کتاب: BOOK: O'Reilly_AI_Engineering_Building_Applications_with_Foundation_Models
این بخش 4 از فصل1 شامل 3 قسمت است:
1.سه لایه پشته هوش مصنوعی (Three Layers of the AI Stack)
2.مهندسی هوش مصنوعی در مقابل مهندسی یادگیری ماشین (AI Engineering Versus ML Engineering)
3.مهندسی هوش مصنوعی در مقابل مهندسی فولاستک (AI Engineering Versus Full-Stack Engineering)
رشد سریع مهندسی هوش مصنوعی همچنین باعث ایجاد مقدار باورنکردنی هیاهو (hype) و ترس از عقب ماندن (FOMO - Fear Of Missing Out) شده است. تعداد ابزارها، تکنیکها، مدلها و برنامههای جدیدی که هر روز معرفی میشوند میتواند طاقتفرسا باشد. به جای تلاش برای همگام شدن با این شنهای دائماً در حال تغییر، بیایید به بلوکهای ساختمانی (building blocks) اساسی مهندسی هوش مصنوعی نگاه کنیم.
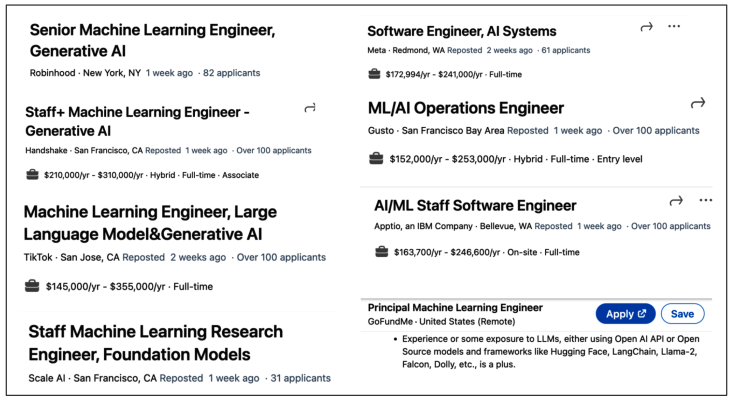
برای درک مهندسی هوش مصنوعی، مهم است بدانیم که مهندسی هوش مصنوعی از مهندسی یادگیری ماشین (ML Engineering) تکامل یافته است. وقتی یک شرکت شروع به آزمایش با مدلهای پایه میکند، طبیعی است که تیم ML موجودش باید این کار را رهبری کند. برخی شرکتها مهندسی هوش مصنوعی را همانند مهندسی یادگیری ماشین در نظر میگیرند، همانطور که در شکل ۱-۱۲ نشان داده شده است.
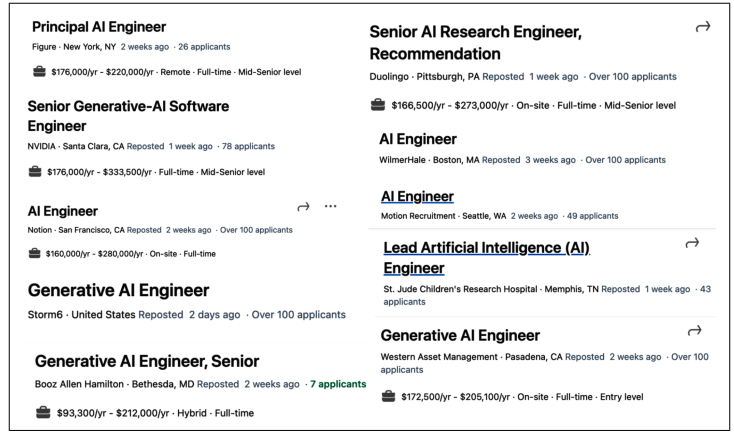
برخی شرکتها شرح شغل جداگانهای برای مهندسی هوش مصنوعی دارند، همانطور که در شکل ۱-۱۳ نشان داده شده است.
