سلام به همه رفقای برنامهنویس و عاشق تکنولوژی!
احتمالا همهمون این تجربه رو داشتیم: بعد از چند روز یا حتی چند هفته جون کندن، بالاخره اون فیچر جدیده رو تموم کردیم. با کلی وسواس کدهارو مرتب کردیم، کامیتهارو تمیز کردیم و یه Pull Request (یا همون PR) تر و تمیز باز میکنیم. و بعد... سکوت. وارد یه مرحلهای میشیم به اسم "انتظار برای ریویو". منتظر یه همکار ارشد که وقت داشته باشه، تمرکز کنه، زمینه کاری مارو یادش بیاد و کدمون رو با دقت ریویو کنه.
فرآیند بازبینی کد یا Code Review، با تمام اهمیتی که تو بالا بردن کیفیت کد، امنیت، اشتراک دانش و پیدا کردن باگها داره، خیلی وقتا به یه گلوگاه بزرگ تو مسیر توسعه تبدیل میشه.
همین چالش بود که جرقه یه ایده رو تو ذهن من زد: «چی میشه اگه یه دستیار هوش مصنوعی داشته باشیم که این کار رو برامون انجام بده؟» این سوال، شروع یه پروژه جذاب تو درس معماری نرمافزار بود که میخوام تو این پست، داستان کامل ساختش، تصمیمهای معماری، چالشها و درسهایی که تو این مسیر یاد گرفتم رو با شما به اشتراک بذارم.

ایده اولیه، مثل خیلی از ایدههای دیگه، ساده و سرراست بود: یه سرویس کوچیک میسازیم که به Webhook گیتهاب یا گیتلب گوش میده. هر وقت یه PR جدید باز شد،diff یا همون تغییرات کد رو میگیریم، صاف میذاریمش کف دست یه مدل زبانی بزرگ (LLM) و بهش میگیم: "لطفاً اینو ریویو کن!". بعد هم جوابش رو به عنوان کامنت روی همون PR پست میکنیم. ساده و قشنگ به نظر میرسید، نه؟
اما وقتی کلاه معمار نرمافزار رو سرمون گذاشتیم و یه کم عمیقتر به ماجرا فکر کردیم، سوالای ترسناکی شروع کردن به جوونه زدن:
مقیاسپذیری: اگه تو یه سازمان بزرگ یا صدها سازمان با صدها دولوپر کار کنیم و همزمان ۱۰۰ تا PR باز بشه چی؟ آیا این سیستم ساده ما از پس این حجم از کار برمیاد یا منفجر بشه؟
قابلیت اطمینان: اگه سرویس LLM برای چند دقیقه قطع بشه یا شبکه به مشکل بخوره چی؟ آیا درخواستهای بازبینی که تو همون لحظه اومدن برای همیشه از بین میرن؟
کیفیت بازخورد: آیا یه LLM فقط با دیدن چند خط کد تغییر کرده، بدون اینکه بدونه این کد تو چه پروژهای، با چه ساختاری و با چه استانداردهایی نوشته شده، میتونه یه بازخورد واقعا مفید و متناسب با کل پروژه بده؟ یا فقط یه سری کامنت کلی و به دردنخور تحویل میده؟
جواب صادقانه به این سوالا، مارو به این نتیجه رسوند که اون سرویس ساده و رویایی، تو دنیای واقعی دوام زیادی نمیاره. ما به یه معماری مهندسیشده نیاز داشتیم.
ما فهمیدیم که برای ساختن یه سیستم قابل اتکا و مقیاسپذیر، باید دوتا نگرانی اصلی رو از هم جدا کنیم: نگرانی دریافت مطمئن درخواستها و نگرانیِ پردازش سنگین و زمانبر بازبینی کد.
