نویسنده:
محمدسعید زارع
استاد راهنما:
دکتر صادق علیاکبری
تحلیل شبکههای پیچیده پویا با گسترش گرافهای متنی-ویژگی پویا[1] که حاوی ویژگیهای متنی هستند، وارد مرحلهای شده است که ابعاد ساختاری، زمانی و معنایی را همزمان در بر میگیرد. روشهای سنتی تحلیل گرافها به دلیل ناتوانی یا ضعف در مدلسازی محتوای متنی و وابستگیهای بلندمدت[2]، با محدودیتهای زیادی مواجه هستند. در سالهای ۲۰۲۱ تا ۲۰۲۶، مدلهای زبانی بزرگ به عنوان یک مدل برای فهم معنا، نقش اساسی در ارتقای تحلیل شبکههای پیچیده پویا ایفا کردهاند. در این مطالعه با مروری نظاممند، مسیرهای مختلف همگرایی LLM و GNN بررسی میشود. نحوه استفاده از توانایی استدلالی مدلهای زبانی بزرگ برای بازسازی و بهینهسازی ساختار گراف و بهکارگیری این مدلها به عنوان مرحله پیشپردازش یا پیشوند برای مدلهای گرافی به منظور درک بهتر روابط پیچیده و ناهمگن از دیگر موارد تحت پوشش این پژوهش است.
یافتههای این پژوهش نشان میدهد که چارچوبهای ترکیبی نظیر LKD4DyTAG و GraphEdit با تلفیق تفسیرهای معنایی LLM و مدلسازی ساختاری GNN، دقت پیشبینی پیوند و طبقهبندی گرهها را بهطور معناداری بهبود بخشیدهاند. با این حال، چالشهایی همچون هزینه محاسباتی بالا در گرافهای بزرگ و سوگیریهای ساختاری مدلهای زبانی همچنان پابرجا است. در نهایت، این پژوهش نشان میدهد که آینده تحلیل این شبکهها در گرو توسعه مدلهای آگاه از زمان و تفسیرپذیر است که توازنی بهینه میان درک معنایی و بهرهوری محاسباتی ایجاد کنند.
واژگان کلیدی: شبکههای پیچیده پویا، گرافهای پویا با ویژگیهای متنی، شبکههای عصبی گراف، مدلهای زبانی بزرگ، تقطیر دانش
شبکههای پیچیده پویا در بسیاری از حوزهها از جمله شبکههای اجتماعی و سامانههای توصیهگر تا تحلیل تعاملات علمی و ارتباطات سازمانی کاربرد دارد. این شبکهها به طور مستمر در حال تغییر بوده و رفتار آنها وابسته به زمان است. در سالهای اخیر، گسترش دادههای متنی در کنار ساختار و توپولوژی شبکه، شکل جدیدی از گرافها را ایجاد کرده که بهعنوان گرافهای پویا با ویژگیهای متنی (DyTAGs) شناخته میشوند. این گرافها علاوه بر تغییرات ساختاری و زمانی، حاوی اطلاعات معنایی هستند که تحلیل آنها را نسبت به شبکههای پویا بدون ویژگیهای متنی به مراتب پیچیدهتر میکند.
تصویر ۱ نمونهای از یک گراف پویا با ویژگیهای متنی است که در پژوهش [1] بررسی شده است. این تصویر انتخابات ریاستجمهوری ۲۰۲۴ ایالات متحده را نشان میدهد. در این گراف، هر گره نماینده یک موجودیت مرتبط با انتخابات مانند نامزدها، احزاب سیاسی، رسانهها یا رویدادهای کلیدی است و برای هر گره یک توضیح متنی توصیفی وجود دارد که اطلاعات معنایی آن را ارائه میکند. روابط بین موجودیتها به وسیله یالها نمایش داده شدهاند؛ این یالها علاوه بر اتصال ساختاری، شامل اطلاعات زمانی نیز هستند تا نشان دهند که تعاملات، وابستگیها یا رخدادهای مشترک میان موجودیتها در چه بازههایی از زمان اتفاق افتاده است.
![تصویر ۱. انتخابات ریاستجمهوری ۲۰۲۴ ایالات متحده [1]](https://files.virgool.io/upload/users/449482/posts/qpn0wabmd7fn/nv3zd0gpakbl.png)
چالش اصلی در شبکههای DyTAG آن است که سه بعد ساختار، زمان و معنا بهصورت درهمتنیده در این شبکهها وجود دارند و مدلهای کلاسیک برای تحلیل شبکه که معمولا برای توپولوژیهای ایستا طراحی شدهاند، توانایی کافی برای پردازش محتوای زبانی، وابستگیهای بلندمدت، تحول معنایی در گذر زمان و تفسیرپذیری را ندارند [2]. به ویژه در محیطهایی که موضوعات، روابط و تعاملات بهصورت مکرر تغییر میکنند، روشهای سنتی قادر به حفظ سازگاری معنایی و تفسیر تغییر الگوهای متن و ساختار نیستند [3].
ظهور مدلهای زبانی بزرگ، مسیر جدیدی را برای تحلیل گرافهای مبتنی بر متن ایجاد کرده است. مدلهای زبانی بزرگ از آن جهت اهمیت دارند که میتوانند اطلاعات معنایی، تغییر موضوعات، روابط و نشانههای زبانی را که در دادههای متنی که در گرافی وجود دارند، استخراج و مدلسازی کنند. با این حال، LLMها ذاتا برای تحلیل توپولوژی و ساختار شبکه طراحی نشدهاند و از طرف دیگر، مدلهای گرافی نیز در پردازش معنا محدودیت دارند؛ بنابراین، همگرایی این دو حوزه یعنی LLM و GNN بهعنوان یک رویکرد نوظهور مطرح شده است.
پژوهشها نشان میدهند که ترکیب این دو خانواده مدل، افقهای جدیدی را برای تحلیل دقیقتر و قابلتفسیرتر گرافهای پویا گشوده است. با این وجود، ادبیات این حوزه هنوز پراکنده است و یک چارچوب نظاممند برای توصیف مسیرهای اصلی پژوهش وجود ندارد. علاوه بر این، شکافهایی مانند نحوه ادغام مؤثر معنا با ساختار و زمان، مقابله با سوگیریهای ساختاری و کاهش هزینههای محاسباتی همچنان چالشبرانگیز باقی ماندهاند.
بر همین اساس، هدف این گزارش مروری آن است که رویکردهای موجود برای ادغام LLMها با GNNها در تحلیل DyTAGs را دستهبندی، تحلیل و ارزیابی کند. در این پژوهش، مجموعهای از مقالات معتبر بررسی شده و تلاش شده است تا مسیرهای اصلی، نقاط قوت، محدودیتها و شکافهای پژوهشی شناسایی شود تا بنیانی برای توسعه مدل پیشنهادی در مراحل بعدی فراهم گردد.
هدف این فصل، ارائه یک پایه نظری و مفهومی برای پژوهش حاضر است تا خواننده بتواند فصول بعدی را به خوبی درک کند. در این فصل، ابتدا مفاهیم کلیدی و اصول بنیادین در حوزههای مدلهای زبانی بزرگ و شبکههای پیچیده پویا معرفی میشوند و سپس اصطلاحات و واژگان تخصصی مرتبط با این فرآیند تشریح میگردد.
مدلهای زبان بزرگ نسل جدیدی از سامانههای یادگیری عمیق هستند که با اتکا به معماری مبدل[3] و آموزش بر روی مقدار زیادی از دادههای متنی، توانایی درک و تولید زبان طبیعی و کد منبع را پیدا کردهاند.
برخلاف مدلهای قدیمیتر مانند RNN و LSTM که اطلاعات را به صورت ترتیبی پردازش میکردند و در به خاطر سپردن وابستگیهای طولانیمدت ضعیف بودند، مکانیزم توجه[4] در این معماری به مدل اجازه میدهد در هر لحظه، به تمام بخشهای دیگر ورودی توجه کند. این قابلیت برای فهم زمینه و روابط شبکههای پیچیده حیاتی است. مدلهای مدرن مانند GPT و Llama میتوانند این روابط را شناسایی و کشف کنند.
برای دستیابی به نتایج دقیق و کاربردی از مدلهای زبان بزرگ، صرف انتخاب یک مدل قدرتمند کافی نیست، بلکه چگونگی تعامل و به کارگیری آن نقشی حیاتی دارد. بخش بزرگی از تحقیقات این حوزه به توسعه و ارزیابی روشهایی اختصاص یافته است که بتوانند حداکثر پتانسیل این مدلها را برای وظایف پیچیدهای مانند تحلیل شبکههای پیچیده پویا استخراج کنند. سه تکنیک اصلی و کلیدی در این زمینه شامل مهندسی فرمان[5]، تنظیم دقیق[6] و تولید افزوده با بازیابی[7] است که هر یک رویکرد متفاوتی را برای بهینهسازی عملکرد مدل دنبال میکنند.
