سلام؛ دوستان میخوام یک مقدمه خیلی جزئی از بحث Page ها در دیتابیس رو مورد بررسی قرار بدیم و ببینیم که پشت پرده Read و Write که روی دیسک میشه، چه خبره.
وقتی از دیتابیس حرف میزنیم، معمولاً ذهنمان میرود سمت جدولها، سطرها و کوئریها. انگار دیتابیس یک فایل اکسل بزرگ است که فقط خیلی سریع تر و جذاب تر کار میکند. اما واقعیت این است که دیتابیسها خیلی پایینتر از این لایه فکر میکنند.
آنها نه «سطر» میشناسند و نه «جدول»؛ چیزی که برایشان معنا دارد، Page است. اگر بخواهیم صادق باشیم، Page همان جایی است که دیتابیس واقعاً زندگی میکند. دیتابیسها از ابتدا با یک چالش بزرگ روبهرو بودهاند: دیسک. دسترسی به دیسک، حتی در بهترین SSDها، در مقایسه با حافظه اصلی بسیار کند است.
اگر قرار بود دیتابیس برای خواندن هر رکورد یا حتی هر جدول، مستقیم به دیسک مراجعه کند، عملاً هیچ سیستم جدیای نمیتوانست روی آن حساب کند.
همینجا بود که مفهوم Page بهوجود آمد؛ یک واحد میانی، نه خیلی بزرگ و نه خیلی کوچک، که دیتابیس بتواند دادهها را در قالب آن جابهجا کند. Page در سادهترین تعریف، کوچکترین واحدی است که دیتابیس حاضر است آن را از دیسک بخواند یا روی دیسک بنویسد.
این نکته خیلی مهم است، چون یعنی دیتابیس هیچوقت نمیگوید «این یک Row را بده». همیشه میگوید «Page مربوط به این Row را بده». حتی اگر فقط یک ستون از یک سطر را بخواهید، دیتابیس مجبور است کل Page را وارد حافظه کند.
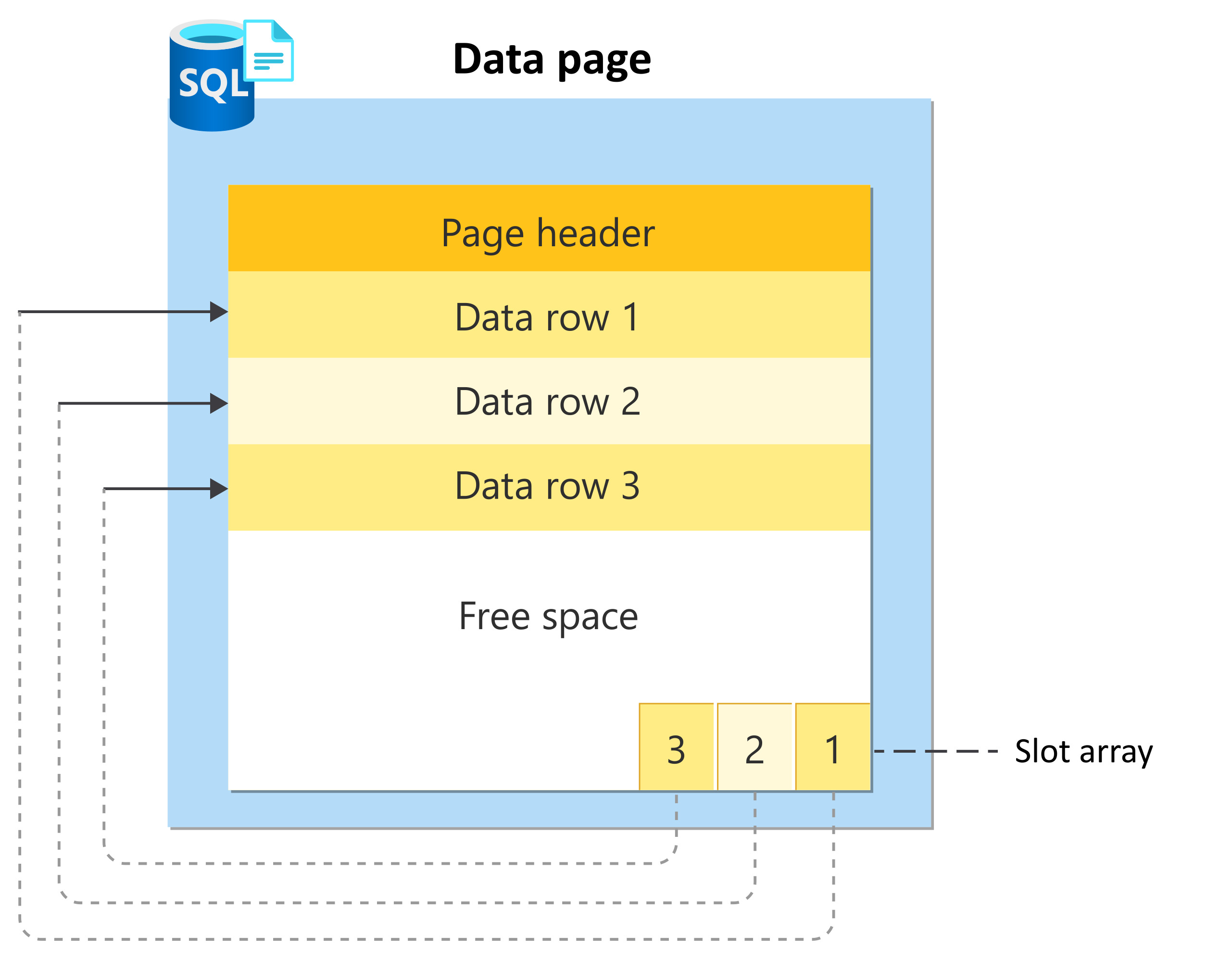
این تصمیم شاید در نگاه اول عجیب به نظر برسد، اما دقیقاً همان چیزی است که دیتابیس را سریع و قابل اعتماد کرده است. وقتی یک Query اجرا میشود، اولین کاری که دیتابیس انجام میدهد این نیست که دنبال داده بگردد؛ اول دنبال Page میگردد. بررسی میکند که آیا Page موردنظر قبلاً در حافظه هست یا نه. اگر باشد، عملاً به دیسک کاری ندارد و پاسخ خیلی سریع برمیگردد. اگر نباشد، باید Page را از دیسک بخواند و وارد حافظه کند.