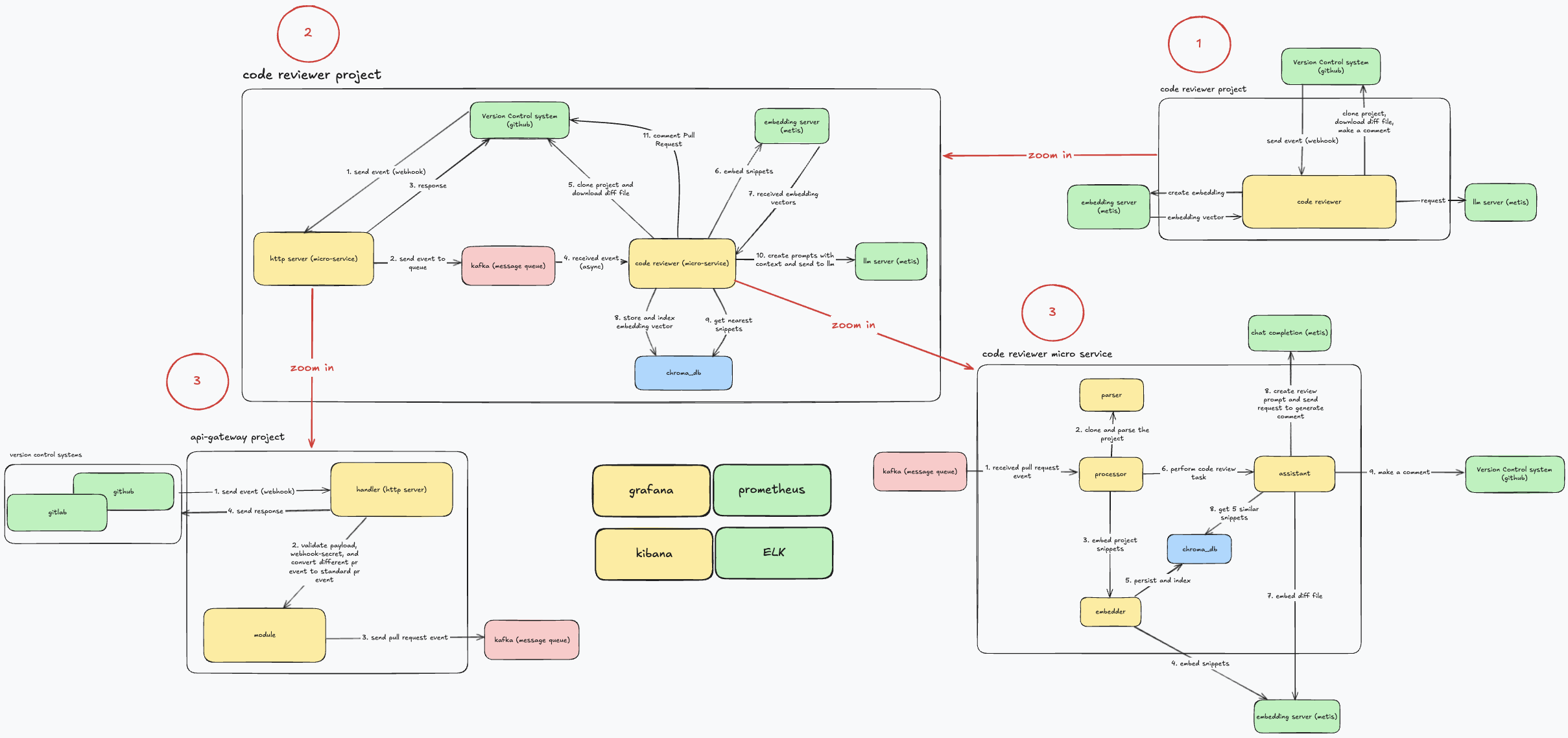
این شد که به یه معماری میکروسرویس و مبتنی بر رویداد رسیدیم که از سه جزء اصلی تشکیل شده بود:
سرویس Gateway: یه سرویس خیلی سبک و سریع که با زبان Go نوشتیمش. تنها وظیفهاش دریافت Webhook از سیستمهای کنترل ورژن، اعتبارسنجی امنیتیش، استاندار کردن ایونت و انداختن سریعش تو یه صفه. این سرویس هیچ کار سنگینی انجام نمیده و برای جواب دادن تو چند میلیثانیه بهینه شده.
کافکا (Kafka): هسته مرکزی سیستم ما! کافکا به عنوان یه واسط و بافر پایدار، این دوتا سرویس رو به طور کامل از هم جدا (Decouple) میکنه. کافکا تضمین میکنه که حتی اگه سرویس پردازشیمون برای ساعتها از کار بیفته، هیچ درخواستی از بین نمیره.
سرویس Code Reviewer: موتور اصلی و باربر سیستم که اونم با Go نوشته شده. این سرویس رویدادها رو از کافکا برمیداره و تمام کارای سنگین مثل کلون کردن پروژه، تحلیل کد، صحبت با هوش مصنوعی و ثبت کامنت رو انجام میده.
این معماری به ما اجازه داد تا سیستمی بسازیم که هم سریع و پاسخگو باشه و هم قابل اطمینان و مقیاسپذیر.

شاید جالب باشه که یه کم جزئیتر ببینیم داخل هر کدوم از این میکروسرویسها چه خبره.
