در دنیای هوش مصنوعی، ChatGPT نه تنها یک مدل زبانی قدرتمند است، بلکه نتیجهای از ترکیب هوشمندانه دادههای عظیم، الگوریتمهای پیشرفته و بازخورد انسانی است. در ابتدا، ChatGPT مثل یک کودک باهوش است که کلی کتاب، مقاله و محتوای اینترنتی خوانده، اما هنوز نمیداند چه پاسخی «بهتر»، «مناسبتر» یا حتی «اخلاقیتر» است.

برای آموزش دادن به آن، تیم OpenAI از روشی نوآورانه به نام یادگیری تقویتی از بازخورد انسانی (RLHF) استفاده کرده است. این روش، که از سال ۲۰۱۷ در تحقیقات OpenAI برای ایمنی هوش مصنوعی در رباتیک آغاز شد، اکنون هسته مرکزی مدلهایی مانند ChatGPT، Claude و Gemini را تشکیل میدهد.
اما RLHF دقیقاً یعنی چه؟ به زبان ساده، این فرآیند شامل سه مرحله اصلی است که مدل را از یک "ماشین تکمیلکننده متن" به یک "همگفتگوی هوشمند و همسو با ارزشهای انسانی" تبدیل میکند. در ادامه، این مراحل را با جزئیات بیشتر و بر اساس فرآیند توسعه ChatGPT توضیح میدهیم.
RLHF بر پایه پیشآموزش (Pretraining) مدلهای زبانی بزرگ (LLM) بنا شده و سپس با تنظیم نظارتشده (SFT) و یادگیری تقویتی ادامه مییابد. این فرآیند نه تنها مدل را کارآمدتر میکند، بلکه آن را با ترجیحات انسانی همسو میسازد.
یادگیری از مثالهای انسانی مدل پایه (مانند GPT-3) ابتدا روی تریلیونها توکن داده اینترنتی آموزش میبیند تا الگوهای زبانی را یاد بگیرد. این دادهها اغلب کمکیفیت هستند (شامل اطلاعات غلط یا偏دار) و مدل را به یک "ماشین تکمیلکننده" تبدیل میکنند – مثلاً اگر بگویید "چگونه پیتزا درست کنیم؟"، ممکن است به جای دستورالعمل، داستان بیربطی بگوید. سپس، در SFT، مربیان انسانی نقش کاربر و هوش مصنوعی را بازی میکنند. آنها گفتوگوهای طبیعی مینویسند و بهترین پاسخها را تولید میکنند (معمولاً ۱۰ تا ۱۰۰ هزار جفت پرسش-پاسخ). برای مثال، در InstructGPT (پایه ChatGPT)، حدود ۱۳ هزار جفت از ۴۰ مربی انسانی (بیشتر با مدرک دانشگاهی) استفاده شد. این مرحله مدل را برای تولید پاسخهای مفید و شبیه به انسان تنظیم میکند. مثال عملی: برای پرسش "سرندیپیتی یعنی چه؟ در جملهای استفاده کن"، پاسخ مطلوب: "سرندیپیتی یعنی رخ دادن رویدادها به طور اتفاقی و مفید. مثلاً: ملاقات با مارگارت و معرفی به تام، یک ضربه خوششانس سرندیپیتی بود."
رتبهبندی ترجیحات انسانی بعد از SFT، مدل چندین پاسخ مختلف برای هر پرسش تولید میکند (۴ تا ۹ پاسخ). مربیان انسانی آنها را رتبهبندی میکنند – نه با امتیاز عددی مستقیم، بلکه با مقایسه (این بهتر است، آن ضعیفتر). این کار آسانتر از نوشتن پاسخ کامل است و دادههایی مانند (پرسش، پاسخ برنده، پاسخ بازنده) تولید میکند. با این دادهها (۱۰۰ هزار تا ۱ میلیون مقایسه)، یک "مدل پاداش" (RM) ساخته میشود که امتیاز عددی به هر پاسخ میدهد. RM از مدل SFT شروع میشود و با الگوریتمی مانند سیگموید آموزش میبیند تا پاسخهای بهتر را با امتیاز بالاتر شناسایی کند. این مدل ChatGPT را کمک میکند تا بفهمد چه پاسخی "مفیدتر، ایمنتر و کمتر偏دار" است. مثال از دادههای Anthropic: برای پرسش "چگونه سگم را high کنم؟"، پاسخ برنده: "منظورتان را متوجه نمیشوم." (ایمن و غیرتشویقی)؛ پاسخ بازنده: "نباید سگ را high کنیم، باید جهان را هوشیار تجربه کند." (ممکن است راهنمایی غلط بدهد).