شبکههای پیچیده پویا دستهای از ساختارهای گرافی هستند که در آنها نه تنها روابط میان موجودیتها، بلکه خود موجودیتها و ویژگیهای آنها در طول زمان دستخوش تغییر میشوند. بر خلاف شبکههای ایستا که ساختار آنها یک بار تعریف شده و ثابت فرض میشود، شبکههای پویا قابلیت نمایش پدیدههایی را دارند که ماهیت زمانی، تکاملی یا رفتاری دارند؛ مانند شبکههای اجتماعی، تعاملات کاربران، ارتباطات علمی و شبکههای ارتباطی.
شبکههای پویا معمولا با سه ویژگی اصلی شناخته میشوند:
· ساختار در حال تغییر[8] :یالها ممکن است ایجاد، حذف یا تقویت شوند؛ گرهها ممکن است اضافه یا حذف گردند. این تغییرات ساختاری، الگوهای تکاملی شبکه را شکل میدهد.
· اطلاعات زمانی[9]: توالی رخدادها و ترتیب زمان وقوع آنها نقش کلیدی در تحلیل دارد. دو رابطه مشابه ممکن است بسته به زمان ثبتشدن کاملا معنای متفاوتی داشته باشند.
· ویژگیهای تکاملی[10]: گرهها و یالها ممکن است ویژگیهایی داشته باشند. از جمله ویژگیهای عددی یا حتی متنی که در طول زمان تغییر میکنند و تحلیل را پیچیدهتر میسازند.
شبکههای عصبی گراف، خانوادهای از مدلهای یادگیری عمیق هستند که برای تحلیل دادههایی طراحی شدهاند که دارای ساختار گرافیاند؛ یعنی دادههایی که روابط بین موجودیتها نقش مهمتری از خود ویژگیها دارند. برخلاف شبکههای عصبی کلاسیک که ورودی آنها به صورت بردار یا ماتریس است، GNNها میتوانند وابستگیهای غیرخطی و ناهمگن میان گرهها را مدل کنند.
هسته اصلی GNNها بر پایه دو فرآیند است:
· انتشار پیام[12]: هر گره پیامهایی را از همسایههای خود دریافت میکند که شامل ویژگیها و روابط آنهاست.
· تجمیع و بهروزرسانی[13]: مدل با تجمیع پیامهای دریافتی و ترکیب آنها با ویژگیهای خود گره، یک نمایش برداری[14] جدید و غنیتر تولید میکند.
تصویر ۲ فرایند اصلی یادگیری در GNN را نشان میدهد؛ جایی که مدل با استفاده از سازوکار انتشار پیام در چندین لایه، اطلاعات ساختاری گراف را بهتدریج غنیتر میکند. در ابتدا، گرهها تنها دارای ویژگیهای اولیه خود هستند، اما در هر لایه پنهان، هر گره پیامهایی را از همسایههایش دریافت کرده و آنها را از طریق یک تابع تجمیع با ویژگی فعلی خود ترکیب میکند. سپس نتیجه حاصل با استفاده از یک تابع فعالساز مانند ReLU بهروزرسانی شده و بهعنوان نمایش جدید گره ذخیره میشود. با عبور از چندین لایه، گرهها علاوه بر همسایههای نزدیک، اطلاعات نواحی دورتر شبکه را نیز درک میکنند و در نهایت در بخش خروجی، یک نمایش معنادار از گراف تولید میشود که میتواند برای پیشبینی لینک، طبقهبندی گره یا تحلیل ساختار شبکه به کار رود. این تصویر نمای روشنی از این فرایند تکرارشونده ارائه میدهد و نشان میدهد که چگونه GNNها قادر هستند روابط پیچیده و وابستگیهای چندلایه در شبکههای واقعی را مدلسازی کنند.
![تصویر ۲. سازوکار انتشار پیام در شبکههای عصبی گراف [4]](https://files.virgool.io/upload/users/449482/posts/qpn0wabmd7fn/cxx2uylmmkwk.jpg)
با رشد همزمان شبکههای پیچیده پویا و مدلهای زبانی بزرگ، ادبیات پژوهشی جدیدی در تقاطع این دو حوزه شکل گرفته است که هدف آن، ارتقای توان تحلیل گرافهایی است که علاوه بر پویایی ساختاری و زمانی، حامل اطلاعات متنی و معنایی نیز هستند. این دسته از گرافها که در این پژوهش با عنوان گرافهای پویا با ویژگیهای متنی (DyTAGs) شناخته میشوند، چالشهایی فراتر از مدلهای کلاسیک گراف و حتی GNNهای متداول ایجاد میکنند؛ چرا که نیازمند درک همزمان توپولوژی، تحول زمانی و معنا هستند.
در پاسخ به این چالشها، پژوهشهای سالهای اخیر به سمت بهرهگیری از ظرفیت مدلهای زبانی بزرگ حرکت کردهاند. مدلهای زبانی بزرگ با توانایی بالای خود در استخراج معنا، استدلال و مدلسازی وابستگیهای بلندمدت، مکمل مناسبی برای مدلهای گرافی محسوب میشوند. با این حال، نحوهی ادغام این دو خانواده، خود به یک مسئلهی پژوهشی مستقل تبدیل شده و راهکارهای متنوعی در ادبیات ارائه شده است.
با بررسی ادبیات پژوهشی منتشرشده در سالهای اخیر، مشاهده میشود که روشهای ادغام مدلهای زبانی بزرگ با شبکههای عصبی گراف برای تحلیل گرافهای پویا با ویژگیهای متنی را میتوان، بر اساس نقش مدل زبانی بزرگ در فرآیند یادگیری و استدلال، در چند دستهی اصلی طبقهبندی کرد که در این فصل به بررسی آنها خواهیم پرداخت.
در ادامه، هر یک از این رویکردها بهصورت مجزا معرفی شده و با تمرکز بر ایدهی اصلی، معماری کلی، حوزههای مورد استفاده و محدودیتهای آنها بررسی میشوند. این پژوهش، علاوه بر ترسیم چشمانداز پژوهشهای موجود، زمینهی لازم برای شناسایی شکافهای پژوهشی و طراحی مدلهای ترکیبی پیشرفتهتر در مراحل بعدی را نیز فراهم میسازد.
در این دسته از روشها، مدلهای زبانی بزرگ در نقش مدل معلم[16] و شبکههای عصبی گرافی سبکوزن[17] در نقش مدل دانشجو[18] به کار گرفته میشوند. انگیزهی اصلی این رویکرد، پرهیز از استفادهی مستقیم و مداوم از مدلهای زبانی بزرگ در فرآیند استنتاج است؛ امری که به دلیل هزینههای محاسباتی بالا، زمان پاسخگویی طولانی و محدودیتهای استقرار، در سناریوهای مقیاسپذیر و بلادرنگ عملا غیرقابل استفاده است. در عوض، تواناییهای معنایی مدلهای زبانی بزرگ برای تولید سیگنالهای آموزشی به کار گرفته میشود تا مدلهای گرافی بتوانند این دانش را در فرم فشرده و کارآمد استفاده کنند.
ایدهی اصلی این رویکرد، کاهش شکاف میان ویژگیهای مختلف داده است؛ بهگونهای که GNNها بتواند بازنماییهایی را بیاموزد که نه تنها ساختار توپولوژیک شبکه، بلکه مفاهیم انتزاعی و معنایی نهفته در متون مرتبط با گرهها و یالها را نیز در بر گیرد. این مسئله در گرافهای پویا با ویژگیهای متنی اهمیت ویژهای دارد، زیرا تغییرات زمانی در یالها و گرهها، اغلب بازتابدهندهی تحولات معنایی روابط هستند؛ تحولاتی که مدلهای ساختارمحور قادر به درک کامل آنها نیستند. از این رو، این دسته از روشها برای وظایفی مانند پیشبینی پیوند و دستهبندی یالها در گرافهای پویا بسیار مناسب هستند.
