تو قسمت چهاردهم از مسیر بلاگ پستهای کوبرنتیز، میریم سراغ مفاهیم مالتی تننسی تا بررسی کنیم که اگر بخواهیم چند تیم یا مشتری رو روی کلاستر داشته باشیم با چه مواردی روبرو هستیم.

خب یه مروری کنیم پستهای قبلی رو:
دواپس چیه و چرا لازمه؟ اینجا در مورد دواپس و ضرورت استفاده از آن صحبت کردم.
چطور اپلیکیشن مناسب کلاد آماده کنیم؟ و اینجا توضیح دادم که چطور میتونیم یه اپلیکیشن مناسب کلاد توسعه بدیم.
چه عمقی از لینوکس برای دواپس لازمه؟ و اینجا توضیح دادم که کدوم موارد لینوکس برای دواپس الزامی هست که اول سراغ اون موارد بریم.
خودکارش کن,مشکلاتت حل میشه در اینجا در مورد اتومیشن و اینکه انسیبل چیه و چه کمکی به ما میکنه صحبت کردم.
در مسیر دواپس اینبار اجزای اصلی انسیبل تو این پست اجزای انسیبل رو معرفی کردم و آنها را شرح دادم.
در مسیر دواپس به داکر رسیدیم (قسمت اول) تو این پست داکر رو شروع کردیم و اونو معرفی کردیم.
در مسیر دواپس اینبار: پشت داکر چه خبره؟ (قسمت دوم) توی این پست در مورد تکنولوژی هایی که داکر ازشون استفاده میکنه توضیح دادیم.
تست نوشتن و شروع مسیر CI/CD (قسمت اول) توی این پست انواع تست رو بررسی کردیم و با ابزارهای CI/CD آشنا شدیم و یه مقایسه بین گیتلب و جنکینز داشتیم.
در مسیر CI/CD گیت رو بررسی میکنیم (قسمت دوم) توی این پست قبل ورود به گیتلب نیاز بود که گیت و ورژن کنترل سیستم ها رو یه بررسی کنیم.
در مسیر CI/CD شناخت گیتلب (قسمت سوم) توی این پست اجزای گیتلب رو بررسی کردیم و با کامپوننتهای مختلفی که داره بیشتر آشنا شدیم.
در مسیر CI/CD پایپلاین و رانر گیتلب (قسمت چهارم) توی این پست پایپلاین و رانر گیتلب رو بررسی کردیم.
در مسیر CI/CD وریبل، گیتآپس و جمعبندی (قسمت پنجم) توی این پست وریبلهای گیتلب رو بررسی کردیم و یه معرفی کوتاه از گیتآپس و آتودواپس کردیم و در انتها یه مقدار تجربههای خودم رو در گیتلب باهاتون به اشتراک گذاشتم.
در مسیر Observability، الک (قسمت دوم) توی این پست استک قدرتمند ELK رو بررسی کردیم.
در مسیر Observability، جمع بندی استک الک (قسمت سوم) توی این پست بقیه کامپوننتهای استک الک رو بررسی کردیم و fluentd و fluentbit رو مقایسه کردیم و نهایتا یه معرفی هم روی opensearch داشتیم.
در مسیر Observability، استک پرومتئوس (قسمت چهارم) توی این پست یه معرفی اولیه داشتیم روی استک پرومتئوس.
در مسیر Observability، استک پرومتئوس (قسمت پنجم) توی این پست یه مقدار کامپوننت های استک پرومتئوس رو بیشتر بررسی کردیم.
در مسیر Observability، استک ویکتوریا (قسمت ششم) توی این پست استک ویکتوریا رو معرفی کردیم و سعی کردیم با پرومتئوس مقایسهاش کنیم.
در مسیر Observability، میمیر (قسمت هفتم) توی این پست در مورد ابزار میمیر از ابزارهای گرافانا توضیح دادیم و کاربردش رو بررسی کردیم.
در مسیر Observability، لوکی (قسمت هشتم) توی این پست در مورد ابزار گرافانا برای مدیریت لاگ یعنی لوکی توضیح دادیم و آخرشم یه معرفی کوتاه رو graylog داشتیم.
در مسیر Observability، تمپو (قسمت نهم) توی این پست در مورد تریسینگ توضیح دادیم و گرافانا تمپو رو بررسی کردیم و یه معرفی کوتاه روی Jaeger داشتیم
در مسیر Observability، گرافانا (قسمت دهم) توی این پست در مورد گرافانا و HA کردنش و همچنین یه سری از ابزارهاش مثل alloy , incident, on-call توضیح دادیم.
آغاز مسیر کوبر (قسمت اول) تو این قدم به معرفی ابزارهای ارکستریشن پرداختیم و مدارک کوبرنتیز رو بررسی کردیم.