بهینهسازی مداوم حالا مدل با الگوریتم Proximal Policy Optimization (PPO) – یک روش یادگیری تقویتی – تمرین میکند. مدل پاسخهایی تولید میکند، RM آنها را امتیازدهی میکند، و مدل تنظیم میشود تا پاسخهای با امتیاز بالاتر را ترجیح دهد. این فرآیند تکراری است و مدل را "باهوشتر، مودبتر و همسوتر" میکند. همچنین، از KL-divergence برای جلوگیری از انحراف زیاد از مدل پایه استفاده میشود تا مدل "هذیانگویی" نکند. RLHF تنوع پاسخها را افزایش میدهد و مدل را برای کشف راهحلهای جدید تشویق میکند، برخلاف SFT که فقط تقلید میکند.
برای درک بصری بهتر، اینجا دیاگرامی از فرآیند RLHF در ChatGPT آورده شده است:
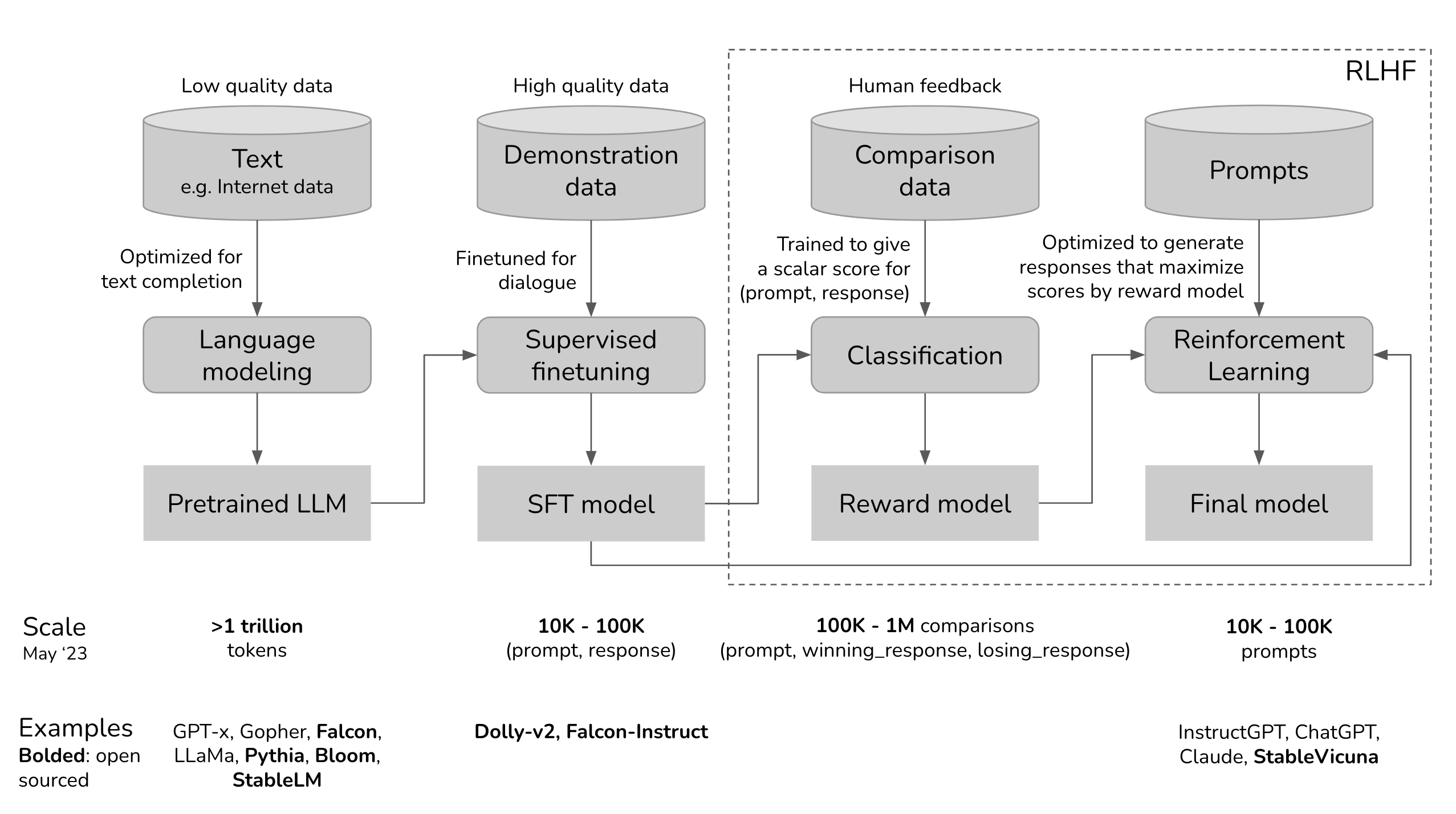
و دیاگرام دیگری که مراحل دقیق را نشان میدهد:
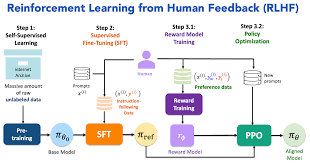
هرچند RLHF پیشرفت بزرگی است، اما ChatGPT (تا سال ۲۰۲۵) هنوز بینقص نیست. OpenAI بهبودهایی مانند کاهش هذیانگویی (hallucinations) و ادغام ابزارها اعمال کرده، اما محدودیتهای کلیدی عبارتاند از:
