منابع ارائه شده یک نمای کلی جامع از انواع و تکامل معماریهای اصلی شبکههای عصبی عمیق فراهم میآورند. این شبکهها با اجزای پایهای مانند لایههای پنهان (Hidden Layers) و توابع فعالسازی (Activation Functions) ساخته شدهاند و از شبکههای بنیادی پیشخور (FNNs) که جریان اطلاعاتی یکسویه دارند، شروع میشوند. مدلهای تخصصیتر شامل شبکههای عصبی کانولوشنی (CNNs) هستند که برای دادههای شبکهای مانند تصاویر طراحی شدهاند و از قابلیت اشتراک وزن (Weight Sharing) برای استخراج سلسله مراتب ویژگیها استفاده میکنند. اگرچه شبکههای عصبی بازگشتی (RNNs) در ابتدا برای دادههای توالیمحور توسعه یافتند، اما معماریهای پیشرفتهای نظیر LSTM برای حل مشکل گرادیان ناپدیدشونده (vanishing gradient problem) در آنها پدیدار شدند. با این حال، در کاربردهای مدرن NLP، ترنسفورمرها (Transformers) به دلیل مقیاسپذیری و قابلیت پردازش موازی از طریق مکانیسم توجه به خود (self-attention)، کارایی بالاتری نسبت به RNNها در مدیریت وابستگیهای دوربرد (long-range dependencies) از خود نشان دادهاند. در نهایت، شبکههای عصبی گرافی (GNNs) از یک مکانیزم انتقال پیام (message-passing mechanism) برای تحلیل ساختارهای دادهای نامنظم استفاده میکنند و برای تحلیل شبکههای اجتماعی و سیستمهای توصیهگر حیاتی هستند.
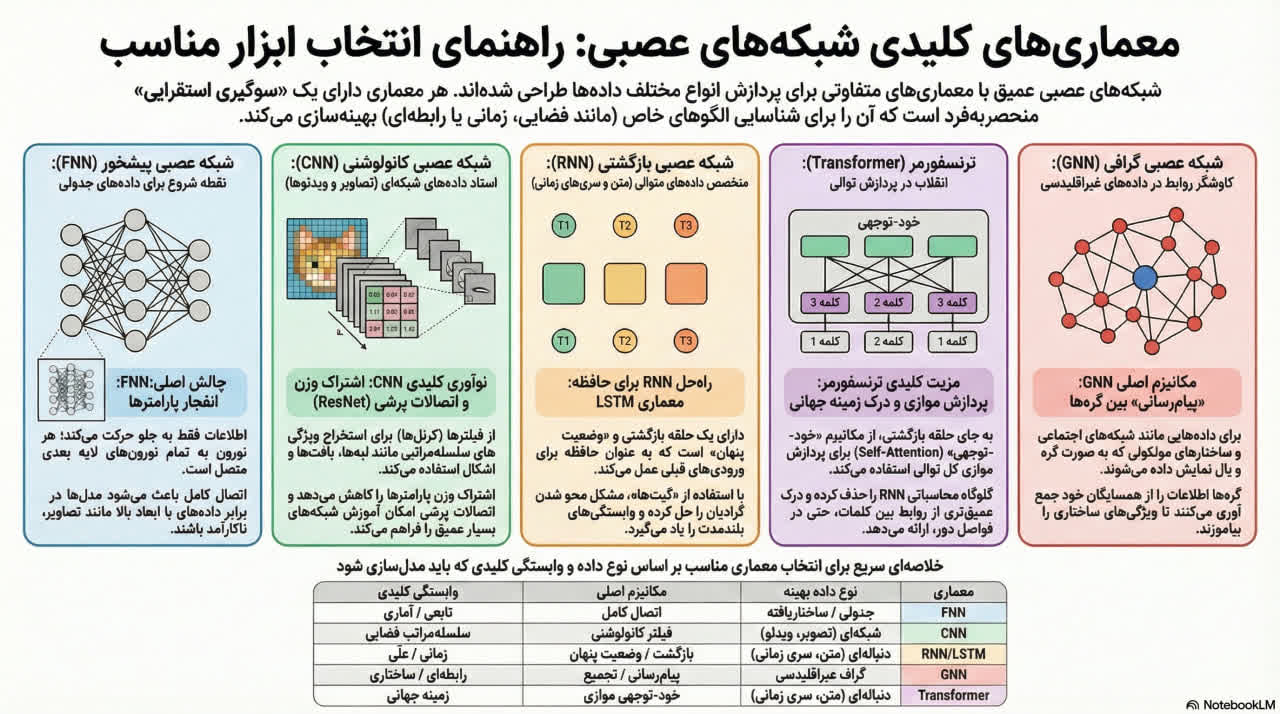
اثربخشی یک شبکه عصبی عمیق به همسوسازی معماری و "بایاس استقرایی" (inductive bias) آن با ساختار ذاتی دادههای ورودی بستگی دارد. این تحلیل، تکامل معماریهای بنیادی (FNN، CNN، RNN و GNN) و نوآوریهای نظری کلیدی که موفقیت آنها را ممکن ساخت، ردیابی میکند. این معماریها که هر یک برای نوع خاصی از داده بهینه شدهاند، سنگ بنای یادگیری عمیق مدرن را تشکیل میده دهند.
مخفف
نام کامل
نوع داده بهینه
