اگر وبسایت شما به هر شکلی به جاوا اسکریپت متکی است، از SPA گرفته تا صفحات سادهای که فقط چند رفتار تعاملی دارند، احتمالاً بارها با این ایده روبهرو شدهاید که «هر چیزی را میشود بعد از لود با JavaScript اصلاح کرد». این نگاه در تجربه کاربری شاید جواب بدهد، اما در سئو تکنیکال یک نقطه شکست جدی دارد: گوگل لزوماً همیشه به مرحلهای نمیرسد که کد شما را اجرا کند.
همین جمله کوتاه، دقیقاً همان چیزی است که گوگل در مستندات رسمی JavaScript SEO Basics شفافتر کرده و به زبان ساده میگوید اگر تصمیمهای حیاتی درباره ایندکس شدن و گاهی حتی رندر شدن را به JavaScript بسپارید، دارید روی یک فرآیند غیرقطعی شرط میبندید.
این بروزرسانی از آن جنس تغییرهایی است که شاید در ظاهر فقط یک اصلاح واژهای به نظر برسد، اما در عمل میتواند مسیر طراحی معماری صفحات، سیاستهای انتشار محتوا و حتی فرآیند دیباگ تیمهای سئو و توسعه را تغییر بدهد.
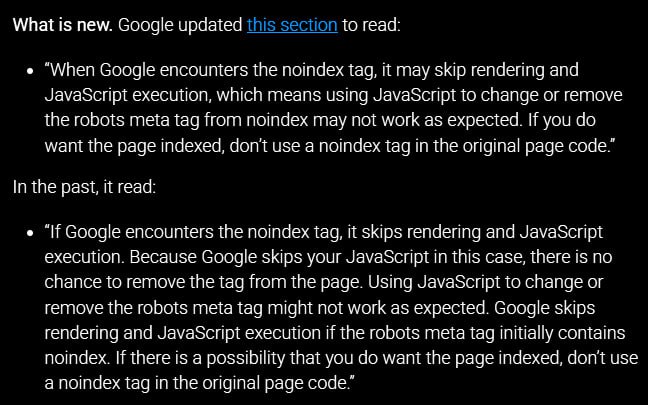
در نسخه جدید مستندات «Understand the JavaScript SEO basics»، گوگل در بخش مربوط به robots meta tag و noindex، جملهای اضافه کرده که پیامش روشن است: وقتی Google با noindex مواجه میشود، ممکن است رندر و اجرای جاوا اسکریپت را رد کند. نتیجه هم مشخص است: اگر شما امید دارید که بعداً با JavaScript مقدار noindex را بردارید یا به index تغییر دهید، ممکن است گوگل اصلاً آن بخش را نبیند.
نکته مهمتر اینجاست که گوگل از عبارتی استفاده کرده که «عدم قطعیت» را مستقیم وارد بازی میکند: به جای اینکه بگوید حتماً رندر انجام نمیشود، گفته «ممکن است» انجام نگردد. این یعنی رفتار رندر در این سناریو تضمینشده نیست و میتواند تحتتأثیر منابع رندر، سیاستهای پردازشی و شرایط مختلف تغییر کند. همین عدم قطعیت برای سئو کافی است تا بگوییم: کنترل ایندکس را به چیزی که ممکن است اجرا نشود نسپارید.
در دنیای مهندسی نرمافزار، وقتی یک رفتار «احتمالی» میشود، یعنی شما دیگر نمیتوانید روی آن به عنوان ستون اصلی معماری حساب کنید. سئو هم دقیقاً همین میباشد: اگر یک مسیر، تضمینی نیست، نمیتواند محل تصمیمهای حیاتی باشد.
اما تصمیمهای حیاتی یعنی چه؟ یعنی هر سیگنالی که تعیین میکند یک URL وارد ایندکس شود یا نه، چه چیزی نسخه اصلی صفحه است و آیا گوگل باید صفحه را اصلاً ارزش پردازش بیشتر بداند یا نه. مثل:
meta robots و noindex؛
هدر X-Robots-Tag؛
؛rel=canonical
وضعیتهای HTTP مانند 200، 301، 404، 410؛
سیاستهای دسترسی و بلاک کردن محتوا.
وقتی شما این سیگنالها را «بعد از لود» و «بعد از اجرای JS» تنظیم میکنید، دارید آنها را به مرحلهای میبرید که شاید اتفاق نیفتد. این همان جایی است که گوگل دارد خیلی صریح هشدار میدهد.
برای اینکه عمق پیام را درست بگیریم، باید مدل پردازش صفحات جاوا اسکریپتی در گوگل را مثل یک خط تولید ببینیم، نه یک عملیات همزمان.