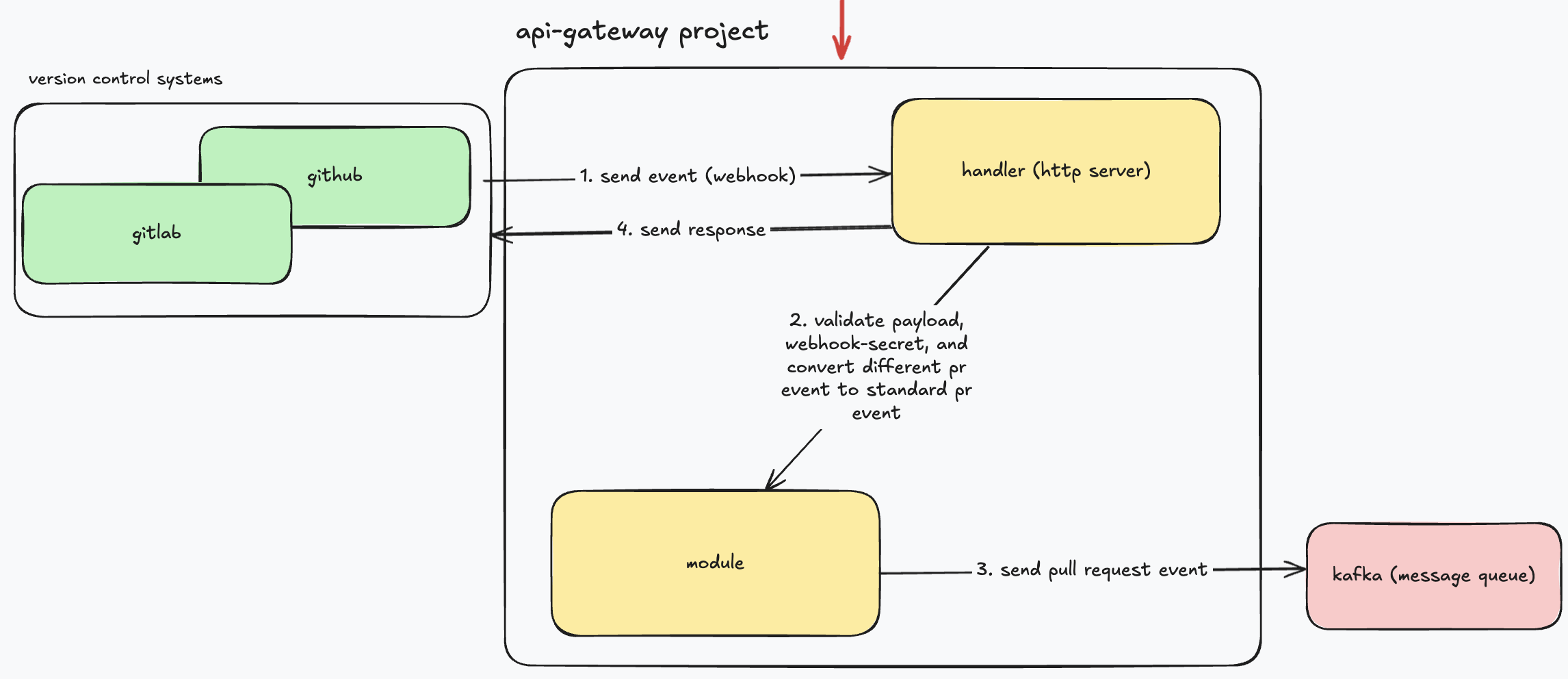
معماری داخلیapi-gateway: این سرویس مثل یه نگهبان دم در ورودی عمل میکنه. فلسفه اصلیش اینه که سریع، سبک و بیحالت (Stateless) باشه و ایونتهای هر کدوم از سیستم کنترل نسخه رو به مدل داخلی مپ کنه. داخلش چندتا کامپوننت کلیدی داریم:
Handler: این اولین کامپوننتیه که با درخواست Webhook روبرو میشه. کارش مدیریت روتهای HTTP و پاسخهای اولیه است.
Webhook Processor: این بخش، گارد امنیتی ماست. اولین کارش اینه که با استفاده از Webhook Secret، امضای درخواست رو چک میکنه تا مطمئن بشه واقعا از طرف گیتهاب اومده.
Event Converter: این کامپوننت، مترجم ماست. ساختار پیچیده و شلوغ JSON گیتهاب رو میگیره و به یه مدل داده داخلی، تمیز و استاندارد تبدیل میکنه. این همون الگوی آداپتوره که قبلا بهش اشاره کردم.
Event Sender: این بخش، مدل داده استاندارد شده رو میگیره و با مکانیزم retry، سعی میکنه اون رو تو کافکا منتشر کنه.
