سلام. وقتی با حجم زیادی دیتا سر و کار داشته باشیم و بخواهیم روش جستجوی درستوحسابی پیاده کنیم، احتمالاً یا مستقیم یا غیرمستقیم کارمون به Lucene خواهد خورد.
Lucene در اصل یه کتابخونهی جستجوی متن (Full-Text Search) هست که توسط Apache توسعه داده میشه و تمرکزش روی اینه که «جستجو سریع، دقیق و قابلکنترل» باشه. نه بیشتر، نه کمتر. یعنی خودش ادعا نمیکنه یه محصول آمادهست، بلکه ابزار میده دستتمون تا خودمون سیستم جستجویی که میخواهیم رو بسازیم.
Lucene به زبان Java نوشته شده و از همون اول هم با این ذهنیت طراحی شده که بتونه روی حجم خیلی زیاد داده جواب بده. چیزی که تو مستندات رسمی خیلی روش تأکید شده اینه که Lucene قراره هستهی جستجو باشه، نه کل سیستم. یعنی خبری از UI، REST API یا دیپلوی آماده نیست؛ اینا چیزاییه که باید خودمون بسازیم یا ابزارهای بالادستی برامون فراهم کنند.
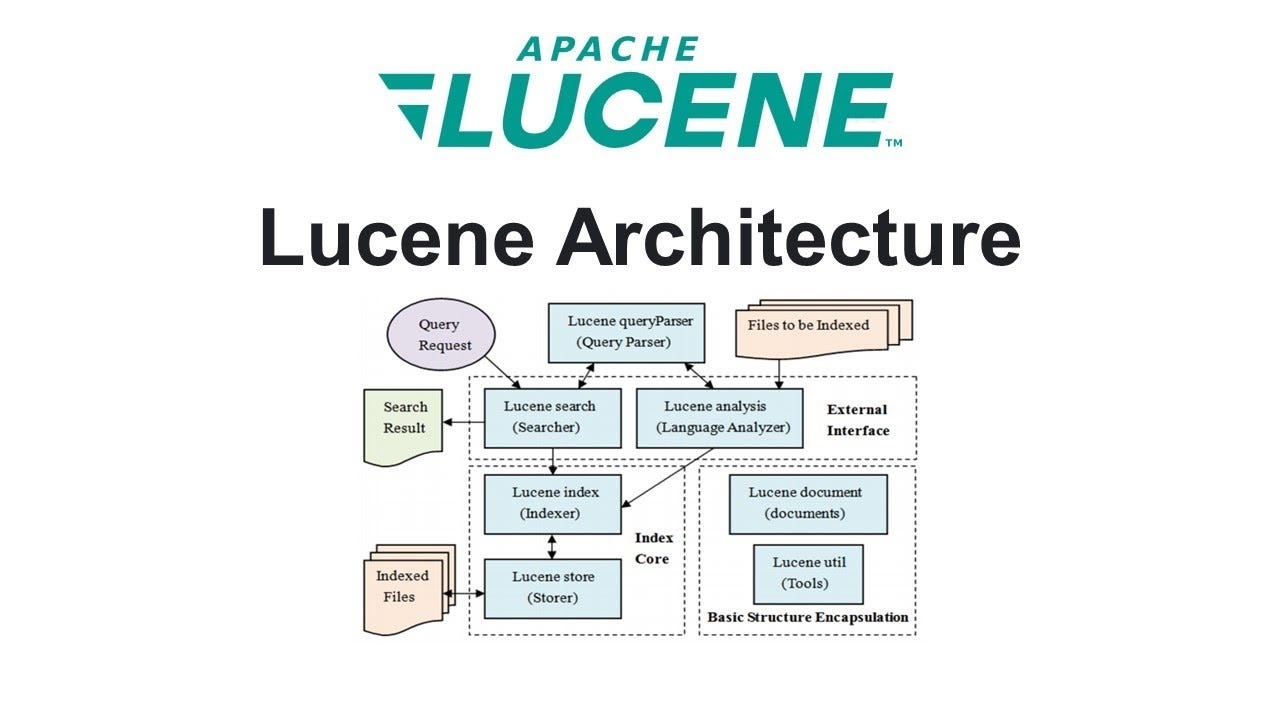
Lucene کارش دو تا چیز اصلیه:
ایندکسکردن و جستجو کردن.
اول دادهها (معمولاً متن) رو میگیری، بهش میگی چجوری تحلیل بشن (Analyzer)، بعد Lucene ازشون یه ساختار بهینه میسازه که اسمش هست Index. بعدش هر وقت کاربر یا سیستم یه Query میفرسته، Lucene خیلی سریع میره سراغ همون ایندکس و نتایج مرتبط رو برمیگردونه. نکتهی مهم اینه که Lucene اصلاً قرار نیست مثل دیتابیس رکورد به رکورد بگرده؛ کل فلسفهاش اینه که از قبل همهچی رو آماده کرده.
