
بالاتر هم بهش اشاره کردیم این موارد باعث میشه که فرآيند اسکجولینگ کوبرنتیز دشوارتر و سنگینتر بشه و اصطلاحا داریم این مسیر ور دستکاری میکنیم و بهتره که تا جایی که بهش نیاز نداریم ازشون استفاده نکنیم. هر چی سادهتر باشه فرآيند راحتتر پیش میره ولی هر زمان که بهش نیاز داشتیم میتونیم به خوبی از این قابلیتها استفاده کنیم.
در ادامه مسیر میریم سراغ ادامه مطالب کوبرنتیز و موارد مربوط به این بلاگ پست رو تکمیل میکنیم و مطالب کوبرنتیز رو ادامه میدیم.
مراقب خودتون باشید. 🌹🐳🌹

خوبه که داکرمی رو تو جاهای مختلف فالو کنید. پذیرای نظرات شما هستیم.
🫀 Follow DockerMe 🫀
🔔 Follow YouTube 🔔
📣 Follow Instagram 📣
🖇 Follow LinkedIn DockerMe🖇
🔎 Follow Linkedin Ahmad Rafiee 🔎
🕊 Follow Twitter 🕊