در دنیای دیجیتال امروز، دسترسی به دادههای وب یکی از پایههای اساسی برای تحلیل، تولید محتوا، تحقیقات بازار و حتی هوش مصنوعی است. با این حال، بسیاری از وبسایتها برای حفاظت از محتوای خود در برابر دسترسیهای غیرمجاز، از سیستمهای امنیتی پیشرفتهای مانند فایروالهای برنامههای وب (WAF) و سرویسهای ابری مانند Cloudflare استفاده میکنند. این سیستمها اغلب منجر به بروز خطاهای مانند 403 Forbidden میشوند که دسترسی رباتهای اسکرپینگ را مسدود میکنند.
در این مقاله، به بررسی جامع این چالشها میپردازیم و یک راهکار هوشمندانه و کارآمد را معرفی میکنیم: استفاده از فیدهای RSS واسط. این روش نه تنها موانع امنیتی را دور میزند، بلکه دادهها را به صورت ساختارمند و پایدار ارائه میدهد. هدف این مقاله، پوشش کامل موضوع از صفر تا صد است تا مخاطبان بتوانند با آگاهی کامل، فرآیندهای جمعآوری داده خود را بهینهسازی کنند. ما به بررسی تاریخچه، مفاهیم فنی، مزایا، معایب، مثالهای واقعی، مسائل قانونی و اخلاقی، و در نهایت راهنمایی عملی برای پیادهسازی خواهیم پرداخت.
اسکرپینگ وب (Web Scraping) فرآیندی است که در آن دادههای موجود در صفحات وب به صورت خودکار استخراج و ذخیره میشوند. این تکنیک از دهه 1990 میلادی آغاز شد، زمانی که اینترنت عمومی شد و نیاز به جمعآوری دادههای بزرگ برای تحلیلهای آماری و تجاری افزایش یافت. در سادهترین شکل، اسکرپینگ شامل ارسال درخواستهای HTTP به سرورهای وب و تجزیه و تحلیل کد HTML پاسخ است. ابزارهایی مانند BeautifulSoup در پایتون یا Scrapy برای این منظور استفاده میشوند.
اسکرپینگ وب برای کسبوکارها، بهویژه شرکتهای بزرگ، به ابزاری کلیدی برای جمعآوری دادهها و تصمیمگیریهای دادهمحور تبدیل شده است. طبق گزارش Bright Data (2024)، بسیاری از شرکتهای پیشرو، از جمله بخش قابلتوجهی از سازمانهای Fortune 500، از اسکرپینگ وب برای اهدافی مانند تحلیل بازار، نظارت بر قیمت رقبا، و جمعآوری دادههای مشتریان استفاده میکنند. برای مثال، شرکتهای تجارت الکترونیک مانند آمازون یا eBay از اسکرپینگ برای تنظیم استراتژیهای قیمتگذاری خود بهره میبرند. این روش به کسبوکارها امکان میدهد تا با دادههای بهروز و دقیق، تصمیمات استراتژیک بهتری بگیرند.
یکی از اصلیترین موانع در اسکرپینگ، سیستمهای حفاظتی مانند WAF و Cloudflare است. WAF یا Web Application Firewall، یک لایه امنیتی است که ترافیک ورودی به وبسایت را نظارت کرده و درخواستهای مشکوک را مسدود میکند. این سیستمها بر اساس الگوهایی مانند سرعت درخواستها، الگوی رفتار کاربر یا حتی نوع هدرهای HTTP عمل میکنند. Cloudflare، به عنوان یکی از محبوبترین ارائهدهندگان خدمات CDN (Content Delivery Network) و امنیت ابری، بیش از 25 میلیون وبسایت را حفاظت میکند. این سرویس از تکنیکهایی مانند CAPTCHA ،JavaScript Challenges و تشخیص بات استفاده مینماید تا دسترسیهای خودکار را محدود کند.
خطای 403 Forbidden یکی از رایجترین نشانههای این حفاظتهاست. این خطا به معنای «دسترسی ممنوع» است و زمانی رخ میدهد که سرور درخواست را به عنوان غیرمجاز شناسایی کند. دلایل اصلی آن عبارتند از:
تشخیص بات: اگر درخواست بدون هدرهای معتبر (مانند User-Agent) ارسال شود، سیستم آن را به عنوان ربات تشخیص میدهد. برای مثال، در Stack Overflow، کاربران گزارش کردهاند که بدون هدرهای مناسب، درخواستهای پایتون بلافاصله با 403 مواجه میشوند.
