اگه تو دنیای برنامهنویسی و توسعه نرمافزار فعالیت میکنی، حتما با کلی مفهوم و اصطلاح عجیب و غریب برخورد کردی: از «Infrastructure as Code» گرفته تا «Domain Driven Design» و «Serverless» و ...
تو این پست سعی کردم ۱۵ تا از این مفاهیم مهم و پرکاربرد رو خیلی خلاصه به زبان ساده توضیح بدم.

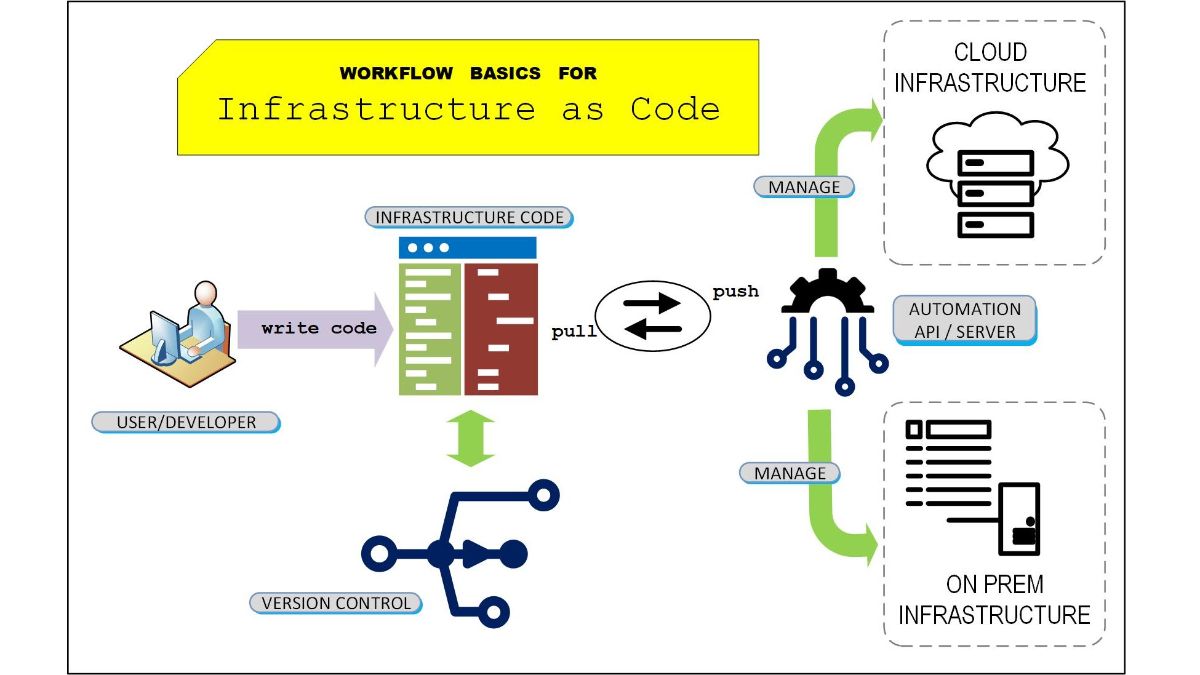
۱) مفهوم Infrastructure as Code یا همون IaC: توی دنیای توسعه مدرن، فقط کدنویسی اپلیکیشن کافی نیست. هر اپلیکیشن نیاز به یه زیرساخت داره: مثل سرورها، دیتابیسها، شبکه، تنظیمات امنیتی، load balancer و کلی چیز دیگه. تا چند سال پیش، این زیرساختها معمولا بهصورت دستی یا با اسکریپتهای پراکنده مدیریت و ساخته میشدن. خب مشکلش چیه؟ زمانبر، خطاپذیر و غیرقابل تکرار!
مفهوم IaC یعنی به جای اینکه بیای از طریق UI یا کامندلاین سرور رو بالا بیاری، همهچیز رو بهصورت کد قابل نسخهبندی، تکرارپذیر و قابل خودکارسازی بنویسی. انگار داری کد اپلیکیشن مینویسی، فقط اینجا داری محیط اجرای اپ رو تعریف میکنی.
در این روش دو رویکرد اصلی داریم:
در DevOps، روشهای IaC خیلی به کمک میاد تا همهچیز رو خودکار کنه و کار تیمها رو سریع و راحتتر کنه. با IaC، میتونیم زیرساختها رو مثل کد نرمافزار بنویسیم و هر تغییر رو کنترل و نسخهبندی کنیم (مثلا با ابزارهای کنترل ورژن مثل git). این باعث میشه که محیطهای مختلف مثل توسعه، تست و تولید همیشه یکسان و بدون مشکل باشن و همزمان پروسههای CI/CD هم سریعتر پیش برن.
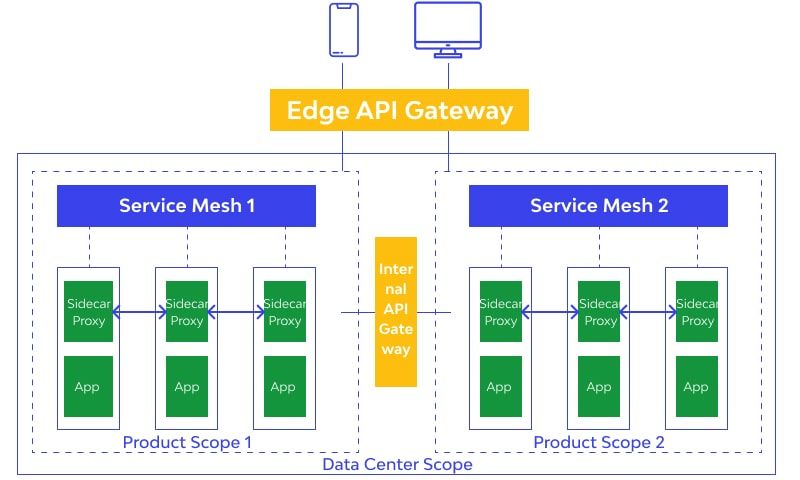
۲) مفهوم API Gateway & Service Mesh: هر دو برای مدیریت ارتباطات در معماری میکروسرویسها استفاده میشن، ولی هر کدوم وظایف خاص خودشون رو دارن.
الگوی API Gateway مثل دروازه ورود عمل میکنه که درخواستهای کاربران (کلاینتها) رو دریافت و بعد اونها رو به سرویسهای مناسب هدایت (route) میکنه. علاوه بر این، موارد امنیتی (مثل احراز هویت و مجوز دسترسی) و ترافیک (مثل محدودیت نرخ درخواستها و جلوگیری از بار بیش از حد) هم جز وظایف همین سرویسه. مهمتر اینکه میتونه پروتکلهای مختلف رو به هم تبدیل کنه و حتی پاسخها رو از چند سرویس مختلف جمع کنه و یه جواب واحد برای کاربر ارسال کنه.