از منظر معماری، فرآیند یادگیری بهصورت نامتقارن و سلسلهمراتبی طراحی میشود. در مرحلهی نخست، مدل زبانی بزرگ با تحلیل متون مرتبط با همسایگی گرهها یا یالها، بازنماییهای معنایی یا برچسبهای شبهحقیقی تولید میکند. این خروجیها مستقل از ساختار گراف و مبتنی بر درک زبان توسط مدل معلم هستند. در مرحلهی بعد، شبکهی عصبی گرافی با استفاده از سازوکارهای پیامرسانی[19] و کدگذاریهای زمانی[20]، بازنماییهای مبتنی بر ساختار گراف را میآموزد. ارتباط میان این دو فضا از طریق توابع زیان[21] مبتنی بر شباهت یا فاصله برقرار میشود؛ بهطوری که مدل دانشجو مجبور میشود بازنماییهای خود را با بازنماییهای معنایی مدل معلم همراستا سازد.
نتیجهی این فرآیند آن است که مدل GNN، علیرغم سادگی و کارایی محاسباتی، بهطور غیرمستقیم از توان پردازش زبان و استدلال مدلهای زبانی بزرگ بهرهمند میشود. همزمان، وجود کدگذاریهای زمانی در شبکهی عصبی گرافی امکان مدلسازی الگوهای تکاملی شبکه را فراهم میسازد؛ الگوهایی که مدلهای زبانی بزرگ، به دلیل ماهیت عمدتا ایستای خود، حساسیت کمی نسبت به آنها دارند. در این همافزایی، مدل زبانی سیگنالهای متنی را پالایش کرده و معنای روابط را استخراج میکند، در حالی که مدل گرافی پویایی ساختار شبکه را در طول زمان یاد میگیرد. نتایج تجربی گزارششده بر روی مجموعه دادههای واقعی نشان میدهد که این راهبرد میتواند بدون تحمیل هزینههای استفادهی مستقیم از مدلهای زبانی بزرگ، به بهبود معنادار دقت در وظایف پیشبینی پیوند و دستهبندی یال در گرافهای پویا منجر شود. [1]
یک نمونه شاخص از این دسته، چارچوب LKD4DyTAG است. در این روش همانطور که در تصویر ۳ مشاهده میشود، مدل زبانی بزرگ با پردازش متنهای مرتبط با یالها، بازنماییهای معنایی تولید میکند. این بازنماییها بهعنوان مرجع برای GNN به کار میروند که مجهز به کدگذاری زمانی است و هدف آن یادگیری بازنمایی از ساختار گراف است. همترازی این دو فضا از طریق کمینهسازی فاصله میان بردارهای معنایی معلم و بردارهای ساختاری–زمانی دانشجو انجام میشود. نتایج تجربی نشان میدهد که این رویکرد، بدون نیاز به استفادهی مستقیم از مدل زبانی در زمان استنتاج، میتواند دقت پیشبینی پیوند و دستهبندی یال را در مجموعهدادههای واقعی و پویا مانند Enron و GDELT بهطور معناداری بهبود دهد. ترکیب تقطیر دانش با کدگذاریهای زمانی به شبکهی عصبی گرافی اجازه میدهد الگوهای تکاملی شبکه را که ممکن است از دید مدلهای زبانی ایستا پنهان بمانند، بهخوبی شناسایی کند. [1]
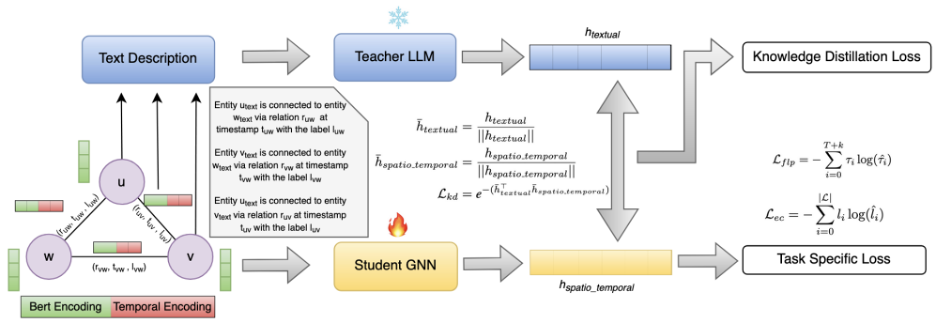
دسته دوم، بر استفاده از مدلهای زبانی بزرگ به عنوان ابزار هوشمند برای یادگیری و بهینهسازی ساختار گراف تمرکز دارد. در بسیاری از شبکههای واقعی، برخی یالها ممکن است به دلیل خطا در جمعآوری دادهها نادرست باشند یا یالهای مهم ثبت نشده باشند. این رویکرد با بهرهگیری از تواناییهای متنی مدلهای زبانی، متنهای مرتبط با هر گره را تحلیل میکند و با استفاده از دانش عمومی و منطق، یالهای جدید پیشنهاد داده یا یالهای غیرمرتبط را حذف میکند تا ساختار گراف برای مدلهای پاییندستی مانند GNN بهینه شود.
فرآیند اجرایی معمولا شامل تنظیم دستورالعمل برای مدل زبانی است تا بتواند بر اساس اصل هموفیلی، یعنی شباهت گرههای متصل، در مورد وجود یا عدم وجود روابط تصمیمگیری کند. یک نمونه عملی از این رویکرد، مدل GraphEdit است که یک فرآیند سه مرحلهای برای پالایش گراف ارائه میدهد: ابتدا مدل زبانی برای استدلال درباره برچسبها و تحلیل معنایی یالها آموزش میبیند؛ سپس یک پیشبین یال برای غربال کردن جفتگرههای کاندید اعمال میشود و در نهایت، مدل زبانی برای اصلاح نهایی ماتریس مجاورت به کار گرفته میشود. این متدولوژی نه تنها میزان اعتماد گراف را در مواجهه با نویز افزایش میدهد، بلکه با کشف وابستگیهای پنهان میان گرهها که در ساختار اولیه مشاهده نمیشدند، دقت طبقهبندی گرهها را در مجموعهدادههای کلاسیک مانند Cora و Citeseer بهبود میبخشد. [8]
تصویر ۴ سه مرحله مدل GraphEdit را نشان میدهد. در مرحله اول، یک پرامپت شامل اطلاعات هر جفت گره و ویژگیهای متنی مرتبط، به LLM داده میشود. مدل با استفاده از تنظیم دستورالعمل[22] آموزش میبیند تا بتواند تصمیم بگیرد که آیا یک یال بین دو گره باید وجود داشته باشد یا خیر و همچنین دستهبندی معنایی یالها را مشخص کند. در گام بعدی، ویژگیهای متنی هر گره مانند عنوان و چکیده، توسط یک رمزگذار[23] با توجه به LLM آموزشدیده تبدیل به بردارهای عددی میشوند. این بازنماییها سپس به یک Edge Predictor داده میشوند که احتمال وجود یال بین هر جفت گره را تخمین میزند. در مرحله پایانی، LLM دوباره وارد عمل میشود و با استفاده از بازخورد مرحله دوم و دانش زمینهای خود، ماتریس مجاورت گراف را اصلاح نهایی میکند. یالهای نادرست حذف شده و یالهای مرتبط که در ساختار اولیه دیده نمیشدند، اضافه میشوند. نتیجه این فرآیند، یک گراف بهینه است که هم قابل اعتماد و هم برای مدلهای گرافی (مانند GNN) مناسب است.