محدودیت IP: اگر چندین درخواست از یک IP ارسال شود، Cloudflare آن را به عنوان حمله DDoS یا اسکرپینگ انبوه تلقی میکند.
چالشهای جاوا اسکریپت: Cloudflare چالشهایی مانند حل CAPTCHA یا اجرای کد JS را تحمیل میکند که رباتهای ساده قادر به عبور از آن نیستند. Scrapfly گزارش میدهد که در سال 2025، بیش از 40% وبسایتها از این چالشها استفاده میکنند.
این چالشها نه تنها فرآیند اسکرپینگ را کند میکنند، بلکه میتوانند منجر به هزینههای اضافی برای پراکسیها یا ابزارهای ضدبات شوند. در انجمنهای Reddit، کاربران اغلب از دشواری اسکرپینگ سایتهای Cloudflare محافظتشده شکایت دارند و به دنبال راهحلهای جایگزین هستند.
برای غلبه بر این موانع، روشهای سنتی متعددی وجود دارد، اما هر کدام محدودیتهای خود را دارند:
استفاده از پراکسی و چرخش IP: با تغییر IP در هر درخواست، میتوان از بن شدن جلوگیری کرد. سرویسهایی مانند IPRoyal یا Bright Data پراکسیهای چرخشی ارائه میدهند. اما این روش هزینهبر مییاشد و ممکن است سرعت را کاهش دهد.
تقلید رفتار انسانی: با افزودن هدرهای واقعی (مانند User-Agent مرورگرهای واقعی) و تأخیر بین درخواستها، میتوان بات را شبیه کاربر واقعی کرد. ابزارهایی مانند Selenium برای این منظور استفاده میشوند، اما مصرف منابع بالایی دارند.
ابزارهای ضدبات: سرویسهایی مانند CapSolver برای حل CAPTCHA یا cloudscraper برای دور زدن Cloudflare طراحی شدهاند. با این حال، این ابزارها همیشه بهروز نیستند و ممکن است توسط بهروزرسانیهای Cloudflare خنثی شوند.
معایب این روشها شامل هزینه بالا، پیچیدگی فنی و خطر قانونی است. علاوه بر این، اسکرپینگ خام دادهها را بدون ساختار ارائه میدهد که پردازش آن زمانبر است.
RSS (Really Simple Syndication) یک استاندارد XML برای توزیع محتوا است که در سال 1999 توسط Netscape معرفی شد. این فیدها اجازه میدهند محتوای وبسایتها (مانند اخبار و مقالات) به صورت ساختارمند و بهروز به کاربران یا برنامهها ارسال شود. در ابتدا، RSS برای خوانندههای فید مانند Google Reader استفاده میشد، اما امروزه در اتوماسیون محتوا کاربرد دارد.
فیدهای RSS واسط، مانند آنهایی که توسط rss.app ارائه میشوند، یک لایه اضافی هستند که حتی برای سایتهایی بدون RSS بومی، فید ایجاد میکنند. rss.app بیش از 1000 منبع را پشتیبانی میکند و ویژگیهایی مانند استخراج تصاویر بزرگ، فیلترهای پیشرفته و تبدیل RSS به JSON یا CSV دارد. این ابزار با کپی کردن URL وبسایت، فید سفارشی ایجاد میکند و بهروزرسانیهای خودکار ارائه میدهد.
در زمینه اسکرپینگ، RSS به عنوان جایگزینی برای دسترسی مستقیم عمل میکند؛ زیرا محتوا را بدون نیاز به تجزیه HTML ارائه میدهد. گزارش MoldStud نشان میدهد که استفاده از RSS میتواند زمان جمعآوری داده را تا 50% کاهش دهد.