الگوی Service Mesh یه لایه ارتباطی است که داخل معماری میکروسرویسها قرار میگیره و بیشتر برای ارتباطات داخلی بین سرویسها استفاده میشه. در واقع، این لایه شامل پراکسیهای سبکی (sidecar) هست که کنار هر سرویس قرار میگیرن و ارتباطات بین سرویسها رو کنترل میکنن. این پروکسیها به طور خودکار سرویسها رو کشف (مثلا با Kubernetes DNS)، ترافیک رو متعادل و امنیت رو برقرار میکنن و حتی اطلاعات دقیقی درباره وضعیت سرویسها ارائه میدن. به کمک این سیستم، همه ارتباطات داخل سرویسها هم پایش میشه و مشکلات ارتباطی سریعتر شناسایی میشن.
این پراکسی همون Envoy Proxy در معماری کوبرنتیز هست که کنار هر سرویس (مثلا یه Pod در Kubernetes) به عنوان sidecar نصب میشه و از وظیفههایی که داره میتونیم به این دو مورد اشاره کنیم:
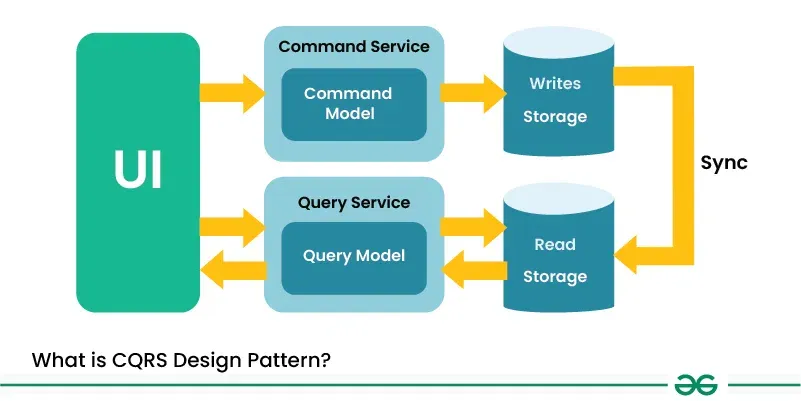
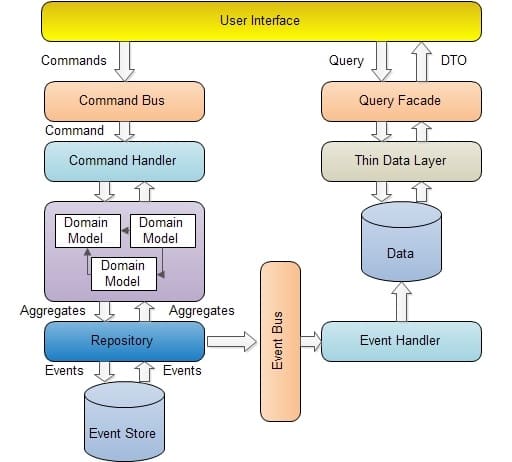
۳) مفهوم Command Query Responsibility Segregation یا همون CQRS: یعنی "تفکیک مسئولیت فرمان و پرسوجو". یه سبک معماری پیشرفتهست که کمک میکنه سیستمهای نرمافزاری پیچیده، راحتتر مقیاسپذیر بشن، کارایی بهتر و انعطافپذیری بیشتری داشته باشن. تو این سبک، کار نوشتن (Commands) و خوندن (Queries) از دیتابیس رو از هم جدا میکنیم؛ یعنی برای هرکدوم یه مدل جدا تعریف میکنیم و با منطق خودشون هندل میشن.
یعنی چی؟ یعنی از نگاه CQRS ما دوتا مسیر داریم: یکی برای کارهایی مثل ایجاد، ویرایش یا حذف دادهها که وضعیت سیستم رو عوض میکنن و یکی برای خوندن اطلاعات که هیچ تغییری نمیده، مثل همون SELECT ساده.
معمولا این مدل زمانی به درد میخوره که:
یه مثال خوبش معماری Master-Slave (یا همون Primary-Replica) تو PostgreSQL هست. تو این مدل، همهی عملیاتهای نوشتن فقط روی سرور Primary انجام میشن و Replicaها فقط برای خوندن هستن. اینجوری فشار روی هر سرور کم میشه و کل سیستم روانتر کار میکنه. (تو اکثر سیستمها معمولا Replicaها لود بیشتری دارن و باید چندتا از اونها وجود داشته باشد.)
البته همیشه یه مقدار تاخیر بین Primary و Replica وجود داره، چون هماهنگ شدنشون زمان میبره (بهش میگن eventual consistency).
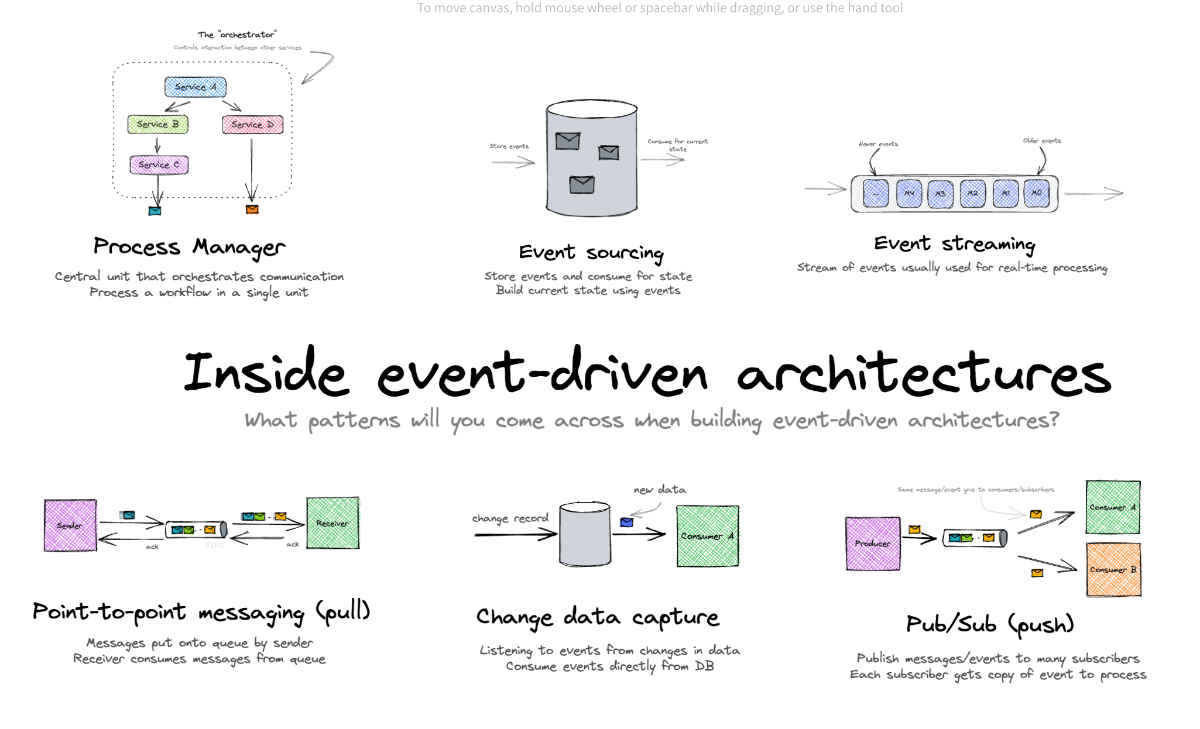
۴) مفهوم Event-Driven Architecture (EDA): در معماری رویداد محور، اجزای مختلف یک سیستم (مثل پرداخت، ایمیل، انبارداری و...) مستقیما هم دیگه رو کال نمیکنن و بجاش وقتی اتفاقی میافته (مثلاً پرداخت موفق، ثبت سفارش یا ورود کاربر)، سیستم یک رویداد (Event) منتشر میکنه. (یعنی به صورت Async با هم ارتباط دارن نه Sync) سرویسهای دیگهای که به این نوع رویداد علاقهمند هستن، اون رو دریافت میکنن و با توجه به هدفشون یهکاری با اون انجام میدن.
