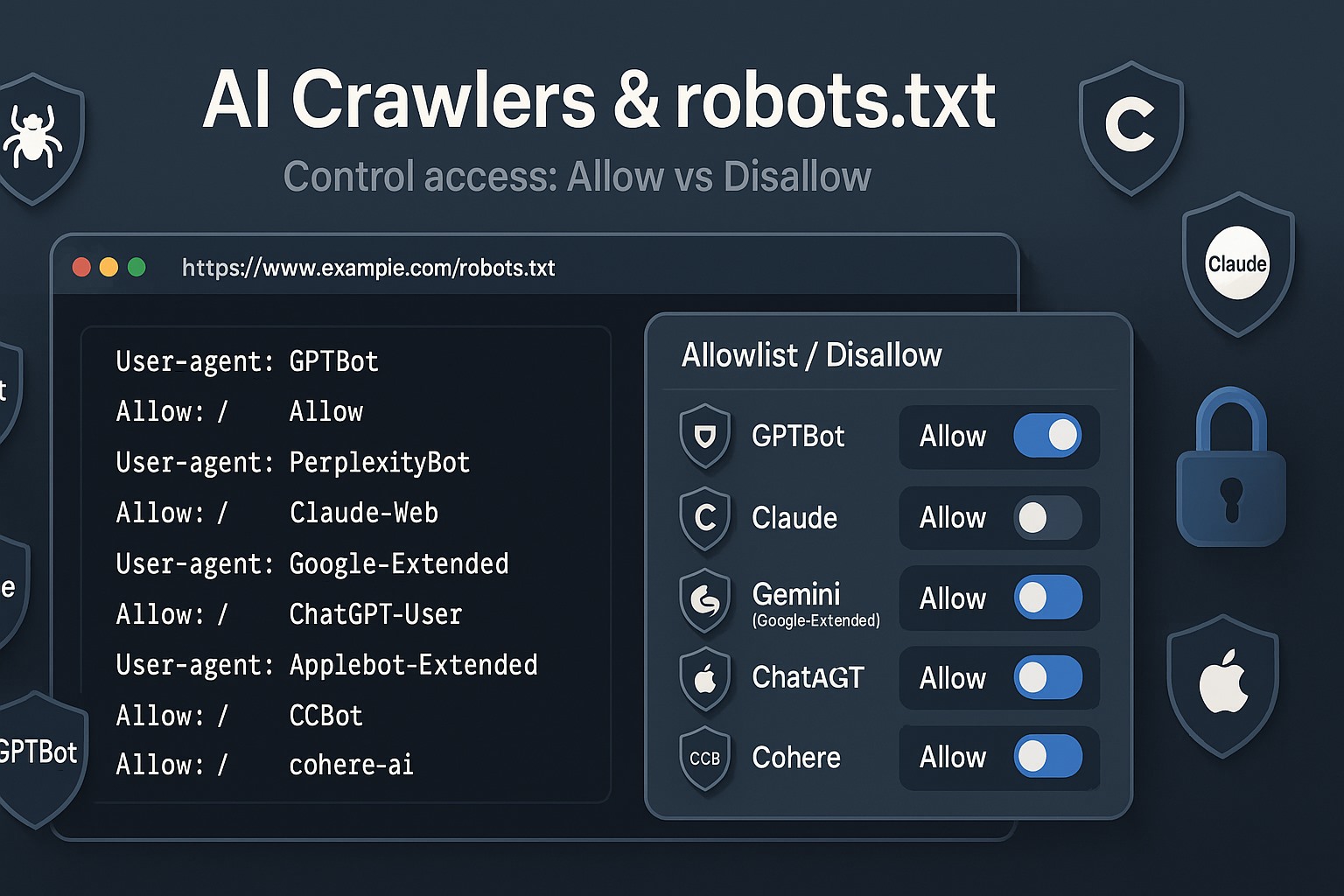
robots.txt سالها یک ابزار ساده برای مدیریت ترافیک خزندهها بود؛ اما با ظهور موتورهای جستجوی مولد، چتباتها و ایجنتهای وب، این فایل تبدیل شده به نقطهٔ تصمیمگیری درباره سه چیز:
۱) چه کسی میتواند به محتوای شما دسترسی بگیرد، ۲) این دسترسی برای چه هدفی است (نمایش، جستجو، یا آموزش مدل)، و ۳) با چه محدودیتهایی.