کوبر سینگل ( قسمت دوم ) توی این قدم در مورد kubectl , kubeconfig توضیح دادیم و تعدادی ابزار رو معرفی کردیم که به کمک اونها میتونیم یک کوبرنتیز دمهدستی واسه تستهامون داشته باشیم.
کامپوننتهای کوبر ( قسمت سوم ) توی این پست کامپوننتهای مختلف کوبرنتیز رو بررسی کردیم و اجزای نودهای مستر و ورکر رو دونه دونه بررسی کردیم و توضیح دادیم.
پادها و مدیریت اونها در کوبرنتیز (قسمت چهارم) توی این پست در مورد پاد توی کوبرنتیز توضیح دادیم و موارد مربوط به اون رو بررسی کردیم.
ورکلودهای کوبر و مدیریت منابع کوبر (قسمت پنجم) توی این پست در مورد namespaceها توی کوبر توضیح دادیم و انواع ورکلود کوبر رو بررسی کردیم.
اگه لازم شد کوبر خودش گنده میشه! ( قسمت ششم ) توی این پست در مورد سه نوع ورکلود مرتبط با scaling به صورت خودکار در کوبرنتیز توضیح دادیم.
نتورک کوبر (قسمت هفتم) توی این قسمت انواع سرویس توی کوبرنتیز رو بررسی کردیم و در مورد مفاهیم اینگرس و نتورک پالیسی توضیح دادیم.
استورج کوبرنتیز (قسمت هشتم) توی این قسمت در مورد انواع استورج توی کوبرنتیز توضیح دادیم و مفاهیم PV و PVC و Storage Class رو بررسی کردیم.
پراب، ریکوئست و لیمیت (قسمت نهم) توی این قسمت موارد مربوط به محدود کردن منابع کانتینر توی کوبرنتیز رو بررسی کردیم و در مورد انواع probe ها توی کوبرنتیز توضیح دادیم.
پاد تو نود (قسمت دهم) توی این قسمت درمورد فرآیند انتقال پاد به نود مناسب مفاهیم پیشرفتهتری مثل affinity و anti-affinity و taint و toleration رو بررسی کردیم.
اولویت پاد و امنیت (قسمت یازدهم) توی این قسمت در مورد تعیین اولویت برای پادها و جنبههای مختلف امنیت در کوبرنتیز توضیح دادیم.
کنترل دسترسی به کوبر (قسمت دوازدهم) توی این قسمت در مورد مراحل دسترسی به api کوبرنتیز صحبت کردیم و بعدش مفاهیمی مثل سرویس اکانت رو توضیح دادیم.
دیزاین کلاستر (قسمت سیزدهم) توی این قسمت در مورد طراحی و دیزاین یک کلاستر و روشهای مختلفی که داره توضیح دادیم و همچنین تفاوت روشهای مختلف تقسیم منابع در کلاسترها را بررسی کردیم.
مالتی تننسی در کوبر (قسمت چهاردهم) توی این قسمت چالشهای مربوط به داشتن چند مستاجر بر روی کلاستر کوبرنتیز توضیح دادیم.
هلم (قسمت پانزدهم) توی این قسمت پکیج منیجر معروف کوبرنتیز یعنی Helm رو بررسی کردیم و در موردش ویژگیها و کاربردهاش توضیح دادیم.
سی آر دی و اُپراتور (قسمت شانزدهم) توی این قسمت در مورد اینکه چطوری یه ریسورس کاستوم شده به کلاستر اضافه کنیم توضیح دادیم و مفهوم اُپراتور رو توی کوبر بررسی کردیم.
نصب کلاستر با kubeadm (قسمت هفدهم) توی این قسمت قدم به قدم نحوه نصب یک کلاستر کوبرنتیز رو با استفاده از ابزار kubeadm توضیح دادیم.
نصب کلاستر با kubespray (قسمت هجدهم) توی این قسمت نحوه نصب کلاستر با یه پروژه خیلی خوب به نام کیوب اسپری که یه انسیبل خفن برای ستاپ کلاستر رائه میده رو توضیح دادیم.
نصب کلاستر با rancher (قسمت نوزدهم) توی این قسمت توضیح دادیم که چطور با استفاده از ابزار RKE یک کلاستر کوبرنتیز راهاندازی کنیم.
توصیه میکنم که حتما این پستها رو هم مطالعه کنید. بریم که ادامه بدیم.
در دنیای مدیریت کانتینرها، یکی از رویکردهای مهم و رایج، به اشتراکگذاری کلاستر کوبرنتیز بین چندین تیم یا چندین مشتری است. این رویکرد که تحت عنوان چند-مستاجری (Multi-Tenancy) شناخته میشود، مزایایی همچون صرفهجویی در هزینهها، سادهسازی مدیریت و بهرهبرداری بهتر از منابع را به همراه دارد. با این حال، چند-مستاجری چالشهایی نیز به همراه دارد؛ از جمله مسائل امنیتی، تضمین عدالت در توزیع منابع و مدیریت مشکلات ناشی از Noisy Neighbors و ... .