اینجاست که اهمیت چیزی به نام Buffer Pool یا Shared Buffers مشخص میشود؛ جایی که دیتابیس Pageها را نگه میدارد تا مجبور نباشد هر بار به دیسک مراجعه کند. نکتهای که معمولاً در آموزشهای سطحی دیتابیس گفته نمیشود ولی میخوام در این بخش اشاره کنم این است که Page فقط شامل دادههای جدول نیست. خود دیتابیس هم اطلاعات کنترلی، متادیتا، ایندکسها و حتی وضعیت فضای خالی را در قالب Page ذخیره میکند. یعنی از نگاه دیتابیس، همهچیز Page است. جدول، ایندکس و حتی لاگها، همگی روی همین مفهوم سوار شدهاند.
به همین خاطر است که وقتی میگوییم «دیتابیس کند شده»، در واقع داریم درباره رفتار Pageها صحبت میکنیم، نه صرفاً کوئریها. ارتباط بین Row و Page هم یکی از آن جاهایی است که اگر درکش نکنیم، خیلی از رفتارهای عجیب دیتابیس برایمان بیمنطق به نظر میرسد. Rowها داخل Pageها جا میگیرند و هر Page میتواند چندین Row را در خودش نگه دارد.
حالا اگر Rowهای ما بزرگ باشند، مثلاً ستونهای زیاد یا فیلدهای متنی حجیم داشته باشند، طبیعتاً تعداد کمتری Row در هر Page جا میشود. نتیجهاش این است که برای خواندن همان تعداد داده، دیتابیس مجبور میشود Pageهای بیشتری را از دیسک یا حافظه عبور دهد. این یعنی هزینه بیشتر، هم از نظر I/O و هم از نظر مصرف حافظه. ایندکسها هم دقیقاً از همین منطق پیروی میکنند. وقتی از B-Tree یا ساختارهای مشابه استفاده میکنیم، هر گره درخت در واقع یک Page است. حرکت کردن در ایندکس، یعنی پریدن از یک Page به Page دیگر. به همین دلیل است که عمق ایندکس، میزان Fragmentation و حتی ترتیب درج دادهها میتواند تأثیر مستقیم روی سرعت کوئری داشته باشد. دیتابیس در حال دنبال کردن اشارهگرهای Page است، نه سطرهای انتزاعی که ما در سطح SQL میبینیم.
با گذشت زمان و با عملیات مداوم Insert، Update و Delete، پیج ها کمکم نظم اولیهشان را از دست میدهند. بعضی Pageها نصفهپر میشوند، بعضی جاها دادهها پراکنده میشوند و دیتابیس برای رسیدن به یک نتیجه ساده مجبور میشود Pageهای بیشتری را بررسی کند. این همان چیزی است که به آن Fragmentation میگوییم؛ مشکلی که روی کاغذ ساده به نظر میرسد، اما در عمل میتواند یک سیستم سالم را به یک سیستم کند و پرهزینه تبدیل کند. شاید در نهایت مهمترین نکته این باشد که Page به ما یاد میدهد دیتابیس چطور فکر میکند. دیتابیسها موجودات منطقی هستند که با محدودیتهای سختافزار کنار آمدهاند. این عزیزان به جای اینکه دنبال ایدهآلترین حالت مفهومی باشند، دنبال کمهزینهترین جابهجایی داده هستند. وقتی این را بفهمیم، خیلی از تصمیمهایمان در طراحی دیتابیس تغییر میکند؛ از انتخاب نوع ستونها گرفته تا نحوه ایندکسگذاری و حتی شکل نوشتن Queryها. اگر بخواهیم جمعبندی کنیم، Page همان لایهای است که دنیای انتزاعی SQL را به دنیای واقعی سختافزار وصل میکند. جایی بین حافظه و دیسک، جایی که تصمیمهای کوچک میتوانند تأثیرهای بزرگ بگذارند. تا وقتی Page را نفهمیم، دیتابیس را فقط از روی ظاهرش قضاوت کردهایم؛ اما وقتی وارد دنیای Pageها میشویم، تازه میفهمیم چرا دیتابیسها اینقدر پیچیده، و در عین حال اینقدر هوشمند طراحی شدهاند.
اگر فرصت کنم و خدا بخواد، در مقاله بعدی اول در مورد ساختار فنی Page ها و قسمت های تشکیل دهنده اون رو مورد بررسی قرار میدیم. بعد اگر فرصت شد میریم سراغ Page های BCM و DCM و سپس در مورد Concurrency و Page locking میخوام باهم صحبت کنیم و بررسی کنیم و درخواست ها به صورت هم زمان میریزه سر دیتابیس، چه اتفاقاتی رخ میده. حتما میخوام در مورد Page های GAM و SGAM هم یه صحبتی داشته باشیم و اینکه PFS چه نقشی در این وسط داره بازی میکنه. معماری زیرین رو در کل بررسی خواهیم کرد انشاا...