نکته کلیدی اینجاست: همه رباتها یکسان نیستند. برخی فقط برای جستجو و ارجاع ترافیک میآیند، بعضی صرفاً وقتی کاربر از ربات میخواهد صفحهای را بخواند سر میزنند و گروهی هم برای ساخت/بهروزرسانی مدلهای زبانی داده جمع میکنند. شما باید این تفاوتها را بشناسید تا به جای «اجازه/ممنوع» کلی، یک سیاست دقیق و قابلدفاع پیاده کنید. مستندات رسمی گوگل تأکید میکند که robots.txt ابزاری برای مدیریت دسترسی خزندههاست و الزامآور حقوقی نیست؛ خزندههای معتبر آن را رعایت میکنند، اما برای اطلاعات حساس باید راهکارهای فنی دیگری کنار آن بگذارید.
در این مقاله، صفر تا صد مدیریت دسترسی ایجنتها/چتباتها را پوشش میدهیم: از شناخت اکوسیستم رباتها و تفاوت اهدافشان، تا الگوهای پیکربندی دقیق، نکات اجرایی، آزمون و مانیتورینگ و چکلیست پیادهسازی.
برای طراحی یک robots.txt حرفهای، اول باید انواع «کاربر-ایجنت»ها و نقششان را تفکیک کنید. در عمل، با سه دسته اصلی طرفید:
این رباتها محتوای شما را برای نمایش و لینکدهی در نتایج جستجوی درون چتباتها/تجربههای جستجوی مولد میخوانند؛ هدف آنها آموزش مدلهای پایه نیست.
OpenAI – OAI-SearchBot: برای ظاهر شدن در نتایج جستجوی ChatGPT باید این عامل را مسدود نکنید. خود OpenAI صراحتاً میگوید OAI-SearchBot برای «Surfacing» یا «نمایش دادن محتوا در نتایج جستجو» است و برای آموزش مدلهای پایه استفاده نمیشود.
Anthropic – Claude-SearchBot: برای بهبود کیفیت نتایج جستجوی مبتنی بر Claude. غیرفعال کردن آن، محتوای شما را از ایندکس جستجویشان حذف میکند.
Apple – Applebot (خزنده جستجو) و «Applebot-Extended» (توکن کنترل آموزش): Applebot برای جستجو است؛ Applebot-Extended به شما امکان میدهد آموزش مدلها را محدود کنید، بدون اینکه لزوماً در جستجو حذف شوید.
Perplexity – PerplexityBot: برای نمایش و لینکدهی نتایج در Perplexity جستجو میکند؛ طبق مستند رسمی، برای «آموزش مدلهای پایه» استفاده نمیشود.
Common Crawl – CCBot: کرال عمومی برای پایگاه داده Common Crawl که مبنای بسیاری از پژوهشها/مدلهاست. امکان تأیید اصالت از طریق rDNS فراهم است.
وقتی یک کاربر از داخل چتبات از ربات میخواهد صفحهای را بخواند، این ایجنتها به نمایندگی از کاربر درخواست میفرستند:
OpenAI – ChatGPT-User: فقط وقتی کاربر واقعاً درخواست دسترسی میدهد، به وب سر میزند؛ و مطابق مستندات رسمی، robots.txt را رعایت میکند.
Anthropic – Claude-User: مشابه مورد بالا برای اکوسیستم Claude.