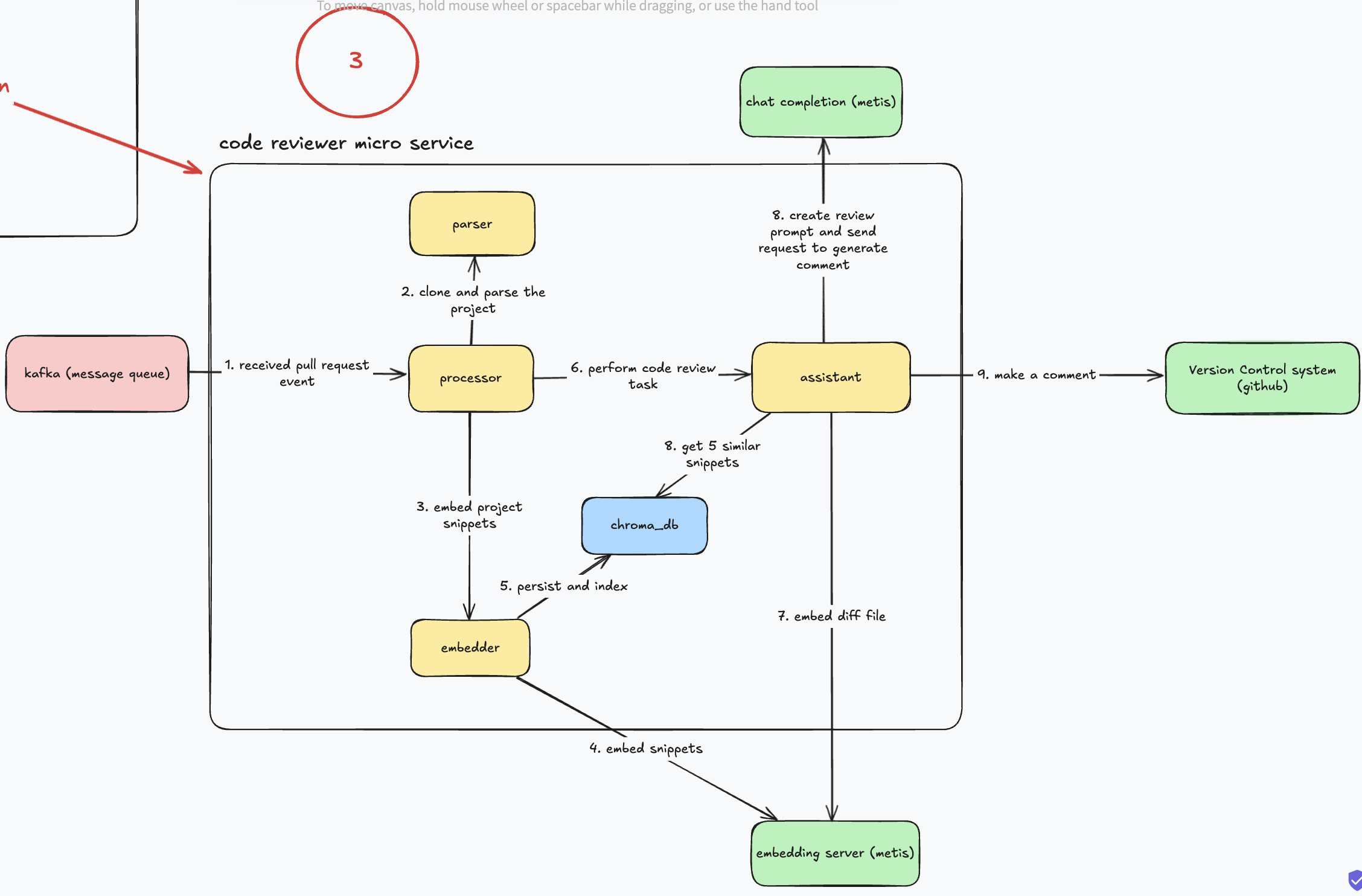
معماری داخلی code-reviewer: این سرویس، مغز متفکر سیستمه. تمام منطق اصلی اینجا پیادهسازی شده و ساختارش کاملا ماژولاره:
Event Processor: این کامپوننت، ارکستراتور یا رهبر ماست. یه Worker Pool از Goroutineها راه میندازه، پیامهارو از کافکا میکشه بیرون و کل فرآیند بازبینی رو برای هر پیام، از اول تا آخر هماهنگ میکنه.
VCS Client: متخصص گیت ما. این یه اینترفیسه که تمام کارهای مربوط به سیستم کنترل نسخه مثل کلون کردن، دانلود diff و پست کردن کامنت رو انجام میده.
Project Parser: این بخش، کل پروژه کلون شده رو با Tree-sitter تحلیل میکنه و به قطعههای معنایی مثل توابع و کلاسها میشکنه.
Project Embedder: قطعههای کد رو از پارسر میگیره، به یه سرویس امبدینگ خارجی میده و بردارهای حاصل رو برای ذخیرهسازی آماده میکنه. (بجای امبد کردن هر کلمه یا خط، یک تابع یا کلاس یک بردار میشه.)
