در این مطلب میخواهیم کمی «جبر خطی» را نه به شکل خشک دانشگاهی، بلکه مثل جعبهابزار ذهنیای ببینیم که پشت صحنهی هوش مصنوعی و شبکههای عصبی کار میکند. سعی میکنم هر مفهوم را با مثال ساده و شهودی توضیح بدهم.
۱. بردار (Vector): فلشهای چندبعدی
بردار را میتوانید مثل یک «فلش» در فضا تصور کنید.
- تعریف ساده:
بردار یعنی یک لیست از عددها:
v = [3, 4] # یعنی از مبدأ (۰،۰) ۳ واحد به راست، ۴ واحد به بالا حرکت میکنیم.
برداشت شهودی:
هر بردار یک «نقطه» در فضا هم هست.
۲. اندازه (Magnitude): طول بردار
اندازه یا طول بردار، فاصلهی آن نقطه از مبدأ است.
v = [3, 4] # |v| = 5
۳. ماتریس (Matrix): جدولِ تبدیلها
ماتریس را میتوانید مثل یک «تابع خطی» یا «ماشین تبدیل» برای بردارها ببینید.
کار اصلی:
بردارها را از یک فضا به فضای دیگر نگاشت (تبدیل) میکند. مثلا:
y = A x # map vector x into another space by using matrix A
ماتریس A بردارها را در جهت x دو برابر میکند، ولی جهت y را دستنخورده میگذارد.

۴. ضرب داخلی (Dot Product): سنجش شباهت
ضرب داخلی بین دو بردار، ترکیبی از «طولها» و «زاویه بین آنها» است و معمولا برای سنجش شباهت استفاده میشود.
برداشت شهودی
- اگر زاویه بین دو بردار کم باشد (تقریباً همجهت باشند)، ضرب داخلی بزرگ و مثبت است ⇒ مشابه هستند.
- اگر عمود باشند ⇒ ضرب داخلی صفر است ⇒ مستقل/بیربط.
- اگر در جهت مخالف باشند ⇒ منفی میشود.