اینها برای گردآوری داده جهت آموزش/بهروزرسانی مدلهای مولد استفاده میشوند. سیاست شما درباره این دسته از منظر حقوقی/برند و بار سرور اهمیت ویژه دارد:
OpenAI – GPTBot: کرالر رسمی برای بهبود مدلها. میتوانید به صورت مسیری یا کلی، اجازه یا محدودیت بدهید.
Apple – Applebot-Extended: خودش کرال نمیکند؛ یک «توکن کنترلی» در robots.txt است تا اجازه/ممنوعیت استفاده آموزشی از داده کرالشده توسط Applebot را تعیین کند.
Anthropic – ClaudeBot: برای داده آموزشی؛ غیرفعال کردنش سیگنال عدماستفاده آتی در دیتاستهای آموزشی آنهاست. Anthropic صراحتاً از Crawl-delay هم پشتیبانی میکند.
Google – Google-Extended: «ربات» نیست؛ یک توکن robots.txt برای کنترل استفاده از محتوایتان در Bard/Gemini/Vertex AI و نسلهای بعدی.
توجه: برخی عوامل دیگر مثل «cohere-ai» گزارش شدهاند، اما مستندات رسمی عمومی واضحی ندارند؛ اگر میخواهید با دید محافظهکارانه عمل کنید، میتوانید برایشان قاعده بگذارید، اما «منبع رسمی» را همواره بررسی کنید.
جایگاه و دامنه اثر: فایل فقط در ریشه هر میزبان/پروتکل اعمال میشود (example.com/robots.txt جدا از www.example.com/robots.txt).
تقدم قواعد: گروهی با دقیقترین تطابق User-agent اعمال میشود؛ قواعد «User-agent: *» نقش پیشفرض دارند؛ ترتیب خطوط درون گروه مهم است اما «گروهِ انتخابشده» با دقیقترین تطابق تعیین میشود. (برای جزئیاتِ نحوهٔ تفسیر در گوگل به مستنداتشان رجوع کنید.)
محدودیتهای حقوقی و فنی: robots.txt ضمانت قضایی نیست؛ خزندههای معتبر رعایت میکنند ولی برای اسرار تجاری/داده حساس به احراز هویت، کنترل دسترسی و ابزارهای شبکهای متکی باشید.
دستورهای غیرمعیاری: Crawl-delay بخشی از استاندارد رسمی نیست؛ بعضیها (مثل Anthropic) احترام میگذارند، بعضیها (مثل Googlebot) نادیده میگیرند.
X-Robots-Tag و meta robots: اینها «ایندکس» را کنترل میکنند، نه «دسترسی خزنده»؛ برای مدیریت سرچ کلاسیک کنار robots.txt استفاده میشوند.
«اثر گذشته»: ممانعت امروز مانع استفاده از دادهای که پیشتر جمع شده نمیشود؛ این نکته را سازمانهای مدنی نیز گوشزد کردهاند.
برای هر «عامل» یکی از این سه سیاست را تعیین کنید:
۱) اجازه کامل برای «نمایش/جستجو»، اما منع «آموزش»
۲) اجازه محدود (فقط برخی مسیرها)
۳) ممنوعیت کامل
این تصمیم را با این پرسشهای راهبردی مشخص کنید:
آیا این منبع ترافیک ارجاعی میآورد (Referral/Brand Visibility)؟ (مثلاً OAI-SearchBot یا PerplexityBot)
آیا استفاده آموزشی با منافع/قراردادهای شما همراستاست؟ (مثلاً GPTBot ،ClaudeBot ،Applebot-Extended)
هزینه منابع سرور و ریسکهای امنیتی/حقوقی چیست؟ (Common Crawl rDNS و سیاستهای سرعتکرال را بسنجید.)
سناریو: ناشر محتوا که میخواهد دیده شود، اما نمیخواهد دادهاش برای آموزش مدلها مصرف شود.