چرا EDA مهمه؟
اجزای اصلی معماری EDA:
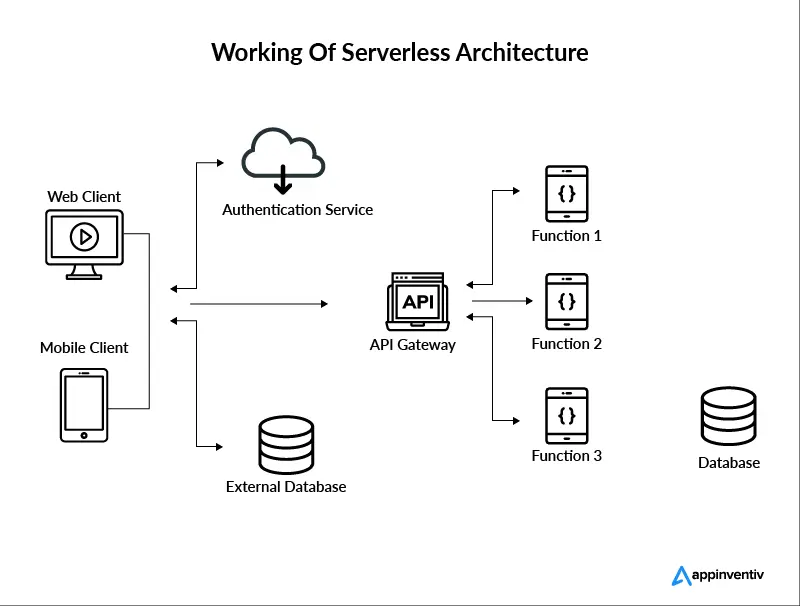
۵) مفهوم Serverless Architecture: یه سبک طراحی سیستمهای نرمافزاریه که توش نیاز نیست خودت سرور رو مدیریت کنی. یعنی نه لازمه سرور بخری، نه کانفیگ کنی، نه نگران scale باشی. همهی این کارا رو cloud provider (مثل AWS یا Google Cloud) برات انجام میده. تو فقط کدت رو مینویسی، اونم به شکل تابعهای کوچیک و مستقل که هر کدوم یه کار خاص انجام میدن و در زمان خاصی باید اجرا بشن.
ویژگیهای اصلی serverless:
یکی از مثالهایی که وجود داره AWS Lambda است. در این مکانیزم، تابعی مینویسیم که کد خاصی رو انجام میده و بعد این تابع روی AWS Lambda آپلود میشه. بعد از اون، AWS Lambda این تابع را به صورت خودکار اجرا میکنه زمانی که یک رویداد رخ میده.
برخی الگوهای طراحی در معماری Serverless:
الگو Function-as-a-Gateway: در اون تابعی به عنوان درگاه اصلی سیستم عمل میکنه و با پردازش اولیه (مانند احراز هویت یا لاگبرداری) درخواستها رو به سرویسهای داخلی هدایت میکنه.
الگو Event Stream Processing: در این الگو، دادهها بهصورت stream از منابعی مانند Kafka، AWS Kinesis، Pub/Sub یا IoT دستگاهها تولید میشن. هر event از stream باعث اجرای یک تابع Serverless میشه.
الگو Aggregator: تابع به عنوان تجمیعگر عمل میکنه و دادهها رو از چند سرویس مختلف جمع میکنه و به کلاینت برمیگردونه.
۶) مفهوم API-first Approach: در دنیای امروز، وقتی داریم درباره ساخت نرمافزار صحبت میکنیم، مخصوصا در سیستمهای پیچیدهای مثل میکروسرویسها یا اپلیکیشنهایی که برای موبایل، وب و mini-app طراحی میشن، یکی از بخشهای خیلی مهم طراحی API هست. API یا همون رابط برنامهنویسی اپلیکیشنها، در واقع پلیه که سیستمها یا بخشهای مختلف یک سیستم از طریق اون با هم ارتباط برقرار میکنن.
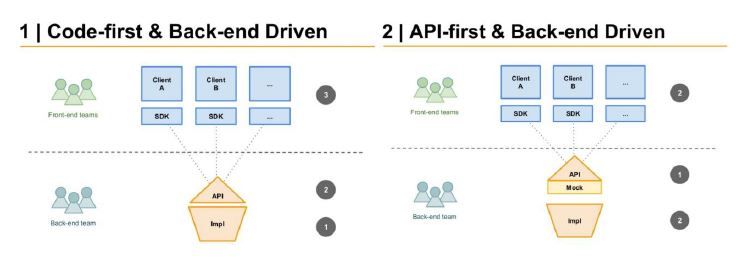
حالا وقتی میگیم رویکرد API-First، یعنی باید از همون اول API رو طراحی و توافق کنیم و بعد بقیه چیزها رو بنویسیم (دقیقا مقابل Code-First). یعنی قبل از اینکه سراغ کدنویسی بکاند، فرانتاند یا تست بریم، باید مشخص کنیم که API ما چطور کار میکنه، چه دادههایی میگیره، چه خروجیهایی میده، چه خطاهایی ممکنه پیش بیاد و بهطور کلی، چه قراردادهایی بین هر بخش وجود داره.
قبلا در تیمهای برنامهنویسی اول بکاند رو مینوشتن و بعد به تیم فرانتاند یه مستند ساده میدادن (یا شاید اصلاً مستندی وجود نداشت!). این روش مشکلات زیادی داشت. مثلا تیم فرانتاند مجبور بود منتظر تیم بکاند بمونه و این باعث میشد که کارها با تاخیر زیادی پیش بره. همچنین ارتباط بین تیمها همیشه سخت و پر از سوءتفاهم بود، چون مستندات یا اصلا وجود نداشت یا خیلی ناقص بودن. تازه، تست کردن API هم سخت و پر از مشکل میشد.