چندین تیم (Multiple Teams):
در این حالت، یک سازمان میتواند چندین تیم را بر روی یک کلاستر مشترک مستقر کند. هر تیم یک یا چند ورکلود دارد و ممکن است نیاز به برقراری ارتباط با یکدیگر و حتی کلاسترهای دیگر داشته باشند.
اعضای تیمها غالباً از طریق ابزارهایی مانند kubectl یا سیستمهای GitOps به منابع کوبرنتیز دسترسی دارند. اینجا اعتماد نسبی بین تیمها وجود دارد، اما همچنان باید از سیاستهای کوبرنتیز همچونRBAC ، Quotas و Network Policies برای اطمینان از امنیت، مدیریت منصفانه و جداسازی نسبی استفاده شود.
چندین مشتری (Multiple Customers):
نوع دیگر مالتی تننسی زمانی است که یک ارائهدهندهی سرویس SaaS چندین نمونه از سرویس خود را برای مشتریان مختلف بر روی یک کلاستر اجرا کند. در این حالت، مشتریان دسترسی مستقیمی به کلاستر ندارند و کوبرنتیز عملاً از دید آنها پنهان است. هدف اصلی اینجا معمولاً بهینهسازی هزینهها و تامین ایزولهسازی قوی بین ورکلودهای مشتریان مختلف است.

مالتی تننسی در کوبرنتیز را میتوان به روشهای مختلفی پیادهسازی کرد و هر روش نیز مصالحههایی در سطح امنیت، پیچیدگی، هزینه و میزان جداسازی ایجاد میکند. در ادامه به برخی از ابزارها و الگوهای رایج در این زمینه میپردازیم:
کنترل دسترسی مبتنی بر نقش (RBAC):
RBAC روشی استاندارد برای کنترل سطوح دسترسی در کوبرنتیز است. با استفاده از Roles و RoleBindings (در سطح Namespace) میتوانید تعیین کنید که کدام کاربر یا سرویساکانت به چه منابعی دسترسی دارد. در محیط چند-تیمی، RBAC ابزاری کلیدی برای محدود کردن دسترسی تیمها به فضای نام (Namespace) مختص خود و جلوگیری از دخالت در منابع کلاستر سطح بالا (Cluster-Level) توسط کاربران غیرمجاز است.
سهمیهها (Resource Quotas):
کوبرنتیز این امکان را میدهد که استفاده از منابعی همچون CPU، حافظه، یا حتی تعداد آبجکتها (مثلاً تعداد Pod یا ConfigMap) را در هر Namespace محدود کنید. این قابلیت در محیطهای چند-تیمی که هر تیم به API کوبرنتیز دسترسی دارد، اطمینان میدهد که یک تیم نتواند با ایجاد تعداد زیادی منبع، منابع کلاستر را اشغال کند و برای دیگران مشکل ایجاد نماید. سهمیهها ابزاری مهم برای تضمین عدالت و جلوگیری از بروز مشکل «همسایه پرسروصدا» هستند. البته باید توجه داشت که سهمیهها (Quotas) همه چیز را کنترل نمیکنند؛ برای مثال، روی ترافیک شبکه اثر مستقیم ندارند.
جداسازی شبکه (Network Policies):
با استفاده از Network Policy، میتوان ارتباط بین پادها را کنترل و محدود کرد. در محیطهای مالتی تننسی حساس، میتوانید یک سیاست پیشفرض تعریف کنید که ارتباط بین پادها را مسدود نماید، و صرفاً ارتباط با سرویس DNS یا جریانهای ارتباطی مجاز شده را فعال کنید. بدین ترتیب امنیت و جداسازی به مراتب افزایش خواهد یافت. به صورت پیش فرض تمام پادها داخل کلاستر کوبرنتیز به یکدیگر از طریق شبکه دسترسی دارند.
جداسازی ذخیرهسازی (Storage Isolation):
ذخیرهسازی در کوبرنتیز با استفاده از PersistentVolume و PersistentVolumeClaim مدیریت میشود. با تعریف StorageClassهای متفاوت برای هر مستاجر، میتوانید به هر تیم یا مشتری فضای ذخیرهسازی ویژهای اختصاص دهید. اگر از یک StorageClass مشترک استفاده میکنید، توصیه میشود از سیاست Reclaim با مقدار Delete استفاده کنید تا پس از آزاد شدن منابع، دوباره در اختیار مستاجر دیگری قرار نگیرد و از خطرات امنیتی احتمالی جلوگیری شود.
جداسازی در سطح نود (Node Isolation):
با اختصاص دادن مجموعهای از نودها به یک مستاجر خاص، میتوان از مخلوط شدن پادهای مستاجران مختلف بر روی یک نود جلوگیری کرد. این کار ریسک حملات احتمالی و مشکلات Noisy Neighbors را کاهش میدهد. حتی اگر مهاجمی به یک نود نفوذ کند، تنها به پادها و حجمهای ذخیرهسازی همان مستاجر دسترسی خواهد داشت.