# اجازه به ایجنتهای جستجو/نمایش User-agent: OAI-SearchBot Allow: / User-agent: PerplexityBot Allow: / User-agent: Applebot Allow: / User-agent: Claude-SearchBot Allow: / # منع آموزش مدلها User-agent: GPTBot Disallow: / User-agent: ClaudeBot Disallow: / User-agent: Applebot-Extended Disallow: / # اجازهٔ واکشی کاربرمحور (در صورت تمایل) User-agent: ChatGPT-User Allow: / User-agent: Claude-User Allow: /
سناریو: فقط میخواهید مستندات/سوالات پرتکرار دیده شوند.
# پیشفرض: ممنوع User-agent: * Disallow: / # اجازهٔ محدود به پوشهٔ مستندات User-agent: OAI-SearchBot Allow: /docs/ Disallow: / User-agent: PerplexityBot Allow: /docs/ Disallow: / User-agent: Applebot Allow: /docs/ Disallow: / User-agent: Claude-SearchBot Allow: /docs/ Disallow: / # منع آموزش User-agent: GPTBot Disallow: / User-agent: ClaudeBot Disallow: / User-agent: Applebot-Extended Disallow: /
سناریو: داده حساس یا ریسک بالا/ظرفیت پایین.
User-agent: * Disallow: / # یا بهصورت صریح برای هر عامل اصلی: User-agent: GPTBot Disallow: / User-agent: OAI-SearchBot Disallow: / User-agent: ChatGPT-User Disallow: / User-agent: ClaudeBot Disallow: / User-agent: Claude-SearchBot Disallow: / User-agent: Claude-User Disallow: / User-agent: PerplexityBot Disallow: / User-agent: CCBot Disallow: / User-agent: Applebot Disallow: / User-agent: Applebot-Extended Disallow: /
# Anthropic صراحتاً Crawl-delay را میپذیرد User-agent: ClaudeBot Crawl-delay: 2 Allow: / # برای دیگران روی WAF/Rate Limit حساب کنید (Googlebot Crawl-delay را نادیده میگیرد)
نکته اجرایی: اگر ترکیبی از «Allow و Disallow» در یک گروه میدهید، حتماً مسیرهای دقیق را مشخص کنید و روی مسیرهای حساس (admin/ ،/checkout ،/cart ،/wp-admin/ و …) صریحاً Disallow بگذارید.
OpenAI سه نقش متمایز دارد: GPTBot (آموزش)، OAI-SearchBot (جستجو/سرفیسینگ) و ChatGPT-User (دسترسی کاربرمحور). آنها به صورت رسمی کاربری هرکدام را تفکیک کردهاند.
Apple «Applebot-Extended» را برای کنترل استفاده آموزشی معرفی کرده است؛ Applebot همچنان برای جستجو به کار میرود.
Anthropic سه عامل مجزا دارد و حتی از Crawl-delay پشتیبانی میکند؛ غیرفعال کردن هرکدام اثر متفاوتی دارد (آموزش، جستجو یا واکشی کاربرمحور).
PerplexityBot برای نمایش و لینکدهی نتایج است؛ اگر میخواهید در نتایج Perplexity دیده شوید، اجازه بدهید.
Common Crawl امکان راستیآزمایی rDNS و محدوده IP اختصاصی دارد (برای تشخیص جعل User-Agent).
Google-Extended «خزنده» نیست؛ یک توکن robots.txt برای کنترل استفاده داده در مدلهای مولد گوگل است و ماهیتش با Googlebot فرق دارد.
۱) یک فایل برای هر میزبان/پروتکل: example.com و www.example.com فایلهای جدا میخواهند.
۲) رمزگذاری UTF-8 و متن ساده؛ خطوط نامعتبر نادیده گرفته میشوند.
۳) Sitemap را در robots.txt اعلان کنید؛ برای کرالرهایی که پشتیبانی میکنند:
Sitemap: https://example.com/sitemap.xml
۴) «پیشفرض امن» بچینید: ابتدا Disallow برای * و سپس Allowهای انتخابی برای ایجنتهای هدف.