اما با رویکرد API-First، از همون اول که قرارداد API مشخص بشه، تیمهای مختلف مثل فرانتاند، بکاند، تست، DevOps و ... میتونن کارهای خودشون رو بهطور همزمان پیش ببرن. این باعث میشه که همه بتونن مستقل از هم کار کنن و مشکلات ناشی از تاخیرها و سوءتفاهمها کمتر بشه. چون طراحی API اول انجام میشه، مستندات همیشه بهروز و معتبر هستن.
یکی دیگه از مزایای این رویکرد هم اینه که میتونیم خیلی سریع API رو شبیهسازی کنیم و برای تیم فرانتاند یه Mock Server راه بندازیم تا حتی قبل از اینکه بکاند واقعی پیادهسازی بشه، بتونن شروع به کار کنن. همچنین وقتی API رو به عنوان یک قرارداد رسمی طراحی میکنیم، خیلی راحتتر میتونیم مواردی مثل امنیت، نسخهبندی، اعتبارسنجی و مدیریت خطاها رو پیادهسازی کنیم. (طراحی میتونه با ابزارهایی مثل OpenAPI یا Postman بشه.)
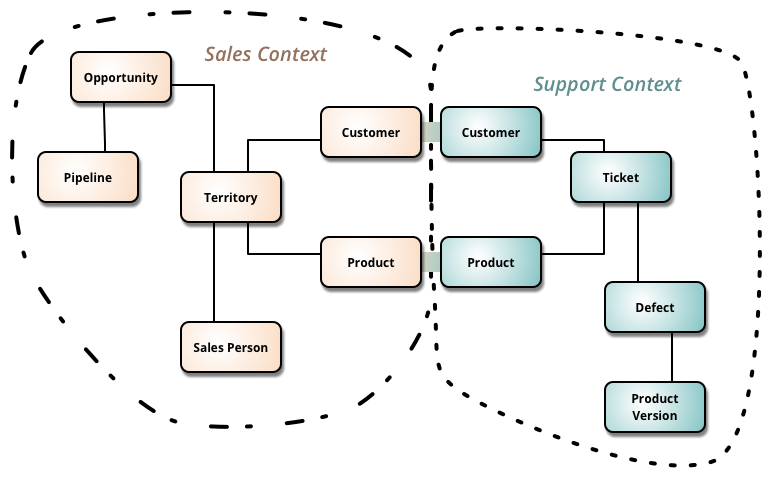
۷) مفهوم Domain Driven Design: یه روشیه که تاکید میکنه اول باید مشکل واقعیای که نرمافزار قراره حل کنه رو خوب بشناسیم، بعد بریم سراغ طراحی، انتخاب فریمورک، دیتابیس و پیادهسازی. یعنی اول ببینیم دقیقا توی چه دنیایی قراره کار کنیم؟ مشتریهامون کیان؟ قوانین کسبوکار چیه؟ چه اتفاقاتی قراره بیوفته؟ برای اینکه دامنه رو بفهمیم، باید با آدمهایی که واقعا اون حوزه رو میشناسن (domain expert) مثل کارشناس بانکی، مدیر فروش، پزشک غیره تعامل کنیم.
برای اینکه بفهمیم DDD چیه، اول این هر کدوم از این D ها رو بررسی میکنیم:
حالا برای طراحی تاکتیکی بر پایه DDD به معرفی چند الگو مهم میپردازیم. این تاکتیکها کمک میکنن که مدل دامنهمون رو به شکلی ساختاریافته و منظم طراحی کنیم.
این الگوها به ما کمک میکنن تا مدل دامنه رو منطقی، مقیاسپذیر و قابل نگهداری بسازیم.
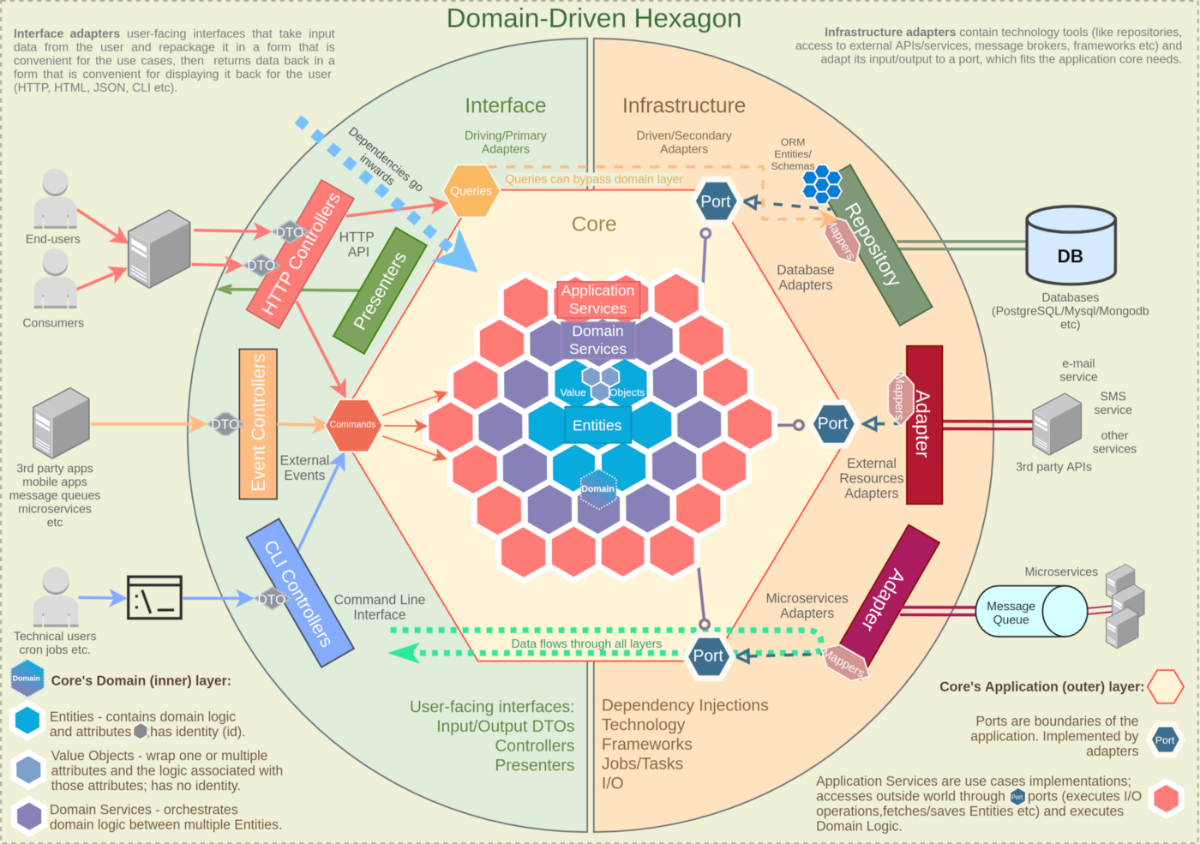
۸) مفهوم Hexagonal Architecture: یه معماری طراحی نرمافزاره که تمرکز اصلیش روی جداسازی منطق اصلی(هسته) سیستم از وابستگیهای خارجیه (مثل پایگاه دادهها یا رابطهای کاربری). این معماری کمک میکنه که نرمافزار بهراحتی قابل انعطاف و توسعه باشه، چون هسته سیستم رو بهطور مستقیم به هیچکدوم از این اجزا وابسته نمیکنه.