Embeddings Repository: اینم یه اینترفیسه که با پایگاه داده برداری یعنی ChromaDB حرف میزنه و امبدینگهارو برای جستجوهای آینده ذخیره میکنه.
Assistant: این کامپوننت، الگوی RAG رو پیادهسازی میکنه. diff رو امبد میکنه، از ChromaDB زمینه مرتبط رو پیدا میکنه، پرامپت نهایی رو مهندسی میکنه و با LLM حرف میزنه.
این پروژه پر از چالشٰهای جذاب بود. در ادامه چندتا از مهمترین درسهایی که تو عمل یاد گرفتیم رو باهاتون به اشتراک میذارم:
شاید مهمترین درسی که از این پروژه گرفتم، درک عمیق قدرت جداسازی اجزا بود. استفاده از کافکا فقط یه انتخاب فنی نبود، بلکه یه تصمیم استراتژیک برای بالا بردن قابلیت اطمینان، دسترسپذیری و مقیاسپذیری بود. با این کار، ما به یه سیستم ناهمگام رسیدیم. Gateway کارش رو میکنه و اصلاً براش مهم نیست که Code Reviewer زنده هست یا نه. این یعنی اگه سرویس پردازشیمون به هر دلیلی (مثلاً برای آپدیت یا به خاطر یه باگ) از کار بیفته، Gateway به کار خودش ادامه میده و هیچ درخواستی از سمت سیستم کنترل ورژن رد نمیشه. این یعنی دسترسپذیری بالا.
خیلی زود فهمیدیم که فرستادنdiffخالی برای LLM، بازخوردای کلی و نه چندان مفیدی تولید میکنه. یه دستیار هوشمند واقعی باید پروژه رو بفهمه. اینجا بود که الگوی RAG (Retrieval-Augmented Generation) به کمک ما اومد.
ما به جای اینکه فقط تغییرات رو به LLM بدیم، تصمیم گرفتیم بهش "زمینه" بدیم. برای این کار:
با استفاده از لایبری Tree-sitter، کل کد پروژه رو به قطعههای معنایی (مثل توابع، متدها و کلاسها) شکستیم. این خیلی دقیقتر از شکستن کد بر اساس خطوط خالیه.
بعد، این قطعههارو به بردار عددی (Embedding) تبدیل کردیم و تو پایگاه داده برداری ChromaDB ذخیره و ایندکس کردیم.
حالا وقتی یه PR جدید میاد، سیستم ما diff رو هم به بردار تبدیل میکنه و با جستجو تو ChromaDB، مشابهترین کدهارو از دل پروژه پیدا میکنه و به عنوان "زمینه" به LLM میده.
نتیجه؟ بازخوردایی که به نظر دقیق، هوشمند و هماهنگ با بقیه کدبیس بودن. LLM حالا میدونست که استایل کدنویسی تو این پروژه چجوریه و میتونست پیشنهادهای خیلی بهتری بده.
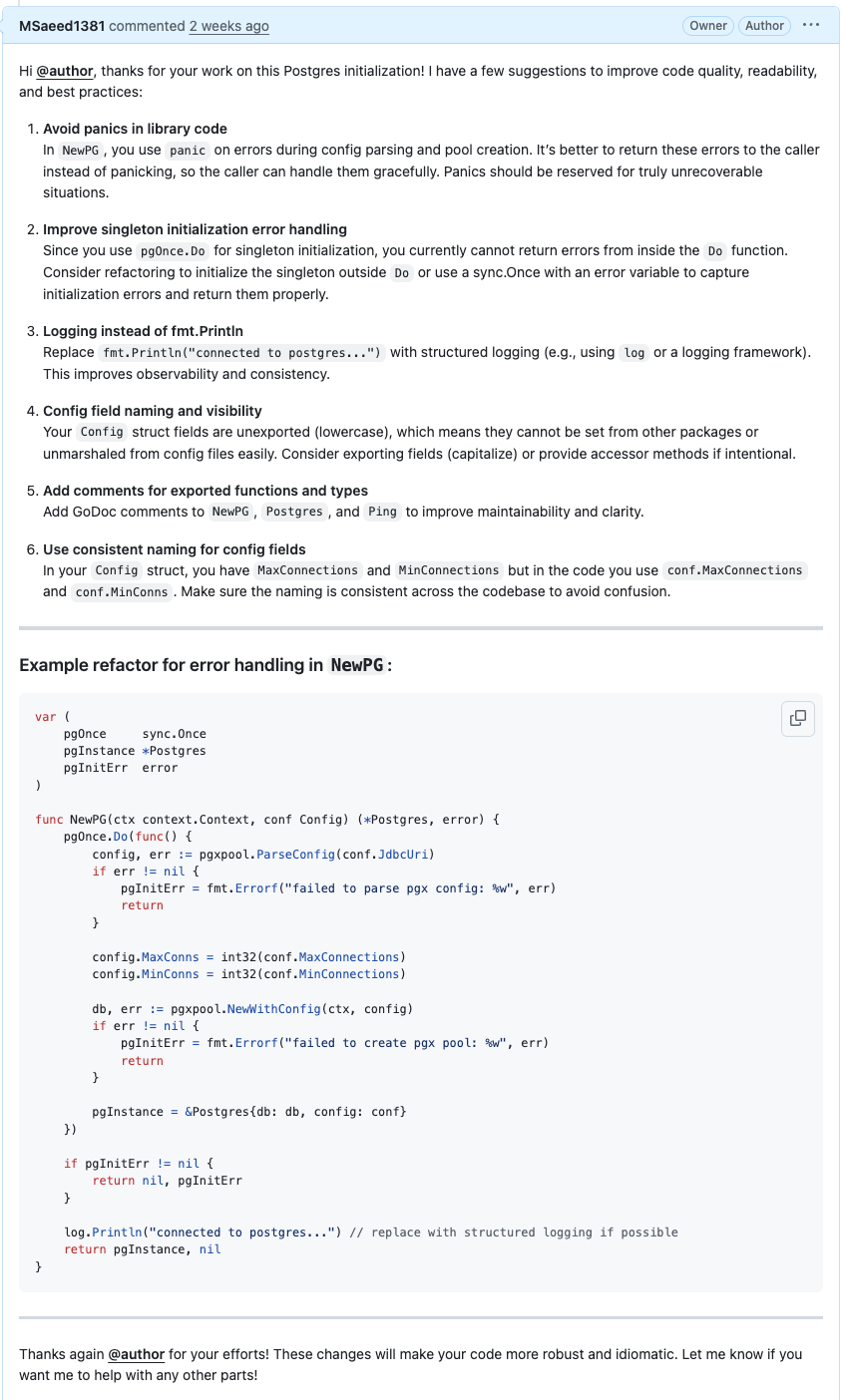