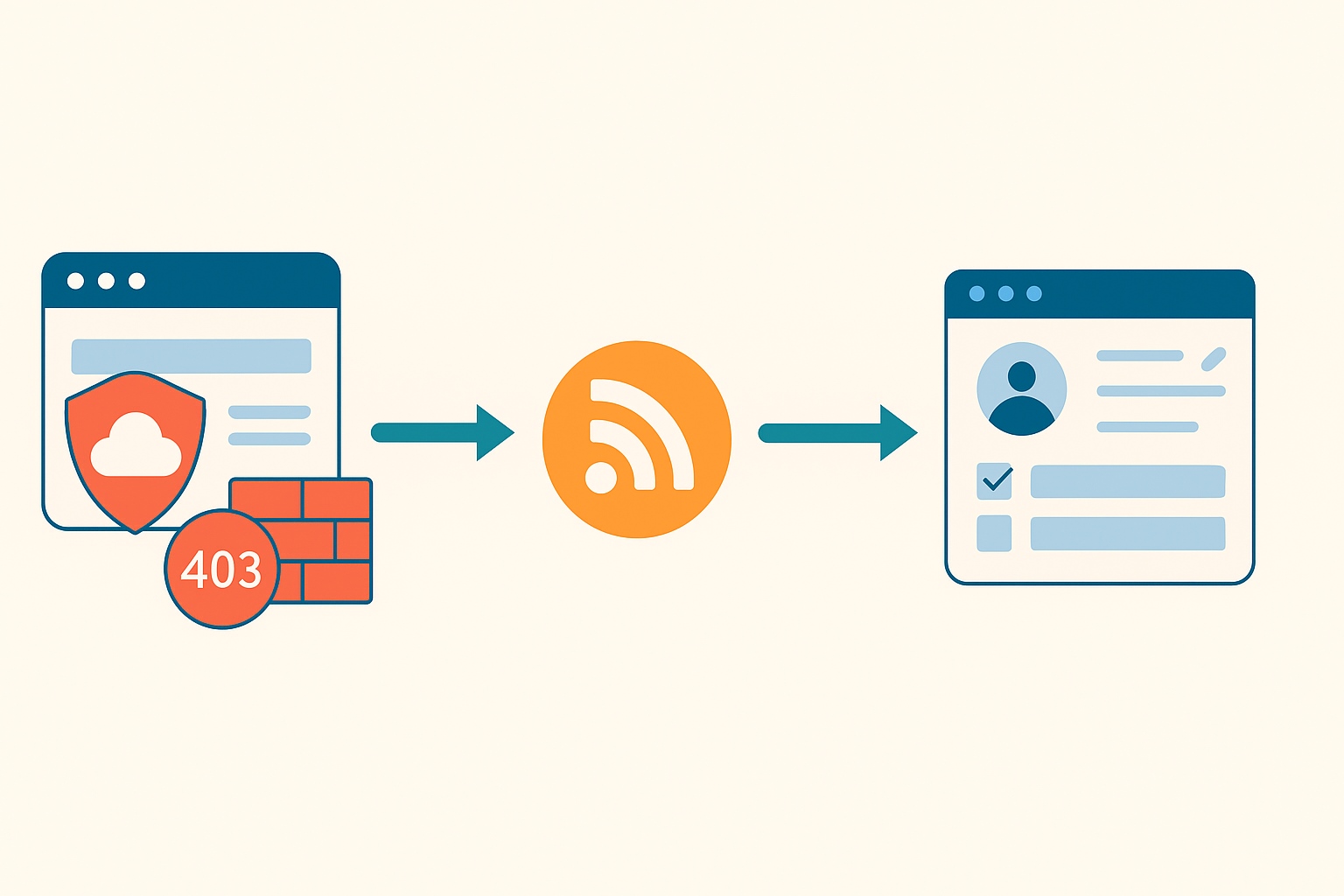
فیدهای RSS واسط با ایفاء نقش بهعنوان یک واسطه محتوایی عمل میکنند و راهکاری هوشمندانه برای دسترسی به محتوای وبسایتهای محافظتشده ارائه میدهند. به جای ارسال مستقیم درخواستهای HTTP به سرور هدف، که ممکن است با موانع امنیتی مانند WAF یا Cloudflare مواجه شود، ابزارهایی مانند rss.app بهعنوان یک پل ارتباطی عمل میکنند. این ابزارها محتوای موردنظر را از وبسایت استخراج کرده و آن را در قالب یک فید RSS ساختارمند ارائه میدهند. این روش نهتنها فرآیند دسترسی به دادهها را سادهتر میکند، بلکه پایداری و کارایی را نیز بهبود میبخشد. در ادامه، جزئیات عملکرد این روش و مزایای آن تشریح میشود:
غلبه بر محدودیتهای WAF و Cloudflare: درخواستهای ارسالی از طریق سرورهای ابزارهایی مانند rss.app به گونهای طراحی شدهاند که مشابه رفتار کاربران واقعی به نظر برسند، نه رباتهای محلی. این ویژگی باعث میشود که سیستمهای امنیتی مانند WAF یا Cloudflare، که معمولاً درخواستهای مشکوک را با خطای 403 Forbidden مسدود میکنند، نتوانند این درخواستها را بهعنوان تهدید شناسایی کنند. در نتیجه، برخلاف اسکرپینگ مستقیم که اغلب با چالشهای امنیتی مواجه میشود، فیدهای RSS محتوا را بدون نیاز به حل CAPTCHA یا چالشهای جاوا اسکریپت ارائه میدهند.