در این معماری، هسته سیستم با دنیای بیرون از طریق پورتها ارتباط برقرار میکنه. در سمت دیگه، آداپتورها قرار دارن که وظیفه پیادهسازی این پورتها رو بر عهده دارن. مثلا وقتی سیستم نیاز به دریافت داده از یک پایگاه داده یا انجام یک درخواست HTTP داره، آداپتورها اون درخواستها رو به فرمتهایی که هسته سیستم میفهمه تبدیل میکنن.
حالا بهتره اجزای اصلی معماری هگزاگونال رو با هم دیگه ببینیم (به شکل زیر هم همزمان نگاه کن!):
حالا این معماری چه مزیتی داره؟
۹) مفهوم Event Sourcing: یه الگوی معماریه که به جای اینکه وضعیت نهایی دادهها رو مستقیما توی دیتابیس ذخیره کنیم، تاریخچهی تغییرات (eventها) رو نگه میداریم. یعنی هر تغییری که روی سیستم اعمال میشه (مثل «ثبت سفارش»، «پرداخت»، «ارسال سفارش») بهصورت یک Event ذخیره میشه و وضعیت فعلی از روی اونها بازسازی (replay) میکنیم (معمولا تو فلوهای چند استیتی خیلی کاربرد داره). در واقع از Command برای دریافت درخواستها و از Aggregate برای اعتبارسنجی و پیادهسازی منطق کسبوکار استفاده میکنیم.
چرا خوبه از این معماری استفاده کنیم با اینکه خیلی بیشتر فضا اشغال میکنه؟
پس این الگو مزایایی مانند Audit (ثبت دقیق تغییرات)، Time Travel (امکان بازگشت به وضعیتهای گذشته سیستم)، Root Cause Analysis (تحلیل علت ریشهای مشکلات)، Fault Tolerance (تحمل خطا) و Service Autonomy (استقلال سرویسها) را در اختیار ما قرار میده. همه این ویژگیها باعث میشن که سیستمهای پیچیده، کارا، مقیاسپذیر و قابل اعتمادتر شوند. برای decoupling بین سرویسها میتونیم از روشهای Async مثل Event Bus ها هم استفاده کنیم.
۱۰) مفهوم Low-code/No-code platforms: وقتی میخوایم یه اپلیکیشن یا ابزار توسعه بدیم، معمولا باید کلی کد بزنیم. اما پلتفرمهای Low-Code و No-Code اومدن که این مسیر رو راحتتر کنن (بیشتر برای غیر توسعهدهندهها (Citizen Developers) مناسبه در حالتهایی که میخوان یهچیز MVP بیارن بالا):
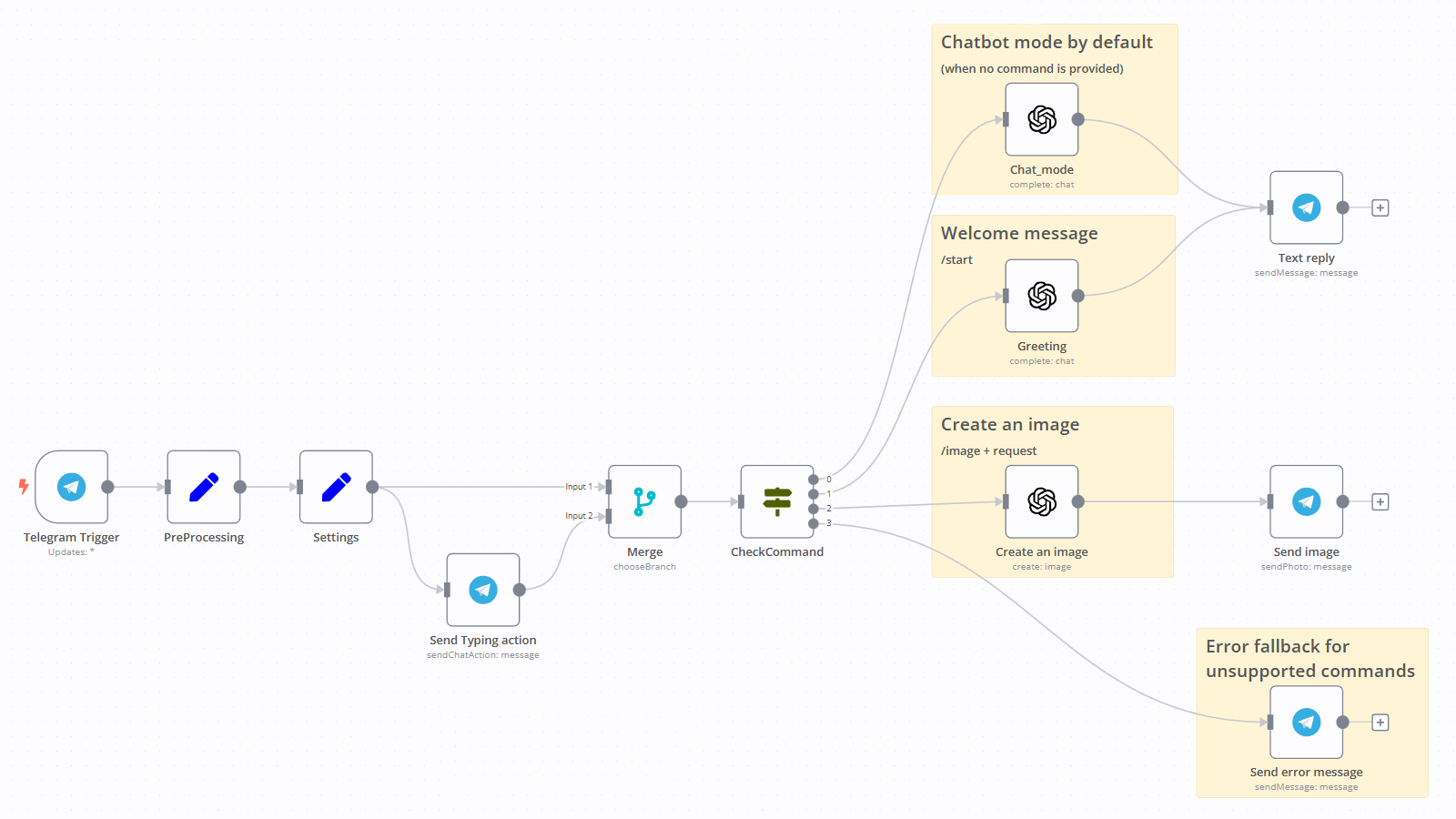
برای مثال یکی از این ابزارها n8n است که یک پلتفرم Low-code workflow automation با ساختار Node-based و event-driven هست. یعنی با وصل کردن Nodeهایی مثل Webhook، Gmail، Google Sheets یا Function (برای اجرای کد جاوااسکریپت)، میتونی جریان دادهها بین سرویسها رو تعریف کنی. هر Node در واقع یک abstraction از یک task یا API هست که ورودی و خروجی JSON داره و میشه با expression یا کد دلخواه اون رو کنترل کرد.
