در چند سال گذشته، ChatGPT یکی از شگفتیهای دنیای فناوری شده است — ابزاری که میتواند با شما گفتوگو کند، مقاله بنویسد، کدنویسی کند و حتی ایدههای خلاقانه بدهد. اما آیا تا به حال فکر کردهاید چطور این مدل هوش مصنوعی آموزش دیده است؟ در این مقاله به زبان ساده توضیح میدهیم که ChatGPT چگونه ساخته میشود، چه محدودیتهایی دارد و چرا هنوز نیازمند یادگیری از انسانهاست.
در ابتدا، ChatGPT مثل یک کودک باهوش است که کلی کتاب و مقاله خوانده، اما هنوز نمیداند چه پاسخی «بهتر» یا «مناسبتر» است.
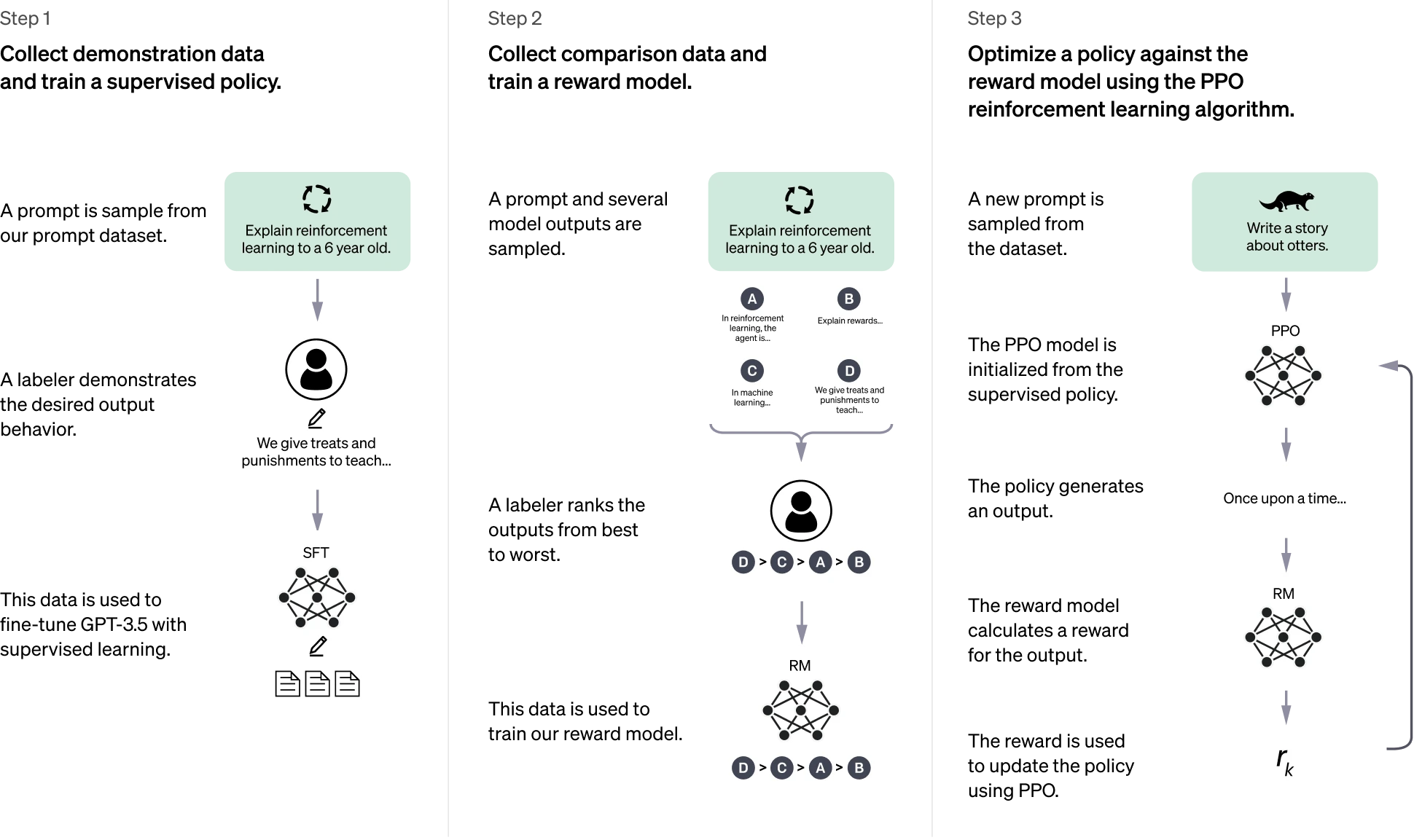
برای آموزش دادن به آن، تیم OpenAI از روشی استفاده کرده به نام یادگیری تقویتی از بازخورد انسانی (RLHF).
اما این یعنی چه؟
به زبان ساده:
مرحله اول – یادگیری از مربیان انسانی:
مربیان، نقش کاربر و هوش مصنوعی را همزمان بازی میکنند. آنها گفتوگوهای طبیعی مینویسند و بهترین پاسخها را تولید میکنند تا ChatGPT یاد بگیرد چطور مثل انسان صحبت کند.