چند-مستاجری در کوبرنتیز روشی قدرتمند برای بهینهسازی هزینهها و بهرهبرداری مؤثر از منابع مشترک است. با این حال، نیازمند برنامهریزی دقیق، انتخاب مناسب ابزارهای نظارتی و امنیتی، و پیادهسازی سیاستهای کنترلی است. از RBAC و سهمیهها گرفته تا Network Policy و Node Isolation، هر کدام بخشی از پازل مالتی تننسی در کوبرنتیز را کامل میکنند. با استفادهی هوشمندانه از این ابزارها و الگوها، میتوان به یک کلاستر اشتراکی امن، پایدار و عادلانه دست یافت که نیازهای چندین تیم یا چندین مشتری را به خوبی برآورده کند.

داشتن چندین تیم یا مشتری که یک کلاستر Kubernetes را بهطور مشترک استفاده میکنند از منظر هزینه منطقی به نظر میرسد، اما این کار برامون سربارهایی رو داره که باید بررسی کنیم که مثلا بهتره که چنتا کلاستر جداگانه بالا بیاریم یا روی یک کلاستر جداسازی و ایزولهسازی انجام بدیم.
مطالبی که در ادامه توضیح میدهیم از این مقاله گرفته شده و سعی کردیم آزمایشهایی که انجام دادند رو اینجا توضیح بدیم.

بیشتر تیمها کلاستر خود را بر اساس محیطها (environment) پارتیشنبندی میکنند.
برای مثال، ده تیم ممکن است هر کدام سه محیط (مثلاً dev ،test و prod) داشته باشند.
اگر کلاستر را بر مبنای تیم و محیط تقسیمبندی کنید، در مجموع 30 بخش (slice) متمایز خواهید داشت.
حالا اگر بخواهیم مقیاس را به 50 تیم گسترش دهیم چه میشود؟ در این صورت، 150 بخش به دست میآید (50 تیم × 3 محیط = 150).
اما پیامدهای این تصمیم چیست؟
تصور کنید میخواهید برای مدیریت ترافیک ورودی، یک Ingress Controller مستقر کنید.

دو انتخاب اصلی دارید:
یک Ingress Controller واحد برای تمام مستأجران.
یک Ingress Controller اختصاصی برای هر مستأجر.
یک Ingress Controller واحد در مقابل Ingress Controllerهای اختصاصی
فرض کنید میخواهید از nginx-ingress controller استفاده کنید و request پیشفرض آن 100 میلیهسته (millicore) CPU و 90 مگابایت حافظه است.
اگر تصمیم بگیرید برای هر مستأجر یک Ingress Controller اختصاصی مستقر کنید، برای 50 مستأجر به صورت زیر خواهد بود:
CPU: 50 × 100 millicore = 5 vCPU
Memory: 50 × 90MB = 4.5GB
نزدیکترین نمونهی EC2 که با این مشخصات همخوانی دارد یک c6i.2xlarge با قیمت حدود 250 دلار در ماه است. اگر با اشتراک گذاشتن یک Ingress Controller بین 50 مستأجر مشکلی ندارید، هزینهها تنها کسر کوچکی از این مقدار خواهد بود، چرا که فقط بابت 100 میلیهسته و 90MB حافظه میپردازید.
اما آیا این واقعبینانه نیست زیرا ترافیک ورودی 50 مستأجر احتمالاً بیش از یک Ingress Controller واحد نیاز دارد و به طور متوسط ممکن است از مقدار 100mi و 90MB بیشتر مصرف کند. علاوه بر این، در سناریویی که چیزی خراب شود یا نیاز به ارتقا داشته باشد، همهی مستأجران تحت تأثیر قرار میگیرند.
از آنجا که Kubernetes برای soft multi-tenancy طراحی شده، ارزش دارد که پیکربندیهای مختلف چندمستأجری را از نرم تا سخت بررسی کنیم.
هزینهها را برای سه پیکربندی با سطوح جداسازی افزایشی مقایسه کردند که در ادامه نتایج را بررسی میکنیم:
Hierarchical Namespace controller for soft multi-tenancy.
vCluster for isolating control planes.
Karmada for managing a cluster per tenant (hard multi-tenancy).
بیایید با Hierarchical Namespace Controller شروع کنیم.
یک مؤلفه است که در کلاستز نصب میکنید و به شما اجازه میدهد Namespaceها را تو در تو (nested) ایجاد کنید.

ایدهی هوشمندانه پشت آن این است که همه Namespaceهای فرزند، منابع را از والد به ارث میبرند و این تو در تو بودن میتواند بینهایت ادامه یابد.
