سلام. اول میخوام یک موضوعی رو بیان کنم اینکه این مقاله کمی طولانی هست و در سه قسمت اصلی تقسیم بندی شده است. پس اگر معمار سیستم های پایگاه داده هستید و یا علاقه زیادی به مباحث پایگاه داده دارید، این مقاله برای شما مفید خواهد بود.
در قسمت اول: مشروحی بر چیستی موضوع رو خواهیم داشت.
در قسمت دوم: تعاریف دقیق کلید واژه ها رو خواهیم داشت.
در قسمت سوم: به بررسی مقاله آقای Edgar Frank Codd مطروحه در سال 1970
خواهیم پرداخت.
اگر در مورد آقای کاد اطلاعات کافی ندارید، پیشنهاد میکنم این مقاله رو حتما بررسی کنید.
دوستان اگر چند سالی با دیتابیسهای رابطهای سر و کله زده باشید، احتمالاً SQL شده رفیق شفیقتان. کوئری میزنیم، دیتا میگیریم، کار راه میافتد و تمام. اما معمولاً یک سؤال مهم را از خودمان نمیپرسیم: «پایگاه داده این دستوراتی که من نوشتم را چطور میفهمد؟»
جواب کوتاه این است: نه با SQL، بلکه با چیزی عمیقتر به اسم جبر رابطهای.
ایدهی جبر رابطهای اولینبار توسط Edgar Frank Codd در مقالهی معروفش در سال ۱۹۷۰ مطرح شد؛ زمانی که هنوز خبری از SQL به شکل امروزیاش نبود. آقای کاد دنبال یک زبان برنامهنویسی نبود؛ دنبال یک مدل فکری بود. مدلی که به ما اجازه بده درباره دادهها بدون وابستگی به فایل، دیسک و جزئیات فیزیکی فکر کنیم.
برای شروع، باید یک سوءتفاهم رایج را کنار بگذاریم:
در مدل رابطهای، «جدول» فقط یک جدول نیست. چیزی که ما بهش میگیم جدول، از دید کاد یک Relation است. Relation یعنی یک رابطهی ریاضی؛ چیزی شبیه یک مجموعه. داخل این مجموعه، هر سطر یک Tuple است. اگر بخواهم خیلی خودمونی بگم، Tuple یعنی «یک رکورد کامل». هر ستون هم یک Attribute است؛ یعنی یک ویژگی از داده، مثل نام، سن یا ایمیل.
نکتهی مهم اینجاست که Relation مجموعه است، نه لیست. یعنی ترتیب سطرها مهم نیست و تکرار معنی ندارد. شاید در SQL اینها را حس نکنیم، ولی در ذهن جبر رابطهای، اینها اصول پایهاند.
حالا که داده را مجموعه دیدیم، طبیعی است که بخواهیم روی آن عملیات انجام بدهیم. اینجاست که جبر رابطهای وارد بازی میشود. جبر رابطهای مجموعهای از عملگرهاست که روی Relationها کار میکنند و یک ویژگی خیلی مهم دارند: هر عملی که انجام میدهیم، خروجیاش باز هم یک Relation است. آقای کاد روی این موضوع خیلی تأکید داشت، چون همین ویژگی است که اجازه میدهد عملیاتها را ترکیب کنیم و بهینهسازی منطقی انجام بدهیم.
مثلاً عملگر Selection را در نظر بگیر. Selection یعنی انتخاب بعضی سطرها بر اساس یک شرط. اگر بخواهم ساده بگویم، همان کاری که WHERE در SQL میکند. فرض کن یک Relation داریم به اسم Students. وقتی میگوییم «دانشجوهایی که معدلشان بالای ۱۸ است»، در جبر رابطهای داریم یک Selection انجام میدهیم. خروجی این کار نه یک لیست، نه یک فایل، بلکه یک Relation جدید است که فقط بعضی از Tupleها را دارد.
یا عملگر Projection. Projection یعنی انتخاب بعضی ستونها. مثلاً میگویی «از جدول دانشجوها فقط نام و ایمیل را میخواهم». این دقیقاً Projection است. باز هم خروجی یک Relation جدید است؛ با Attributeهای کمتر، ولی همچنان یک Relation کامل.