مکانیسم اصلی
وابستگی غالب
FNN
شبکه عصبی پیشخور (Feedforward Neural Network)
دادههای جدولی/ساختاریافته
اتصال کامل (Full Connectivity)
تابعی/آماری
CNN
شبکه عصبی کانولوشنی (Convolutional Neural Network)
دادههای شبکهای (تصویر، ویدئو)
فیلترینگ کانولوشنی
سلسلهمراتب فضایی
RNN
شبکه عصبی بازگشتی (Recurrent Neural Network)
دادههای توالی (متن، سری زمانی)
بازگشت/حالت پنهان
زمانی/عِلّی
GNN
شبکه عصبی گراف (Graph Neural Network)
دادههای گراف غیراقلیدسی
ارسال پیام/تجمیع
رابطهای/ساختاری
مفهوم "مهندسی محدودیت معماری" (architectural constraint engineering) در قلب تکامل یادگیری عمیق قرار دارد. معماریهای موفق مانند CNN و RNN، اتصالات عمومی و پرپارامتر را با محدودیتهای تخصصی جایگزین میکنند تا کارایی و عملکرد را بهبود بخشند. به عنوان مثال، CNN با مهندسی محدودیت اشتراک وزن (weight sharing)، بایاس استقرایی هموردایی انتقالی (translational equivariance) را در معماری خود تعبیه میکند، در حالی که RNN با اتصالات بازگشتی مشترک در طول زمان، بایاس علیت زمانی (temporal causality) را اعمال میکند. این استراتژی به شبکههای تخصصی اجازه میدهد تا با پارامترهای بسیار کمتر، عملکردی برتر نسبت به یک شبکه کاملاً متصل و بدون محدودیت داشته باشند. این تحلیل با بررسی معماری بنیادین و در عین حال محدود شبکههای عصبی پیشخور آغاز میشود.
شبکههای عصبی پیشخور (FNN) که با نام پرسپترونهای چندلایه (MLP) نیز شناخته میشوند، سادهترین معماری یادگیری عمیق هستند که با جریان یکطرفه اطلاعات از لایه ورودی به خروجی و اتصال کامل بین لایهها مشخص میشوند. اهمیت استراتژیک آنها در این است که به عنوان بلوک سازنده اساسی برای بسیاری از مدلهای پیچیدهتر عمل میکنند و پایه و اساس درک سایر معماریها را تشکیل میدهند.