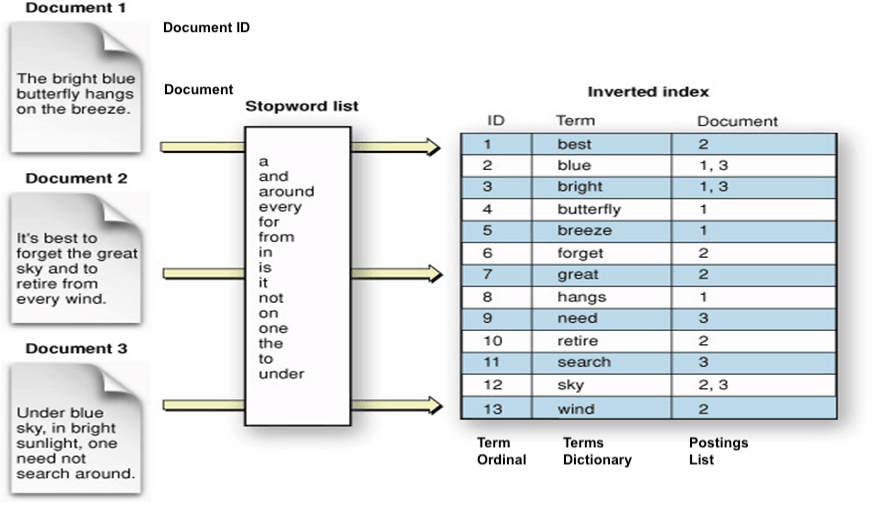
هستهی اصلی Lucene چیزی به اسم Inverted Index هست. اگر بریم برای بررسی عمیق موضوع:
بهجای اینکه بگه «این سند چه کلماتی داره»، میگه «این کلمه تو کدوم سندها اومده».
مثلاً بهجای اینکه برای کلمهی «معماری» کل دیتاست رو بگرده، مستقیم میدونه این کلمه تو چه سندهایی وجود داره و حتی چند بار تکرار شده. همین نگاه معکوسه که باعث میشه Lucene بتونه روی میلیونها سند هم جستجوی سریع انجام بده، بدون اینکه به CPU و I/O فشار زیادی بیاد.

Lucene فرض نمیکنه متن خام همون چیزیه که باید ایندکس بشه. قبل از ایندکس، متن میره توی یه مرحله به اسم Analysis. اینجا اتفاقاتی مثل اینا میافته:
شکستن متن به Token
حذف Stop Wordها
نرمالسازی حروف
Stemming یا Lemmatization
Stemming یعنی اینکه کلمه رو با یهسری قواعد مکانیکی کوتاه کنی تا به یه ریشهی تقریبی برسی. مثل این میمونه که واژه «running» رو تبدیل میکنه به «run» یا واژه «connection» رو تبدیل میکنه به «connect».
Lemmatization یه قدم جلوتره. اینجا سیستم سعی میکنه کلمه رو به شکل پایهی واقعی زبان (lemma) برسونه، با در نظر گرفتن:
نقش دستوری (اسم، فعل، صفت)
ساختار زبانی
گاهی context جمله
مثل این میمونه که واژه «better» رو تبدیل میکنه به «good». اینجا خروجی حتماً یه کلمهی معتبر زبانیه. کندتر از stemming هست و اینکه Lucene به صورت پیش فرض از Stemming استفاده میکنه.
همهی اینا با چیزی به اسم Analyzer کنترل میشه. چیزی که مستندات Lucene روش خیلی تأکید دارن اینه که انتخاب Analyzer درست، نصف کیفیت جستجوی شماست. اگه اینجا اشتباه کنی، بهترین Queryها هم نجاتمون نمیدن. باید دقت کافی رو داشته باشیم.
برخلاف چیزی که خیلیها فکر میکنن، Query تو Lucene فقط یه match ساده نیست. Query میتونه شامل کلی منطق باشه:
منطق phrase query
منطق fuzzy search
منطق wildcard
منطق range query
منطق Boolean logic
Lucene این Queryها رو میگیره، میبره روی Index، بعد با الگوریتمهای رتبهبندی (مثل BM25) نتایج رو امتیازدهی میکنه. یعنی خروجی صرفاً «پیدا شد / نشد» نیست؛ یه لیست مرتبشده از مرتبطترین نتایجه. یکم بیشتر در مورد الگوریتم BM25 صحبت کنیم بچه ها.
BM25 (که اسم کاملترش Okapi BM25 هست) یه الگوریتم رتبهبندی نتایج جستجوئه.
یعنی وقتی کاربر یه Query میزنه و چند تا سند match میشن، BM25 تصمیم میگیره:
«کدوم نتیجه واقعاً به درد این کاربر میخوره و باید بالاتر نمایش داده بشه؟»
تو دنیای واقعی، این یعنی تفاوت بین:
«یه چیزی پیدا شد»
و «همونی که دنبالش بودم پیدا شد»
خب Lucene داره از BM25 استفاده میکنه و دوستانی که میخوان اطلاعات بیشتری در این حوزه کسب کنند، پیشنهاد میکنم این رو بررسی کنند.
Index تو Lucene یه فایل بزرگ یکتکه نیست. از چند تا Segment تشکیل شده که هر کدوم مستقلن. این طراحی باعث میشه:
نوشتن و خواندن همزمان راحتتر بشه
ایندکسسازی Incremental باشه
Performance تو حجم بالا حفظ بشه
Lucene خودش مدیریت merge شدن segmentها رو انجام میده، ولی مستندات رسمی بارها میگن که اگه تو محیط production هستی، باید بدونی این mergeها چه زمانی و با چه هزینهای انجام میشن.
ما معمولا Lucene رو باید در جایی استفاده کنیم که:
دیتاهامون زیاده، جستجو مهمتر از CRUD سادهست، میخواییم روی relevance و ranking کنترل داشته باشیم، حاضر هستیم معماری جستجو رو خودمون طراحی کنی از ابتدا. به همین خاطره که خیلی از سیستمهای معروفتر مثل Elasticsearch یا Solr، در واقع اومدن روی Lucene سوار شدن و لایههای بالادستی بهش اضافه کردن.