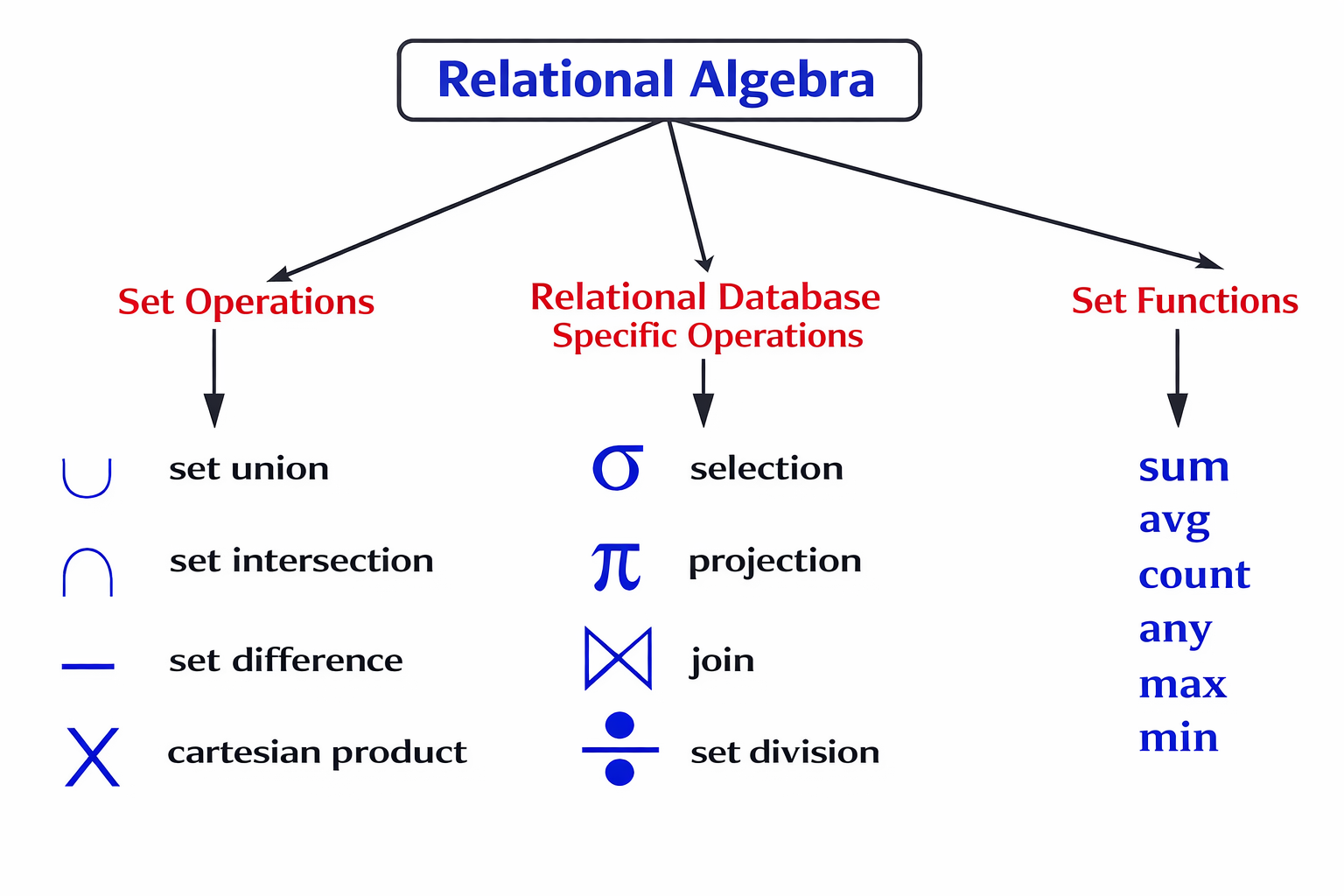
جایی که داستان جالبتر میشود، وقتی چند Relation را با هم ترکیب میکنیم. مثلاً Cartesian Product که معمولاً اسمش ترسناک به نظر میرسد، در اصل یعنی ترکیب هر Tuple از یک Relation با هر Tuple از Relation دیگر. Joinهایی که ما هر روز مینویسیم، در نگاه جبر رابطهای، چیزی نیستند جز ضرب دکارتی به اضافهی Selection. اگر ضرب دکارتی، جبر، رابطه یا جبر رابطه ای رو دقیق نمیتونیم درک کنیم معانیش رو، معنیش این نیست باید این فیلد رو رها کنیم. در بخش بعدی (قسمت 2)، سعی کردم تعاریف دقیق از این کلید واژه ها رو داشته باشیم. آقای کاد در مقالههای بعدیاش (اوایل دههی ۷۰ میلادی) دقیقاً روی همین تجزیهی Join تأکید میکند تا نشان بدهد اینها مفاهیم مستقل نیستند، بلکه از چند عمل ساده ساخته شدهاند.