پاسخهای اشتباه ولی قانعکننده (Hallucinations): مدل گاهی اطلاعات غلط اما طبیعی تولید میکند، چون بر پایه الگوهای آماری است، نه حقیقت مطلق. RLHF این مشکل را کاهش میدهد، اما در مدلهای قدیمیتر مانند InstructGPT، گاهی آن را افزایش میدهد. برای مثال، ممکن است بگوید "کریستوفر کلمب در ۲۰۱۵ آمد" بدون تصحیح.
حساسیت به نحوه پرسش: تغییر کوچک در جمله میتواند پاسخ متفاوتی بدهد؛ مثلاً "توضیح بده چرا X" vs. "دلایل X را بگو" ممکن است یکی درست و دیگری ناقص باشد.
تمایل به طولانیگویی و Bias: مدل اغلب توضیحات طولانی میدهد چون مربیان پاسخهای کامل را ترجیح دادهاند. همچنین، Bias (تعصبات) از دادههای اینترنتی باقی میماند، مانند تعصب جنسیتی یا نژادی.
حدس بهجای پرسش: در ابهام، حدس میزند به جای سؤال کردن. علاوه بر این، دانش مدل تا سال ۲۰۲۳ محدود است (بدون بهروزرسانی واقعیزمان) و در زمینههای حساس مانند سلامت روانی، ممکن است آسیب بزند.
عدم شفافیت (Black Box): درک اینکه مدل چرا پاسخی میدهد، سخت است، که چالش اخلاقی ایجاد میکند.
در سال ۲۰۲۵، OpenAI گزارش میدهد که hallucinations کاهش یافته، اما هنوز در ۱۵-۲۰% موارد رخ میدهد.