به این ترتیب، اگر یک Role در Namespace والد ایجاد کنید، همان منبع در فرزندان هم در دسترس خواهد بود. در پشت صحنه، کنترلر تفاوت بین دو Namespace را محاسبه کرده و منابع را کپی میکند.
بیایید یک مثال ببینیم.
بعد از نصب کنترلر، میتوانید یک Namespace ریشه به شکل زیر ایجاد کنید:
$ kubectl create ns parent
حالا میتوانید یک نقش (Role) در Namespace والد با دستور زیر ایجاد کنید:
$ kubectl -n parent create role test1 --verb=* --resource=pod
حالا یک اسکریپت برای ایجاد 50 Namespace فرزند بنویسید:
#!/bin/bash for i in {1..50} do kubectl hns create "tenant-$i" -n parent done
اگر لیست Roleها را در هر یک از Namespaceهای فرزند بررسی کنید، میبینید که Role به آنها منتقل شده است:
$ kubectl get roles -n tenant-1 NAME CREATED AT test1 2024-02-29T20:16:05Z
همچنین میتوانید رابطه بین Namespaceها و ساختار درختی آنها را ببینید:
$ kubectl hns tree parent parent ├── [s] tenant-1 ├── [s] tenant-10 ├── [s] tenant-11 ├── [s] tenant-12 ├── [s] tenant-13 ├── [s] tenant-14 ├── [s] tenant-15 ├── [s] tenant-16 # truncated output
اما Namespaceهای تو در تو چگونه پیادهسازی شدهاند؟
نیماسپیسهای فرزند در واقع همان Namespaceهای معمولی Kubernetes هستند. میتوانید با دستور زیر آنها را فهرست کنید:
$ kubectl get namespaces NAME STATUS default Active hnc-system Active kube-node-lease Active kube-public Active kube-system Active parent Active tenant-1 Active tenant-10 Active tenant-11 Active tenant-12 Active tenant-13 Active #...
ارتباطات آنها در Hierarchical Namespace Controller ذخیره شده و این کنترلر مسئول انتشار (propagate) منابع از والد به فرزند است.
هزینه اجرای چنین اپراتوری پایین است: درخواست کنونی برای حافظه و CPU حدود 300MB حافظه و 100 میلیهسته CPU است. اما این روش محدودیتهایی دارد. در Kubernetes، منابعی مانند Pod و Deployment در سطح Namespace اعمال میشوند. اما بعضی منابع در سطح کل کلاستر global هستند، مانند ClusterRole ، ClusterRoleBinding ، Namespaceها ، PersistentVolumeها، CustomResourceDefinitionها (CRD) و غیره. اگر مستأجران بتوانند Persistent Volume مدیریت کنند، همهی PVهای کلاستر را خواهند دید، نه فقط PVهای خودشان.
این منابع گلوبال در کنترل پلین ذخیره میشوند. پس اگر بخواهیم برای هر مستأجر یک کنترل پلین مجزا داشته باشیم چه؟
شما میتوانید به هر مستأجر یک کلاستر اختصاص دهید یا از یک روش سبکتر استفاده کنید: اجرای یک کنترل پلین به صورت یک پاد در کلاستر میزبان.
مستأجران مستقیماً به این کنترل پلین (که در قالب پاد است) وصل شده و منابع خود را در آن ایجاد میکنند.
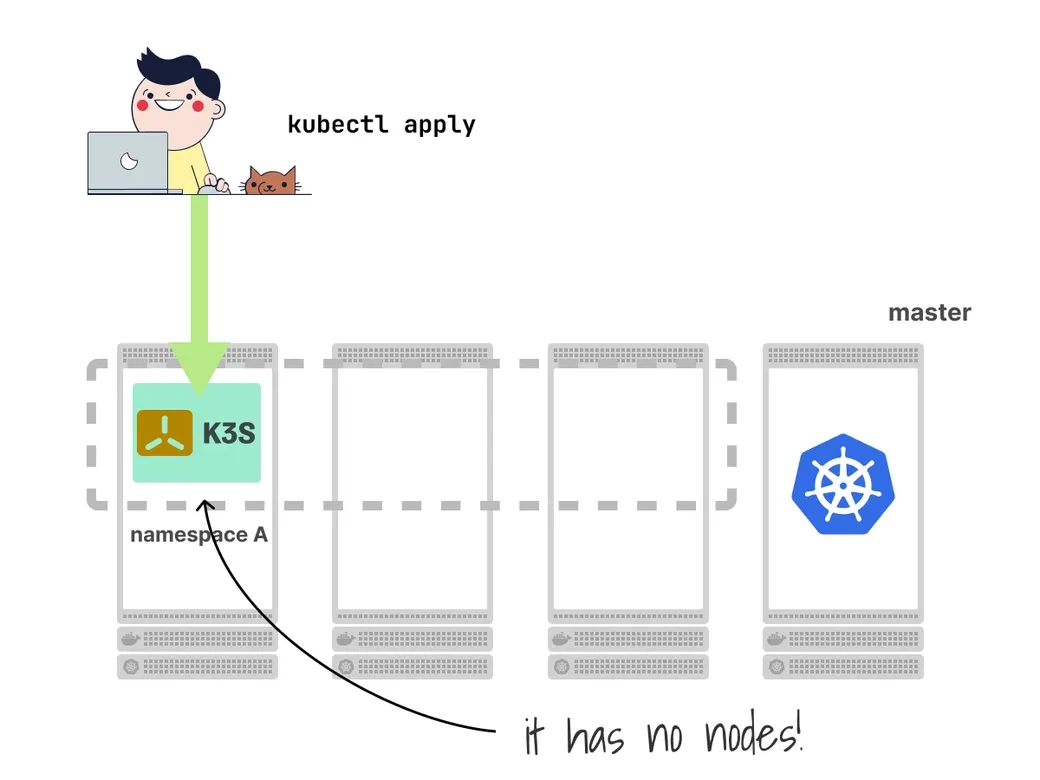
با این کار، کنترل پلین فقط متعلق به آنهاست و در نتیجه منابع گلوبال و مشکل contention و رقابت بر سر منابع حذف میشود.
