همه ما میدانیم که داده، قلب علم داده است. اما آیا تا به حال فکر کردهاید که خود دادهها به چند دسته تقسیم میشوند؟
واقعیت این است که دادهها شکل و شمایل متفاوتی دارند.
بعضی از آنها مرتب و ردیفی هستند، مثل یک صفحه اکسل مرتب. بعضی دیگر کاملاً بیقاعده و آشفته به نظر میرسند، مثل یک ایمیل یا یک ویدیو.
در این مقاله، قرار است با این انواع داده و فرمتهای معروف آنها آشنا شویم.
اولین و مهمترین تقسیمبندی که هر دانشمند داده باید بلد باشد، تفاوت بین دادههای ساختاریافته و غیرساختاریافته است.
بیایید با هم این دو را بررسی کنیم.
به زبان ساده، داده ساختاریافته یعنی دادهای که در قالب جدول، با سطر و ستون مشخص، سازماندهی شده است.
مثل یک فایل اکسل را تصور کنید. ستون اول اسم، ستون دوم سن، ستون سوم شهر. هر سطر هم مربوط به یک شخص.
این نوع داده بسیار خوشرفتار است. کامپیوترها به راحتی میتوانند آن را بخوانند، جستجو کنند و روی آن محاسبه انجام دهند.
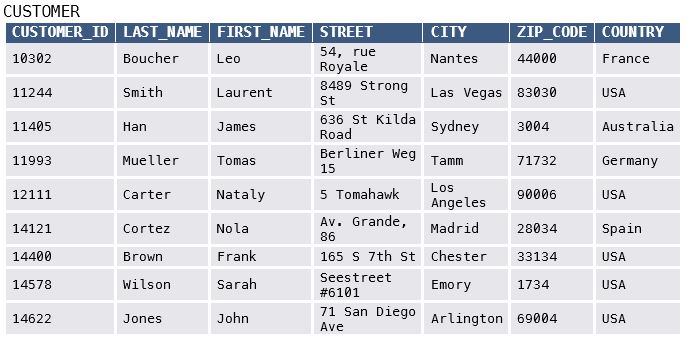
مثالهای معروف داده ساختاریافته کدامند؟
لیست مشتریان یک فروشگاه، جدول نمرات دانشآموزان، اطلاعات محصولات در یک فروشگاه آنلاین.
حدس بزنید چند درصد دادههای جهان از این نوع هستند؟ فقط حدود ۲۰ درصد.
بله، درست خواندید. فقط ۲۰ درصد دادههای دنیا ساختاریافته هستند. جالب میشود، نه؟
حالا برسیم به قطب مخالف. داده غیرساختاریافته یعنی دادهای که ساختار جدولی و منظمی ندارد.
این دادهها حجیمتر، پیچیدهتر و البته بسیار رایجتر هستند.
حدود ۸۰ درصد دادههای جهان غیرساختاریافته هستند. تصور کنید! این یعنی چهار پنجم دنیای داده، بیقاعده و نامرتب به نظر میرسد.
مثال بزنیم تا واضح شود.
متن یک کتاب، یک ایمیل طولانی، پست اینستاگرامی شما، یک فایل صوتی از یک پادکست، یک ویدیو در یوتیوب، یا یک عکس از صورت خودتان.
هیچکدام از اینها در قالب جدول و سطر و ستون قرار نمیگیرند. در عین حال، ارزش اطلاعاتی فوقالعادهای دارند.
کار علم داده همین جاست: چگونه از این دادههای بیقاعده، دانش و بینش استخراج کنیم؟
بین این دو دنیا، یک حالت میانی هم وجود دارد. به آن داده نیمهساختاریافته میگویند.
این دادهها کاملاً بیقاعده نیستند، اما مثل جدول هم مرتب نیستند. آنها از برچسبها (tags) یا کلیدها برای سازماندهی استفاده میکنند.
جالب است بدانید که معروفترین فرمتهایی که در ادامه معرفی میکنیم، دقیقاً در همین دسته قرار میگیرند.
حالا که با انواع داده از نظر ساختار آشنا شدیم، وقت آن است که با رايجترین فرمتهای فایل در علم داده آشنا شویم.
این فرمتها تعیین میکنند که داده چگونه ذخیره، منتقل و پردازش شود.

سادهترین و قدیمیترین قهرمان دنیای داده، CSV است. مخفف Comma-Separated Values یعنی مقادیری که با کاما از هم جدا شدهاند.
یک فایل CSV را مثل یک صفحه اکسل ساده در نظر بگیرید. سطر اول معمولاً نام ستونهاست. سطرهای بعدی هم دادهها هستند. هر خانه با یک کاما از خانه بعدی جدا میشود.
مزیت بزرگ CSV چیست؟ سادگی فوقالعاده آن. هر نرمافزاری از اکسل گرفته تا پایتون، میتواند CSV را باز کند.
عیب آن هم این است که فقط دادههای ساده و مسطح را میتواند ذخیره کند. نمیتواند روابط پیچیده و تو در تو را نشان دهد.
اگر با دادههای ساختاریافته سروکار دارید، CSV اولین گزینه شماست.
JSON یک اسم آشنا برای کسانی است که با وب کار کردهاند. مخفف JavaScript Object Notation است.
برخلاف CSV که صاف و مسطح است، JSON میتواند دادههای تو در تو و سلسلهمراتبی را ذخیره کند.
تصور کنید میخواهید اطلاعات یک کتاب را ذخیره کنید. کتاب یک نویسنده دارد، چندین فصل، هر فصل چند زیربخش. JSON به راحتی این ساختار را حفظ میکند.
امروزه تقریباً تمام APIهای معروف (مثلاً API توییتر یا اینستاگرام) خروجی خود را با فرمت JSON ارائه میدهند.
فرمت JSON برای دادههای نیمهساختاریافته و وب، بیرقابت است.
XML را میتوان پدربزرگ JSON در نظر گرفت. مخفف eXtensible Markup Language.
XML هم مثل JSON میتواند دادههای تو در تو را ذخیره کند، اما با ظاهری کمی متفاوت. XML از برچسبهای باز و بسته شونده استفاده میکند، شبیه به HTML که دیدهاید.
مهمترین تفاوت XML با JSON این است که XML کمی قدیمیتر و سنگینتر است. یعنی فایل XML معمولاً حجم بیشتری نسبت به JSON برای همان داده اشغال میکند.
با این حال، XML هنوز هم در صنایعی مثل بانکداری، سیستمهای قدیمی بیمارستانی و فرمتهای آفیس (مثل فایلهای docx) بسیار رایج است.
اگر با سیستمهای قدیمی و سازمانی سروکار دارید، احتمالاً با XML روبرو خواهید شد.

بیایید یک جمعبندی سریع و ساده داشته باشیم.
اگر داده شما کاملاً جدولی و مرتب است و خبری از پیچیدگی نیست، سراغ CSV بروید. ساده و همهگیر.
اگر با APIهای وب کار میکنید یا داده شما ساختار تو در تو و سلسلهمراتبی دارد، JSON انتخاب اول شماست.
اگر در یک سازمان بزرگ و قدیمی کار میکنید و با سیستمهای شرکتی سروکار دارید، XML را هم باید بشناسید.