یکی از چیزهای جالبی که با n8n انجام میدن ساخت باتهای تلگرامیه. برای مثال میتونیم یک workflow بسازیم که با Telegram node پیامهای ورودی رو دریافت کنه و با استفاده از گرههای منطقی، پاسخهای خودکار یا عملیات دیگه (مثل ارسال پیام، ذخیره داده یا اتصال به APIها) انجام بده. (تصویر زیر یک نمونه از بات تلگرامی رو نشون میده)
۱۱) مفهوم Business Process Management Systems (BPMS): سیستم مدیریت فرآیند کسبوکار یا همون BPMS یه پلتفرم یا ابزار نرمافزاریه که به سازمانها کمک میکنه فرآیندهای کاریشون رو مدلسازی، اجرا، پایش و بهینهسازی کنن. با استفاده از BPMS میتونیم جریان کارها رو خودکار کنیم، تصمیمگیریها رو طبق قوانین کسبوکار انجام بدیم و در نهایت عملکرد فرآیندها رو با گزارش و مانیتورینگ دقیق بررسی کنیم. این سیستم معمولا شامل یه موتور گردش کار، ابزار مدلسازی (مثل BPMN) و امکان اتصال به سیستمهای دیگه مثل CRM یا پایگاه دادههاست.
به صورت مختصر چرخه حیات مدیریت فرایندهای کسبوکار رو بررسی میکنیم:

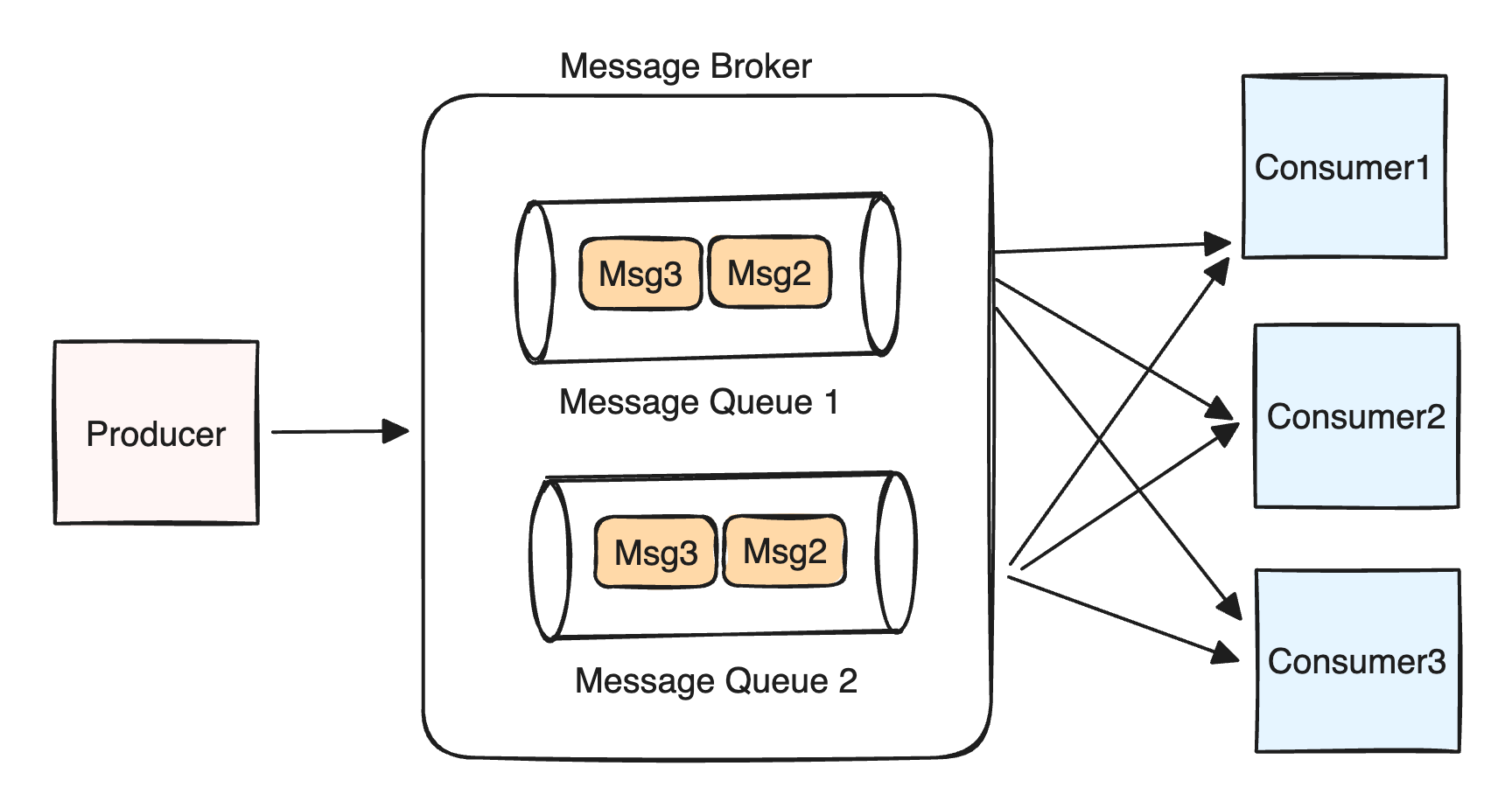
۱۲) مفهوم Message Queue (such as Kafka and RabbitMQ): یه سیستم ارتباطی بین اجزای مختلف سیستمهاست که برای ارسال پیامها به صورت غیرهمزمان (Async) استفاده میشه. این پیامها معمولا در صفهایی ذخیره میشن و هر سرویس یا برنامهای که نیاز به دریافت پیام داشته باشه میتونه اونها رو دریافت و پردازش کنه. (مثلا تو Kafka، مصرفکنندهها با مشخص کردن یه consumer group (در حالتی که چند consumer بخوان به صورت مستقل از MQ بخونن) و topic name، به سیستم میگن که به چه topicی میخوان گوش بدن.)
یکی از بزرگترین مزایای MQ اینه که باعث میشه سیستمها decoupled بشن. یعنی یه سرویس میتونه بدون اینکه منتظر پاسخ از سرویسهای دیگه بمونه، پیام رو تو صف بفرسته و بره سراغ کارای دیگه.