یک نکتهی مهم این وسط هست که معمولاً کمتر بهش توجه میکنیم: SQL خودِ جبر رابطهای نیست. SQL از جبر رابطهای الهام گرفته، ولی کاملاً با آن یکی نیست. SQL تکرار دارد، ترتیب دارد، NULL دارد و به پیادهسازی وابسته است. اما جبر رابطهای کاملاً صوری و تمیز است. در واقع، وقتی شما یک کوئری SQL مینویسید، موتور پایگاه داده آن را به یک نمایش داخلی شبیه به جبر رابطهای تبدیل میکند و بعد تازه میرود سراغ اجرا.
و این دقیقاً همان چیزی است که آقای کاد دنبالش بود. او در مقالات سالهای ۱۹۷۰ تا ۱۹۷۲ بارها روی مفهوم استقلال منطقی داده تأکید میکند. یعنی برنامهنویس باید بتواند بگوید «چه دیتایی میخواهم»، نه اینکه مجبور باشد بداند «دیتا دقیقاً کجای دیسک و با چه ساختاری ذخیره شده». جبر رابطهای ابزار این نوع فکر کردن است. البته این موضوع برای معمارها نیست ها. معمار پایگاه داده باید دقیق بدونه که سیستم چگونه کار میکنه. برنامه نویس ما، تاکید دارم که صرفاً برنامه نویس و توسعه دهنده ما نیاز به عمیق شدن زیاد در این حوزه ندارد.
اگر بخواهم تجربهی شخصیام را بگم، جبر رابطهای چیزی نیست که هر روز بنشینیم و فرمولهایش را بنویسیم. اما وقتی آن را بفهمید، یک اتفاق جالب میافتد:
کوئریهای بد را زودتر تشخیص میدهید، Joinهای بیمنطق توی ذوقتان میزند، و طراحی دیتابیس برایتان از «حس شهودی» تبدیل میشود به «تصمیم آگاهانه».
در نهایت، جبر رابطهای میراث فکری کسی است که قبل از همه فهمید پایگاه داده فقط محل ذخیرهی اطلاعات نیست، بلکه یک سیستم فکری است. اگر بخواهیم معماری داده را جدی بگیریم، راهی نداریم جز اینکه حداقل یک بار، عمیق و درست، این زبان زیرساختی را بفهمیم؛ زبانی که پایگاه داده واقعاً با آن فکر میکند.
وقتی از «جبر» حرف میزنیم، منظورمان یک سری عمل و قانون است که روی یکسری اشیاء مشخص انجام میشود و نتیجهی قابل پیشبینی میدهد.
مثلاً در جبر عددی، ما عدد داریم و عملگرهایی مثل جمع و ضرب. در جبر رابطهای هم دقیقاً همین اتفاق میافتد، فقط بهجای عدد، با «رابطه» کار میکنیم.
پس جبر یعنی:
مجموعهای از عملگرها + قوانینی که مشخص میکنند این عملگرها چطور روی دادهها اعمال شوند.
اینجا معمولاً اولین سوءتفاهم شکل میگیرد.
رابطه از دید پایگاه داده رابطهای فقط یک جدول ظاهری نیست.
در تعریف رسمی، رابطه یک مجموعه از تاپلهاست.