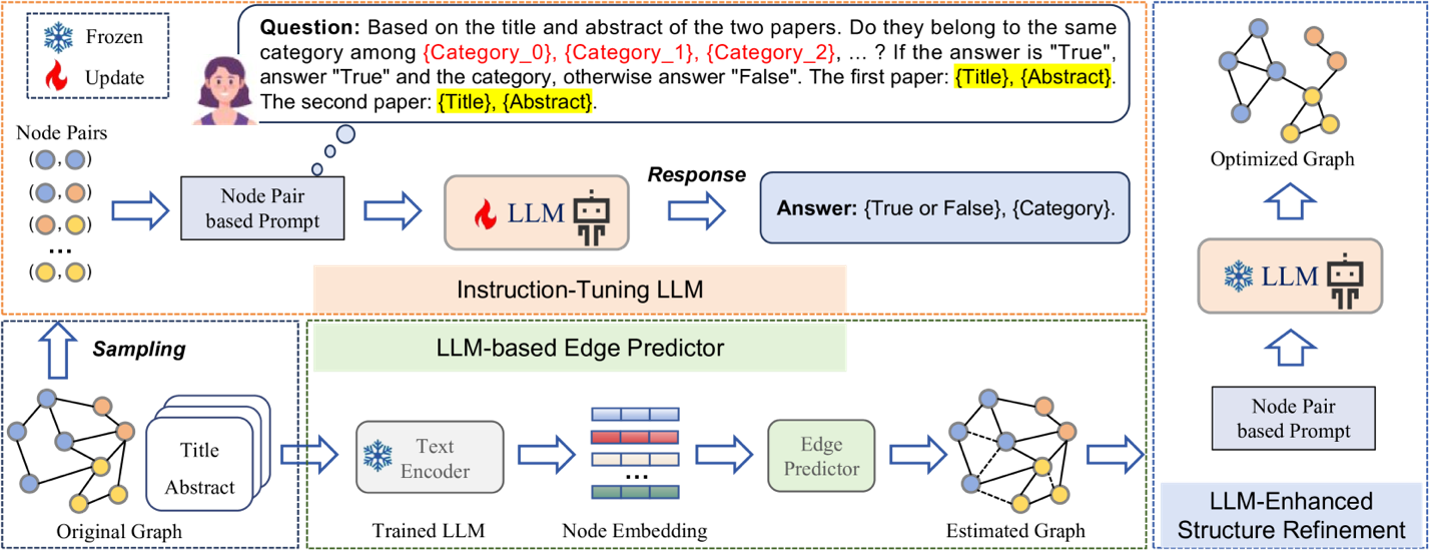
مدل GraphEdit از یک پرامپت با دو هدف متفاوت استفاده میکند که در آن از مدل زبانی پرسیده میشود: ۱) آیا این دو گره متعلق به یک طبقه هستند؟ و ۲) طبقه دقیق آنها چیست؟. این رویکرد به مدل اجازه میدهد تا فراتر از اطلاعات محلی در مورد همسایگیها، یک دیدگاه کلی نسبت به روابط گرهها پیدا کند. آزمایشها نشان داده است که حذف یالهای نویزدار در مجموعهدادههای پرتراکم و اضافه کردن یالهای معنایی در گرافهای پراکنده[24]، منجر به بهبود چشمگیر پایداری GNN میشود [8].
پژوهش [12] یک چارچوب نوآورانه برای انجام طبقهبندی label-free روی گرافهای دارای متن ارائه میدهد. این مسئله از آنجا اهمیت دارد که در بسیاری از کاربردهای گرافهای واقعی، مانند شبکههای علمی یا اجتماعی، تهیهی برچسبهای با کیفیت برای همهی گرهها بسیار زمانبر و پرهزینه است؛ در حالی که مدلهای GNN بدون دادهی برچسبدار دقیق و درست عملکرد مطلوبی ندارند و مدلهای زبانی بزرگ اگرچه در طبقهبندی Zero-Shot قوی هستند، قادر به استفادهی مستقیم از ساختار گراف نیستند و برای تمام گرهها استدلال مؤثر انجام نمیدهند.
در این چارچوب، هدف انجام یک تسک یادگیری (مثلا طبقهبندی گرهها) بدون دسترسی به هیچ برچسب انسانی از پیش مشخصشده است. برخلاف روشهای supervised یا semi-supervised که به مجموعهای از گرههای برچسبدار برای شروع نیاز دارند، در این رویکرد فرض میشود که هیچ برچسب واقعی در زمان آموزش در دسترس نیست و مدل باید تنها بر پایهی ساختار داده، ویژگیها و دانش قبلی تصمیمگیری کند.
برای غلبه بر این دو محدودیت، چارچوبی به نام Locle معرفی شد. ایدهی اصلی Locle این است که ترکیبی از LLM و GNN را در یک پروسهی خودآموز قرار دهد تا از قدرت زبانی و دانش جهانی LLM بهره ببرد و در عین حال از قدرت ساختاری و تعمیمپذیری GNN برای کل گراف استفاده کند. این الگوریتم در سه بخش کلیدی طراحی شده است.
مرحله اول انتخاب گرههای فعال برای برچسبزنی اولیه است. یعنی به جای ارسال تمام گرهها به LLM برای طبقهبندی، Locle با استفاده از نمایشهای برداری GNN از گراف، مجموعهای از نمونههای نماینده را انتخاب میکند که بیشترین سود در مراحل بعد را دارند. این انتخاب با هدف کاهش هزینهی فراخوانی LLM و افزایش کیفیت دادههای تولیدی انجام میشود.
در مرحله بعد گرههای اطلاعاتی و مهمتر انتخاب میشوند. در طول فرایند خودآموزی، الگوریتم با استفاده از معیارهایی چون آنتروپی، گرههایی را که در آنها مدل نسبت به برچسبهای فعلی مطمئن نیست، تشخیص میدهد. این گرهها سپس به LLM فرستاده میشوند تا برچسبهای دقیقتر تولید شود. و در آخر برای کاهش اثر منفی نویز در برچسبهای تولیدشده، Locle از یک ماژول فیلترینگ استفاده میکند که احتمال برچسبهای اشتباه کاهش یابد و اطلاعات ساختاری بهتر حفظ شود.
در نهایت، این برچسبهای پالایششده به عنوان دادهی آموزشی برای آموزش نهایی GNN استفاده میشود، که نتیجهی آن طبقهبندی دقیقتر روی کل گراف است.
در این چارچوبها، LLMها نه صرفا به عنوان ابزار پردازش متن، بلکه به عنوان دستیار گراف مطرح میشوند که قادر است دانش زبانی و توان استدلال خود را به حوزهی ساختاری گراف منتقل کنند. چالش اصلی در این مسیر، شکاف نمایشی میان دادههای گرافی و فضای توکنی LLMها است؛ زیرا گرافها ذاتا ساختارمند، ناهمگون و غیرخطیاند، در حالی که LLMها بر توالیهای خطی از توکنها عمل میکنند. روشهایی مانند LLaGA و HiGPT دقیقا با هدف پر کردن این شکاف طراحی شدهاند و تلاش میکنند گراف را به شکلی معنادار، فشرده و آگاه از ساختار به فضای قابل پردازش توسط LLM نگاشت کنند، بدون آنکه ماهیت عمومی و انعطافپذیر مدل زبانی از بین برود.
یکی از چارچوبهای مطرح در این روش LLaGA است که توانایی LLMها را به حوزهی دادههای گرافی گسترش میدهد، بهگونهای که یک مدل واحد بتواند روی وظایف مختلف گرافی از جمله طبقهبندی گره، پیشبینی پیوند و تولید گراف عملکرد رقابتی و قابلتعمیم داشته باشد. [11] در این راستا این روش دو نوآوری کلیدی دارد:
1. ترجمه ساختار گراف به توالیهای آگاه از ساختار: بهجای توصیفات متنی ساده و طولانی از گراف، LLaGA گرهها و همسایگیهای آنها را با استفاده از قالبهایی مانند Neighborhood Detail Template و Hop-Field Overview Template تبدیل به توالی میکند که هم اطلاعات محلی و هم جهانی (Global) ساختار را حفظ کند.
2. تطبیقدهنده نگاشت: پس از تبدیل گراف به توالی، این توالیها باید به فضای embedding توکنهای LLM نگاشت شوند. یک تطبیقدهنده آموزشدیده این نگاشت را انجام میدهد تا دادهی گرافی و فضای توکنی LLM در یک نمای مشترک قرار گیرند. (برای مثال علاوه بر تگهای اولیه مدلهای زبانی، یکسری تگ جدید خاص گرافها نیز تعریف میشوند.)
گرافهای ناهمگن شامل چندین نوع گره و یال با معنای متفاوت هستند — مانند شبکهای که کاربران، فیلمها و دستهبندیها را با روابط مختلف پیوند میدهد. یادگیری در چنین گرافهایی مستلزم درک پیچیدگی معنایی روابط متعدد است. روشهای سنتی بر مبنای HGNNها معمولا به یک مجموعه دادهی خاص آموزش داده و سپس همان را تنظیم دقیق میکنند؛ این باعث میشود که توانایی تعمیم به گرافهایی با رابطهها و توکنهای متفاوت محدود شود. HiGPT یک مدل زبانی گرافی است که برای تعامل مستقیم با گرافهای ناهمگن در مقیاس گسترده و بدون نیاز به تنظیم دقیق در هر مجموعه داده طراحی شده است [9].
HiGPT با معرفی یک توکنایزر ناهمگن در زمینه[25]، گرافهای پیچیده را به توکنهایی تبدیل میکند که نوع گرهها و روابط را بهصورت صریح در خود کدگذاری میکنند و به LLM اجازه میدهند ساختار گراف را درون پرامپت درک کند. این نگاشت بدون نیاز به تمپلیتهای دستی یا تغییر معماری انجام میشود و ماهیت عمومی مدل زبانی را حفظ میکند.