ارائه دادههای ساختارمند: فیدهای RSS دادهها را در قالبی منظم و استاندارد شامل اطلاعاتی مانند عنوان، خلاصه محتوا، لینک منبع و تاریخ انتشار ارائه میکنند. این ساختارمندی، پردازش دادهها را به مراتب آسانتر از تجزیه کد HTML خام مینماید، که معمولاً در اسکرپینگ سنتی با پیچیدگیهای ناشی از تغییرات ساختاری وبسایت همراه است.
پشتیبانی از پردازش موازی و اتوماسیون: با استفاده از فیدهای RSS، میتوان چندین منبع محتوا را به صورت همزمان نظارت کرد. این امکان برای پروژههایی که نیاز به جمعآوری، ترجمه یا انتشار خودکار محتوا دارند، بسیار ارزشمند است. برای مثال، میتوانید فیدهای متعدد را به سیستمهای مدیریت محتوا (CMS) متصل کنید تا فرآیند تولید محتوا به صورت خودکار انجام شود.
فرض کنید قصد دارید اخبار یک وبسایت خبری محافظتشده توسط Cloudflare را جمعآوری کنید. کافی است URL وبسایت را در پلتفرمی مانند rss.app وارد کنید تا یک فید RSS سفارشی برای آن ایجاد شود. سپس، با استفاده از ابزارهایی مانند Feedly برای مشاهده یا کتابخانههایی مانند feedparser در پایتون، میتوانید به راحتی محتوای فید را دریافت و پردازش نمایید. این روش نهتنها سریع و کارآمد است، بلکه از پیچیدگیهای فنی اسکرپینگ سنتی نیز جلوگیری میکند.
استفاده از فیدهای RSS واسط مزایای متعددی نسبت به اسکرپینگ سنتی دارد که آن را به گزینهای برتر برای توسعهدهندگان، تولیدکنندگان محتوا و کسبوکارها تبدیل میکند. در ادامه به تفصیل به این مزایا میپردازیم:
کارایی و سرعت بینظیر: فیدهای RSS دادهها را به صورت واقعی زمان و بدون نیاز به ارسال درخواستهای مکرر HTTP ارائه میدهند. برخلاف اسکرپینگ سنتی که نیازمند بارگذاری کامل صفحات وب، تجزیه کد HTML و استخراج دادهها از ساختارهای پیچیده است، فیدهای RSS محتوا را در قالب استاندارد XML یا JSON ارائه میکنند که آماده پردازش میباشد. طبق گزارش MoldStud (2025)، استفاده از فیدهای RSS میتواند زمان جمعآوری دادهها را تا 50% کاهش دهد، بهویژه برای وبسایتهایی با بهروزرسانیهای مکرر مانند سایتهای خبری یا بلاگها. برای مثال، یک سایت خبری مانند BBC که روزانه صدها مقاله منتشر میکند، میتواند از طریق فید RSS در کمتر از چند ثانیه بهروزرسانی شود، در حالی که اسکرپینگ همان محتوا ممکن است به دلیل بارگذاری صفحات و پردازش HTML چندین دقیقه یا حتی ساعتها طول بکشد. این سرعت بالا بهویژه برای پروژههایی که نیاز به دادههای واقعیزمان دارند، مانند نظارت بر اخبار یا تحلیل بازار، حیاتی میباشد.
کاهش خطر بلاک شدن: فیدهای RSS واسط از سرورهای معتبر استفاده میکنند که درخواستها را با هدرهای استاندارد و رفتار شبیه به کاربر انسانی ارسال میکنند. این امر خطر شناسایی و مسدود شدن توسط سیستمهای امنیتی مانند Cloudflare را به حداقل میرساند. در مقابل، اسکرپینگ سنتی اغلب به دلیل ارسال درخواستهای مکرر از یک IP یا عدم استفاده از هدرهای معتبر، منجر به بلاک شدن میشود.
دادههای ساختارمند و آماده پردازش: فیدهای RSS دادهها را در قالب XML یا JSON ارائه میدهند که شامل فیلدهای مشخصی مانند عنوان، توضیحات، لینک، تاریخ انتشار و حتی تصاویر است. این ساختارمندی نیاز به تجزیه و تحلیل پیچیده HTML را از بین میبرد. در اسکرپینگ سنتی، تغییرات در ساختار HTML سایت (مانند تغییر کلاسها یا تگها) میتواند کد اسکرپینگ را خراب کند، اما فیدهای RSS این مشکل را ندارند؛ زیرا خروجی آنها استاندارد و قابل اعتماد است.