اما پاد کنترل پلین کجا اسکجول میشود اگر فقط یک کنترل پلین اجرا کنید؟
کلاستر ویرچوآل یا vCluster این رویکرد را در پیش گرفت و راهحل مبتکرانهای ارائه داد: یک کنترلر که منابع را از کنترل پلین مستأجر به کنترل پلین میزبان کپی میکند.
هنگامی که یک Deployment در کنترل پلین مستأجر ایجاد میکنید، مشخصات پادهای حاصل به کنترل پلین میزبان کپی شده و در آنجا زمانبندی میشوند.
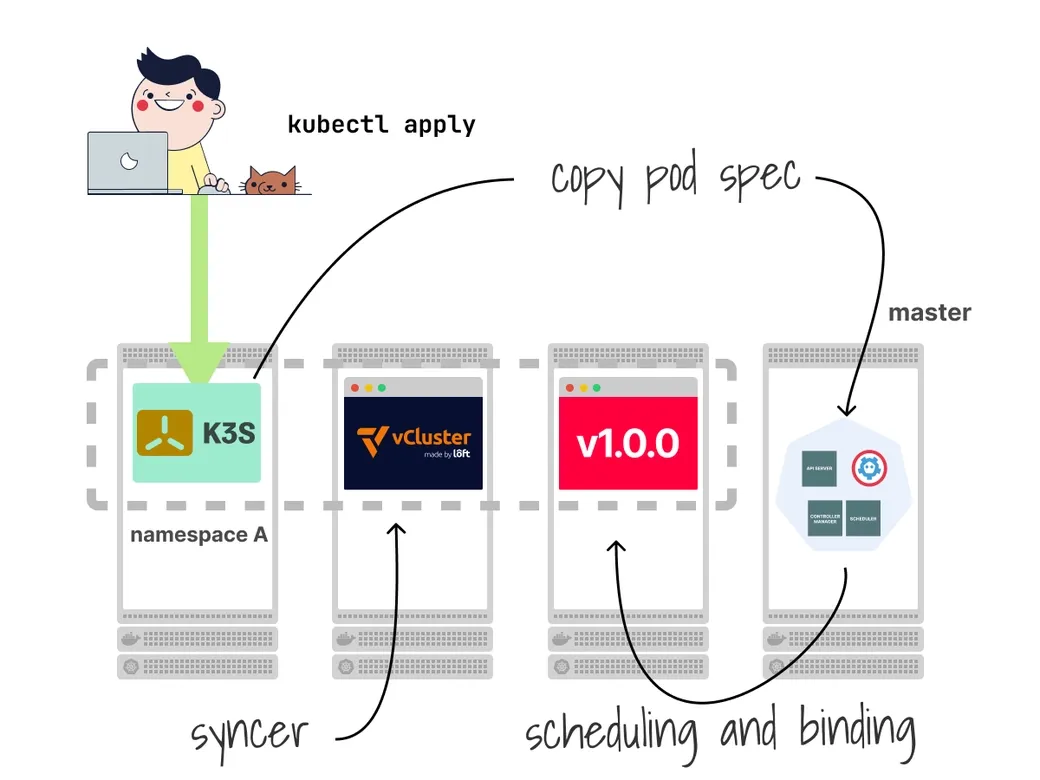
هر مستأجر یک کنترل پلین کامل دارد که انعطافپذیری یک کلاستر واقعی را فراهم میکند.
این کنترل پلین تنها برای ذخیره منابع در یک دیتابیس استفاده میشود.
کنترلر میتواند طوری پیکربندی شود که فقط منابع خاصی را کپی کند.