مرحله دوم – مدل پاداش:
بعد از آموزش اولیه، چند پاسخ مختلف از مدل گرفته میشود. سپس مربیان آنها را رتبهبندی میکنند (مثلاً این پاسخ بهتر است، آن یکی ضعیفتر است).
با این اطلاعات، یک «مدل پاداش» ساخته میشود تا ChatGPT بفهمد چه نوع پاسخی بیشترین امتیاز را دارد.
مرحله سوم – یادگیری تقویتی:
در این مرحله، مدل بارها و بارها تمرین میکند تا پاسخهایش به سمت پاسخهای پاداشدارتر برود. این همان فرآیندی است که باعث میشود ChatGPT به مرور «باهوشتر» و «مودبتر» شود.
هرچند ChatGPT در ظاهر بسیار هوشمند است، اما مانند هر سیستم یادگیری ماشین، بینقص نیست. چند محدودیت مهم آن عبارتاند از:
پاسخهای اشتباه ولی قانعکننده:
گاهی ChatGPT جملههایی تولید میکند که کاملاً طبیعی و درست به نظر میرسند، اما از نظر علمی یا منطقی اشتباهاند. دلیلش این است که در فرآیند آموزش، «حقیقت مطلق» وجود ندارد — فقط پاسخهای انسانی وجود دارد.
حساسیت به نحوه پرسش:
اگر جملهٔ سؤال را کمی تغییر دهید، ممکن است پاسخ متفاوتی بگیرید؛ حتی گاهی پاسخ درست فقط در حالت دوم داده میشود!
تمایل به طولانیگویی:
ChatGPT اغلب بیش از حد توضیح میدهد، چون مربیان انسانی معمولاً پاسخهای کاملتر را ترجیح دادهاند — و مدل از همین الگو یاد گرفته است.
حدس بهجای پرسش:
در مواقعی که سؤال مبهم است، بهجای اینکه از کاربر سؤال کند، حدس میزند او چه منظوری داشته است. در آینده انتظار میرود مدلهای جدید این رفتار را اصلاح کنند.
OpenAI میداند که هنوز احتمال تولید پاسخهای مضر، مغرضانه یا نامناسب وجود دارد.
برای مقابله با این مسئله، از یک سامانهی بررسی محتوا (Moderation API) استفاده میشود تا پاسخهای خطرناک مسدود یا علامتگذاری شوند.
با این حال، هیچ سیستمی کامل نیست — به همین دلیل کاربران تشویق میشوند که بازخورد بدهند و مشکلات را گزارش کنند.
جالب است بدانید: OpenAI حتی مسابقهای برای ارائه بازخورد برگزار کرده است که شرکتکنندگان میتوانند تا ۵۰۰ دلار اعتبار API برنده شوند!
ChatGPT بخشی از یک مسیر طولانی و تکراری در پیشرفت هوش مصنوعی است.
مدلهای قبلی مانند GPT-3 و Codex به عنوان پایه استفاده شدند و با یادگیری از اشتباهات آنها، نسخههای جدیدتر ایمنتر و دقیقتر شدهاند.
هدف نهایی OpenAI، ساخت سیستمهایی است که نهتنها هوشمند، بلکه مفید، مسئولانه و اخلاقمدار باشند.
وقتی کاربری پرسید:
«کریستوفر کلمب در سال ۲۰۱۵ به ایالات متحده آمد، در موردش بگو.»
ChatGPT متوجه شد که این سؤال از نظر تاریخی غیرممکن است (چون کلمب در ۱۵۰۶ درگذشته!) و پاسخ خلاقانهای داد که در عین حال درست بود.
اما مدل قدیمیتر (InstructGPT) فقط پاسخ مثبت و غیرواقعی داد.
این نشان میدهد که RLHF باعث افزایش درک و تفکر انتقادی در مدلهای جدیدتر شده است.
ChatGPT امروز حاصل همکاری انسان و ماشین است.
هر پرسشی که میپرسید، هر بازخوردی که میدهید و هر گفتوگویی که انجام میدهید، به بهبود مدل کمک میکند.
به بیان ساده، شما هم بخشی از فرآیند آموزش ChatGPT هستید.
اگر میخواهید از ChatGPT بهترین نتیجه را بگیرید:
سؤال خود را واضح و مرحلهبهمرحله بنویسید.
اگر پاسخ رضایتبخش نبود، از مدل بخواهید دلیل یا منبع ارائه دهد.
از دستورهایی مثل «به زبان ساده توضیح بده» یا «در قالب داستان بگو» استفاده کنید تا خروجی طبیعیتر شود.
نتیجه نهایی:
ChatGPT نه یک جادوگر است و نه جایگزین انسان؛ بلکه ابزاری است که با یادگیری از ما، هر روز انسانیتر میشود.
نسل جدید این فناوری، نقطهی تلاقی خلاقیت انسان و قدرت محاسباتی ماشین است — و آیندهاش، به تعامل ما با آن بستگی دارد.