Tuple (تاپل) یعنی یک رکورد کامل؛ چیزی که ما معمولاً بهش میگیم «یک سطر»
Attribute (ویژگی) یعنی یک ستون؛ مثل نام، سن، ایمیل
کل رابطه یعنی یک مجموعه از این تاپلها
یک نکتهی مهم رو داشته باشیم اینجا اینکه رابطه مجموعه است، نه لیست. یعنی ترتیب سطرها اهمیتی نداره و تکرار مفهومی ندارد (حتی اگر در SQL ببینیم). این نگاه دقیقاً همان چیزی است که آقای کاد روی آن تأکید داشت.
حالا که جبر و رابطه را جداگانه فهمیدیم، تعریف مشهور جبر رابطهای خیلی تمیز میشود. من اینطور میگم:
جبر رابطهای مجموعهای از عملگرهای صوری است که روی روابط تعریف میشوند و نتیجهی هر عملگر نیز یک رابطه است.
این جمله شاید ساده به نظر برسد، اما یک مفهوم بسیار مهم داخلش خوابیده:
خاصیت بستهبودن (Closure)
یعنی هر کاری روی داده انجام بدیم، باز هم در دنیای Relation باقی میمانیم. همین ویژگی است که امکان ترکیب عملیات، بازنویسی و بهینهسازی را میدهد.
در سیستمهای پایگاه داده رابطهای، جبر رابطهای زبان اجرایی نیست؛ زبان فکری است. یعنی چی؟ یعنی اینکه شما با SQL حرف میزنید، اما پایگاه داده در لایههای داخلی، کوئری شما را به چیزی شبیه جبر رابطهای تبدیل میکند و بعد تصمیم میگیرد چطور آن را اجرا کند.
به بیان سادهتر:
SQL چیزی است که شما مینویسید،
جبر رابطهای چیزی است که دیتابیس میفهمد.
این دقیقاً همون چیزی است که آقای کاد در مقاله معروفش در سال ۱۹۷۰ و مقالات بعدیاش در اوایل دههی ۷۰ میلادی مطرح کرد؛ برای رسیدن به استقلال منطقی داده. اصلاً موضوع داره به صراحت در مقاله بیان میشه.
فرض کنیم یک Relation داریم به اسم Students با این Attributeها:StudentID, Name, Age, GPA
Selection یعنی فیلتر کردن تاپلها بر اساس شرط.
اگر بگیم:
«دانشجوهایی که معدلشان بالای ۱۸ است»
از دید جبر رابطهای:
ما داریم روی Relation Students یک Selection انجام میدهیم و خروجیاش یک Relation جدید است که فقط بعضی تاپلها را دارد.
از نظر ذهنی خیلی شبیه این است:
SELECT * FROM Students WHERE GPA > 18;
Projection یعنی انتخاب بعضی Attributeها.
مثلاً میگیم:
«از دانشجوها فقط نام و معدل را میخواهم»
در این حالت:
تعداد ستونها کم میشود
ولی همچنان خروجی یک Relation معتبر است
معادل ذهنی SQL:
SELECT Name, GPA FROM Students;
Union یعنی ترکیب دو Relation همساختار.
فرض کنیم:
PassedStudents
ExcellentStudents
اگر Union بگیریم:
همهی دانشجوهایی که یا پاس شدهاند یا ممتازند، در یک Relation جدید جمع میشوند.
Difference یعنی کم کردن یک Relation از Relation دیگر.
مثلاً:
«دانشجوهایی که ثبتنام کردهاند ولی هنوز پاس نشدهاند»
از نظر مفهومی:
یک Relation را از دیگری کم میکنیم و خروجی باز هم یک Relation است.
دوستان اینجا معمولاً همه میترسند، ولی در اصل مفهومش ساده است. همون موضوعی که در بخش قبلی گفتم یک مثال میزنیم تا راحت تر بشه فهمش.
اگر Relation Students و Relation Courses را ضرب دکارتی کنیم:
هر دانشجو با هر درس ترکیب میشود
خروجی شامل تمام ترکیبهای ممکن است
Joinهایی که هر روز مینویسیم، در واقع:
ضرب دکارتی + Selection هستند
کاد دقیقاً برای همین این عملگر را پایهای در نظر گرفت.