مثلا این مثال رو ببینین:
عکس زیر تغییرات یک pr ساده رو نشون میده. همونطور که میدونیم ما متغیر MinConns رو خوندیم در صورتی که اصلا داخل این تغییرات، فیلدهای conf مشخص نیست.

و حالا کامنت هوش مصنوعی:
علاوه بر ۵ مورد اول که خیلی به جا و عالی هستند، مورد ۶ به صراحت گفته که استراکت Config فیلد MinConns نداره و باید از MinConnections استفاده کنی و در ادامه خودش تیکه کد رو اصلاح کرده و این همون جادوی RAG عه.
تو سیستمهای توزیعشده، خطا یه اتفاق محتمل نیست، بلکه حتمی هست. شبکه قطع میشه، سرویسای خارجی از دسترس خارج میشن، یه باگ باعث کرش کردن سرویس میشه و... . ما از اول با این دیدگاه طراحی کردیم:
تلاش مجدد هوشمند: برای تمام ارتباطای خارجی، الگوی Retry با Exponential Backoff + Jitter رو پیادهسازی کردیم. این یعنی سیستم ما در برابر خطاهای موقت، به جای تسلیم شدن، چند بار با فاصلههای زمانی تلاش مجدد میکنه.
Graceful Shutdown: سرویسهامون طوری نوشته شدن که موقع دریافت سیگنال خاموش شدن، کارای در حال پردازش رو تموم میکنن و بعد خاموش میشن. این کار جلوی از دست رفتن داده رو میگیره.
Health Checks: با تعریف اندپوینتهای liveness و readiness، به ارکستریتور (مثل Docker Swarm) اجازه میدیم سلامت سرویسهارو چک کنه و در صورت نیاز، اونا رو به صورت خودکار ریاستارت کنه.
از همون روز اول، ما پشته مانیتورینگ خودمون رو با Prometheus و Grafana بالا آوردیم و لاگهارو به صورت ساختاریافته (JSON) به ELK Stack فرستادیم. این کار به ما اجازه داد تا متریکهای کلیدی مثل تاخیر پردازش (Latency)، توان عملیاتی (Throughput) و نرخ خطا رو به صورت زنده ببینیم.

یکی از بهترین تصمیمایی که گرفتیم، استفاده گسترده از اینترفیسها تو زبان Go بود. ما برای هر چیزی که با دنیای خارج حرف میزد (مثل سیستم کنترل ورژن، کلاینت LLM یا کافکا) یه اینترفیس تعریف کردیم. این کار دوتا مزیت فوقالعاده داشت:
آزمونپذیری (Testability): ما تونستیم تو تستهامون، به راحتی تمام این اجزای خارجی رو Mock کنیم. این یعنی میتونستیم کل فرآیند رو بدون نیاز به یه ارتباط واقعی با گیتهاب یا پرداخت هزینه به OpenAI، از اول تا آخر تست کنیم.