در MQها معمولا دو مدل ارتباطی اصلی وجود داره: queue-based و publish-subscribe
مدل Point-to-Point یا queue-based: در این مدل، یک Producer، پیامها رو داخل یک صف میذاره و این صف حکم یک حافظه موقت بین فرستنده و گیرنده رو داره. بعد یک یا چند Consumer به این صف وصل میشن، اما هر پیام فقط توسط یکی از مصرفکنندهها خونده و پردازش میشه. (مکانیزم At-most-once / At-least-once) این مدل به درد load balancing بین چند نمونه از یک سیستم میخوره.
مدل Pub/Sub: فرستنده (Publisher) پیامها رو روی یک Topic منتشر میکنه و Subscriber که به اون موضوع subscribe کرده باشه، یه نسخه از پیام رو دریافت میکنه. برخلاف مدل صفی که هر پیام فقط به یه مصرفکننده میرسه، توی Pub/Sub همهی Subscriber ها پیام رو دریافت میکنن.
استفاده از Message Queue در سیستمهایی که نیاز به مقیاسپذیری و مدیریت بار بالا دارن، خیلی نیازه. با اینکه MQها باعث کاهش وابستگیها میشن، این سیستمها قابلیت retry و backpressure هم دارن، یعنی میتونن پیامها رو ذخیره کنن و در صورت بروز خطا دوباره ارسال کنن، یا فشار روی مصرفکنندهها رو مدیریت کنن که بار زیادی رو تحمل نکنه. در نتیجه، این سیستمها بسیار مقیاسپذیر و مقاوم به خطا میشن.
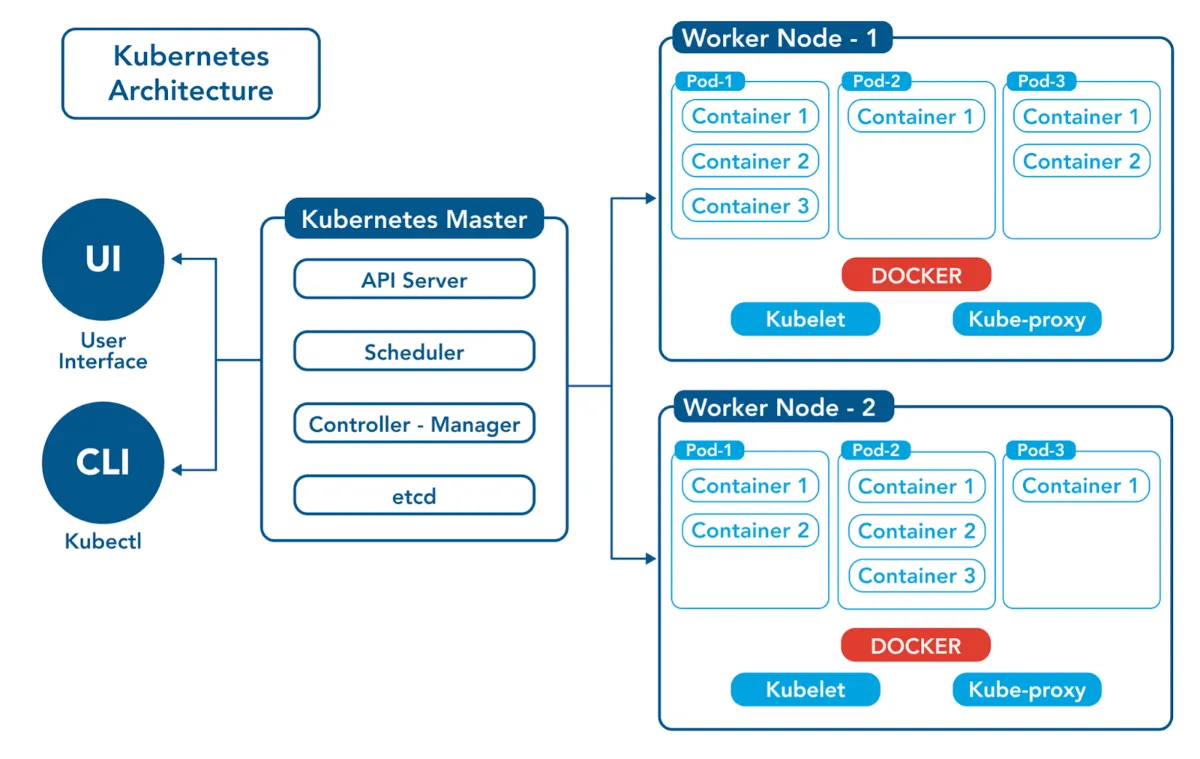
۱۳) مفهوم Container Orchestration (such as Kubernetes): کانتینرها محیطهای اجرایی سبکوزن و ایزولهای هستن که روی یک کرنل مشترک اجرا میشن. اگه شما یک سیستم توزیعشده مبتنی بر کانتینر (مثلا با Docker) راهاندازی کنید، وقتی تعداد سرویسها زیاد بشه (مثلا ۱۰۰ میکروسرویس) دیگه نمیتونید بهصورت دستی اونها رو مدیریت کنید. اینجاست که Container Orchestration وارد میشه.
این ابزار توزیعشده برای مدیریت و هماهنگی تعداد زیادی کانتینر به صورت خودکار، بهویژه زمانی که سیستم ما از چند سرویس تشکیل شده و قراره روی چند ماشین (Node) اجرا بشه، کاربرد داره(مثل k8s). به جای اینکه دستی کانتینرها رو بسازیم، اجرا و بهروزرسانی کنیم، Kubernetes این وظایف رو برعهده میگیره و باعث میشه مقیاسپذیری، پایداری و خودکارسازی بسیار راحتتر بشه.
برای مثال k8s به شما اجازه میده تا تعداد مشخصی کانتینر از هر سرویس رو همیشه در حال اجرا نگه دارید. مثلاً بگیم "۳ نسخه از سرویس پرداخت همیشه بالا باشه"، اگه یکی خراب بشه، Kubernetes خودش یکی دیگه بالا میاره. (Self-healing) همینطور امکان انجام بهروزرسانی بدون توقف (downtime) سرویس (rolling update) و بازگشت به نسخه قبلی (rollback) رو هم فراهم میکنه.
این ابزار از مفاهیمی مثل Pod (مجموعهای از یک یا چند کانتینر)، Deployment (برای مدیریت نسخهها)، Service (برای اتصال به کانتینرها) و Volume (برای مدیریت دادهها) استفاده میکنه. هر چیزی در Kubernetes با فایلهای YAML تعریف میشه که در واقع وضعیت ایدهآل سیستمه.
در نتیجه، Kubernetes ابزاریه که به توسعهدهندهها و تیمهای DevOps کمک میکنه تا اپلیکیشنهای پیچیده و توزیعشده رو به شکلی قابل اعتماد، مقیاسپذیر و خودکار اجرا و مدیریت کنن، بدون اینکه دغدغه وضعیت تکتک کانتینرها رو داشته باشن.