۵) Caching: بعضی خزندهها robots.txt را کش میکنند؛ تغییرات را با لاگها و ابزارهای تست راستیآزمایی کنید.
۶) ایمنسازی لایه شبکه: چون robots.txt داوطلبانه است، برای داده حساس روی احراز هویت، WAF ،Rate limiting و بلاک IP/ASN هم حساب کنید (اپل حتی CIDRهای Applebot را منتشر کرده است).
۷) تمایز «عدم نمایش در نتایج جستجو کلاسیک» با «عدم استفاده آموزشی»: meta robots/X-Robots-Tag فقط «ایندکس» را کنترل میکنند، نه آموزش مدلها. برای آموزش باید به توکنهای آموزشی (GPTBot/Applebot-Extended/ClaudeBot و …) قاعده بدهید.
۸) اثر گذشته را فراموش نکنید: Opt-out امروز، برداشتهای قبلی را پاک نمیکند. برای این بخش توقع درست ایجاد کنید.
تست دستی با cURL:
curl -I https://example.com/robots.txt curl -A "GPTBot" -I https://example.com/protected-path/
بررسی لاگهای وبسرور: ضربِ آهنگ درخواست، مسیرها، و User-Agent را زیر نظر بگیرید.
راستیآزمایی اصالت عاملها:
Common Crawl: rDNS باید به crawl.commoncrawl.org.* ختم شود.
Applebot: rDNS دامنهٔ *.applebot.apple.com و تطبیق با CIDRهای رسمی.
ابزارهای کنسول جستجو (برای گوگل): URL Inspection/Live Test جهت فهم «Crawl allowed?» و «Indexing allowed?».
هدف: دیده شدن در جستجو و دریافت ترافیک ارجاعی، اما عدماستفاده آموزشی.
راهبرد: Allow برای OAI-SearchBot/PerplexityBot/Applebot/Claude-SearchBot و Disallow برای GPTBot/ClaudeBot/Applebot-Extended. (اثر تجاری OAI-SearchBot در ارجاع ترافیک توسط خود OpenAI توضیح داده شده است.)
هدف: حضور در جستجوهای محصولی و مقایسهای، با ممنوعیت آموزش.
راهبرد: مشابه سناریوی ۱؛ بهعلاوه محدودسازی مسیرهای سبد/چکاوت/داشبورد مشتری با Disallow سراسری برای همه ایجنتها.
هدف: فقط docs/ باز باشد، باقی بخشها بسته.
راهبرد: الگوی B (whitelist) + Sitemap.
هدف: مسدودسازی کامل و اجرای انسداد در لایه شبکه.
راهبرد: الگوی C + WAF/Rate limit + احراز هویت. یادآوری: robots.txt بهتنهایی کافی نیست.
دامنه/زیردامنه و پروتکلها را فهرست کنید؛ برای هرکدام robots.txt جداگانه بسازید.
تصمیم سیاستی برای هر عامل:
آموزش: GPTBot ،ClaudeBot ،Applebot-Extended (توکن)
جستجو/نمایش: OAI-SearchBot ،Claude-SearchBot ،Applebot ،PerplexityBot ،CCBot
واکشی کاربرمحور: ChatGPT-User ،Claude-User
الگوی مناسب (A/B/C/D) را انتخاب و مسیرهای حساس را صریحاً Disallow کنید.
Sitemap را اضافه کنید و لاگها را برای تأیید رعایتپذیری مانیتور کنید.
راستیآزمایی اصالت (rDNS/CIDR) برای Applebot/CCBot.
تست با cURL و ابزارهای کنسول جستجو (Crawl allowed? / Indexing allowed?).
سیاست را هر ۳–۶ ماه بازبینی کنید (ایجنتهای جدید/بهروزرسانی نامها).