۵. امبدینگ (Embedding): معنیِ فشرده در قالب یک بردار
امبدینگ، یک بردار است که «معنی» چیزی را در خودش فشرده کرده:
کلمه، تصویر، کاربر، محصول و…
- مثال:
یک کلمه مثل «گربه» را میتوان به یک بردار ۳۰۰ بعدی تبدیل کرد:
embedding("cat")=[0.12,−0.87,0.03,…]
در این فضا:
- بردار «dog» نزدیک به «cat» است، چون معناشان مشابه است.
- بردار «car» از آنها دور است.
ضرب داخلی و فاصلهی بین امبدینگها در این فضا، مقدار «شباهت معنایی» را به ما میدهد.
۶. رتبه (Rank): میزان اطلاعات مستقل در ماتریس
رتبهی یک ماتریس، تعداد ستونها (یا سطرهای) «خطی مستقل» آن است.
ستونهای خطی مستقل یعنی هیچ ستونی را نمیتوان با ترکیب خطی بقیه ساخت.
- اگر:
رتبه = تعداد ستونها ⇒ تمام ستونها اطلاعات جدید دارند.
رتبه کم ⇒ برخی ستونها تکراری یا وابستهاند.
مثال:
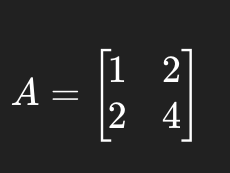
در ماتریس بالا ستون دوم دقیقا ۲ برابر ستون اول است. پس:
فقط یک ستون «اطلاعات منحصربهفرد» دارد.
رتبهی این ماتریس: ۱
(rank = 1 ⇒ فقط یک ستون واقعا اطلاعات جدید دارد.)
۷. دترمینان (Determinant): ضریب بزرگنمایی فضا
دترمینان یک ماتریس مربعی، یک عدد است که میزان «گسترش یا جمع شدن فضا» توسط آن ماتریس را نشان میدهد.
اگر:
(det(A)| > 1|) ⇒ ماتریس فضا را بزرگ میکند.
(det(A)| < 1|) ⇒ فضا را کوچک/فشرده میکند.
(det(A)|= 0|) ⇒ فضا را روی بعد پایینتری میخواباند (مثلا صفحه به خط)، و ماتریس «وارونپذیر» نیست.
مثال:
import numpy as np matrix = np.array([[2, 0], [0, 2]]) det = np.linalg.det(matrix) # نتیجه: 4
ماتریس فوق هر شکل دوبعدی را ۴ برابر بزرگتر میکند (مساحتها ×۴ میشوند).
۸. بردار ویژه و مقدار ویژه (Eigenvector & Eigenvalue)
بیشتر بردارها وقتی یک ماتریس به آنها اعمال میشود، هم «طول» و هم «جهت»شان عوض میشود.
اما بردارهای ویژه خاص هستند:
بردار ویژه (Eigenvector): برداری است که تحت عمل ماتریس، جهتش تغییر نمیکند، فقط طولش تغییر میکند.
مقدار ویژه (Eigenvalue): همان ضریب کشیدگی است.
استفاده در PCA (تحلیل مؤلفههای اصلی)
در PCA، هدف این است که دادهی در ابعاد بالا را به فضای کمبعدتر ببریم، بدون اینکه زیاد از «اطلاعات مهم» از دست بدهیم.
مراحل ساده:
1. ماتریس کوواریانس داده را میسازیم.
2. بردارهای ویژهی این ماتریس را حساب میکنیم ⇒ اینها همان مؤلفههای اصلی هستند.
3. مقدارهای ویژه میگویند هر مؤلفه چقدر از «واریانس» (پراکندگی/اطلاعات) را توضیح میدهد.
4. بردارهای ویژه را بر اساس مقدار ویژه مرتب میکنیم، و مثلا فقط «k تا از بزرگترینها» را نگه میداریم ⇒ کاهش بُعد.
به زبان ساده:
بهترین جهتها برای نگاهکردن به داده (با بیشترین اطلاعات) همان بردارهای ویژهی با مقدار ویژهی بزرگتر هستند.
۱۰. مشتق (Derivative): نرخ تغییر
مشتق، سرعت تغییر تابع را در یک نقطه اندازهگیری میکند.
- تعبیر هندسی: شیب خط مماس بر نمودار در آن نقطه.
مثال:
اگر تابع برابر f(x) = x^2 باشد مقدار مشتق تابع برابر f'(x) = 2x است. به این معنی که اگر در نقطه x= 2 مقدار x را یک مقدار خیلی کوچک تغییر کند، مقدار y حدوداً به اندازهی ۴ برابر آن تغییر کوچک افزایش پیدا میکند زیر مشتق در ان نقطه برابر ۴ است.
۱۱. گرادیان (Gradient): مشتق در ابعاد بالاتر
وقتی تابعی چند متغیر دارد، گرادیان آن تابع، یک بردار از مشتقهای جزئی است.
گرادیان جهت «بیشترین افزایش» تابع را نشان میدهد.
برای کمینه کردن تابع (مثلا خطا در شبکه عصبی)، باید در «جهت مخالف گرادیان» حرکت کنیم ⇒ گرادیان نزولی (Gradient Descent).
۱۲. ژاکوبین (Jacobian): ماتریس مشتقهای جزئی
وقتی تابعتان چند ورودی و چند خروجی دارد، ژاکوبین همان چیزی است که مشتق را به صورت ماتریس نشان میدهد.
به فارسی: ماتریس مشتقات جزئی مرتبه اول.
برداشت شهودی: شیب/حساسیت خروجیها نسبت به ورودیها در یک نقطه.
در شبکههای عصبی، ژاکوبین وزنها و خروجی لایهها را به هم ربط میدهد و در محاسبهی گرادیانها نقش دارد.
۱۳. هسین (Hessian): ماتریس انحنا
وقتی مشتق درجه دو بگیریم، به هسین میرسیم.
نقش: توصیف «انحنا» یا «شکل محلی» تابع:
اگر هسین مثبتمعین باشد ⇒ در آن نقطه یک مینیمم موضعی داریم.
اگر منفیمعین باشد ⇒ ماکسیمم موضعی.
اگر مخلوط باشد ⇒ نقطه زینی.
در بهینهسازی پیشرفته (مثل نیوتن روشها)، هسین کمک میکند سریعتر به مینیمم برسیم.
۱۴. قانون زنجیرهای (Chain Rule): قلب بکپراپ در شبکههای عصبی
وقتی تابعی به صورت ترکیب چند تابع نوشته شود، مشتق y نسبت به x با قانون زنجیرهای به دست میآید:
y=f(g(x))

قانون زنجیرهای میگوید:
برای پیدا کردن مشتق نهایی، باید مشتق هر لایه را در مشتق لایهی بعدی ضرب کنیم.
این دقیقا همان کاری است که Backpropagation انجام میدهد.
برای محاسبهی مشتقهای ترکیبی، دو راه اصلی داریم:
1. Forward Mode (از ورودی به خروجی):
از x شروع میکنیم، مشتقها را جلو جلو میبریم تا به y برسیم.
2. Reverse Mode (از خروجی به ورودی):
از y (خروجی) شروع میکنیم و مشتقها را به عقب، به سمت پارامترها برمیگردانیم.
در شبکههای عصبی معمولا به دلیل وجود تعداد پارامتر های زیاد از روش Reverse Mode استفاده می شود و تمام گرادیان ها در یک مرحله backward pass محاسبه می شوند.
با تشکر