توسعهپذیری (Extensibility): اگه فردا بخوایم به جای گیتهاب از GitLab پشتیبانی کنیم، کافیه یه پیادهسازی جدید از اینترفیس VersionControlSystem بنویسیم. بقیه کد اصلا نیازی به تغییر نداره. این یعنی معماری ما برای آینده آماده است.

ما از اول پروژه رو به صورت Monorepo مدیریت کردیم. این کار مدیریت وابستگیها رو ساده میکرد، اما یه چالش داشت: با هر تغییر کوچیک، نباید کل سیستم دوباره بیلد و تست میشد. راهحل ما یه Pipeline CI/CD هوشمند تو GitHub Actions بود. این Pipeline پیام هر کامیت رو تحلیل میکنه و فقط و فقط همون سرویسی که تغییر کرده رو بیلد و تست (+ محاسبه کاوریج) میکنه بر اساس commit message. این کار زمان اجرای Pipeline رو از چندین دقیقه به کمتر از دو دقیقه کاهش داد و چرخه توسعه رو فوقالعاده سریع کرد.
یه نکته ظریف ولی خیلی مهم، تعریف یه مدل داده داخلی و استاندارد (PullRequestEvent) بود. Webhookای که از گیتهاب میاد، یه ساختار خیلی پیچیده و تو در تو داره. ما تو همون سرویس Gateway، این ساختار رو به یه مدل ساده و تمیز که خودمون تعریف کرده بودیم تبدیل کردیم. این کار (که بهش الگوی آداپتور هم میگن) باعث شد سرویس اصلی ما یعنی Code Reviewer اصلا درگیر پیچیدگیهای گیتهاب نشه. اگه فردا بخوایم GitLab رو اضافه کنیم، فقط کافیه یه آداپتور جدید براش بنویسیم که خروجیش همین مدل استاندارد خودمون باشه و بازم نیاز نیست تغییر دیگری ایجاد کنیم.
از همون لحظه اول، امنیت رو به عنوان یه بخش اصلی از طراحی در نظر گرفتیم. اولین کاری که Gateway ما انجام میده، اعتبارسنجی امضای Webhook با استفاده از یه Secret مشترک با گیتهابه. این کار جلوی حملات جعل درخواست رو میگیره و تضمین میکنه که فقط گیتهاب میتونه با سیستم ما حرف بزنه. این یه درس مهم بود که امنیت رو نباید برای آخر کار گذاشت.
سیستم ما از کلی جزء مختلف تشکیل شده: دوتا سرویس Go، کافکا، ChromaDB، پرومتئوس، گرافانا و... . اگه قرار بود برای هر بار تست کردن، همه اینارو جدا جدا بالا بیاریم، دیوونه میشدیم! استفاده از Docker Compose یه نعمت بزرگ بود. با یه دستور ساده، کل این اکوسیستم پیچیده روی لپتاپ ما بالا میومد و ما میتونستیم به راحتی فرآیند رو از اول تا آخر تست کنیم. این کار سرعت توسعه رو به شدت بالا برد.
در نهایت، فهمیدیم که کیفیت خروجی سیستم فقط به مدل LLM یا کیفیت زمینه بستگی نداره، بلکه به شدت به هنر پرامپتنویسی (Prompt Engineering) هم وابسته است. ما وقت گذاشتیم تا یه قالب پرامپت طراحی کنیم که به LLM دقیقا بگه ازش چی میخوایم:
You are an expert code reviewer. Review the following git diff and provide improvements. Focus on code quality, readability, and adherence to best practices. Only provide code snippets if necessary. Follow the language's code conventions. Make feedback personal and show gratitude to the author using "@" when tagging. ### Git Diff: {{.text}} ### Context: {{.context}}
یه درس مهم دیگه این بود که رفتار سیستم نباید تو کد هاردکد بشه. ما از اول تمام پارامترهای مهم، از آدرس سرویسها و کلیدهای API گرفته تا تعداد Workerها و حتی متن پرامپتها رو تو فایلهای config.yaml و متغیرهای محیطی قرار دادیم. این کار به ما اجازه داد تا بدون نیاز به یه خط تغییر کد و بیلد مجدد، رفتار سیستم رو تو محیطهای مختلف (توسعه، تست، پروداکشن) به راحتی تنظیم کنیم. این یعنی انعطافپذیری بالا.