معماری اصلی یک FNN بر اساس مفهوم اتصال کامل (Full Connectivity) بنا شده است، که در آن هر نورون در یک لایه به تمام نورونهای لایه بعدی متصل است. این اتصال متراکم به شبکه امکان میدهد تا روابط تابعی بسیار پیچیده بین ویژگیهای ورودی و پیشبینیهای خروجی را مدل کند. FNNها برای دادههای جدولی یا ساختاریافته که در آنها ترتیب ویژگیها فاقد معنای ذاتی فضایی یا زمانی است، بهینه هستند.
با وجود سادگی، FNNها از محدودیتهای ذاتی شدیدی رنج میبرند که کاربرد آنها را برای دادههای با ابعاد بالا مانند تصاویر غیرممکن میسازد.
انفجار پارامترها (Parameter Explosion): اتصال کامل منجر به افزایش نمایی تعداد پارامترها میشود. به عنوان مثال، برای پردازش یک تصویر کوچک ۱۰۰x۱۰۰ پیکسلی، یک نورون در لایه پنهان بعدی به ۱۰۰۰۰ وزن نیاز دارد. این رشد غیرقابل کنترل پارامترها، مدلی را ایجاد میکند که از نظر محاسباتی پرهزینه و نیازمند حجم عظیمی از داده برای آموزش است.
نفرین ابعاد (Curse of Dimensionality): این مشکل زمانی تشدید میشود که بدانیم چرا دادههای مورد نیاز FNN عملاً غیرقابل دستیابی هستند. با افزایش تعداد ویژگیها، حجم فضای ویژگی به صورت نمایی گسترش مییابد و این امر باعث میشود که دادههای آموزشی موجود بسیار پراکنده شوند. در نتیجه، عملکرد روشهای تحلیلی که به تراکم دادهها متکی هستند، به شدت کاهش مییابد.
در نتیجه، شکست FNNها در پردازش کارآمد دادههای ساختاریافته فضایی به دلیل انفجار پارامترها و نفرین ابعاد، توسعه معماریهایی با کارایی ساختاری داخلی را ضروری ساخت؛ معماریهایی که بتوانند با بایاسهای استقرایی مناسب، این محدودیتهای مقیاسپذیری را دور بزنند.
شبکههای عصبی کانولوشنی (CNN) دستهای از شبکههای پیشخور هستند که به طور خاص برای پردازش دادههای شبکهای مانند تصاویر مهندسی شدهاند تا مستقیماً به مشکل انفجار پارامترها در FNNها پاسخ دهند. اهمیت استراتژیک آنها در تواناییشان به عنوان استخراجکنندههای ویژگی قدرتمند، خودکار و سلسلهمراتبی نهفته است که به طور ذاتی ساختار فضایی دادهها را درک میکنند.
لایه کانولوشنی، هسته اصلی CNN، دو محدودیت قدرتمند را برای حل مشکلات مقیاسپذیری FNNها تحمیل میکند:
میدانهای دریافتی محلی (Local Receptive Fields): هر نورون در یک لایه کانولوشنی، دادهها را تنها از یک ناحیه کوچک و محلی از لایه قبلی پردازش میکند. این اصل تعداد اتصالات را به شدت کاهش میدهد و این بایاس را القا میکند که ویژگیهای بصری مهم، محلی هستند.
اشتراک وزن (Weight Sharing): اصل اعمال وزنهای یکسان فیلتر در سراسر فضای ورودی، یک نوآوری کلیدی است. این مکانیسم به شبکه خاصیت هموردایی انتقالی (Translational Equivariance) میبخشد؛ یعنی شبکه میتواند یک ویژگی (مانند یک لبه عمودی) را صرفنظر از موقعیت آن در تصویر تشخیص دهد. این امر منجر به کاهش چشمگیر تعداد پارامترهای قابل آموزش میشود.