Rename برای وقتی است که:
اسم Relation یا Attributeها را عوض میکنیم
تا در ترکیب عملیاتها دچار ابهام نشویم
این عملگر ساده، ولی در جبر رابطهای بسیار حیاتی است.
خب حالا اطلاعات بالا رو داشته باشیم. میخوام یک مثال دیگر بزنم ببینیم موضوع چی هست. فرض میکنیم دو تا جدول داریم به نام های Students برای نگهداری اطلاعات دانشجو ها مشتمل بر ستون های شناسه، نام و رشته. جدول دیگری داریم بنام Enrollments برای نگهداری اطلاعات دروس دانشجو ها مشتمل بر ستون های شناسه، شناسه ارتباطی دانشجو، درس و نمره.
حالا بریم سراغ اطلاعات موجود در جداول:
در جدول Students داریم:
1) شناسه: 1 | نام: علی | رشته: کامپیوتر
2) شناسه: 2 | نام: سارا | رشته: برق
3) شناسه: 3 | نام: سحر | رشته: کامپیوتر
در جدول Enrollments داریم:
1) دانشجو: 1 | درس: پایگاه داده | نمره: 18
2) دانشجو: 2 | درس: سیستم عامل | نمره: 15
3) دانشجو: 3 | درس: پایگاه داده | نمره: 19
سوال: اسم دانشجوهایی که رشتهشون کامپیوتر هست و درس پایگاه داده رو گرفتن رو پیدا کن.
SELECT S.name FROM Students S JOIN Enrollments E ON S.sid = E.sid WHERE S.major = 'CS' AND E.course = 'DB';
توجه داشته باشیم که name یعنی نام دانشجو، CS یعنی رشته کامپیوتر Computer Science و DB یعنی درس پایگاه داده و sid شناسه دانشجو ها میباشد.
حالا میریم معادل در جبر رابطهای (Relational Algebra) ها رو داشته باشیم:
انتخاب دانشجویان رشته کامپیوتر: σ major=′CS′(Students)
انتخاب ثبت نامهای درس پایگاه داده σ course=′DB′(Enrollments)
جوین روی شناسه ها σ major=′CS′(Students) ⋈ Students.sid=Enrollments.sid σ course=′DB′(Enrollments)
پروجکشن روی نام ها π name(σ major=′CS′(Students) ⋈ Students.sid=Enrollments.sid σ course=′DB′(Enrollments))
دوستان خواهش میکنم عنایت ویژه بفرمایید ببینید چه اتفاقی در حال رخ دادن هست. معادل و تطبیق مفهومی SQL و جبر رابطهای رو باهم داشته باشیم:
WHERE در SQL معادل σ (selection) در جبر رابطه ای
SELECT ستونها در SQL معادل π (projection) در جبر رابطه ای
JOIN در SQL معادل ⨝ (join) در جبر رابطه ای
FROM در SQL معادل رابطههای ورودی در جبر رابطه ای
پس در نتیجه اگر یک معمار با مطالعه موضوعات فوق بخواهد برای خودش یک جمع بندی داشته باشه، میگه:
SQL در اصل یک زبان اعلانی (Declarative) است،
اما در پشت صحنه، موتور دیتابیس کوئری را به جبر رابطهای تبدیل میکند.
یعنی:
ما در SQL میگیم«چی میخوام» و دیتابیس با جبر رابطهای تصمیم میگیره «چطوری بهش برسم»
جبر رابطهای به ما یاد میدهد چطور درباره داده فکر کنیم، نه فقط چطور از آن اطلاعات بکشیم بیرون. این همان دیدی است که آقای کاد بیش از پنجاه سال پیش مطرح کرد و هنوز هم ستون فقرات پایگاه دادههای رابطهای است. اگر این لایه را بفهمید، SQL برایتان شفافتر میشود، طراحی دیتابیستان منطقیتر میشود و مهمتر از همه، دیگر با پایگاه داده «کورکورانه» کار نمیکنید.
این مقاله اساساً میگه:
کاربر نباید درگیر این باشه که دادهها توی کامپیوتر چطوری ذخیره شدن.