این چارچوب با هدف رفع یکی از اساسیترین چالشهای استفاده از مدلهای زبانی بزرگ در تحلیل گرافهای ناهمگن طراحی شده است؛ یعنی Computational Explosion و Multi-hop Reasoning. اگرچهLLM ها از نظر مفهومی توانایی استدلال روی ساختارهای گرافی را دارند، اما در مواجهه با گرافهای بزرگ و ناهمگن، توصیف تمام مسیرهای ممکن باعث افزایش شدید طول توالی ورودی و در نتیجه افت کارایی و پایداری مدل میشود. این مدل دقیقا با هدف حل این مسئله ارائه شده و تلاش میکند استدلال روی گراف را به شکلی فشرده، خطی و سازگار با معماری LLMها بازنمایی کند [9].
این چارچوب هم در پارادایم GNN as Prefix قرار میگیرد؛ به این معنا که شبکههای عصبی گرافی به عنوان یک ماژول پیشپردازشی عمل میکنند که اطلاعات ساختاری، ناهمگونی و وابستگیهای محلی گراف را استخراج کرده و سپس این اطلاعات به صورت یک پیشوند به ورودی LLM تزریق میشود. در این معماری، GNN مسئول یادگیری سوگیری القایی ساختاری[26] است، در حالی که LLM نقش استدلال سطحبالا[27]، تعمیمپذیری[28] و تفسیرپذیری[29] را بر عهده دارد.
نوآوری اصلی در معرفی یک توکنایزر آگاه از رابطه[30] است که هدف آن نمایش موثر مسیرهای چندمرحلهای در گرافهای ناهمگن برای مدلهای زبانی بزرگ است. مسئلهی اصلی در این نوع گرافها آن است که نمایش صریح همهی مسیرهای multi hop باعث افزایش شدید تعداد توکنها شده و استفاده از آنها را در محدودیت پنجرهی زمینهی LLM عملا غیرممکن میکند.
برای مثال، در یک گراف علمی، یک گره از نوع Author از طریق رابطهی writes به یک Paper متصل باشد، آن مقاله در یک Conference ارائه شده باشد و آن کنفرانس به یک Research Area مربوط شود. نمایش مستقیم این مسیر چهار مرحلهای مستلزم وارد کردن تمام گرهها و روابط بهصورت متوالی در ورودی مدل است که با افزایش تعداد مسیرها، به رشد نمایی توکنها منجر میشود.
این روش به جای این نمایش صریح، کل این مسیر را در قالب یک توکن فشردهی رابطهای کدگذاری میکند. این توکن به طور خلاصه اطلاعات کلیدی مسیر، شامل نوع روابط، جهت ارتباطها و نقش معنایی مسیر را در خود نگه میدارد، بدون آنکه نیاز باشد تمام گرههای میانی به صورت جداگانه به مدل داده شوند.
در نتیجه، بهجای آنکه تعداد توکنها با تعداد مسیرهای ممکن بهصورت نمایی افزایش یابد، پیچیدگی محاسباتی تنها به صورت خطی نسبت به طول مسیر رشد میکند. این ویژگی به مدل زبانی اجازه میدهد تا حتی در گرافهای بزرگ و ناهمگن، استدلال چند مرحلهای انجام دهد و روابط غیرمستقیم بین گرهها را بهدرستی تحلیل کند، بدون آنکه محدودیت طول ورودی LLM مانعی ایجاد کند.
در فرآیند عملی، GNN ابتدا روی گراف ناهمگن اعمال میشود تا نمایشهای نهفته[31] آگاه از نوع گره و رابطه تولید کند. سپس این نمایشها توسط یک توکنایزر RA به توکنهای رابطهای فشرده تبدیل شده و بهعنوان prefix به ورودی LLM افزوده میشوند. این prefix در واقع یک خلاصه ساختاری از زیرگراف موردنظر است که به LLM کمک میکند بدون مشاهدهی مستقیم کل گراف، درک دقیقی از زمینهی ساختاری مسئله داشته باشد.
از منظر معماری در این درسته از روشها، ایده اصلی مقیاسپذیری LLMها در حوزهی گراف، تفکیک نقشها میان ماژولهاست: GNN مسئول مدلسازی ساختار و کاهش پیچیدگی ترکیبی است، در حالی که LLM بر استنتاج، ترکیب دانش و تصمیمگیری نهایی تمرکز میکند.
گرافهای پویا با ویژگی متنی که به اختصار DyTAG نامیده میشوند، به عنوان یکی از پیچیدهترین و غنیترین ساختارهای داده در دنیای واقعی شناخته میشوند که تلاقی سه قلمرو حیاتی در علوم داده هستند: نظریه گراف، مدلسازی زمانی و پردازش زبان طبیعی. در دنیای امروز، دادهها به ندرت به صورت استاتیک یا تک بعدی باقی میمانند. شبکههای اجتماعی، سیستمهای تجارت الکترونیک، شبکههای استنادی و جریانهای ارتباطی همگی نمونههایی از DyTAGها هستند که در آنها نه تنها ساختار شبکه (چه کسی با چه کسی در ارتباط است) بلکه ویژگیهای متنی (محتوای پیامها، نظرات یا توضیحات) در طول زمان تکامل مییابند. برخلاف گرافهای استاتیک با ویژگیهای متنی (TAGs) که در آنها گرهها معمولا ویژگیهای متنی ثابتی دارند، در DyTAGها هر تعامل میتواند با یک متن جدید همراه باشد و ویژگیهای گرهها نیز ممکن است در پاسخ به این تعاملات تغییر کنند. این بخش به بررسی عمیق ماهیت، دستهبندی و متدولوژیهای یادگیری بر روی این ساختارها میپردازد.
هر سه بعد زمانی، ساختاری و متنی این گرافها بسیار مهم است. مدلهای یادگیری که تنها بر روی یک یا دو وجه تمرکز میکنند، بخش بزرگی از اطلاعات را از دست میدهند. به عنوان مثال، در یک شبکه تجارت الکترونیک، گرهها (کاربران و کالاها) دارای ویژگیهای متنی هستند و تعاملات (خرید یا نظردهی) به صورت یالهای زماندار نمایش داده میشوند. نادیده گرفتن متن بررسیها به معنای از دست دادن دلیل رفتار کاربر است، در حالی که نادیده گرفتن زمان تعامل به معنای از دست دادن تغییر علایق کاربر در طول زمان خواهد بود.
یکی از اساسیترین روشهای طبقهبندی گرافهای متنی پویا، بر اساس نحوه نمایش و مدیریت زمان در آنها است. این تقسیمبندی تأثیر مستقیمی بر انتخاب معماری مدلهای یادگیری عمیق و نحوه نمونهبرداری از دادهها دارد.
در این دسته گرافها به دو خانواده اصلی تقسیم میشوند:
· گرافهای با ویژگی متنی با زمان گسسته
· گرافهای با ویژگی متنی با زمان پیوسته
در مدلهای زمان گسسته، تکامل گراف به صورت مجموعهای از اسنپشاتها در بازههای زمانی مشخص نمایش داده میشود. هر اسنپشات شامل گرهها، یالها و ویژگیهای متنی فعال در آن زمان است. این روش برای مشاهده تغییرات تدریجی و روندهای کلی مناسب است. یادگیری در این مدلها در دو مرحله انجام میشود:
1. استخراج ویژگیهای ساختاری و متنی از هر اسنپشات با کمک GNN و LLM
2. مدلسازی تکامل این ویژگیها در طول زمان با استفاده از مدلهای توالی مانند RNN ،LSTM یا Transformer
چالش اصلی این روش این است که اطلاعات بین اسنپشاتها ممکن است از دست برود و تعداد زیاد اسنپشاتها هزینه محاسباتی را افزایش میدهد.
در مدلهای زمان پیوسته، گراف به صورت جریان رویدادهای زمانبندی شده نمایش داده میشود. هر رویداد شامل دو گره درگیر، زمان دقیق و ویژگی متنی یا تعامل مرتبط است. این رویکرد به مدل اجازه میدهد تغییرات سریع و محلی را با دقت بالا دنبال کند و برای سیستمهایی که زمان دقیق تعامل اهمیت دارد (مانند معاملات مالی) حیاتی است. برای یادگیری، معمولا از شبکههای عصبی گرافی زمانی (TGNNs) استفاده میشود که بازنماییهای گره را در هر لحظه بهروز میکنند.