ما تصمیم گرفتیم که سند معماری نرمافزار (SAD) رو به جای اینکه تو یه فایل Word گوشه درایو خاک بخوره، به صورت فایلهای .excalidraw داخل خود ریپازیتوری و کنار کد نگه داریم. این یعنی سند معماری ما هم مثل کد، ورژنبندی میشد و با هر تغییر بزرگ تو پروژه، ما موظف بودیم سند رو هم آپدیت کنیم. این کار باعث شد معماری فقط یه نقشه اولیه نباشه، بلکه یه مستند زنده باشه که همیشه وضعیت واقعی سیستم رو منعکس میکنه.
ما میخواستیم ببینیم سیستممون زیر بار سنگین چطور رفتار میکنه، اما اجرای لود تست روی API واقعی LLM میتونست تو چند دقیقه صدها دلار هزینه داشته باشه! راهحل ما شبیهسازی بود. ما یه سرور Mock خیلی ساده نوشتیم که رفتار LLM رو شبیهسازی میکرد: یه درخواست میگرفت، یه مدت زمان تصادفی مثلا بین ۵۰ تا ۷۰ ثانیه صبر میکرد و یه جواب ثابت برمیگردوند. اینطوری تونستیم با خیال راحت هزاران درخواست رو به سیستم بفرستیم و عملکرد کافکا، Worker Pool و پایگاه داده رو زیر فشار واقعی تست کنیم، بدون اینکه نگران هزینهها باشیم.
یکی از مهمترین تصمیمات فنی برای تضمین قابلیت اطمینان، غیرفعال کردن Auto-Commit در مصرفکننده کافکا بود. به طور پیشفرض، کافکا پیامهارو بعد از اینکه از صف خونده میشن، به صورت خودکار تایید (Commit) میکنه. اما این خیلی خطرناکه! اگه ما پیام رو بخونیم و قبل از اینکه کارمون تموم بشه سرویس کرش کنه، پیام برای همیشه از دست میره. ما Commit رو به حالت دستی تغییر دادیم. این یعنی Code Reviewer ما پیام رو میخونه، تمام کارهاشو انجام میده (کلون، پارس، تحلیل، ثبت کامنت) و فقط و فقط اگه همه چیز با موفقیت تموم شد، به کافکا میگه: "اوکی، من کار این پیام رو تموم کردم، میتونی حذفش کنی." این کار، تضمین پردازش At-Least-Once رو به ما داد.

با تمام تلاشی که کردیم، مهمه که شفاف در مورد محدودیتهای فعلی سیستم هم حرف بزنیم. ساختن یه سیستم بینقص یه رویا است و هر معماریای چالشهای خودش رو داره.
هزینه و عملکرد: راستشو بخواین، این سیستم ارزون نیست. هر فراخوانی LLM و هر عملیات امبدینگ هزینه داره. ما با بهینهسازیهایی مثل ایندکس کردن هوشمند سعی کردیم هزینههارو کنترل کنیم، اما همیشه یه تریدآف بین هزینه، سرعت و کیفیت بازخورد وجود داره.
وابستگی به سرویسهای خارجی: عملکرد سیستم به در دسترس بودن APIهای GitHub و LLM Provider وابسته است.
ریسک توهم (Hallucination): مدلهای LLM، با تمام قدرتی که دارن، گاهی اوقات دچار "توهم" میشن و ممکنه پیشنهادهای اشتباه یا بیربط بدن. ما با مهندسی پرامپت سعی کردیم این ریسک رو کم کنیم، اما در نهایت، این سیستم یه دستیاره، نه یه دانای کل! همیشه یه نظارت انسانی لازمه.
محدودیت طول پرامپت
عدم فهم منطق کسبوکار: دستیار ما تو پیدا کردن مشکلات سینتکسی، استایل کدنویسی و حتی باگهای رایج خیلی خوبه، اما یه چیز مهم رو نمیفهمه: منطق کسبوکار. اون نمیتونه به شما بگه که آیا فیچری که نوشتین، دقیقا همون چیزیه که تیم محصول میخواسته یا نه. این بخش همچنان به طور کامل به عهده انسانهاست.
امیدوارم این تجربه براتون مفید بوده باشه. اگه دوست داشتین بیشتر در موردش بخونین دو بخش پایین رو یه نگاه بندازین.
سند معماری نرم افزار پروژه:
https://docs.google.com/document/d/1tw3hMXn30H02zzrR7fVarZX2keQQ_hf5UrzyhpStFz0/edit?usp=sharing
کد پروژه:
https://github.com/MSaeed1381/go-code-reviewer
لینک ارائه در آپارات:
https://www.aparat.com/v/zfhl0r5
لینک اسلایدها:
https://drive.google.com/drive/folders/1LfOJ5WEnsHa8emLFQVY8pyNYFHzCyGXB?usp=sharing
(این مطلب، بخشی از تمرینهای درس معماری نرمافزار در دانشگاه شهیدبهشتی است)