در مستندات خود گوگل، این فرآیند به سه فاز اصلی تقسیم میشود: کراول (Crawling)، رندر (Rendering) و ایندکس (Indexing). یعنی اول HTML اولیه و منابع کشف میشوند، بعد (در صورت نیاز) صفحه وارد صف رندر میشود، سپس خروجی رندرشده برای استخراج نهایی محتوا و لینکها و سیگنالها استفاده میشود.
گوگل صریحاً توضیح میدهد که Googlebot همه صفحات را برای رندر در صف قرار میدهد، مگر اینکه یک robots meta tag یا هدر به گوگل بگوید صفحه نباید ایندکس شود. بعد هم وقتی منابع اجازه بدهد، یک Chromium بدون رابط (headless) صفحه را رندر میکند و جاوا اسکریپت را اجرا مینماید.
همین یک جمله کافی است تا بفهمیم چرا noindex در HTML اولیه خطرناک میگردد: چون noindex میتواند مانع ورود صفحه به صف رندر شود. یعنی قبل از اینکه JavaScript شما فرصت نفس کشیدن داشته باشد، مسیر پردازش قطع میگردد.
از نگاه مهندسی، این کاملاً منطقی است. رندر کردن جاوا اسکریپت هزینه دارد. وقتی یک صفحه با noindex اعلام میکند «برای نتایج جستجو کاربردی نیست»، سیستم میتواند تصمیم بگیرد هزینه رندر را پرداخت نکند. حالا اگر شما برنامهتان این بوده که بعداً با JS بگویید «نه، اتفاقاً این صفحه باید ایندکس شود»، دارید خلاف جهت یک سیگنال اولیه حرکت میکنید. همین تضاد، منشأ ریسک است.
بیشتر خطاهای سئو در سایتهای جاوا اسکریپتی، نه از «وجود JS»، بلکه از «محل تصمیمگیری» ناشی میشود. بیایید دو سناریوی رایج را دقیقتر ببینیم.
این همان چیزی است که گوگل عملاً دربارهاش هشدار داده: شما در پاسخ اولیه سرور این را دارید:
<meta name="robots" content="noindex">
بعد در JavaScript (مثلاً پس از دریافت پاسخ از API یا تشخیص وضعیت کاربر) آن را حذف میکنید یا به index تغییر میدهید. مشکل اینجاست که ممکن است گوگل اصلاً جاوا اسکریپت را اجرا نکند و صفحه همانطور noindex باقی بماند. این دقیقاً همان جملهای است که گوگل اضافه کرده و میگوید ممکن است رندر و اجرای JS در مواجهه با noindex انجام نشود.
نتیجه عملی:
صفحهای که باید ایندکس شود، به شکل مرموزی ایندکس نمیگردد یا مدام بین وضعیتها نوسان دارد یا در Search Console رفتارهای غیرقابل پیشبینی نشان میدهد.
این سناریو هم رایج است، مخصوصاً در فروشگاهها یا اپهای مبتنی بر API. شما یک URL محصول دارید، صفحه با 200 لود میشود، بعد API میگوید محصول وجود ندارد و شما با JS یک meta robots noindex تزریق میکنید.
جالب اینجاست که مستندات گوگل نمونه کد همین مدل را هم نشان میدهد، اما دقیقاً کنار همان بخش هشدار میدهد که noindex ممکن است باعث شود رندر و اجرای JavaScript انجام نگردد، پس استفاده از JS برای تغییر یا حذف robots meta tag از noindex ممکن است طبق انتظار کار نکند.
پس چه کار باید کرد؟ اگر صفحه واقعاً «وجود ندارد»، راه استاندارد مهندسی وب این است که سرور همان ابتدا وضعیت مناسب برگرداند (مثل 404 یا 410) یا به صفحه مناسب ریدایرکت کند. اگر هم بنا به دلایل سیاستی یا فنی لازم است URL در دسترس کاربر بماند اما ایندکس نشود (مثلاً صفحات داخلی، نتایج جستجوی سایت، صفحات وابسته به ورود یا صفحات کمارزش برای سرچ)، باز هم تصمیم را بهتر است در سطح سرور بگیرید، نه بعد از لود.
یکی از ریشههای گیجی در تیمها این است که noindex را با بلاک کردن کراول قاطی میکنند. اینها یک چیز نیستند.
گوگل در مستندات noindex خیلی روشن میگوید برای اینکه noindex اثر کند، صفحه نباید توسط robots.txt بلاک شده باشد و باید برای کراولر قابل دسترسی باشد، وگرنه گوگل اصلاً noindex را نمیبیند.