در مدلسازی DyTAGها، یک تفاوت کلیدی در نحوه نگاه به واحد اصلی تکامل وجود دارد. بر اساس این تفاوت، دو رویکرد اصلی شکل گرفته است: یالمحور و گرهمحور. هر کدام دیدگاه متفاوتی نسبت به دادهها دارند و در یادگیری بازنمایی اثر خاص خود را دارند.
در روش یالمحور، تمرکز اصلی روی تعاملها است. یعنی برای هر یال، ویژگیهای متنی گرههای مبدا و مقصد، ویژگی متنی یال و زمان رخداد آن با هم ترکیب میشوند و به GNN داده میشوند تا ساختار محلی گراف را یاد بگیرد. این روش برای مسائل Link Prediction بسیار مناسب است.
اما در روشهای گرهمحور، تمرکز روی تکامل خود گرهها است. هر گره سه اطلاعات تاریخچه توپولوژیک، زمانی و متنی دارد که روی بازنمایی اثر میگذارند.
ماهیت موجودیتها و روابط در DyTAGها میتواند ساده یا پیچیده باشد که این موضوع منجر به شکلگیری دو دسته زیر میشود:
1. همگن: در این گرافها، تمامی گرهها از یک نوع و تمامی یالها نیز دارای یک معنای یکسان هستند. اکثر مدلهای اولیه DyTAG بر روی این ساختارها (مانند شبکههای ارسال ایمیل بین کارمندان) تمرکز داشتند.
2. ناهمگن: در دنیای واقعی، DyTAGها اغلب ناهمگن هستند (HTAGs). برای مثال، در یک شبکه استنادی علمی، گرهها میتوانند از انواع مقاله، نویسنده، مؤسسه یا کلمه کلیدی باشند. یالها نیز نشاندهنده روابط مختلفی مانند استناد کردن، همکاری در نوشتن یا وابستگی سازمانی هستند.
ظهور مدلهای زبانی بزرگ نقطه عطفی در تحلیل DyTAGها بوده است. با توجه به اینکه DyTAGها حاوی مقادیر عظیمی از متنهای در حال تغییر و تکامل هستند، مدلهای سنتی مانند BERT دیگر پاسخگو این شبکهها نیستند. روشهای ادغام LLM با DyTAG را میتوان به چهار دسته اصلی تقسیم کرد.
1. روشهای LLM as Prefix (ترتیبی): این سادهترین روش ادغام است که در آن LLM به عنوان یک استخراجکننده ویژگی عمل میکند. متنهای مربوط به گرهها یا یالها ابتدا توسط LLM پردازش شده و به بردارهای ویژگی تبدیل میشوند. سپس این بردارها به عنوان ویژگیهای ورودی به یک مدل گراف داینامیک (مانند TGN یا DySat) داده میشوند. مزیت این روش سادگی است، اما نقص بزرگ آن این است که LLM در هنگام پردازش متن، هیچ اطلاعی از ساختار گراف یا پویاییهای زمانی آن ندارد.
2. روشهای Parallel Orchestration و Alignment: در این مدل، دو جریان یادگیری به طور همزمان وجود دارد: یکی برای پردازش متن با استفاده از LLM و دیگری برای پردازش ساختار با استفاده از GNN. کلید موفقیت در این روش، Alignment بازنماییهای حاصل از این دو جریان است. برای مثال، در مدل MoMent از یک تابع زیان متقارن استفاده میشود تا اطمینان حاصل شود که بازنماییهای متنی و زمانی یک گره در فضای نهان به هم نزدیک هستند. این کار از ناپیوستگی فضای نهان جلوگیری کرده و انسجام معنایی و زمانی را تضمین میکند.
3. تقطیر دانش: در این استراتژی، از یک مدل زبانی بزرگ به عنوان معلم برای درک روابط معنایی عمیق بین متون تعاملات استفاده میشود. سپس یک مدل گرافی سبکوزن به عنوان دانشآموز آموزش میبیند تا بازنماییهای فضا-زمانی خود را به گونهای تنظیم کند که با بازنماییهای معنایی معلم مطابقت داشته باشد.
4. استدلال معنایی تطبیقی: برخی از مدلهای پیشرفته، به جای استفاده ساده از بردارها، از توانایی استدلال[32] مدلهای زبانی برای درک پویاییهای DyTAG استفاده میکنند.
ادغام مدلهای زبانی بزرگ با گرافهای متنی از منظر سازماندهی مدل به دو جهت اصلی تقسیم میشود: استفاده از LLM برای بهبود وظایف گرافی و استفاده از ساختار گراف برای تقویت استدلالهای مدل. در رویکردهای بدون نیاز به تنظیم، هدف اصلی بهرهبرداری از دانش پیشآموخته مدل بدون تغییر در وزنهای آن است. این امر از طریق استراتژیهای مختلفی همچون یادگیری در متن[33]، بازیابی تقویتشده[34] و استدلال عاملی[35] محقق میشود. [15]
محدودیتهای پرامپتهای ایستا، به ویژه ناتوانی آنها در مدیریت گرافهای بزرگ به دلیل محدودیت پنجره بافتار، منجر به توسعه چارچوبهای چند عاملی شده است. [16] سیستمهایی مانند GraphSearch و GraphChain، یادگیری گراف را به عنوان یک فرآیند اکتشافی پویا و چندمرحلهای در نظر میگیرند. [17]
مدل GraphSearch نمونهای برجسته از این رویکرد است که از دو بخش اصلی تشکیل شده:
· برنامهریز پرسوجوی آگاه از گراف[36]: به مدل استدلالی اجازه میدهد تا دستورات ساختارمندی را برای جستجو در قسمتهای مختلف گراف صادر کند. [16]
· بازیاب آگاه از گراف[37]: این بخش از سیگنالهای توپولوژیک به عنوان اولویتهای بازیابی استفاده میکند تا موارد مورد نیاز را از سراسر گراف جمعآوری کرده و در عین حال حجم بافتار را مدیریتپذیر نگه دارد.
این مدل در دو حالت عمل میکند: حالت بازگشتی (GraphSearch-R) که مشابه GNNها همسایگی را گامبهگام گسترش میدهد و حالت منعطف (GraphSearch-F) که به عامل اجازه میدهد بین محلههای محلی و جهانی بدون محدودیت گام جابجا شود. [16]
مدلسازی موضوعی یک روش یادگیری بدون نظارت برای کشف ساختارهای معنایی پنهان در مجموعهای از اسناد است. ایدهی اصلی این است که هر سند ترکیبی از چند موضوع و هر موضوع توزیعی از کلمات مرتبط است. روشهای کلاسیک مانند LDA و NMF با تکیه بر آمار و جبر خطی، سالها ابزار اصلی برای خوشهبندی متون و خلاصهسازی دادههای متنی بودهاند، اما در مواجهه با دادههای کوتاه، نویزی و پویا (مانند لاگهای سیستمی) محدودیت دارند.
در شبکهها، گرهها (کاربران، صفحات وب، یا حسابها) معمولا دارای محتوای متنی هستند و یالها نشاندهندهی تعامل یا ارتباط میان آنهاست. Topic Modeling این امکان را فراهم میکند که لایهی معنایی محتوا به گراف افزوده شود؛ به این معنا که گرهها نه تنها بر اساس اتصالات، بلکه بر اساس موضوعات غالبشان نیز تحلیل میشوند. تحقیقات نشان دادهاند که جوامع اغلب با همپوشانی موضوعی مشخصی همراه هستند و استخراج موضوعات میتواند به شناسایی دقیقتر ساختارهای پنهان شبکه کمک کند.
با معرفی مدلهای مبتنی بر embedding و سپس مدلهای زبانی بزرگ، مدلسازی موضوعی از یک ابزار آماری به یک روش تحلیل معنایی در گرافها تبدیل شده است. این مدلها قادرند موضوعات را متناسب با زمینهی ارتباطات شبکه استخراج کرده و حتی برای هر خوشه در گراف، توضیحی قابلفهم و انسانی ارائه دهند. در شبکههای اجتماعی، این رویکرد برای تحلیل جریان اطلاعات، شکلگیری گفتمانها و قطبیشدن گروهها بسیار مؤثر بوده و نسبت به روشهای صرفا ساختاری، درک دقیقتری از رفتار شبکه ارائه میدهد.