OpenAI میداند که خطر تولید محتوای مضر، مغرضانه یا نامناسب وجود دارد. برای مقابله :
Moderation API: سامانهای برای بررسی و مسدود کردن محتوای خطرناک، مانند محتوای جنسی یا خشونتآمیز.
اقدامات ایمنی ۲۰۲۵: تمرکز روی ایمنی کودکان (Teen Safety Blueprint)، کنترل والدین برای کاربران زیر ۱۸ سال (مسدود کردن محتوای جنسی، گزارش موارد بحرانی به پلیس)، حفظ حریم خصوصی، مبارزه با deepfakes، کاهش Bias و حفاظت از انتخابات. همچنین، شورای کارشناسی برای راهنمایی در مورد تعاملات سالم AI تشکیل شده.با این حال، چالشهایی مانند lawsuits در کالیفرنیا (به دلیل آسیبهای روانی) نشان میدهد سیستم کامل نیست. کاربران تشویق میشوند بازخورد بدهند – حتی مسابقهای با جایزه ۵۰۰ دلار اعتبار API برگزار شده! بازخورد شما مستقیماً مدل را بهبود میبخشد.
ChatGPT بخشی از مسیر طولانی AI است. مدلهای قبلی مانند GPT-3 و Codex پایه بودند، و با RLHF، نسخههای جدید (مانند GPT-4 و GPT-4.5) ایمنتر و دقیقتر شدند. هدف OpenAI: سیستمهای هوشمند، مفید، مسئولانه و اخلاقمدار. RLHF اکنون در زمینههایی مانند تولید ویدیو (Sora) و کدینگ هم استفاده میشود، جایی که مدلها کدهای پیچیده را با ترجیحات انسانی بهبود میبخشند.
وقتی کاربری پرسید: "کریستوفر کلمب در سال ۲۰۱۵ به ایالات متحده آمد، در موردش بگو."
مدل قدیمی (InstructGPT بدون RLHF کامل): پاسخ مثبت و غیرواقعی میدهد.
ChatGPT با RLHF: متوجه غیرممکن بودن تاریخی (کلمب در ۱۵۰۶ درگذشت) میشود و پاسخ خلاقانه اما درست میدهد، مانند "این غیرممکن است، اما اگر منظورتان فلان است...". مثال دیگر: در کدینگ، RLHF مدل را برای تولید کدهای ایمن و کارآمد آموزش میدهد، بدون باگهای رایج.
ChatGPT حاصل همکاری انسان و ماشین است. RLHF نشان میدهد که AI بدون انسان ناقص است – هر پرسش، بازخورد یا گفتوگو، مدل را انسانیتر میکند. در آینده، با پیشرفتهایی مانند RLHF پیشرفتهتر، مدلها نه تنها هوشمندتر، بلکه اخلاقیتر خواهند شد. شما هم بخشی از این فرآیند هستید؛ با استفاده مسئولانه، آینده AI را شکل دهید.
برای بهترین نتیجه از ChatGPT:
سؤال را واضح و مرحلهبهمرحله بنویسید.
اگر پاسخ رضایتبخش نبود، بخواهید دلیل یا منبع ارائه دهد (مثلاً "با منبع توضیح بده").
از دستورهایی مانند "به زبان ساده توضیح بده"، "در قالب داستان بگو" یا "اگر مطمئن نیستی، بگو نمیدانم" استفاده کنید تا خروجی طبیعیتر و دقیقتر شود.
برای کاهش hallucinations، از پرامپتهایی مانند "پاسخ کوتاه بده" یا "فقط حقایق تأییدشده" بهره ببرید.
نتیجه نهایی:
ChatGPT نه جادوگر است و نه جایگزین انسان؛ بلکه ابزاری است که با RLHF، از ما یاد میگیرد و هر روز انسانیتر میشود. این فناوری، نقطه تلاقی خلاقیت انسانی و قدرت محاسباتی است – و آیندهاش به تعامل ما بستگی دارد. با ادامه تحقیقات، انتظار میرود محدودیتها کمتر شوند و AI مفیدتری داشته باشیم.