لایه ادغام (Pooling) نقش دوگانهای را ایفا میکند: اول، به طور سیستماتیک ابعاد فضایی نقشههای ویژگی را کاهش میدهد (downsampling) تا کارایی محاسباتی افزایش یابد. دوم، با خلاصهسازی اطلاعات یک ناحیه (مثلاً با استفاده از Max Pooling)، درجهای از ثبات انتقالی محلی (local translational invariance) را به ویژگیهای استخراجشده میبخشد. با انباشت چندین لایه کانولوشنی و ادغام، CNN به طور خودکار یک سلسلهمراتب ویژگیها (feature hierarchy) را یاد میگیرد. لایههای اولیه ویژگیهای ساده مانند لبهها و رنگها را تشخیص میدهند، در حالی که لایههای عمیقتر این ویژگیهای ساده را برای شناسایی اشیاء پیچیده ترکیب میکنند.
ساخت CNNهای واقعاً عمیق با یک چالش اساسی به نام مشکل تخریب (degradation problem) مواجه بود، که در آن افزودن لایههای بیشتر منجر به کاهش دقت آموزش میشد. شبکههای باقیمانده (ResNet) با معرفی اتصالات پرشی (skip connections) این مشکل را به طور اساسی حل کردند. نوآوری اصلی ResNet در بازتعریف مسئله یادگیری است. به جای اینکه یک بلوک از لایهها مستقیماً تابع مطلوب H(x) را یاد بگیرد، وظیفه آن یادگیری یک تابع باقیمانده (residual function) سادهتر به شکل F(x) است. اگر نگاشت همانی بهینه باشد (یعنی لایه نباید کاری انجام دهد)، شبکه به راحتی میتواند F(x) = 0 را یاد بگیرد که یک کار پیشپاافتاده است. سپس خروجی بلوک به صورت y = F(x) + x محاسبه میشود. اتصال پرشی + x یک مسیر مستقیم و بدون مانع برای جریان گرادیانها در طول فرآیند انتشار بازگشتی فراهم میکند و این بازتعریف، مشکل تخریب گرادیان را در شبکههای بسیار عمیق حل کرده و آموزش مدلهایی با بیش از ۱۵۰ لایه را ممکن ساخت.
با تسلط CNNها بر دادههای فضایی، چالشهای متمایز پردازش دادههای دارای وابستگی زمانی، نیاز به یک معماری جدید را آشکار کرد که بتواند حافظه و ترتیب را مدلسازی کند.
شبکههای عصبی بازگشتی (RNN) برای پردازش دادههای متوالی مانند متن و سریهای زمانی تخصصی شدهاند تا چالش مدلسازی وابستگیهای زمانی را حل کنند. اهمیت استراتژیک آنها در توانایی مدلسازی این وابستگیها از طریق تحمیل اتصالات بازگشتی (recurrent connections) است که نوعی حافظه را در شبکه ایجاد میکند.
مکانیسم اصلی RNN حول یک حلقه بازخورد میچرخد. شبکه یک حالت پنهان (hidden state) با نماد (h_t) را حفظ میکند که به عنوان حافظه عمل کرده و اطلاعات ورودیهای قبلی را در خود ذخیره میکند. در هر گام زمانی، RNN ورودی فعلی (x_t) را در چارچوب حالت پنهان قبلی (h_{t-1}) پردازش میکند تا خروجی را تولید و حالت پنهان را برای گام بعدی بهروز کند.
چالش اصلی RNNهای ساده، مشکل محو شدن گرادیان (vanishing gradient problem) است. در طول فرآیند آموزش که انتشار بازگشتی در طول زمان (BPTT) نامیده میشود، گرادیانها میتوانند با عبور از گامهای زمانی متعدد به صورت نمایی کوچک شوند. این پدیده باعث میشود که شبکه نتواند وابستگیهای بلندمدت (long-term dependencies) را یاد بگیرد. این ناتوانی، یک شکست در بهینهسازی (optimization failure) ناشی از گرادیانهای ناپایدار بود، نه یک نقص در ظرفیت نمایشی معماری.