به عبارت دیگر، یک مکانیزم همگامسازی دقیق به شما اجازه میدهد گزینشی تعیین کنید کدام منابع از کلاستر مستأجر به خوشه میزبان منتقل شوند.
فرآیند تست کردن این روش چیزی شبیه موارد زیر است:
vcluster create test --set 'sync.persistentvolumes.enabled=true'
وقتی nested cluster آماده شد، یک PersistentVolume را در فایل pv.yaml ذخیره کنید:
apiVersion: v1 kind: PersistentVolume metadata: name: task-pv-volume labels: type: local spec: storageClassName: manual capacity: storage: 10Gi accessModes: - ReadWriteOnce hostPath: path: "/mnt/data"
سپس آن را با دستور زیر اعمال کنید:
$ kubectl apply -f pv.yaml persistentvolume/task-pv-volume created
از کلاستر مستأجر خارج شوید و همه PVها را در خوشه میزبان ببینید:
$ vcluster disconnect $ kubectl get pv NAME CAPACITY STATUS CLAIM pvc-6ced7d97-c0f4-4a82-a5f8-2337907fff0b 5Gi Bound vcluster-test/data-test-0 vcluster-task-pv-volume-x-vcluster-test-x-test 10Gi Available
دو PV داریم: یکی برای کنترل پلین و دیگری که تازه ساختیم.
اگر همین آزمایش را برای مستأجر دوم تکرار کنیم چه میشود؟
$ vcluster create test2 --set 'sync.persistentvolumes.enabled=true'
دوباره همان pv.yaml را اعمال میکنیم (نام تکراری اما بدون مشکل):
$ kubectl apply -f pv.yaml persistentvolume/task-pv-volume created
از کلاستر خارج شده و PVها را در میزبان بررسی کنید:
$ vcluster disconnect $ kubectl get pv NAME CAPACITY STATUS CLAIM pvc-131f1b41-7ed3-4175-a33d-080cdff41b44 5Gi Bound vcluster-test2/data-test2-0 pvc-6ced7d97-c0f4-4a82-a5f8-2337907fff0b 5Gi Bound vcluster-test/data-test-0 vcluster-task-pv-volume-x-vcluster-test-x-test 10Gi Available vcluster-task-pv-volume-x-vcluster-test2-x-test2 10Gi Available
هر مستأجر فقط یک PV را میبیند، اما کلاستر میزبان همه را میبیند!
توجه کنید برای هر مستأجر ما یک پاد و یک PV داریم. حال برای اجرای یک خوشه برای 50 مستأجر به چه منابعی نیاز داریم؟
یک خوشه با یک pool شامل نودی با 2GB RAM و 1 vCPU را در نظر بگیرید که یک نود دارد و Cluster Autoscaler هم روش نصب شده. سپس اسکریپت زیر را اگر اجرا کنید:
#!/bin/bash for i in {1..50} do vcluster create "tenant-$i" --connect=false --upgrade done
کلاستر در نهایت روی 17 نود پایدار بر اساس تستهای انجام شده استیبل میشود.
از آنجایی که هر نود حدود 12 دلار در ماه هزینه دارد، مجموع حدود 204 دلار در ماه شد. همچنین 1 دلار در ماه برای حجم 10GB PV هزینه داریم. مجموع حدود 254 دلار در ماه یا تقریباً 5 دلار به ازای هر مستأجر در این حالت هزینه میبرد.
اگر به دلایل قانونی نیاز به جداسازی ورکلود در کلاستر مجزا داشته باشید، چه؟
یک گزینه دیگر داشتن یک خوشه اختصاصی برای هر مستأجر است.
میتوانید از Karmada برای مدیریت کلاستر مستأجران و استقرار ورکلودهای مشترک روی تمام کلاسترها استفاده کنید. معماری Karmada مشابه vCluster است:
ابتدا، یک کنترل پلین مدیر (cluster manager) دارید که از چند کلاستر آگاه است.