صرفهجویی در منابع محاسباتی و مالی: اسکرپینگ سنتی نیازمند زیرساختهای پیچیدهای مانند پراکسیهای چرخشی، سرورهای ابری و ابزارهای ضدبات است که هزینههای بالایی دارند. برای مثال، هزینه پراکسیهای چرخشی میتواند ماهانه صدها دلار باشد. در مقابل، فیدهای RSS واسط نیازی به این زیرساختها ندارند و با هزینهای ناچیز یا حتی رایگان (در برخی پلتفرمها) قابل استفاده هستند. این امر بهویژه برای استارتاپها و توسعهدهندگان مستقل بسیار ارزشمند است.
اتوماسیون پیشرفته و انعطافپذیری: فیدهای RSS به راحتی با APIها و ابزارهای اتوماسیون ادغام میشوند. برای مثال، میتوان فیدها را با ابزارهایی مانند Zapier یا Make متصل کرد تا محتوای استخراجشده به صورت خودکار ترجمه، بازنویسی یا در پلتفرمهای دیگر منتشر شود. این قابلیت برای پروژههای تولید محتوای خودکار، مانند وبلاگها یا شبکههای اجتماعی، بسیار کاربردی میباشد. همچنین، امکان پردازش موازی چندین فید به صورت همزمان، بهرهوری را افزایش میدهد.
پایداری در برابر تغییرات سایت: یکی از بزرگترین مشکلات اسکرپینگ سنتی، وابستگی به ساختار HTML سایت است. اگر یک وبسایت طراحی خود را تغییر دهد (مثلاً تغییر کلاسهای CSS یا ساختار تگها)، کد اسکرپینگ نیاز به بازنویسی دارد. فیدهای RSS این مشکل را ندارند؛ زیرا محتوا از طریق سرورهای واسط به صورت استاندارد ارائه میشود. طبق گزارش MoldStud (2025)، استفاده از فیدهای RSS پایداری فرآیند جمعآوری دادهها را به طور قابلتوجهی بهبود میبخشد؛ چراکه این فیدها به تغییرات ساختار سایت وابسته نیستند و دادهها را به صورت استاندارد ارائه میدهند. برای مثال، یک فید RSS از یک وبلاگ فناوری میتواند بدون نیاز به تنظیمات مجدد، حتی پس از تغییر طراحی سایت، به کار خود ادامه دهد، در حالی که اسکرپینگ سنتی ممکن است به دلیل تغییر یک کلاس HTML از کار بیفتد.
کاهش پیچیدگی فنی: برای استفاده از فیدهای RSS، نیازی به دانش عمیق در زمینههایی مانند مدیریت پراکسی یا حل CAPTCHA نیست. ابزارهایی مانند rss.app رابط کاربری سادهای دارند که حتی کاربران غیرفنی نیز میتوانند از آن استفاده کنند.
پشتیبانی از تنوع محتوا: فیدهای RSS واسط میتوانند از انواع مختلف محتوا، از جمله متن، تصاویر، ویدیوها و حتی پادکستها پشتیبانی کنند. این تنوع به کاربران اجازه میدهد تا دادههای چندرسانهای را به راحتی جمعآوری و استفاده کنند.
استفاده از دادههای وب همیشه با مسائل قانونی و اخلاقی همراه است. در ادامه به بررسی این جنبهها در مورد اسکرپینگ و فیدهای RSS میپردازیم:
قانونیت اسکرپینگ: اسکرپینگ وب در صورتی که دادهها عمومی باشند و از فایل robots.txt سایت پیروی کنند، معمولاً قانونی است. با این حال، استفاده تجاری از دادههای اسکرپشده ممکن است نقض قوانین کپیرایت یا شرایط خدمات (Terms of Service) سایت باشد. طبق گزارش ScraperAPI، اسکرپینگ برای اهداف شخصی (مانند تحقیقات دانشگاهی) معمولاً مجاز است، اما فروش دادهها یا استفاده تجاری بدون اجازه میتواند مشکلات قانونی ایجاد نماید. برای مثال، در سال 2022، پرونده LinkedIn علیه hiQ Labs نشان داد که اسکرپینگ دادههای عمومی ممکن است قانونی باشد، اما باید با احتیاط انجام شود.