حافظه طولانی کوتاهمدت (LSTM) و واحدهای بازگشتی دروازهای (GRU) به عنوان راهحلهای مهندسیشده برای غلبه بر این شکست بهینهسازی معرفی شدند. معماری LSTM با معرفی اجزای داخلی پیچیده، جریان اطلاعات و گرادیانها را به طور مؤثری تنظیم میکند:
حالت سلولی (Cell State): این جزء به عنوان یک "نوار نقاله" اختصاصی یا "چرخ فلک خطای ثابت" (Constant Error Carousel) عمل میکند که اطلاعات بلندمدت را در طول توالی حمل میکند. این ساختار به گرادیانها اجازه میدهد تا بدون مانع در طول زمان جریان یابند و از حالت پنهان که برای پیشبینیهای کوتاهمدت استفاده میشود، جدا است.
دروازهها (Gates): سه دروازه تخصصی جریان اطلاعات را به داخل و خارج از حالت سلولی کنترل میکنند:
دروازه فراموشی (Forget Gate): تصمیم میگیرد کدام اطلاعات از حالت سلولی قبلی باید حذف شوند.
دروازه ورودی (Input Gate): کنترل میکند که چه مقدار از اطلاعات جدید باید در حالت سلولی ذخیره شود.
دروازه خروجی (Output Gate): تعیین میکند که کدام بخش از حالت سلولی برای تولید حالت پنهان فعلی و خروجی شبکه استفاده شود.
این مکانیزمهای دروازهای به LSTM اجازه میدهند تا به طور انتخابی اطلاعات را در طول زمان حفظ یا حذف کند و بدین ترتیب مشکل محو شدن گرادیان را حل کند. با این حال، محدودیت بنیادین تمام مدلهای مبتنی بر RNN، یعنی پردازش ذاتاً متوالی آنها، یک تنگنای محاسباتی جدی ایجاد کرد و انگیزه لازم برای تغییر پارادایم بعدی را فراهم نمود.
معماری ترنسفورمر به عنوان یک مدل انقلابی ظهور کرد که با کنار گذاشتن کامل بازگشت، به طور گسترده جایگزین RNNها در وظایف پردازش زبان طبیعی (NLP) شد. اهمیت استراتژیک آن در توانایی غلبه بر تنگنای پردازش متوالی از طریق موازیسازی کامل نهفته است که منجر به پیشرفتهای چشمگیر در مقیاسپذیری و عملکرد شده است.
نوآوری اصلی ترنسفورمر، مکانیسم توجه به خود (self-attention mechanism) است. برخلاف RNNها که توکنها را یک به یک و به صورت متوالی پردازش میکنند و تمام اطلاعات قبلی را در یک بردار حالت پنهان با اندازه ثابت (h_{t-1}) فشرده میکنند، مکانیسم توجه به خود کل توالی ورودی را به طور همزمان و موازی پردازش میکند. این مکانیسم با محاسبه یک امتیاز وابستگی بین هر جفت از عناصر در توالی، صرفنظر از فاصله آنها، به هر عنصر دسترسی مستقیم به زمینه سراسری (global context) را میدهد و تنگنای اطلاعاتی ذاتی ساختار بازگشتی را از بین میبرد.
این تغییر معماری به طور قطعی دو محدودیت اصلی RNNها را برطرف کرد:
پایداری گرادیان (Gradient Stability): با حذف مسیرهای طولانی و متوالی انتشار بازگشتی، مشکل محو شدن گرادیان که ذاتی BPTT بود، به طور کامل حل شد.
موازیسازی (Parallelization): جایگزینی وابستگی متوالی با محاسبات توجه کاملاً موازی، مدلسازی توالی را به عملیاتی تبدیل کرد که برای سختافزارهای مدرن مانند GPUها بسیار بهینه است و زمان آموزش را به شدت کاهش میدهد.
با کنار گذاشتن بازگشت، معماری مدل درک ضمنی خود از ترتیب توالی را از دست داد. مکانیسم توجه به خود ذاتاً نسبت به جایگشت ورودیها ناوردا است (permutation-invariant)، به این معنی که ورودی را به عنوان مجموعهای نامرتب از توکنها در نظر میگیرد. بنابراین، رمزگذاری موقعیتی (positional encoding) یک افزودنی اختیاری نیست، بلکه یک جزء حیاتی است که برای تزریق صریح اطلاعات ترتیبی از دست رفته به مدل، ضروری است.
