تحلیل و بررسی مقاله «بازاندیشی، تلاش مجدد، پاداش: خودبهبودی مدلهای زبانی بزرگ از طریق یادگیری تقویتی»
(Reflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning)

بیشتر تلاشها برای بهبود تواناییهای مدلهای زبانی بر بزرگتر کردن مقیاس متمرکز بودهاند: یعنی استفاده از پارامترهای بیشتر، دادههای آموزشی حجیمتر و پردازندههای گرافیکی (GPU) قدرتمندتر. اما این مقاله رویکرد متفاوتی را ارائه میدهد. در این روش، به مدل یاد داده میشود که وقتی دچار خطا میشود، ابتدا نقد کوتاهی از عملکرد خود بنویسد (بازاندیشی کند) و سپس دوباره برای پاسخ صحیح تلاش کند. نکته کلیدی این است که پاداش یادگیری تقویتی فقط به بخش «بازاندیشی» داده میشود. به این ترتیب، مدل به تدریج یاد میگیرد چگونه خطاهای خود را تشخیص دهد، به جای آنکه صرفاً پاسخهای خاصی را برای وظایف مختلف به خاطر بسپارد.
نویسندگان این مقاله، با استفاده از این روش بر روی دو معیار ارزیابی چالشبرانگیز و خودکار – یکی مربوط به «فراخوانی توابع» (APIGen) و دیگری «معماهای ریاضی» به سبک بازی Countdown – به ترتیب ۱۸ و ۳۴ درصد بهبود عملکرد نشان دادند. جالب اینجاست که مدلهای نسبتاً کوچک (۱.۵ تا ۷ میلیارد پارامتر) با این روش، عملکردی بهتر از مدلهای بسیار بزرگتر (۷۰ میلیارد پارامتر) از خود نشان دادند.
مراحل کار به این صورت است:
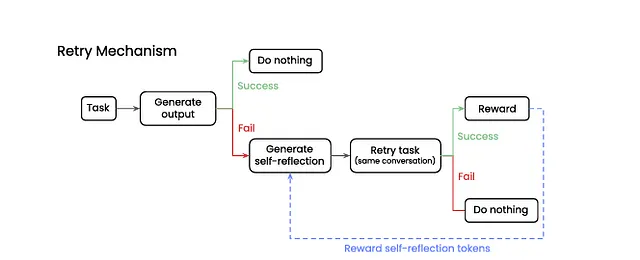
تلاش اول: مدل زبانی بزرگ (LLM) به شکل معمول به درخواست پاسخ میدهد.
بررسی صحت: یک سیستم ارزیاب خودکار، پاسخ را «صحیح» یا «غلط» علامتگذاری میکند.
بازاندیشی درونی (Self-reflection): در صورت غلط بودن پاسخ، مدل یادداشت کوتاهی درباره علت خطای خود (مثلاً «اینجا اشتباه کردم») تولید میکند.
تلاش مجدد: مدل با در نظر گرفتن یادداشت انتقادی خود، دوباره برای پاسخ به درخواست تلاش میکند.
پاداشدهی با GRPO: اگر تلاش مجدد موفقیتآمیز باشد، تنها توکنهایی (واژهها یا اجزای کلام) که در فرآیند بازاندیشی (مرحله ۳) تولید شدهاند، سیگنال پاداش مثبت دریافت میکنند.
دو نکته هوشمندانه در طراحی این روش، اجرای آن را تسهیل کرده است:
بهینهسازی گروهی نسبی (GRPO): این تکنیک، نیاز به یک شبکه ارزش (value network) جداگانه را در یادگیری تقویتی حذف میکند. در نتیجه، فرآیند یادگیری تقویتی برای مدلهای کوچک (۱ تا ۸ میلیارد پارامتر) سبک و قابل اجرا باقی میماند.
آموزش بر روی مجموعه دادهای از خطاها: مدل تنها بر روی نمونههایی آموزش داده میشود که در آنها مدل پایه (بدون این روش) دچار خطا شده است. این کار باعث کاهش زمان استفاده از پردازندههای گرافیکی (GPU) شده و فرآیند یادگیری را بر نقاط ضعف مدل متمرکز میکند.
عملکرد بهتر مدلهای کوچک: مدلهای کوچکتر با این روش، عملکردی بهتر از مدلهای پایه (baseline) بسیار بزرگتر از خود نشان میدهند.
یادگیری عمیقتر: نکته جالبتر این است که پس از بهکارگیری GRPO، بسیاری از پرسشها در همان تلاش اول با موفقیت پاسخ داده میشوند. این امر نشان میدهد که روشهای اکتشافی (heuristics) تشخیص خطا که مدل آموخته است، به توانایی استدلال کلی آن نیز تعمیم پیدا میکند.
عدم فراموشی فاجعهبار: نویسندگان همچنین عملکرد مدل را بر روی چهار معیار ارزیابی گسترده دیگر (MMLU-Pro، GSM8K، HellaSwag، MATH) بررسی کرده و کاهش عملکردی کمتر از ۱ درصد را مشاهده نمودند. این نشان میدهد که پدیده «فراموشی فاجعهبار» (catastrophic forgetting) – یعنی فراموش کردن آموختههای قبلی پس از یادگیری مطالب جدید – در این روش بسیار ناچیز است.