مزیت اخلاقی RSS: فیدهای RSS معمولاً اخلاقیتر از اسکرپینگ سنتی هستند، زیرا محتوا توسط خود سایت یا سرورهای واسط به صورت مجاز توزیع میشود. این روش کپی مستقیم محتوا را شامل نمیشود و اغلب به صورت خلاصه یا لینک ارائه میشود که به منبع اصلی ارجاع میدهد. این امر خطر نقض کپیرایت را کاهش میدهد.
رعایت GDPR و حریم خصوصی: در اروپا، مقررات GDPR (General Data Protection Regulation) هرگونه جمعآوری دادههای شخصی را محدود میکند. هنگام استفاده از فیدهای RSS، باید اطمینان حاصل کنید که دادههای جمعآوریشده شامل اطلاعات شخصی کاربران نیست؛ مگر اینکه اجازه صریح وجود داشته باشد. همچنین، باید از ایجاد بار اضافی بر سرورهای سایت (مانند ارسال درخواستهای بیش از حد) اجتناب کرد.
ملاحظات اخلاقی: از نظر اخلاقی، استفاده از فیدهای RSS باید برای اهداف مفید و غیرمضر باشد. برای مثال، ذکر منبع اصلی محتوا و اجتناب از بازنشر کامل مقالات بدون اجازه، نشانهای از رعایت اخلاق است. همچنین، استفاده از RSS برای اهداف قانونی مانند تجمیع اخبار یا تحلیل دادههای عمومی، به جای سوءاستفاده از محتوا، توصیه میشود.
برای استفاده از فیدهای RSS واسط، مراحل زیر را دنبال کنید تا فرآیند جمعآوری دادههای خود را بهینه کنید:
انتخاب ابزار مناسب: ابزارهایی مانند rss.app ،Feedly یا Inoreader گزینههای محبوبی برای ایجاد و مدیریت فیدهای RSS هستند. rss.app به دلیل پشتیبانی از سایتهای بدون RSS بومی و قابلیتهای پیشرفته مانند تبدیل به JSON، گزینهای عالی است.
ایجاد فید سفارشی: به وبسایت rss.app بروید، URL سایت هدف را وارد کنید و فید RSS سفارشی ایجاد کنید. این ابزار به شما امکان میدهد نوع محتوا (مانند مقالات، تصاویر یا ویدیوها) را مشخص کنید.
خواندن فید با کد: برای اتوماسیون، از کتابخانههای پایتون مانند feedparser استفاده کنید. نمونه کد زیر نحوه خواندن فید را نشان میدهد:
import feedparser feed = feedparser.parse('https://example.com/rss') for entry in feed.entries: print(f"Title: {entry.title}") print(f"Link: {entry.link}") print(f"Summary: {entry.summary}") print("---")
تنظیمات پیشرفته: از فیلترهای پیشرفته rss.app برای محدود کردن محتوا به کلمات کلیدی خاص یا دستهبندیها استفاده کنید. همچنین، میتوانید فید را به فرمتهای دیگر مانند CSV صادر کنید.
ادغام با ابزارهای دیگر: فیدها را با ابزارهای اتوماسیون مانند Zapier متصل کنید تا محتوا به صورت خودکار در پلتفرمهایی مانند WordPress ،X یا Google Sheets منتشر شود.
نظارت و بهروزرسانی: فیدها را به طور منظم بررسی کنید تا از بهروز بودن آنها مطمئن شوید. برخی ابزارها مانند rss.app امکان ارسال اعلان برای بهروزرسانیهای جدید را دارند.
فیدهای RSS واسط یک راهکار انقلابی و کارآمد برای غلبه بر چالشهای اسکرپینگ وبسایتهای محافظتشده هستند. این روش با ارائه دادههای ساختارمند، کاهش خطر بلاک شدن، صرفهجویی در منابع و امکان اتوماسیون پیشرفته، جایگزینی قدرتمند برای اسکرپینگ سنتی است.
با مطالعه مثالهای واقعی، مسائل قانونی و اخلاقی و راهنماییهای عملی ارائهشده در این مقاله، امیدواریم که شما بتوانید به طور کامل از پتانسیل فیدهای RSS برای پروژههای خود بهرهمند شوید. برای شروع، ابزارهایی مانند rss.app را بررسی کنید و فرآیند جمعآوری دادههای خود را به سطح جدیدی ارتقاء دهید.
تهیه شده توسط تیم تخصصی سئو سید احسان خسروی (مدیر، متخصص و مشاور استراتژیک سئو)