در حالی که ترنسفورمرها بر دادههای متوالی تسلط یافتند، دسته دیگری از دادهها—گرافهای با ساختار نامنظم و غیراقلیدسی—نیازمند یک رویکرد معماری متمایز بودند.
شبکههای عصبی گراف (GNN) دستهای از شبکهها هستند که برای دادههای غیراقلیدسی (non-Euclidean data) که به صورت گراف (متشکل از گرهها و یالها) ساختار یافتهاند، طراحی شدهاند. اهمیت استراتژیک آنها در حوزههایی مانند شبکههای اجتماعی، زیستشناسی مولکولی و سیستمهای توصیهگر که در آنها روابط بین موجودیتها نقشی حیاتی ایفا میکند، برجسته است.
مکانیسم عملیاتی اساسی GNNها در چارچوب ارسال پیام (Message Passing) خلاصه میشود. این فرآیند به صورت تکراری بازنماییهای برداری (embeddings) برای هر گره را محاسبه میکند که هم ویژگیهای اولیه گره و هم نقش ساختاری آن در گراف را رمزگذاری میکند. هر تکرار از این فرآیند شامل سه مرحله است:
تولید پیام (Message Generation): هر گره بر اساس وضعیت فعلی خود، پیامی برای همسایگانش تولید میکند.
تجمیع (Aggregation): هر گره پیامهای دریافتی از همسایگان خود را با استفاده از یک تابع تجمیع (مانند جمع یا میانگین) ترکیب میکند.
بهروزرسانی (Update): هر گره حالت خود را بر اساس پیام تجمیعشده و وضعیت قبلی خود بهروز میکند.
تکامل در معماریهای GNN به سمت پردازش اطلاعات پویاتر حرکت کرده است:
شبکههای کانولوشنی گراف (GCN): به عنوان یک مدل پایهای، GCN از وزنهای ثابت و از پیش تعیینشده برای تجمیع اطلاعات همسایگی استفاده میکند. این رویکرد، اگرچه کارآمد است، اما انعطافپذیری محدودی دارد.
شبکههای توجه گراف (GAT): این معماری با گنجاندن یک مکانیسم توجه (attention mechanism) پویا، GCN را بهبود میبخشد. این مکانیسم به مدل اجازه میدهد تا به صورت انطباقی به همسایگان مختلف سطوح اهمیت متفاوتی اختصاص دهد و فرآیند تجمیع را قدرتمندتر و آگاه از زمینه سازد. تغییر معماری از تجمیع ثابت GCN به وزندهی پویای GAT یک رویداد مجزا نیست؛ این تغییر، بازتابی از پارادایم گستردهتری است که در مدلسازی توالی با ترنسفورمر مشاهده شد و نشان میدهد که توجه به یک اصل اولیه جهانی در یادگیری عمیق (universal deep learning primitive) برای ایجاد تجمیع اطلاعات قدرتمندتر و آگاه از زمینه تبدیل شده است.
چالش اصلی که در حال حاضر عمق GNNها را محدود میکند، پدیده بیشهموارسازی (over-smoothing phenomenon) است. پس از تکرار تجمیع در لایههای متعدد، بازنماییهای گرهها به تدریج به یکدیگر شبیه شده و ویژگیهای متمایز خود را از دست میدهند. این امر توانایی مدل برای یادگیری از همسایگیهای دورتر را محدود میکند.
در ادامه، یک تحلیل مقایسهای جامع، ویژگیهای کلیدی و کاربردهای استراتژیک تمام معماریهای مورد بحث را ترکیب میکند.
روایت تکاملی معماریهای شبکه عصبی، یک پیشرفت مداوم از مدل عمومی FNN به سمت معماریهای بسیار تخصصی است. موضوع اصلی این تکامل، مهندسی محدودیتها و بایاسهای استقرایی برای تطبیق کارآمد مدل با ساختار ذاتی دادههاست. این فرآیند از اتصال کامل و پرپارامتر به سمت اتصالات محلی، اشتراکگذاریشده و پویا حرکت کرده است تا کارایی محاسباتی و قدرت تعمیم مدل را به حداکثر برساند.