بازاندیشی بر تکرار صرف، برتری دارد. این مقاله یادآور نظریههای یادگیری در انسان است: فراشناخت (metacognition) یا توانایی اندیشیدن درباره تفکر خود، اغلب دستاوردهای بیشتری نسبت به تمرین صرف و تکراری به همراه دارد. با پاداش دادن به فرآیند رسیدن به بینش و درک خطا، به جای پاداش صرف به پاسخ نهایی، مدل مهارتهای اشکالزدایی (debugging) قابل تعمیمی را میآموزد.
رویکردی عملی برای مدلهای با اندازه متوسط. آموزش مدل با استفاده از هشت پردازنده H100 و برای کمتر از ۲۰۰۰ مرحله یادگیری تقویتی، به شکلی امیدوارکننده، منطقی و قابل دسترس است. این بدان معناست که مراکز دانشگاهی و شرکتهای نوپایی که به توان محاسباتی لازم برای آموزش مدلهای ۷۰ میلیارد پارامتری دسترسی ندارند، با این روش همچنان میتوانند به عملکردهای سطح بالا دست یابند.
محدودیت ارزیابهای خودکار (گلوگاه روش). این روش برای وظایفی که در آنها یک ارزیاب (oracle) خودکار میتواند به وضوح پاسخ را «صحیح» یا «غلط» تشخیص دهد (مانند اجرای کد، تستهای واحد نرمافزار، یا حل معادلات) بسیار مناسب است. اما برای وظایفی با پاسخهای باز، مانند نویسندگی خلاق، مشاوره در زمینه سیاستگذاری، یا سایر کارهای نیازمند قضاوت انسانی، تا زمانی که ارزیابهای خودکار قابل اعتمادی توسعه نیابند، این روش کاربرد محدودی خواهد داشت.
شفافیت بیشتر بازاندیشی به مرور زمان. نویسندگان مقاله نشان میده دهند که یادداشتهای بازاندیشی اولیه مدل، اغلب طولانی و مبهم هستند، اما پس از آموزش با GRPO، این یادداشتها به نکات کلیدی، کوتاه و متمرکز تبدیل میشوند. این یافته با تجربه شخصی من نیز مطابقت دارد: پرگویی اغلب نشانهای از سردرگمی است، در حالی که ایجاز و اختصار، نشاندهنده شفافیت ذهن و درک عمیق است.
همافزاییهای (Synergies) بالقوه. من علاقهمندم که این روش را با رویکرد «زنجیره تفکر» (Chain-of-Thought یا CoT) ترکیب کنم. CoT به بهبود استدلال پیشرونده (forward reasoning) کمک میکند، در حالی که بازاندیشی مبتنی بر GRPO، تحلیل خطای پسرونده (backward error analysis) را تقویت میکند. ترکیب این دو رویکرد میتواند هر دو جنبه را پوشش داده و به نتایج بهتری منجر شود.
پرسشهای باز (نیازمند پژوهش بیشتر):
تعمیمپذیری بین وظایف مختلف: آیا آموزش مهارت بازاندیشی بر روی یک نوع وظیفه (مثلاً فراخوانی توابع) میتواند به بهبود عملکرد در وظایف دیگر (مانند حل معماهای منطقی) کمک کند؟ مقاله به این امکان اشاره میکند، اما آن را به طور مستقیم آزمایش نکرده است.
جایگزینی ارزیابهای خودکار با قضاوت انسانی: آیا میتوان ارزیابهای خودکار (که پاسخ را صرفاً صحیح/غلط میدانند) را با بازخورد انسانی (که ممکن است دقیق نباشد و همراه با خطا باشد) جایگزین کرد؟
برنامهریزی بلندمدت و وظایف چندمرحلهای: GRPO در حال حاضر تنها یک تلاش مجدد را پاداش میدهد. برای وظایف پیچیدهتر و چندمرحلهای (مانند عاملهای هوشمندی که از ابزارهای مختلف استفاده میکنند)، ممکن است به فرآیندهای بازاندیشی عمیقتر و چندلایهای نیاز باشد.
روش «بازاندیشی، تلاش مجدد، پاداش» چیزی فراتر از یک ترفند ساده است؛ به نظر میرسد این روش، حلقهای مفقوده در جعبهابزار توسعه هوش مصنوعی خودبهبودگر (self-improving AI) باشد. این مقاله نشان میدهد که میتوان به مدلهای زبانی آموخت تا نواقص خود را تشخیص داده و آنها را اصلاح کنند – آن هم با حجم دادههای آموزشی نسبتاً کم، توان محاسباتی معقول، و بدون نیاز به یک مدل «معلم» بسیار بزرگ. برای تمام پژوهشگران و توسعهدهندگانی که بر روی ساخت مدلهای زبانی بزرگ و متخصص در حوزههای خاص کار میکنند، بهویژه آنهایی که با محدودیت بودجه مواجه هستند، این تکنیک ارزش بررسی، پیادهسازی و توسعه بیشتر را دارد.