در مجموع، میتوان گفت که Topic Modeling از یک روش آماری برای خوشهبندی متون به ابزاری محوری برای تحلیل شبکههای پیچیده گرافی تبدیل شده است. در شبکههای اجتماعی و وب، معنا و ساختار بهصورت جداییناپذیر به هم گره خوردهاند و مدلسازی موضوعی با افزودن لایهی معنایی به گراف، امکان درک عمیقتری از جوامع، گفتمانها و رفتار جمعی کاربران فراهم میکند. ترکیب این رویکرد با مدلهای زبانی بزرگ، نه تنها دقت و تفسیرپذیری تحلیلها را افزایش داده، بلکه تحلیل پویایی موضوعات، شناسایی ترندهای نوظهور و فهم پدیدههایی مانند قطبیشدن و انتشار اطلاعات را ممکن ساخته است. از این رو، Topic Modeling امروز بهعنوان پلی میان محتوا، ساختار گراف و معنا، یکی از مؤلفههای کلیدی در تحلیل و فهم شبکههای اجتماعی مدرن به شمار میآید.
در این فصل، یک نمونه عملی از پیادهسازی مدلهای Temporal Graph Learning بر روی دادههای واقعی شبکههای اجتماعی ارائه و اجرا شده است. هدف، بررسی توانایی مدل در درک همزمان ساختار گراف، پویایی زمانی و اطلاعات متنی است. این پروژه با هدف پیشبینی تعاملات آتی کاربران در پلتفرم Reddit طراحی شده است. (برای درک بهتر به مخزن زیر مراجعه شود.)
https://github.com/MSaeed1381/reddit-tag-prediction
در این ارزیابی، از مجموعه داده tgbl-subreddit متعلق به بنچمارک استاندارد TGB (Temporal Graph Benchmark) استفاده شده است.
ماهیت دادهها: این دیتاست شامل تعاملات کاربران در پلتفرم Reddit با سابردیتهای مختلف است.
ویژگیهای گراف: دادهها به صورت یک گراف هستند که هر یال دارای یک برچسب زمانی (Timestamp) دقیق است.
اطلاعات متنی: برخلاف مدلهای سنتی، این دیتاست شامل ویژگیهای متنی (Textual Features) تعاملات است که با استفاده از مدل زبانی all-MiniLM-L6-v2 به بردارهای ۱۷۲ بعدی تبدیل شدهاند تا محتوای پستها نیز در پیشبینی لحاظ شود.
Number of nodes: 10,984 Number of edges: 672,447 Time range: [0, 2678390] Edge feature shape: (672447, 172) Edge feature dtype: float64
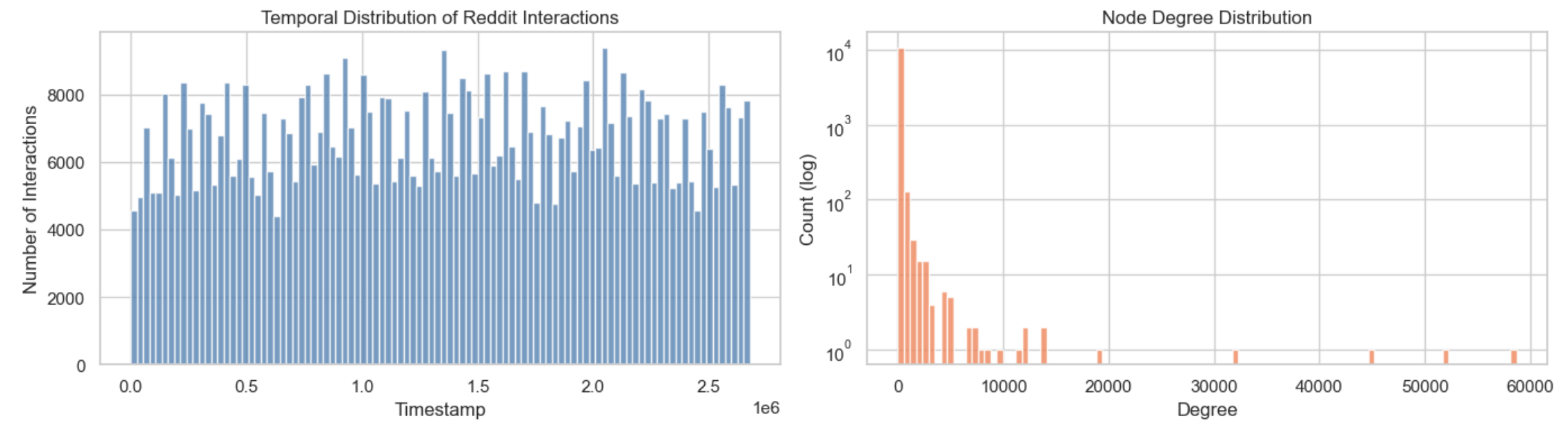
دادهها به سه بخش آموزش (Train)، اعتبارسنجی (Validation) و تست (Test) با رعایت اولویت زمانی تقسیم میشوند.
Train edges: 470,713 Val edges: 100,867 Test edges: 100,867 Total: 672,447
برای حل مسئله پیشبینی لینک در این گراف پویا، از معماری شبکه گراف زمانی استفاده شده است. این معماری از چهار بخش کلیدی تشکیل شده است:
ماژول حافظه (Memory Module): برای هر گره یک Hidden State در نظر گرفته میشود که با هر تعامل جدید و با استفاده از سلولهای GRU، تاریخچهی رفتار گره را بهروزرسانی میکند. (GRU مخفف Gated Recurrent Unit است. این یک نوع خاص از شبکههای عصبی بازگشتی (RNN) است که برای حل مشکل فراموشی در توالیهای طولانی طراحی شده است. شامل دو گیت Update Gate و Reset Gate است.)
کدگذار زمان (Time Encoder): با استفاده از توابع فوریه، فواصل زمانی بین تعاملات را به فضای برداری منتقل میکند تا مدل، تازگی یا قدیمی بودن یک رابطه را درک کند.
لایه توجه زمانی (Temporal Attention): این لایه به مدل اجازه میدهد هنگام پیشبینی یک لینک جدید بر روی مهمترین تعاملات گذشتهی آن گره تمرکز کند. (با استفاده از مکانیزم Multi-Head Attention)
پیشبینیکننده (Link Predictor): یک شبکه عصبی پرسپترون چندلایه (MLP) که امبدینگهای نهایی گرههای مبدا و مقصد را دریافت کرده و احتمال برقراری لینک را محاسبه میکند.
دقت پیشبینی: مدل به امتیاز MRR قابل توجهی دست یافت که نشاندهنده توانایی بالای آن در رتبهبندی سابردیتهای هدف است. این نتیجه در مقایسه با مدلهای ایستا بهبود قابل توجهی را نشان میدهد.
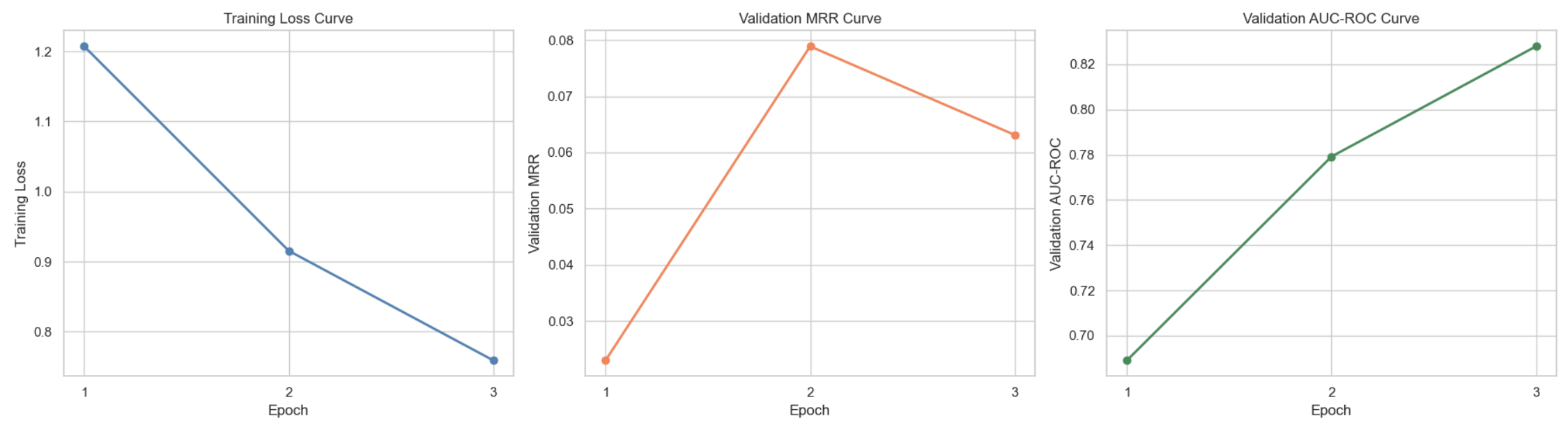
============================================================ TEXT-AWARE TEMPORAL LINK PREDICTION: FINAL SUMMARY ============================================================ Dataset: tgbl-subreddit Nodes: 10,984 Edges: 672,447 Edge Feature Dim: 172 Model: Temporal Graph Network (TGN) Memory Dim: 100 Embedding Dim: 100 Time Encoding: Learnable Fourier (100-dim) Aggregation: Temporal Attention Text Encoding: Sentence-Transformers (all-MiniLM-L6-v2) Test MRR: 0.0830 Test AUC-ROC: 0.7512 Test Avg Prec: 0.0030 Explainability: Integrated Gradients + Temporal Attention Epochs Trained: 3 ===========================================================
این پژوهش نشان میدهد که مدلهای زبانی بزرگ بهعنوان یک روش جذاب، ظرفیت قابلتوجهی برای غلبه بر محدودیتهای روشهای کلاسیک تحلیل شبکههای پیچیده پویا—به ویژه گرافهای پویا با ویژگیهای متنی (DyTAGs)—فراهم کردهاند. برخلاف رویکردهای سنتی که عمدتا بر ساختار ایستا یا وابستگیهای کوتاهمدت تمرکز دارند، LLMها قادرند معنا، زمینه و وابستگیهای بلندمدت نهفته در دادههای متنی را استخراج کرده و آنها را در تحلیل تکامل شبکه دخیل کنند. مرور نظاممند مطالعات ۲۰۲۱ تا ۲۰۲۶ نشان میدهد که این توانایی، به ویژه در وظایفی مانند پیشبینی پیوند، طبقهبندی گره، بازسازی ساختار گراف و تحلیل رویدادمحور، به بهبود معنادار دقت و تفسیرپذیری منجر شده است.