آقای ادگار کاد از همون اول دست میذاره روی یه مشکل جدی سیستمهای دیتابیس قدیمی:
اگه ساختار ذخیرهسازی دادهها عوض بشه (مثلاً ترتیب، ایندکس، یا مسیر دسترسی)، کلی برنامه و گزارش از کار میافتن و این فاجعهست.
سیستمهای قدیمی (درختی و شبکهای مثل IMS و IDS) سه تا وابستگی خطرناک داشتن:
وابستگی به ترتیب دادهها
برنامهها فرض میکردن دادهها به یه ترتیب خاص ذخیره شدن. ترتیب عوض میشد؟ برنامه میترکید.
وابستگی به ایندکسها
ایندکس که باید فقط برای سرعت باشه، عملاً میشد جزئی از منطق برنامه.
وابستگی به مسیر دسترسی (Access Path)
برنامهها دقیقاً میدونستن از چه مسیری به داده برسن.
ساختار عوض میشد؟ برنامه دیگه نمیفهمید داده کجاست.
اقای کاد پیشنهاد میده دادهها رو نه به شکل درخت و شبکه، بلکه به شکل Relation (رابطه) ببینیم؛ چیزی شبیه جدول:
هر سطر = یک رکورد
هر ستون = یک ویژگی
ترتیب سطرها مهم نیست
حتی ترتیب ستونها هم برای کاربر نباید مهم باشه
میگه کاربر فقط باید بدونه:
اسم جدول چیه
ستونهاش چیان
معنی دادهها چیه
و نه اینکه «چطوری ذخیره شدن». خیلی روی این موضوع تاکید داره.
آقای کاد خیلی شفاف مفاهیمی رو تعریف میکنه که امروز بدیهیان:
کلید اصلی (Primary Key): چیزی که هر رکورد رو یکتا میکنه
کلید خارجی (Foreign Key): اشاره به کلید اصلی یه جدول دیگه
و میگه رابطهها میتونن به هم ارجاع بدن، بدون اینکه ساختار فیزیکی به کاربر تحمیل بشه. همین حرف شده امروز استاندارد اصلی پایگاه داده های رابطه ای.
یکی از بخشهای مهم مقاله همینه:
آقای کاد میگه:
جدول خوب، جدولی هست که توش ستونهای چندمقداری و تودرتو نداشته باشیم.
راهحل:
دادههای تودرتو رو جدا کن
کلیدها رو بیار پایین
جدولها رو ساده و اتمیک کن
نتیجه چی میشه اون موقع؟ مشخص هست دیگه؛
ذخیرهسازی سادهتر میشه
انتقال داده راحتتر میشه
ناسازگاری کمتر به وجود میاد
آقای کاد یه ایدهی جسورانه میده:
یه زبان عمومی برای کار با دادهها، بر پایه منطق و Predicate Calculus
چیزی که بعدها الهامبخش SQL شد.
ویژگی مهمش؟
هر رابطه رو میتونی از هر سمتی پرسوجو کنی
لازم نیست مسیر دسترسی رو حفظ باشی
فقط بگو چی میخوای، نه چطور بهش برسی
آقای کاد بین دو نوع افزونگی فرق میذاره:
افزونگی قوی: دادهای که کاملاً از دادههای دیگه قابل محاسبهست
افزونگی ضعیف: دادهای که همیشه وابستهست، ولی دقیقاً قابل محاسبه نیست
و تأکید میکنه:
سیستم باید بتونه ناسازگاریها رو تشخیص بده، حتی اگه موقت باشن.
این مقاله پایهی دیتابیسهای مدرنه. حرف اصلیش اینه:
کاربر نباید اسیر جزئیات ذخیرهسازی بشه
داده باید مستقل از برنامه باشه
رابطهها از مسیرها مهمترن
سادگی منطقی، از بهینهسازی فیزیکی مهمتره
تقریباً هر چیزی که امروز تو دیتابیسهای رابطهای بدیهیه، اولینبار تو همین مقاله گفته شده. معماران و تحلیل گران عزیزمون، این اطلاعات پایه، حتما در کَرییر کاری شما تاثیر گذار خواهند بود.