صرفنظر از اینکه سازمانها مهندسان هوش مصنوعی و مهندسان ML را در کدام موقعیت قرار میدهند، نقشهای آنها همپوشانی قابل توجهی دارند. مهندسان ML موجود میتوانند مهندسی هوش مصنوعی را به فهرست مهارتهای خود اضافه کنند تا چشمانداز شغلی خود را گسترش دهند. با این حال، مهندسان هوش مصنوعیای نیز هستند که هیچ تجربه قبلی ML ندارند.
برای درک بهتر مهندسی هوش مصنوعی و تفاوت آن با مهندسی ML سنتی، بخش بعدی لایههای مختلف فرآیند ساخت برنامه هوش مصنوعی را تجزیه میکند و به نقش هر لایه در مهندسی هوش مصنوعی و مهندسی ML نگاه میکند.
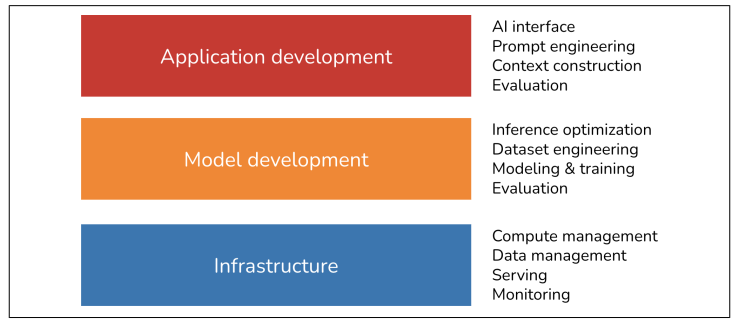
هر پشته برنامه کاربردی هوش مصنوعی دارای سه لایه است: توسعه برنامه، توسعه مدل و زیرساخت. هنگام توسعه یک برنامه هوش مصنوعی، احتمالاً از لایه بالا شروع میکنید و در صورت نیاز به سمت پایین حرکت میکنید:
۱. توسعه برنامه (Application Development) با در دسترس بودن آسان مدلها، هر کسی میتواند از آنها برای توسعه برنامهها استفاده کند. این لایه است که در دو سال گذشته بیشترین فعالیت را به خود دیده و همچنان به سرعت در حال تکامل است. توسعه برنامه شامل فراهم کردن پرامپتهای خوب و زمینه (Context)های لازم برای یک مدل است. این لایه نیازمند ارزیابی دقیق است. برنامههای خوب همچنین مستلزم رابطهای کاربری (Interfaces) خوب هستند.
۲. توسعه مدل (Model Development) این لایه ابزارهایی برای توسعه مدلها فراهم میکند، از جمله چارچوبهایی برای مدلسازی (modeling)، آموزش (training)، ریزتنظیمی (finetuning) و بهینهسازی استنتاج (inference optimization). از آنجایی که داده برای توسعه مدل مرکزی است، این لایه همچنین شامل مهندسی مجموعه داده (dataset engineering) میشود. توسعه مدل نیز نیازمند ارزیابی دقیق است.
۳. زیرساخت (Infrastructure) در پایین پشته زیرساخت قرار دارد که شامل ابزارهایی برای سرویسدهی مدل (model serving)، مدیریت داده و محاسبات و نظارت و مانیتورینگ (monitoring) است.
این سه لایه و مثالهایی از مسئولیتهای هر لایه در شکل ۱-۱۴ نشان داده شده است.
برای اینکه درکی از چگونگی تکامل این چشمانداز با ظهور مدلهای پایه داشته باشیم، در مارس ۲۰۲۴، من گیتهاب را برای تمام ریپوزیتوریهای مرتبط با هوش مصنوعی با حداقل ۵۰۰ ستاره جستجو کردم. با توجه به فراگیر بودن گیتهاب، معتقدم این دادهها شاخص خوبی (proxy) برای درک اکوسیستم هستند. در تحلیل خود، همچنین رپوزیتوریهای برنامهها (applications) و مدلها (models) را نیز گنجاندم، که به ترتیب محصولات لایههای توسعه برنامه و توسعه مدل هستند. در مجموع ۹۲۰ رپوزیتوری یافتم. شکل ۱-۱۵ تعداد تجمعی (cumulative) رپوزیتوریها در هر دسته را به صورت ماهانه نشان میدهد.
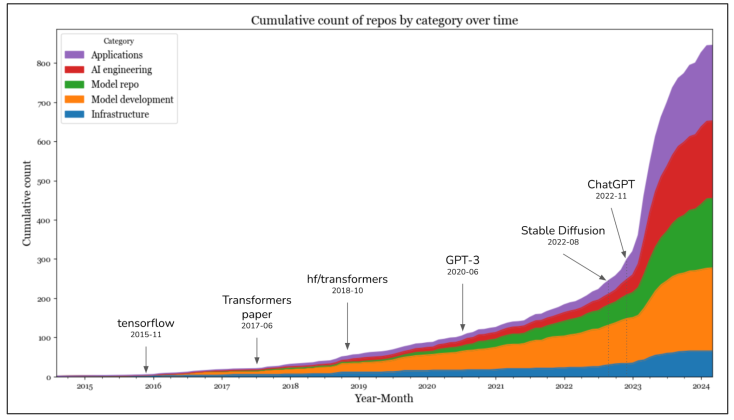
دادهها نشاندهنده افزایش چشمگیر در تعداد ابزارهای هوش مصنوعی در سال ۲۰۲۳، پس از معرفی Stable Diffusion و ChatGPT است. در سال ۲۰۲۳، دستههایی که بیشترین افزایش را داشتند، برنامهها و توسعه برنامه بودند. لایه زیرساخت مقداری رشد داشت، اما بسیار کمتر از رشد دیده شده در سایر لایهها بود. این مورد انتظار است. زیرا حتی با تغییر مدلها و برنامهها، نیازهای زیرساختی اصلی—مدیریت منابع، سرویسدهی، نظارت و غیره—یکسان باقی مانده است.
این ما را به نکته بعدی میرساند. در حالی که سطح هیجان و خلاقیت حول مدلهای پایه بیسابقه است، بسیاری از اصولِ ساخت برنامههای هوش مصنوعی همچنان یکسان مانده است. برای موارد استفاده سازمانی، برنامههای هوش مصنوعی هنوز هم نیاز دارند تا مشکلات کسبوکار را حل کنند، و بنابراین، همچنان ضروری است که از معیارهای کسبوکار به معیارهای ML نگاشت (map) کنیم و برعکس. شما هنوز هم نیاز به آزمایش منظم (systematic experimentation) دارید. با مهندسی ML کلاسیک، شما روی پارامترهای مختلف (hyperparameters) آزمایش میکنید. با مدلهای پایه، روی مدلهای مختلف، پرامپتها، الگوریتمهای بازیابی (retrieval algorithms)، متغیرهای نمونهبرداری (sampling variables) و موارد بیشتر آزمایش میکنید. (متغیرهای نمونهبرداری در فصل ۲ بحث میشوند.) ما هنوز هم میخواهیم مدلها را سریعتر و ارزانتر اجرا کنیم. همچنان مهم است که یک حلقه بازخورد (feedback loop) برقرار کنیم تا بتوانیم برنامههای خود را با دادههای عملیاتی (production data) به صورت تکراری بهبود بخشیم.
این به این معنی است که بسیاری از چیزهایی که مهندسان ML در طول دهه گذشته آموخته و به اشتراک گذاشتهاند، همچنان کاربردی است. این تجربه جمعی، شروع ساخت برنامههای هوش مصنوعی را برای همه آسانتر میکند. با این حال، در بالای این اصول پایدار، نوآوریهای متعددی منحصر به مهندسی هوش مصنوعی وجود دارد که در این کتاب به بررسی آنها خواهیم پرداخت.
هرچند اصول ثابت و تغییرناپذیر استقرار (deploying) برنامههای هوش مصنوعی اطمینانبخش است، اما درک اینکه چگونه شرایط تغییر کرده نیز بسیار مهم است. این موضوع برای تیمهایی که میخواهند پلتفرمهای موجود خود را برای موارد استفاده جدید هوش مصنوعی (new AI use cases) تطبیق دهند، و همچنین برای توسعهدهندگانی که علاقهمندند بدانند برای رقابتی ماندن در یک بازار جدید باید کدام مهارتها را بیاموزند، مفید است.
در سطح بالا، ساخت برنامهها با استفاده از مدلهای پایه امروزی در سه راه اصلی با مهندسی ML سنتی تفاوت دارد:
تمرکز بر انطباق مدل به جای آموزش از صفر:
بدون مدلهای پایه، شما باید مدلهای خود را برای برنامههای کاربردیتان آموزش دهید. با مهندسی هوش مصنوعی، شما از مدلی استفاده میکنید که شخص دیگری آن را برای شما آموزش داده است. این بدان معناست که مهندسی هوش مصنوعی کمتر بر مدلسازی و آموزش، و بیشتر بر انطباق مدل تمرکز دارد.
مدلهای بزرگتر و پرمصرفتر:
مهندسی هوش مصنوعی با مدلهایی کار میکند که بزرگتر هستند، منابع محاسباتی بیشتری مصرف میکنند و تأخیر بالاتری ایجاد میکنند نسبت به مهندسی ML سنتی. این به این معنی است که فشار بیشتری برای آموزش کارآمد و بهینهسازی استنتاج وجود دارد. یک نتیجهگیری از مدلهای پُرمصرف این است که بسیاری از شرکتها اکنون به GPUهای بیشتری نیاز دارند و با خوشههای محاسباتی بزرگتری نسبت به گذشته کار میکنند، که به معنای نیاز بیشتر به مهندسانی است که میدانند چگونه با GPUها و خوشههای بزرگ کار کنند.
خروجیهای باز (open-ended outputs) و چالش ارزیابی :
مهندسی هوش مصنوعی با مدلهایی کار میکند که میتوانند خروجیهای باز (Open-ended) تولید کنند. خروجیهای باز به مدلها انعطافپذیری میدهند تا برای کارهای بیشتری مورد استفاده قرار گیرند، اما ارزیابی آنها نیز سختتر است. این موضوع، ارزیابی را به یک مسئله بسیار بزرگتر در مهندسی هوش مصنوعی تبدیل میکند.
به طور خلاصه، تفاوت مهندسی هوش مصنوعی با مهندسی یادگیری ماشین در این است که کمتر به توسعه مدل میپردازد و بیشتر بر تطبیق و ارزیابی مدلها متمرکز است.
من در این فصل چندین بار به تطبیق مدل (model adaptation) اشاره کردهام، بنابراین قبل از ادامه، میخواهم اطمینان حاصل کنیم که در مورد معنای آن درک یکسانی داریم. به طور کلی، تکنیکهای تطبیق مدل را میتوان بسته به اینکه نیاز به بهروزرسانی وزنهای مدل دارند یا نه، به دو دسته تقسیم کرد:
تکنیکهای مبتنی بر پرامپت (Prompt-based techniques)، که شامل مهندسی پرامپت (Prompt Engineering) است، یک مدل را بدون بهروزرسانی وزنهای آن تطبیق میدهند. شما یک مدل را با دادن دستورالعملها و زمینه (Context) به آن تطبیق میدهید، نه با تغییر خود مدل.
مزایا: شروع با مهندسی پرامپت آسانتر است و به داده کمتری نیاز دارد. بسیاری از برنامههای موفق تنها با مهندسی پرامپت ساخته شدهاند. سهولت استفاده از آن به شما امکان میدهد با مدلهای بیشتری آزمایش کنید، که شانس شما را برای یافتن مدلی که به طور غیرمنتظرهای برای برنامههایتان مناسب است افزایش میدهد.