این نکته مهم است؛ چون بعضی سایتها همزمان هم robots.txt را Disallow میکنند و هم meta noindex میگذارند و بعد تعجب میکنند چرا URL هنوز در نتایج دیده میشود یا چرا حذف نمیگردد. اگر گوگل نتواند صفحه را بخزد، سیگنال noindex را هم نمیبیند.
robots.txt ابزار کنترل دسترسی خزنده به URL است. اما اگر هدف شما حذف از نتایج است، noindex (به شرط قابل کراول بودن) سیگنال صریحتری میباشد. پس وقتی هدف «عدم نمایش در سرچ» است، به جای اینکه صفحه را کورکورانه Disallow کنید، باید استراتژی را دقیق طراحی نمایید: چه چیزی باید کراول شود، چه چیزی باید ایندکس شود و چه چیزی باید فقط برای کاربر باشد.
در بسیاری از پروژهها، URLهایی که عملاً «وجود ندارند» با وضعیت 200 برمیگردند و بعد با یک پیام خطا در UI، داستان تمام میشود. از دید کاربر شاید قابل قبول باشد، اما از دید گوگل این میتواند شبیه soft 404 یا محتوای بیارزش تلقی گردد و روی کیفیت خزیدن و درک سایت اثر بگذارد. بهترین حالت این است که سرور در همان پاسخ اولیه تکلیف را روشن کند.
اگر بخواهیم پیام گوگل را خیلی خلاصه بگوییم: کنترل قابل اتکاء زمانی اتفاق میافتد که robots ،noindex ،canonical و تصمیمهای مشابه از همان HTML اولیه یا هدرهای HTTP به گوگل اعلام شوند؛ چون ممکن است صفحه اصلاً وارد مرحله رندر و اجرای جاوا اسکریپت نگردد.
حالا بیایید این اصل را به چند راهکار عملی و قابل اجرا تبدیل کنیم.
این توصیه مستقیم گوگل است: اگر میخواهید صفحه ایندکس شود، noindex را از کد اولیه حذف کنید. حتی اگر برنامهتان این است که بعداً شرایط تغییر کند، باز هم گذاشتن noindex در ابتدا، یعنی باز کردن در یک ریسک غیرقابل پیشبینی.
گوگل برای پیادهسازی noindex دو راه استاندارد را معرفی میکند: meta tag در head و هدر HTTP با X-Robots-Tag. این دو از نظر اثرگذاری یکساناند، فقط جای پیادهسازی فرق میکند.
برای منابع غیر HTML مثل PDF، تصویر یا ویدیو، خود گوگل توصیه میکند از X-Robots-Tag استفاده نمایید.
اگر وضعیت ایندکس قرار است وابسته به شرایط باشد، مثلاً نوع کاربر، وضعیت محصول، منطقه، زبان، یا انتشار مرحلهای، بهتر است تصمیم در لحظه تولید پاسخ HTTP گرفته شود. در عمل این میتواند یکی از اینها باشد:
SSR در فریمورکهایی مثل Next.js ،Nuxt ،Remix یا هر سرور رندر دیگری؛
middleware روی سرور یا در لایه reverse proxy؛
edge middleware برای تصمیمگیری نزدیک به کاربر.
اصل ماجرا این است که گوگل همان چیزی را ببیند که شما برایش تصمیم گرفتهاید، بدون اینکه مجبور باشد منتظر اجرای JS بماند.
گوگل در همان مستندات میگوید تزریق rel=canonical با JavaScript ممکن است و گوگل هنگام رندر آن را میبیند، اما توصیه نمیکند و هشدار میدهد پیادهسازیهای اشتباه میتوانند چند canonical بسازند یا canonical موجود را تغییر دهند و نتایج غیرمنتظره بدهند.
بنابراین اگر canonical برایتان مهم میباشد، بهتر است آن را از همان HTML اولیه، دقیق، یکتا و بدون تناقض ارائه کنید.
بخش مهمی از پروژههای امروز روی CSR یا SPA بنا شدهاند و واقعیت این است که خیلی از آنها هم به خوبی در گوگل دیده میشوند. پس مسئله «استفاده از JavaScript» نیست، مسئله «وابسته کردن سیگنالهای حیاتی به JavaScript» است.
برای اینکه در SPA هم به سئو ضربه نزنید، چند الگوی سالم وجود دارد:
اول اینکه محتوای اصلی و سیگنالهای متادیتا را تا حد ممکن با SSR یا SSG تولید کنید. وقتی کاربر وارد صفحه میشود، hydration میتواند تجربه اپ مانند را بسازد، اما گوگل از همان HTML اولیه هم تصویر نسبتاً کاملی داشته باشد.