از وظایف این سرویسها میتونیم به این موارد اشاره کنیم:
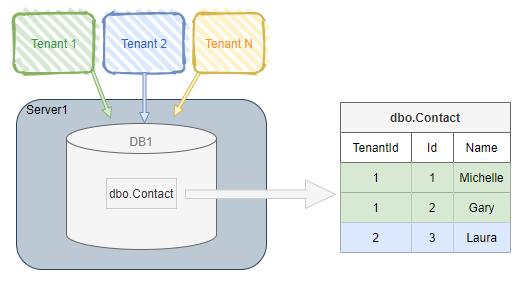
۱۴) مفهوم Multi-Tenancy Architecture: مدلی در طراحی نرمافزارهای SaaS است که در آن، یک نسخه از برنامه و زیرساخت (مثل کد و دیتابیس) بین چند مشتری (tenant) مشترکه، ولی دادههای هر tenant بهطور منطقی از بقیه جدا نگه داشته میشن. بهجای اینکه برای هر مشتری یک سرور یا برنامه جداگانه بالا بیاد، همه مشتریها از یک سیستم مشترک استفاده میکنن، در حالی که انگار سیستم فقط برای اوناست.
به عبارت دیگه یعنی یه اپلیکیشن، یه بار نوشته میشه ولی به تعداد زیاد مشتری یا سازمان خدمات میده. مثلا Slack یا Gmail یه نمونه از این مدل هستن. هر کاربر انگار داره تو فضای خودش کار میکنه ولی همه دارن از یه سیستم مرکزی استفاده میکنن.
مزیت اصلی این مدل، کم کردن هزینه منابع و سادهسازی توسعه و استقراره چون فقط یک نسخه از برنامه رو توسعه، نگهداری و بهروزرسانی میکنیم. اما از طرف دیگه، نیازمند پیادهسازی دقیق برای ایزولهسازی دادههاست تا امنیت و استقلال tenantها حفظ بشه.
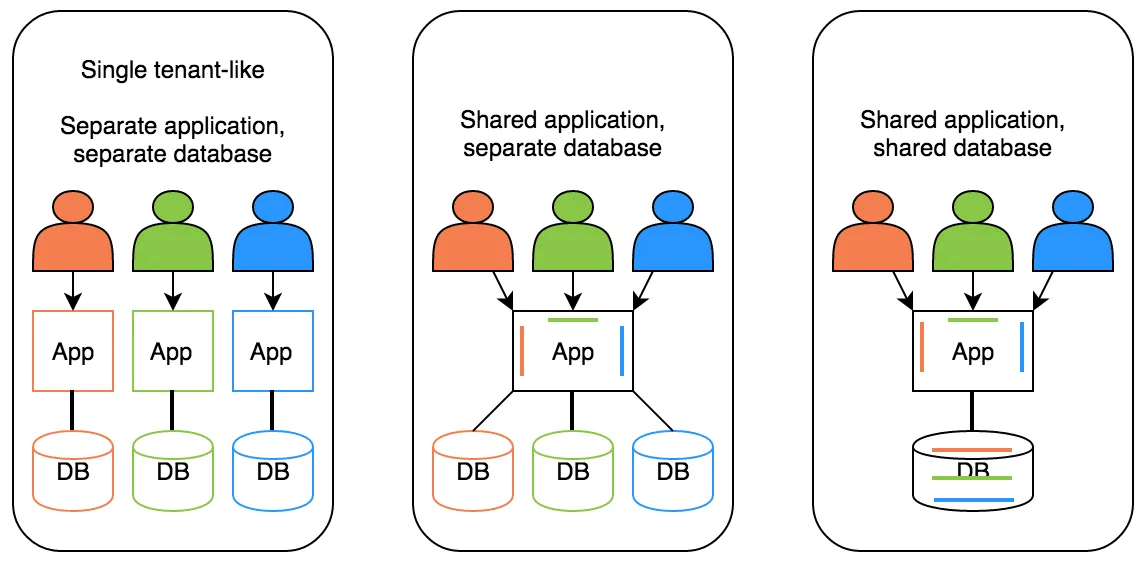
سه مدل از پیادهسازی این نوع سیستمها وجود داره که با هم بررسیشون میکنیم:
روش مشابه دیگری هم برای دستهبندی روشهای پیادهسازی این معماری وجود داره که در تصویر پایین میبینیم.
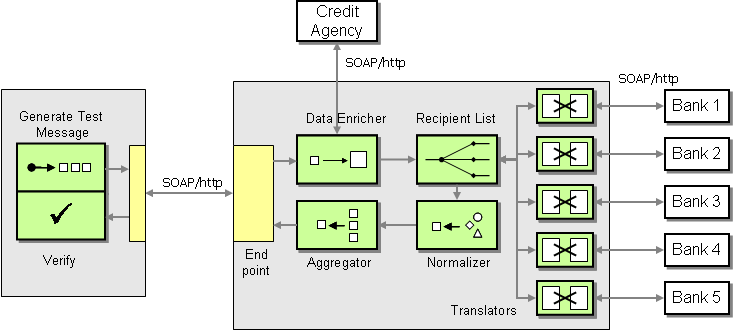
۱۵) مفهوم Enterprise Integration Patterns: وقتی توی یه سازمان یا شرکت بزرگ کار میکنی، معمولا با چندین سیستم مختلف روبهرو میشی. مثلا یه سیستم فروش داریم، یکی برای انبار، یکی برای حسابداری و یکی برای ارسال پیامک یا ایمیل. حالا فرض کن مشتری یه سفارشی ثبت میکنه. این اطلاعات باید از سیستم فروش بره به انبار که محصول رو آماده کنه، بعدش بره به حسابداری که فاکتور بزنه و همزمان برای مشتری پیامک بره که سفارشش ثبت شده. این یعنی سیستمها باید با هم حرف بزنن.
اما مشکل اینجاست: سیستمها معمولا فرق دارن. یکی با JSON کار میکنه، یکی با XML. یکی همیشه روشنه، یکی بعضی وقتا قطعه. یکی فقط شبها کار میکنه، یکی همیشه فعاله. حالا چطوری اینا باید با هم هماهنگ بشن؟ اگه یه پیام اشتباه بره چی؟ اگه چند تا سیستم همزمان باید پیام بگیرن چی؟
اینجاست که EIP میاد وسط. EIP یه مجموعه الگو یا روشه که دقیقا برای حل مسائل یکپارچهسازی ساخته شده. یعنی راهکارهای امتحانشده و آمادهای هستن که میگن مثلا:
اینا فقط چندتا از الگوها هستن. این الگوها توی کتابی به اسم Enterprise Integration Patterns که توسط Gregor Hohpe و Bobby Woolf نوشته شده، بهصورت خیلی کامل توضیح داده شدن. اون کتاب هنوزم یکی از مرجعهای اصلی توی این زمینهست.
در عمل، EIP باعث میشه توی سازمانت، سیستمها بدون این که مستقیم به هم وابسته باشن، بتونن با هم ارتباط برقرار کنن. این یعنی توسعهپذیری بهتر، نگهداری راحتتر و یه ساختار تمیزتر برای ارتباط بین سیستمها.
منابع: