ترجمه کتاب ساخت برنامههای کاربردی با مدلهای پایه - انتشارات O’Reilly
BOOK: O'Reilly_AI_Engineering_Building_Applications_with_Foundation_Models
اگرچه مدلهای زبانی قادر به انجام کارهای باورنکردنی هستند، اما به متن (text) محدود شدهاند. به عنوان انسان، ما جهان را نه تنها از طریق زبان، بلکه از طریق بینایی، شنوایی، لامسه و موارد بیشتر درک میکنیم. توانایی پردازش دادههای فراتر از متن برای هوش مصنوعی ضروری است تا در دنیای واقعی عمل کند.
به همین دلیل، مدلهای زبانی در حال گسترش هستند تا روش های داده ای بیشتری را ترکیب کنند. GPT-4V و Claude 3 میتوانند تصاویر و متون را درک کنند. برخی مدلها حتی ویدیوها، assets سهبعدی، ساختارهای پروتئینی و غیره را درک میکنند. ترکیب روش های داده ایِ بیشتر به مدلهای زبانی، آنها را حتی قدرتمندتر میسازد.
در حالی که بسیاری از مردم هنوز Gemini و GPT-4V را LLM مینامند، بهتر است آنها را به عنوان مدلهای پایه (Foundation Models) توصیف کنیم. کلمه «پایه» هم اهمیت این مدلها در برنامههای کاربردی هوش مصنوعی و هم این واقعیت که میتوانند برای نیازهای مختلف بنا شوند را نشان میدهد.
مدلهای پایه، یک جهش از ساختار سنتی تحقیقات هوش مصنوعی را نشان میدهند. برای مدت طولانی، تحقیقات هوش مصنوعی بر اساس modalities داده تقسیمبندی شده بود. پردازش زبان طبیعی (Natural language Processing ) (NLP) فقط با متن سر و کار داشت. بینایی کامپیوتر فقط با vision سر و کار داشت. مدلهای مبتنی بر متن (Text-only models) میتوانند برای وظایفی مانند ترجمه و تشخیص هرزنامه (spam detection) استفاده شوند. مدلهای مبتنی بر تصویر (Image-only models) میتوانند برای تشخیص اشیاء (object detection) و طبقهبندی تصاویر (image classification) به کار روند. مدلهای مبتنی بر صوت (Audio-only models) میتوانند وظایفی مانند تشخیص گفتار (speech-to-text یا STT) و سنتز گفتار (text-to-speech یا TTS) را انجام دهند.
مدلی که بتواند با بیش از یک modality داده کار کند، یک مدل چندوجهی (multimodal) نیز نامیده میشود. یک مدل چندوجهی تولیدی، مدل بزرگ چندوجهی (Large Multimodal Model - LMM) نیز نامیده میشود. اگر یک مدل زبانی، توکن بعدی را با شرط شدن (conditioned on) روی توکنهای متنی تولید میکند، یک مدل چندوجهی (multimodal model) توکن بعدی را با شرط شدن روی هر دوی توکنهای متنی و تصویری، یا هر modality دیگری که مدل پشتیبانی میکند، تولید مینماید؛ همانطور که در شکل ۱-۳ نشان داده شده است.

درست مانند مدلهای زبانی، مدلهای چندوجهی نیز برای مقیاسپذیری به داده نیاز دارند. خود-نظارتی برای مدلهای چندوجهی نیز کاربرد دارد. برای مثال، اوپنایآی از گونهای از خود-نظارتی به نام نظارت زبان طبیعی (natural language supervision) برای آموزش مدل زبان-تصویر خود به نام CLIP (اوپنایآی، ۲۰۲۱) استفاده کرد. به جای تولید دستی برچسب برای هر تصویر، آنها جفتهای (تصویر، متن)ی را پیدا کردند که به طور همزمان در اینترنت ظاهر میشدند. آنها توانستند یک مجموعه داده متشکل از ۴۰۰ میلیون جفت (تصویر، متن) تولید کنند که ۴۰۰ برابر بزرگتر از ImageNet بود، بدون هزینه برچسبزنی دستی. این مجموعه داده به CLIP اجازه داد تا به اولین مدلی تبدیل شود که میتوانست بدون نیاز به آموزش اضافی، به چندین کار طبقهبندی تصویر تعمیم یابد.
این کتاب از اصطلاح مدلهای پایه (foundation models) برای اشاره به هر دو نوع مدلهای زبانی بزرگ و مدلهای چندوجهی بزرگ استفاده میکند.
توجه داشته باشید که CLIP یک مدل مولد (generative) نیست — آموزش ندیده بود تا خروجیهای باز تولید کند. CLIP یک مدل embedding است که آموزش دیده تا embeddingهای مشترک (joint embeddings) هم برای متون و هم برای تصاویر تولید کند. بخش “مقدمهای بر Embedding” در ادامه کتاب در مورد embeddingها بحث میکند. برای حالا، میتوانید embeddingها را به عنوان بردارهایی در نظر بگیرید که هدف آنها ثبت معنای دادههای اصلی است. مدلهای embedding چندوجهی مانند CLIP، ستون فقرات مدلهای مولد چندوجهی، مانند Flamingo، LLaVA و Gemini (پیشتر با نام Bard) هستند.
مدلهای پایه همچنین نشاندهنده گذار از مدلهای ویژه-وظیفه به مدلهای همهمنظوره هستند. پیش از این، مدلها اغلب برای وظایف خاصی مانند تحلیل احساسات یا ترجمه توسعه مییافتند. یک مدل آموزشدیده برای تحلیل احساسات نمیتوانست ترجمه انجام دهد و بالعکس.
مدلهای پایه، به لطف مقیاس و روش آموزششان، قادر به انجام طیف گستردهای از وظایف هستند. مدلهای همهمنظوره به صورت out-of-the-box (بدون تنظیم خاص) میتوانند برای بسیاری از وظایف نسبتاً خوب عمل کنند. یک مدل زبانی بزرگ (LLM) میتواند هم تحلیل احساسات انجام دهد و هم ترجمه. با این حال، اغلب میتوانید یک مدل همهمنظوره را برای حداکثر کردن عملکردش در یک وظیفه خاص تنظیم (task) کنید.
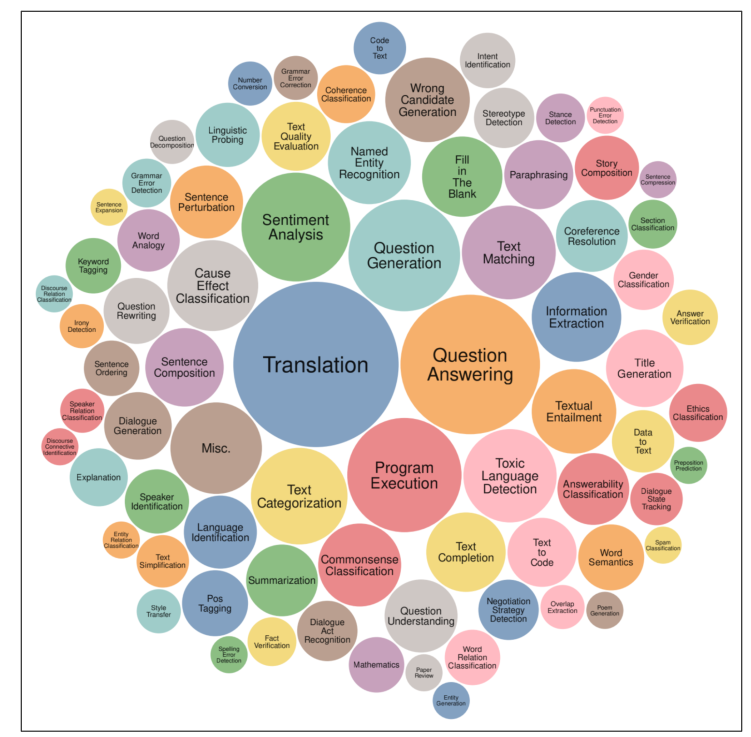
شکل ۱-۴ وظایفی را نشان میدهد که توسط معیار سنجش Super-NaturalInstructions برای ارزیابی مدلهای پایه استفاده شده (Wang و همکاران، ۲۰۲۲)، که ایدهای از انواع وظایفی که یک مدل پایه میتواند انجام دهد ارائه میکند.
تصور کنید که شما با یک خردهفروشی کار میکنید تا یک برنامه برای تولید توضیحات محصول برای وبسایت آنها بسازید. یک مدل out-of-the-box ممکن است بتواند توضیحات دقیقی تولید کند، اما ممکن است در ثبت لحن برند یا برجسته کردن پیامرسانی برند شکست بخورد. توضیحات تولیدشده حتی ممکن است پر از سخنان بازاریابی و کلیشهها باشد.
تکنیکهای متعددی وجود دارد که میتوانید استفاده کنید تا مدل را وادار به تولید خروجی مورد نظرتان کنید. برای مثال، میتوانید دستورالعملهای دقیقی همراه با مثالهایی از توضیحات محصول مطلوب بسازید. این رویکرد، مهندسی پیشنگاشت (Prompt Engineering) است. میتوانید مدل را به یک پایگاه داده از نظرات مشتریان متصل کنید که مدل بتواند از آن برای تولید توضیحات بهتر بهرهبرداری کند. استفاده از یک پایگاه داده برای تکمیل دستورالعملها، تولید تقویتشده با بازیابی (Retrieval-Augmented Generation یا RAG) نامیده میشود. همچنین میتوانید مدل را روی یک مجموعهداده از توضیحات محصول باکیفیت، بیشتر آموزش دهید (Further Train) یا به اصطلاح (Fine-Tuning) کنید.
مهندسی پیشنگاشت (Prompt Engineering)، RAG و فاین-تیونینگ (Fine-Tuning) سه تکنیک بسیار رایج در مهندسی هوش مصنوعی هستند که میتوانید برای تطبیق یک مدل با نیازهای خود از آنها استفاده کنید. بقیه کتاب به طور مفصل در مورد همه آنها بحث خواهد کرد.
تطبیق یک مدل قدرتمند موجود با وظیفه شما، عموماً بسیار آسانتر از ساختن یک مدل برای وظیفه از ابتدا است — برای مثال، مقایسه ده مثال و یک آخر هفته در مقابل ۱ میلیون مثال و شش ماه. مدلهای پایه، توسعه برنامههای کاربردی هوش مصنوعی را ارزانتر کرده و زمان عرضه به بازار (Time to Market) را کاهش میدهند. دقیقاً چه مقدار داده برای تطبیق یک مدل مورد نیاز است، به این بستگی دارد که از کدام تکنیک استفاده میکنید. این کتاب در هنگام هر تکنیک به این سوال نیز خواهد پرداخت. با این حال، مدلهای (task-specific) هنوز مزایای زیادی دارند، برای مثال، ممکن است بسیار کوچکتر باشند که باعث میشود استفاده از آنها سریعتر و ارزانتر تمام شود.
اینکه مدل خود را بسازید یا از مدل موجود بهرهبرداری کنید، یک سوال کلاسیک “خرید در مقابل ساخت” (Buy-or-Build) است که تیمها باید خود به آن پاسخ دهند. بحثهای سراسر این کتاب میتواند در اتخاذ این تصمیم کمک کند.