مدلهای زبانی بزرگ (Large Language Model یا LLM) در اخیرا پیشرفتهای عجیبی داشتهاند و نقشی حیاتی در تحولات تکنولوژی ایفا کردهاند. در این نوشته به مرور تاریخی، کاربردهای کلیدی و ایدههای پشت مدلهای LLM، بهویژه خانواده GPT (Generative Pre-trained Transformer) میپردازیم.

اولین تلاش انسان برای ساخت یک مدل زبانی به دههی 1950 باز میگردد. از همان سالها، مهندسان و دانشمندان با روشهای بیسیک مانند N-grams و روشهای آماری سعی میکردند با داشتن یک توالی از کلمات ادامهی آن را پیشبینی کنند. درست است که این روشها در برابر روشهای امروزی کارآمد به نظر نمیرسند، ولی به عنوان اولین قدم بشریت، قدمهای محکمی بودند که پایهای برای توسعهی مدلهای پیچیدهتر شدند.
با از راه رسیدن روشهای یادگیری عمیق (Deep Learning)، شبکههای عصبی توانستند جایگزین مدلهای آماری سنتی شوند. مدلهایی مانند Word2Vec (2013) و GloVe (2014) مفهوم نمایش برداری کلمات (Word Embeddings) را معرفی کردند، که امکان فهم معنایی عمیقتر از زبان را فراهم کرد.
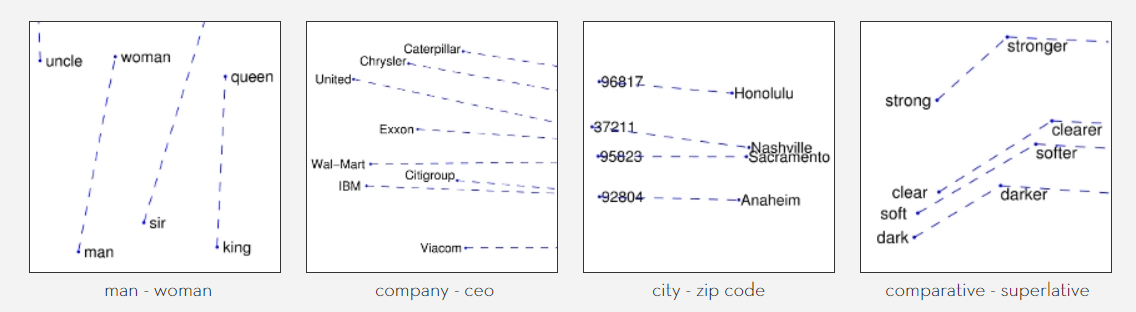
بردارهای کلمات (Word Embeddings) مفاهیم جالبی هستند که در فضاهایی با ابعاد بالا کلمات را تبدیل به بردار میکنند. قسمت جالب این پروسه، این است که مفاهیم و ارتباط کلمات را میتوان با استفاده از جبر خطی از دل آنها استخراج کرد. اگر به موضاعتی مانند بردارهای کلمات یا ریاضیات جبر خطی علاقهمند هستید خوشحال میشم که مطلعم کنید تا به آنها هم بپردازم.
در سال 2017، مقاله معروف Attention is All You Need معماری ترنسفورمر (Transformer) را معرفی کرد. این معماری بر اساس مکانیزم توجه (Attention Mechanism) طراحی شده است که به مدل اجازه میدهد روی بخشهای مهم متن تمرکز کند و وابستگیهای طولانی مدت را بهتر درک کند. برخلاف مدلهای قبلی مانند RNN و LSTM که پردازش ترتیبی داشتند، ترنسفورمرها قابلیت پردازش موازی بالایی دارند. این ویژگیها باعث شدند که ترنسفورمرها در بسیاری از وظایف پردازش زبان طبیعی (NLP) مانند ترجمه ماشینی، خلاصهسازی و تولید متن عملکرد فوقالعادهای داشته باشند.
