مقاله اخیر اپل که میگوید شاید هوش مصنوعی اونقدرها هم که فکر میکنیم باهوش نباشه و کاربرای فضای مجازی واکنشهای متفاوتی داشتن بیایین بررسی کنیم .

چند وقت پیش، اپل یه مقاله منتشر کرد با یه عنوان : «توهم تفکر: فهمیدن نقاط قوت و ضعف مدلهای استدلالی از دریچه پیچیدگی مسئله».
خلاصهش اینه که خیلیها ازش اینجوری برداشت کردن که این هوش مصنوعیهای خفن امروزی شاید واقعاً «فکر» نکنن. راستش من خودمم فکر نمیکنم این مدلها همین فردا دنیا رو بگیرن و یه ابرهوش واقعی بشن، ولی با کلیت حرف این مقاله هم خیلی حال نمیکنم. مثل همیشه، این مقاله حسابی سر و صدا راه انداخت؛ یه عده گفتن «دمت گرم اپل، حرف دلمونو زدی!»، یه عده دیگه هم گفتن «این چه مزخرفیه؟ اپل خودش از قافله عقب مونده!». بیاید خودمونیتر ببینیم جریان چیه و چی به چیه.
نویسندههای اپل میگن خیلی رو عملکرد این مدلهای هوش مصنوعی تو امتحانای ریاضی و کدنویسی حساب باز نکنید. چرا؟ چون:
(الف) این امتحانا یه جورایی «آلوده»ن، یعنی شاید جواباش از قبل تو دادههایی که به مدل خوروندن باشه،
(ب) تازه، فهمیدن اینکه یه مسئله چقدر «سخته» خودش یه معضل گندهست!
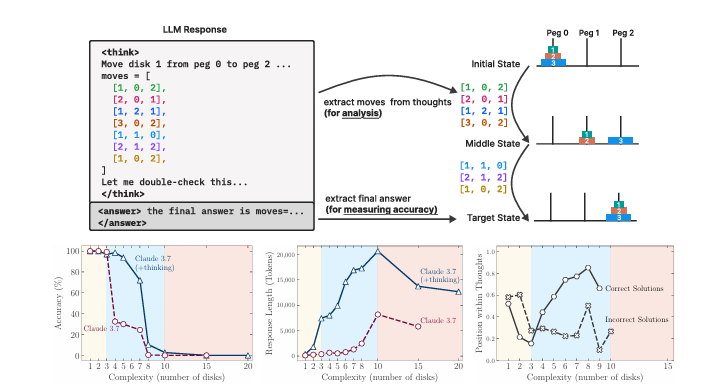
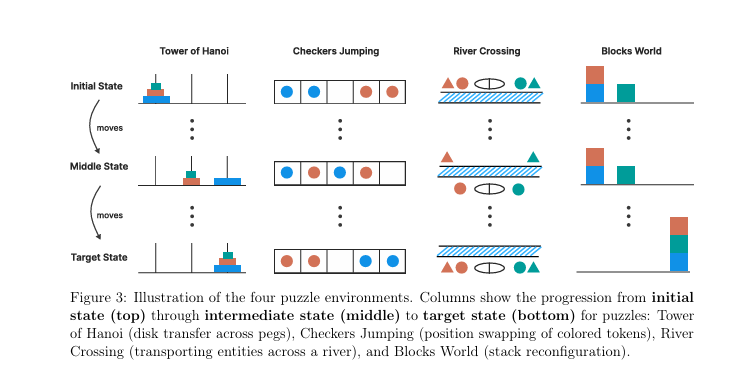
برای همین، رفتن سراغ یه راه دیگه و مدلها رو با چند تا بازی فکری امتحان کردن (مثل برج هانوی، ولی با سختیهای مختلف). از پازلای خیلی ساده (برج هانوی با یه دیسک) تا پازلای خیلی پیچیده (۲۰ تا دیسک).
۱. پازلای خیلی ساده: مدلایی که خیلی اهل فکر کردن نیستن، یا همونقدر خوب بودن یا حتی بهتر! ولی مدلای متفکر گاهی زیادی فکر میکنن و گند میزنن!
۲. پازلای متوسط: اینجا مدلای متفکر دیگه خودشونو نشون دادن و حسابی بهتر عمل کردن.
۳. پازلای خیلی سخت: وقتی کار خیلی سخت میشد، حتی مدلای متفکر هم دیگه جواب درست نمیدادن و انگار کم میآوردن، حتی اگه راه حل رو جلوشون میذاشتی!
نتیجهشون اینه که مدلای متفکر یه «حد پیچیدگی» دارن که نمیتونن ازش رد شن و شاید یه جور محدودیت ذاتی تو توان محاسباتیشون باشه.
۱. این پازلا شاید انتخاب خوبی نباشن!
اگه نگرانیم دادههای ریاضی و کدنویسی آلودهست، چرا سراغ پازلای معروفی مثل برج هانوی رفتیم که راهحلشون تو هر گوشه اینترنت پیدا میشه و احتمالاً تو دادههای مدلها هم بوده؟
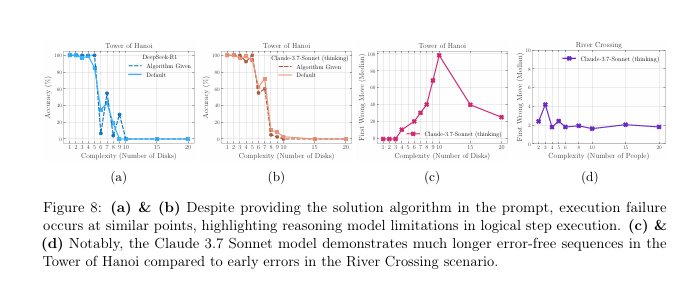
جای تعجب نداره که دادن الگوریتم به مدل کمکی نکرده؛ احتمالاً از قبل بلدش بوده! خود مقالهم میگه مدلها تو اجرای دقیق دستورها مشکل دارن، حتی اگه راه حل رو بدونن.