نوع داده / ساختار
وابستگی مورد نیاز
معماری بهینه (استاندارد فعلی)
ویژگی کلیدی معماری
ملاحظات مقیاسپذیری
دادههای جدولی / ویژگیهای مستقل
نگاشت تابعی
FNN/MLP
اتصال کامل، غیرخطی بودن
موازیسازی بالا، حساس به ابعاد ورودی
تصویر / ویدئو / شبکهها
سلسلهمراتب فضایی (ناوردایی نسبت به انتقال)
CNN (ResNet) / Vision Transformer
کانولوشن، اشتراک وزن، اتصالات پرشی
عالی، بسیار بهینه برای موازیسازی GPU
متن / سری زمانی / صوت
زمینه زمانی دوربرد
ترنسفورمر (مکانیسمهای توجه)
پردازش موازی، رمزگذاری موقعیتی، زمینه سراسری
بالا، با جایگزینی تنگناهای وابستگی متوالی
ساختارهای مولکولی / شبکههای اجتماعی
تعامل رابطهای / همسایگی
GNN (GAT, GraphSAGE)
ارسال پیام، توجه انطباقی
متوسط، حساس به عمق بیشهموارسازی و اندازه گراف
انتخاب معماری بهینه یک تصمیم استراتژیک است که توسط ساختار ذاتی دادهها و وابستگیهای خاصی که باید مدلسازی شوند، تعیین میگردد. CNNها (با اتصالات باقیمانده)، ترنسفورمرها (با توجه به خود) و GNNها به ترتیب، راهحلهای پیشرفته فعلی برای دادههای فضایی، متوالی و رابطهای هستند. تکامل از FNN به مدلهای تخصصی مانند ترنسفورمر و GNN گواهی بر قدرت تعبیه دانش پیشین در معماری است. پیشرفتهای آینده احتمالاً این روند را با توسعه محدودیتها و بایاسهای استقرایی جدید برای تسخیر مرزهای تازه در ساختار و پیچیدگی دادهها ادامه خواهند داد.
منابع ارائه شده یک نمای کلی جامع از انواع و تکامل معماریهای اصلی شبکههای عصبی عمیق فراهم میآورند. این شبکهها با اجزای پایهای مانند لایههای پنهان (Hidden Layers) و توابع فعالسازی (Activation Functions) ساخته شدهاند و از شبکههای بنیادی پیشخور (FNNs) که جریان اطلاعاتی یکسویه دارند، شروع میشوند. مدلهای تخصصیتر شامل شبکههای عصبی کانولوشنی (CNNs) هستند که برای دادههای شبکهای مانند تصاویر طراحی شدهاند و از قابلیت اشتراک وزن (Weight Sharing) برای استخراج سلسله مراتب ویژگیها استفاده میکنند. اگرچه شبکههای عصبی بازگشتی (RNNs) در ابتدا برای دادههای توالیمحور توسعه یافتند، اما معماریهای پیشرفتهای نظیر LSTM برای حل مشکل گرادیان ناپدیدشونده (vanishing gradient problem) در آنها پدیدار شدند. با این حال، در کاربردهای مدرن NLP، ترنسفورمرها (Transformers) به دلیل مقیاسپذیری و قابلیت پردازش موازی از طریق مکانیسم توجه به خود (self-attention)، کارایی بالاتری نسبت به RNNها در مدیریت وابستگیهای دوربرد (long-range dependencies) از خود نشان دادهاند. در نهایت، شبکههای عصبی گرافی (GNNs) از یک مکانیزم انتقال پیام (message-passing mechanism) برای تحلیل ساختارهای دادهای نامنظم استفاده میکنند و برای تحلیل شبکههای اجتماعی و سیستمهای توصیهگر حیاتی هستند.