معماری ترنسفورمر از دو بخش اصلی تشکیل شده است: رمزگذار (Encoder) و رمزگشا (Decoder). رمزگذار وظیفه تحلیل ورودی و استخراج ویژگیها را بر عهده دارد، در حالی که رمزگشا از این ویژگیها برای تولید خروجی استفاده میکند. یکی از اجزای کلیدی در این معماری، Self-Attention Mechanism است که به هر کلمه اجازه میدهد با تمام کلمات دیگر در جمله ارتباط برقرار کند و اهمیت آنها را تعیین کند.
این نوآوریها ترنسفورمر را به استانداردی در معماریهای مدرن تبدیل کرد و زیربنای مدلهای بزرگی مانند BERT و GPT شد.
در ادامه OpenAI در سال 2018 اولین نسخه GPT را معرفی کرد. این مدل از پیشآموزش (Pre-training) روی مقادیر عظیمی از دادهها و تنظیم دقیق (Fine-tuning) برای وظایف خاص بهره میبرد. نسخههای بعدی (GPT-2، GPT-3 و GPT-4) توانستند تواناییهای بینظیری در تولید متن، ترجمه، کدنویسی و حتی خلاقیت نشان دهند. تا امروز که همهی ما از chat-GPT استفاده میکنیم.
پس از معرفی ترنسفورمر در ۲۰۱۷، رقابت جالبی بین شرکتهایی مانند گوگل (با BERT)، OpenAI (با GPT)، و DeepMind (با Chinchilla) شکل گرفت. معرفی APIهای دسترسیپذیر مانند Chat-GPT در ۲۰۲۲، LLMها را از آزمایشگاهها به زندگی روزمره کاربران آورد. امروزه، تمرکز بر توسعهی مدلهای کارآمدتر (مانند LLaMA متا) و ادغام چند حسی (متن، تصویر، صوت) است.
ایدهی اصلی LLM ترکیبی از یادگیری عمیق پیشرفته، مقیاسپذیری بیسابقه، و پردازش معنایی مبتنی بر الگوهای پیچیده است. در قلب این مدلها، مفاهیم زیر نهفتهاند:
همانطور که قبلتر هم اشاره شد، ترنسفورمرها با استفاده از Self-Attention Mechanism، توانایی تحلیل روابط بین کلمات را بدون محدودیت فاصلهی زمانی (برخلاف RNNها) فراهم میکنند. این مکانیزم به مدل اجازه میدهد تا:
این معماری با لایههای چندسر (Multi-Head Attention) ترکیب میشود تا مدل بتواند همزمان از چندین "دیدگاه" متفاوت به متن نگاه کند.
مدلهای LLM در مرحلهی پیشآموزش از یک روش هوشمندانه استفاده میکنند:
یکی از اکتشافات کلیدی در توسعهی LLM، تأثیر نمایی افزایش اندازهی مدل و داده بر عملکرد است.
این مقیاسپذیری منجر به ظهور تواناییهای ناگهانی (Emergent Abilities) مانند استدلال ریاضی یا پاسخ به سؤالات فلسفی شد که در مدلهای کوچکتر دیده نمیشد.
پس از پیشآموزش، LLM از دو روش برای بهبود رفتارشان استفاده میکنند:

مدلهای زبانی بزرگ همچنان در حال پیشرفت هستند و آیندهشان به نظر روشن میآید. احتمالا برنامهی آیندهی آنها در کاهش دادن هزینه، تمرکز بر خلاقتر بودن آنها و توسعهی مدلهایی با قابلیت استدلال و استنتاج (Reasoning) و توسعه مدلهای کارآمدتر خواهد بود.
از اتفاقات شیرینی که امیدواریم در آینده رخ بدهد افزایش قابلیت تعامل با آنهاست. اینکه با انواع مختلف مدیا مانند صحبت یا ویدیو بتوان با مدل ارتباط برقرار کرد. حتی در آیندهی دورتر ممکن است بشریت با این مدلها همکار شود.