پیشنهاد میشود در ابتدای robots.txt، یک کامنت کوتاه سیاستی بگذارید تا همکاران آینده بدانند چرا این قواعد نوشته شدهاند:
# سیاست سازمان: اجازهٔ سرفیسینگ و ارجاع ترافیک؛ منع استفادهٔ آموزشی. # آخرین بازبینی: 2025-08-20 # تماس: seo@example.com / security@example.com # سرفیسینگ/جستجو User-agent: OAI-SearchBot Allow: / User-agent: Applebot Allow: / User-agent: PerplexityBot Allow: / User-agent: Claude-SearchBot Allow: / # واکشی کاربرمحور User-agent: ChatGPT-User Allow: / User-agent: Claude-User Allow: / # آموزش مدلها User-agent: GPTBot Disallow: / User-agent: ClaudeBot Disallow: / User-agent: Applebot-Extended Disallow: / # مسیرهای حساس برای همه User-agent: * Disallow: /admin/ Disallow: /cart/ Disallow: /checkout/ Disallow: /account/ Disallow: /wp-admin/ # نقشهٔ سایت Sitemap: https://example.com/sitemap.xml
استفاده از «Allow» بدون «Disallow» پایه: اگر میخواهید فقط محدودهای را باز کنید، ابتدا Disallow کلی بدهید و سپس Allow مسیر مجاز (طبق الگوی B).
تکیه کامل بر robots.txt برای داده حساس: الزامی نیست؛ حتماً احراز هویت/محدودیتهای شبکه را اضافه کنید.
یکسان فرض کردن عاملها: OAI-SearchBot ≠ GPTBot؛ Applebot ≠ Applebot-Extended؛ Claude-SearchBot ≠ ClaudeBot. سیاست را بر اساس هدف هرکدام بنویسید.
نادیده گرفتن اثر گذشته: انتظار پاک شدن دادههای قدیمی نداشته باشید.
فراموش کردن لاگینگ و مانیتورینگ: بدون لاگ نمیتوانید رعایتپذیری را بسنجید؛ rDNS/ CIDRها را برای تأیید اصالت استفاده کنید.
robots.txt امروز یک «اهرم سیاستگذاری داده» است. با شناخت تفاوت نقش ایجنتها (نمایش، واکشی کاربرمحور، و آموزش) میتوانید به جای «اجازه/ممنوع» کلی، یک سیاست جزئینگر، شفاف و قابلدفاع بسازید: سرفیسینگ (Surfacing) را باز بگذارید تا دیده شوید و ترافیک بگیرید و همزمان استفاده آموزشی را مطابق منافع و حساسیتهای برند محدود کنید.
کلید موفقیت، سه چیز است: مستندسازی دقیق، مانیتورینگ مستمر و بازنگری دورهای؛ چون اکوسیستم ایجنتها دائماً در حال تغییر است و نامها/کارکردها بهروزرسانی میشوند. منابع رسمی هر ارائهدهنده را دنبال کنید و هر سه تا شش ماه سیاستها را بازبینی کنید.
Google-Extended «توکن کنترل داده آموزشی» است، نه Googlebot. بستن آن نباید مانع کرال/ایندکس در جستجوی کلاسیک شود؛ اما سیاستها میتوانند در زمان تغییر کنند، پس صفحه سیاستهای رسمی و اخبار را رصد کنید.
robots.txt داوطلبانه است. برای داده حساس باید به کنترل دسترسی، محتوای پشت لاگین و ابزارهای شبکه (WAF ،Rate limit ،IP/ASN block) تکیه کنید. برای برخی رباتها روشهای تأیید اصالت (rDNS/IP) مستند شده است.
برخی ایجنتها Crawl-delay را میپذیرند (مانند Anthropic) اما Googlebot آن را نادیده میگیرد. برای گوگل از تنظیمات Search Console و برای بقیه از Rate limit در لایه شبکه استفاده کنید.
در کل، Opt-out روی گذشته اثر ندارد. این را شفاف به ذینفعان بگویید تا انتظار اشتباهی شکل نگیرد.
تهیه شده توسط تیم تخصصی سئو سید احسان خسروی (مدیر، متخصص و مشاور استراتژیک سئو)