دوم اینکه اگر مجبورید بخشی از محتوا را با API بگیرید، مطمئن شوید نسخه رندرشده برای گوگل هم قابل دریافت است و مسیرهای شکست مثل تایماوت، خطای API یا بلاک شدن منابع باعث نمیشود صفحه خالی رندر گردد.
سوم اینکه برای مدیریت رندر سمت گوگل، سراغ راهکارهایی بروید که خود گوگل به عنوان گزینههای بهتر معرفی میکند: server-side rendering، static rendering و hydration. در مقابل، گوگل dynamic rendering را بیشتر یک راهحل موقت میداند و آن را به عنوان راهحل بلند مدت توصیه نمیکند؛ چون معمولاً پیچیدگی فنی و هزینه عملیاتی بیشتری به پروژه تحمیل مینماید.

در سایتهای جاوا اسکریپتی، اختلاف بین «HTML خام» و «HTML رندرشده» ریشه خیلی از مشکلات است. بنابراین دیباگ هم باید این دو را جداگانه بررسی کند.
چند قدم عملی که معمولاً سریع جواب میدهد:
HTML اولیه را دقیق ببینید: آیا noindex یا canonical یا robots در همان پاسخ اولیه هست؟ آیا هدر X-Robots-Tag دارید؟ آیا وضعیت HTTP درست است؟
در Search Console از URL Inspection استفاده نمایید و بخش rendered HTML را با raw HTML مقایسه کنید.
لاگهای سرور را بررسی نمایید تا مطمئن شوید Googlebot واقعاً به URLها دسترسی دارد و با 403 یا ریدایرکتهای عجیب مواجه نمیشود.
اگر شما تصمیمهای ایندکس را شرطی کردهاید، حتماً بررسی کنید گوگل کدام نسخه را دریافت میکند؛ مخصوصاً در حالتهای geo، زبان، موبایل یا AB تست.
در عمل، وقتی صفحهای «نباید noindex باشد» ولی است، خیلی وقتها پاسخ اولیه سرور مقصر میباشد؛ نه JS. و دقیقاً این همان چیزی است که این بروزرسانی میخواهد جلویش را بگیرد.
بعضی اشتباهها تا وقتی سایت کوچک است شاید فاجعه نسازد، اما در مقیاس بزرگ دقیقاً تبدیل به افت ایندکس و افت ترافیک میشود.
اشتباه اول این است که محیط استیجینگ یا نسخههای تست را با noindex در HTML اولیه میبندید، بعد در زمان انتشار به پروداکشن (Production)، یک سری مسیرها یا تمپلیتها همان noindex را حفظ میکنند و تیم امیدوار است «بعداً با JS درست میشود». این دقیقاً همان نقطه خطر میباشد.
اشتباه دوم، ساختن صفحات با 200 و محتوای خالی است و بعد پر کردن محتوا با JS، در حالی که رندر سمت گوگل ممکن است دیر یا ناقص انجام شود. اگر محتوای اصلی ارزش سئو دارد، بهتر است از SSR یا SSG استفاده کنید یا حداقل یک نسخه اولیه معنادار در HTML بگذارید.
اشتباه سوم این است که canonical را یکدست نگه نمیدارید: گاهی یک نسخه در HTML اولیه دارید، نسخه دیگری را با JS اضافه میکنید یا بعد از لود مقدار canonical را عوض مینمایید. از نظر گوگل، چند canonical همزمان میتواند باعث رفتارهای غیرمنتظره شود.
اشتباه چهارم، قاطی کردن robots.txt با noindex است. اگر robots.txt را طوری بستهاید که گوگل نتواند صفحه را بخزد، انتظار نداشته باشید noindex اثر کند؛ چون گوگل آن را نمیبیند.
این بروزرسانی یک هشدار نرم اما کاملاً فنی است: Googlebot همیشه مجبور نیست رندر کند و وقتی در HTML اولیه با سیگنالهایی مثل noindex مواجه شود، ممکن است حتی رندر و اجرای جاوا اسکریپت را انجام ندهد. بنابراین حذف یا تغییر noindex با JavaScript یک استراتژی قابل اتکاء برای مدیریت ایندکس نیست.
اگر قرار است صفحه ایندکس گردد، از همان ابتدا باید «قابل ایندکس» به گوگل معرفی شود. اگر قرار نیست ایندکس شود، تصمیم را قطعی، استاندارد و سرورمحور کنید، با meta robots یا X-Robots-Tag و اگر وضعیت ایندکس شرطی است، منطق تصمیمگیری را به سطح پاسخ HTTP بیاورید، جایی که گوگل آن را بدون نیاز به اجرای JS میبیند.
تهیه شده توسط تیم تخصصی سئو سید احسان خسروی (مدیر، متخصص و مشاور استراتژیک سئو)