این مدلها بیشتر رو ریاضی و کدنویسی تربیت شدن، نه پازل. شاید پازلا معیار خوبی برای تست استدلال نباشن. خود اپلم گفته عملکرد مدلها تو پازلای مختلف فرق داره، مثلاً برج هانوی با کلی حرکت یا پازلای سادهتر مثل گذر از رودخانه. منتقدا هم گفتن این پازلا بیشتر «طاقت تکرار کارای زیاد» رو میسنجن تا فکر کردن واقعی.
۲. اون «حد پیچیدگی» شاید ثابت نباشه!
وقتی پازل گنده میشه (مثل برج هانوی ۱۰ دیسکه با ۱۰۲۳ حرکت)، مدل شاید بفهمه مراحل زیاده و بهجای حل قدمبهقدم، دنبال میانبر بگرده.
پس چیزی که تست میکنیم از «میتونه مراحل رو بره؟» میشه «میتونه یه راه کلی پیدا کنه؟» یا «حوصلهش میرسه؟». اینکه نزدیک شکست کمتر تلاش میکنن هم باحاله؛ شاید دارن انرژیشونو مدیریت میکنن یا میفهمن از پسش برنمیان!
واسه همین نمیدونیم واقعاً «نمیتونن» حل کنن یا «نمیخوان» این همه مرحله رو برن!
۳. وجود حد پیچیدگی یعنی استدلال نمیکنن؟
نه بابا! چند نفر از ما میتونیم هزار تا حرکت برج هانوی رو بدون اشتباه بریم؟ اگه نتونیم یعنی فکر نمیکنیم؟ معلومه که نه! فقط حوصله و دقت این همه تکرار رو نداریم.
فکر کردن به ۱۰ مرحلهم فکر کردنه، حتی اگه تو مرحله یازدهم گیر کنی. اینکه مدلها تو اجرای الگوریتمای طولانی مشکل دارن مهمه، ولی معنیش این نیست که کلاً فکر نمیکنن.
با همه اینا، مقاله اپل چند تا نکته جالب داره:
اینکه مدلای متفکر تو مسائل ساده زیادی فکر میکنن و خرابکاری میکنن خیلی باحاله و نشون میده چجوری کار میکنن.
تو مسائل متوسط، مدل اول چند تا راه غلط میره و بعد خودشو درست میکنه و جوابو پیدا میکنه؛ یه جورایی نشون میده داره حل میکنه، هرچند کامل نیست.
تو مسائل سخت، اینکه هیچ جواب درستی به ذهنشون نمیرسه، حتی قبل از اینکه بیخیال شن، نشون میده چقدر قاطی میکنن.
اینکه با سختتر شدن، اول بیشتر زور میزنن ولی یهو ول میکنن، حتی اگه توان محاسباتی داشته باشن، خیلی عجیبه و جای فکر داره.
مثل همیشه، این مقاله کلی سروصدا کرد:
کسایی که همیشه موضع دفاعی راجب هوش مصنوعی میگیرن: گفتن «دیدی گفتم! اینا فقط ادا درمیارن!» و از تجربهشون با مدلایی مثل o3 گفتن که تو مسائل سخت کم میارن.
منتقدا: گفتن «این مقاله چرت و پرته! اپل خودش تو هوش مصنوعی جا مونده، داره بهونه میاره!» حتی گیر دادن که چرا از مدلای خودش استفاده نکرده.
فنیها: بحثاشون تخصصیتر بود. بعضیا گفتن خوبه که محدودیتا رو نشون داده، بعضیا به روش و پازلا ایراد گرفتن.
فنای اپل: اینا به نیت اپل شک کردن و گفتن شاید داره برای خبر بد آماده میشه یا میخواد بگه چرا مدل زبون درستحسابی نداره.
صنعت و دانشگاه: نظرا جورواجور بود. یکی گفت نتیجهگیری گمراهکنندهست، یکی گفت حرف دل مهندسای هوش مصنوعی رو زده. حتی یه جواب رسمی دانشگاهیم دادن!
حرف آخر من:
فکر نمیکنم این مقاله ثابت کنه مدلای هوش مصنوعی «واقعاً» فکر نمیکنن. جامعه هوش مصنوعیم هنوز رو این موضوع توافق نکرده و کلی بحث سر روش تحقیق، نتیجهها و حتی نیت اپل هست. ولی یافتههاش درباره عملکرد مدلها تو سختیهای مختلف و گیر کردنشون چیزای خوبی بهمون میگه.
به نظرم شاید مدلها تو مسائل طولانی و تکراری (مثل پازلای پیچیده) یهو تصمیم بگیرن بیخیال شن، نه اینکه فکر کردنشون محدود باشه. اینکه تو اجرای الگوریتمای طولانی مشکل دارن، حتی اگه راه حل رو بدونن، یه ضعف خاصه. ما آدما هم اگه یه مسئله خیلی پیچیده و خستهکننده باشه، ممکنه قاطی کنیم یا ولش کنیم، ولی معنیش این نیست که فکر نمیکنیم! هنوز معلوم نیست تو این مدلها فرق بین «نمیتونن فکر کنن» و «نمیخوان یه کار طولانی رو ادامه بدن» چیه؛ سؤال مهمیه.
شما چی فکر میکنید؟ این مدلها واقعاً فکر میکنن یا فقط فیلم بازین و شاید این فیلم بازی کردنشونم بهخاطر محدودیتای محاسباتیه، نه اینکه کلاً بلد نباشن؟