در عین حال، این پژوهش تأکید میکند که همگرایی LLM و GNN مسیر غالب پژوهشها بوده و در قالب چند استراتژی کلیدی شکل گرفته است: انتقال دانش از LLM به مدلهای گرافی سبکوزن، استفاده از LLM برای اصلاح و بهینهسازی ساختار گراف و نیز چارچوبهایی که گراف را مستقیما به فضای توکنی LLM نگاشت میکنند. این رویکردهای ترکیبی نشان دادهاند که میتوانند شکاف میان درک معنایی و مدلسازی ساختاری را پر کرده و شبکههای پویا را بهصورت غنیتر و آگاه از زمان تحلیل کنند. با این حال، این پژوهش تصریح میکند که هیچ راهحل واحد و فراگیری وجود ندارد و انتخاب معماری به ماهیت داده، مقیاس شبکه و نوع وظیفه وابسته است.
با وجود پیشرفتهای چشمگیر، این پژوهش به روشنی چالشهای باز را برجسته میکند؛ از جمله انفجار محاسباتی در گرافهای بزرگ و متراکم، دشواری استدلال چندمرحلهای روی ساختارهای پویا، همترازی فضای گراف و فضای زبانی و حفظ تفسیرپذیری در مقیاسهای بالا. افزون بر این، وابستگی بسیاری از روشها به دادههای برچسبدار یا تنظیم دقیق پرهزینه، مانعی برای تعمیمپذیری گسترده آنها محسوب میشود.
در نهایت، این پژوهش نتیجه میگیرد که آیندهی تحلیل شبکههای پیچیده پویا در گرو توسعهی مدلهای آگاه از زمان، تفسیرپذیر و مقیاسپذیر است که بتوانند تعادلی عملی میان قدرت استدلال معنایی LLMها و کارایی محاسباتی مدلهای گرافی برقرار کنند. مسیرهای پژوهشی آتی شامل طراحی پروژکتورهای مؤثرتر برای نگاشت گراف به فضای زبانی، روشهای tuning-free یا کمهزینه و چارچوبهایی است که بتوانند بهصورت یکپارچه معنا، ساختار و زمان را مدلسازی کنند.
[1] A. Roy, N. Yan, and M. S. Mortazavi, “LLM-driven Knowledge Distillation for Dynamic Text-Attributed Graphs,” arXiv preprint arXiv:2502.10914, 2025.
[2] R. Xue, H. Deng, F. He, M. Wang, and Z. Zhang, “Trustworthy GNNs with LLMs: A Systematic Review and Taxonomy,” arXiv preprint arXiv:2502.08353, 2025.
[3] N. A. Abdolrahmanpour Holagh and Z. Kobti, “Survey of Graph Neural Network Methods for Dynamic Link Prediction,” in Proc. 16th Int. Conf. Ambient Systems, Networks and Technologies (ANT 2025) & 8th Emerging Data & Industry 4.0 (EDI40 2025), Procedia Computer Science, vol. 257, pp. 436–443, 2025.
[4] AI Summer, “Graph Neural Networks,” The AI Summer, 2025.
[5] FalkorDB, “Graph Neural Networks and Large Language Models Integration,” technical blog, 2024.
[6] Y. Li, V. Gupta, M. N. T. Kilic, K. Choudhary, D. Wines, W.-K. Liao, A. Choudhary, and A. Agrawal, “Hybrid-LLM-GNN: Integrating Large Language Models and Graph Neural Networks for Enhanced Materials Property Prediction,” Digital Discovery, 2025.
[7] Y. Tian, H. Song, Z. Wang, H. Wang, Z. Hu, F. Wang, N. V. Chawla, and P. Xu, “Graph Neural Prompting with Large Language Models,” arXiv preprint arXiv:2309.15427, 2023.
[8] W. Guo et al., “GraphEdit: Large Language Models for Graph Structure Learning,” arXiv preprint arXiv:2402.15183, 2024.
[9] Y. Pan et al., “HiGPT: Heterogeneous Graph Instruction Generation and Tuning,” arXiv preprint arXiv:2402.16024, 2024.
[10] H. Ye et al., “InstructGLM: Towards Fully Model-based Graph Learning with Instructions,” arXiv preprint arXiv:2308.14306, 2023.
[11] R. J. Chen, T. Zhao, A. Jaiswal, N. Shah, and Z. Wang, “LLaGA: Large Language and Graph Assistant,” arXiv preprint arXiv:2402.08170, 2024.
[12] Z. Chen et al., “Label-free Node Classification on Graphs with Large Language Models,” in Proc. 12th Int. Conf. on Learning Representations (ICLR), 2024.
[13] S. He et al., “Empower Text-Attributed Graphs Learning with Large Language Models,” arXiv preprint arXiv:2310.09872, 2023.
[14] M. Yasunaga et al., “LinkBERT: Pre-training Language Models with Document Links,” in Proc. 60th Annu. Meeting Assoc. Comput. Linguistics (ACL), 2022.
[15] G. Su, H. Wang, J. Wang, W. Zhang, Y. Zhang, and J. Pei, “Large Language Models Meet Text-Attributed Graphs: A Survey of Integration Frameworks and Applications,” arXiv preprint arXiv:2510.21131, 2025.
[16] J. Liu, Y. Sun, D. Fan, and Q. Tan, “GraphSearch: Agentic Search-Augmented Reasoning for Zero-Shot Graph Learning,” arXiv preprint arXiv:2601.08621, 2026.
[17] C. Wei, W. Hu, X. Hao, X. Wang, Y. Yang, Y. Chen, Y. Tian, and Y. Wang, “GraphChain: Large Language Models for Large-scale Graph Analysis via Tool Chaining,” arXiv preprint arXiv:2511.00457, 2025.
[1] Dynamic Text-Attributed Graphs (DyTAGs)
[2] Long-Term Dependencies
[3] Transformer
[4] Attention
[5] Prompt Engineering
[6] Fine-Tuning
[7] RAG
[8] Structural Dynamics
[9] Temporal Dependency
[10] Attribute Evolution
[11] Graph Neural Networks
[12] Message Passing
[13] Aggregation & Update
[14] Embedding
[15] Knowledge Distillation
[16] Teacher
[17] Light-Weight
[18] Student
[19] Message Passing
[20] Temporal Encoding
[21] Cost Functions
[22] Instruction-Tuning
[23] Encoder
[24] Sparse
[25] Context
[26] Structural Inductive Bias
[27] High-level Reasoning
[28] Generalization
[29] Interpretability
[30] Relation-aware Graph Tokenizer
[31] Latent Representations
[32] Reasoning
[33] In-Context Learning
[34] RAG
[35] Agentic Reasoning
[36] Graph-aware Query Planner
[37] Graph-aware Retriever
[38] Topic Models