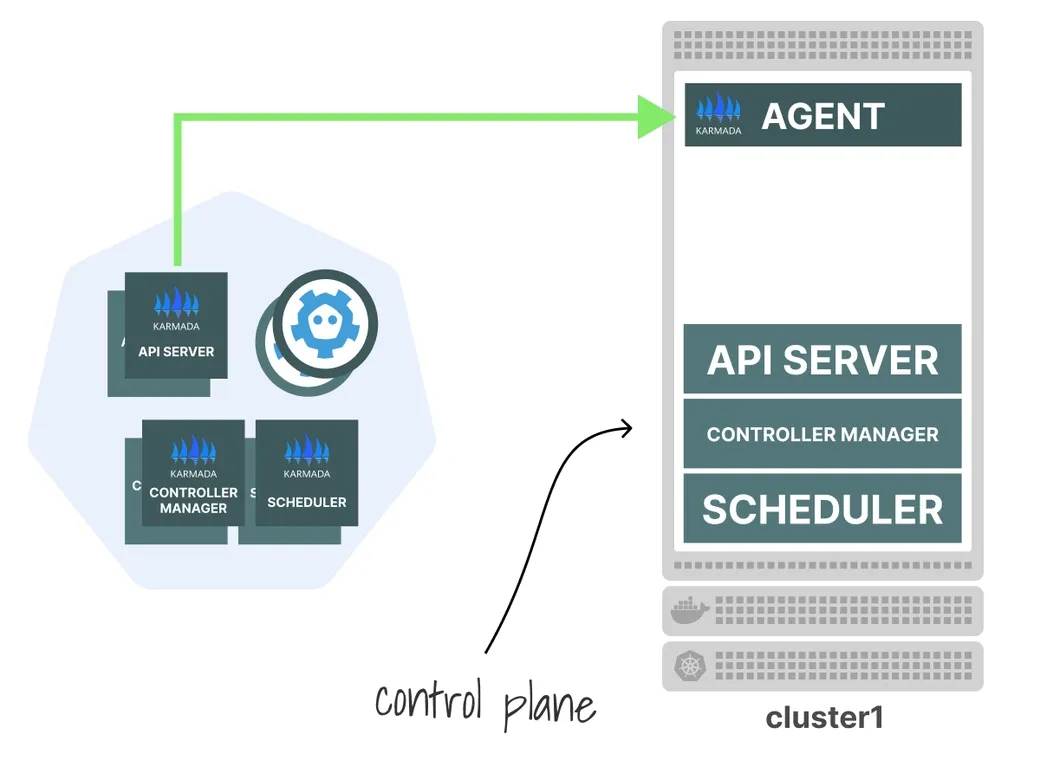
معمولاً آن را در یک کلاستر ویژه که ورکلودی اجرا نمیکند، مستقر میکنند.
سپس Karmada از یک عامل (agent) استفاده میکند که دستورات را از کنترل پلین Karmada دریافت و به کلاستر محلی ارسال میکند.
در نهایت چنین ترکیبی دارید:
کنترل پلین Karmada میتواند ورکلود را روی همه کلاسترها اسکجول کند.
هر کلاستر میتواند همچنان به صورت مستقل ورکلود اجرا کند.
از میان تمام گزینهها، این گرانترین حالت برای نگهداری و بهرهبرداری است.
در آزمایش انجام شده 51 کلاستر (50 مستأجر و 1 مدیریت) با یک نود (1vCPU، 2GB) ساخته شده.
همه کلاسترها منطقهای (Regional) و بدون HA بودند و پلتفرم Akamai هزینهای برای کنترل پلینها دریافت نکرد. تنها هزینه، هزینه یک نود کاری (Worker) برای هر کلاستر بود.
The total: 50$12=~$612/month or ~$12/tenant/month (the cost of the single node).
Comparing multi-tenancy costs:
سه گزینهی چندمستأجری دارای سطوح جداسازی و هزینههای بسیار متفاوتی هستند. باید حواسمون باشه که مالتی تننسی رو باید برای تمام اعضای کلاستر در نظر بگیریم یعنی مانیتورینگ، لاگینگ، پایپلاینها و غیره هم هستند.
هزینهها بسیار متفاوت است، اما توجه داشته باشید که همه گزینههای چندمستأجری مشابه هم نیستند.
با استفاده از کلاسترهای جداگانه عملاً انتخابی ندارید: باید حداقل یک Ingress Controller اختصاصی به ازای هر خوشه داشته باشید — بنابراین گزینههای کمتری برای اشتراک و صرفهجویی در هزینه دارید.
میزبانی چندین مستأجر در یک کلاستر Kubernetes مستلزم تعادل بین هزینهها و جداسازی است.
میتوانید چندمستأجری نرم را با سربار کم انتخاب کنید، اما ریسک تأثیرگذاری یک مشکل روی همهی مستأجران وجود دارد. یا میتوانید جداسازی کامل را انتخاب کنید اما باید نصب، مدیریت و ارتقای کلاسترها را برای چندین تیم را بر عهده بگیرید. گزینهی دیگر یک راه میانه است: یک خوشه مشترک با یک کنترل پلین اختصاصی برای هر مستأجر (مثل vCluster) که مقداری جداسازی همراه با هزینههای قابل مدیریتتر ارائه میدهد.
در بلاگ پستهای بعدی مسیرمون رو ادامه میدیم و بیشتر و بیشتر در مورد کوبرنتیز یاد میگیریم.
مراقب خودتون باشید. 🌹🐳🌹

خوبه که داکرمی رو تو جاهای مختلف فالو کنید. پذیرای نظرات شما هستیم.
🫀 Follow DockerMe 🫀
🔔 Follow YouTube 🔔
📣 Follow Instagram 📣
🖇 Follow LinkedIn DockerMe🖇
🔎 Follow Linkedin Ahmad Rafiee 🔎
🕊 Follow Twitter 🕊