معایب: مهندسی پرامپت ممکن است برای کارهای پیچیده یا برنامههایی با نیازمندیهای عملکردی سختگیرانه کافی نباشد.
ریزتنظیمی (Finetuning)، از سوی دیگر، نیازمند بهروزرسانی وزنهای مدل است. شما یک مدل را با ایجاد تغییرات در خود مدل تطبیق میدهید.
مزایا: به طور کلی، تکنیکهای ریزتنظیمی پیچیدهتر هستند و به داده بیشتری نیاز دارند، اما میتوانند کیفیت، تاخیر و هزینه مدل شما را به طور قابل توجهی بهبود بخشند. بسیاری از کارها بدون تغییر وزنهای مدل ممکن نیست، مانند تطبیق مدل با یک کار جدید که در طول آموزش با آن مواجه نبوده است.
حال بیایید روی لایههای توسعه برنامه و توسعه مدل زوم کنیم تا ببینیم هر کدام با ظهور مهندسی هوش مصنوعی چگونه تغییر کردهاند. این کار را با آنچه مهندسان ML سنتی بیشتر با آن آشنا هستند، شروع میکنیم. این بخش مروری بر فرآیندهای مختلف دخیل در توسعه یک برنامه هوش مصنوعی ارائه میدهد. نحوه کار این فرآیندها در سرتاسر این کتاب بحث خواهند شد.
توسعه مدل، لایهای است که معمولاً بیشترین ارتباط را با مهندسی یادگیری ماشین سنتی دارد. سه مسئولیت اصلی دارد: مدلسازی و آموزش (modeling and training)، مهندسی مجموعه داده (dataset engineering) و بهینهسازی استنتاج (inference optimization). ارزیابی نیز لازم است، اما از آنجایی که بیشتر افراد ابتدا در لایه توسعه برنامه با آن مواجه میشوند، ارزیابی را در بخش بعدی بحث خواهم کرد.
مدلسازی و آموزش به فرآیند طراحی یک معماری مدل، آموزش آن و Finetuning آن اشاره دارد. نمونههایی از ابزارها در این دسته عبارتند از: Google’s TensorFlow ، Hugging Face’s Transformers
و Meta’s PyTorch
توسعه مدلهای یادگیری ماشین نیازمند دانش تخصصی ML است. این دانش شامل آشنایی با انواع مختلف الگوریتمهای ML (مانند خوشهبندی (clustering) ، رگرسیون لجستیک، درخت تصمیم و فیلتر کردن مشارکتی (collaborative filtering) ) و معماریهای شبکه عصبی (مانند پیشخور (feedforward) ، بازگشتی( recurrent )، کانولوشنی (convolutional) و ترنسفورمر (transformer) ) میشود. همچنین مستلزم درک این است که یک مدل چگونه یاد میگیرد، شامل مفاهیمی مانند گرادیان کاهشی (gradient descent)، تابع زیان (loss function)، منظمسازی (regularization) و غیره.
با در دسترس بودن مدلهای پایه، دانش ML دیگر یک ضرورت برای ساخت برنامههای هوش مصنوعی نیست. من با بسیاری از سازندگان برنامههای هوش مصنوعی موفق و فوقالعاده ملاقات کردهام که اصلاً علاقهای به یادگیری درباره گرادیان کاهشی ندارند.
با این حال، دانش ML هنوز فوقالعاده با ارزش است، زیرا مجموعه ابزارهایی که میتوانید استفاده کنید را گسترش میدهد و در رفع مشکل هنگامی که یک مدل مطابق انتظار عمل نمیکند کمک میکند.
آموزش همیشه شامل تغییر وزنهای مدل میشود، اما همه تغییرات وزنهای مدل، آموزش محسوب نمیشوند. برای مثال، کوانتیزاسیون (Quantization)، فرآیند کاهش دقت وزنهای مدل، از نظر تکنیکی ارزشهای وزن مدل را تغییر میدهد اما “آموزش” در نظر گرفته نمیشود.
اصطلاح آموزش (training) اغلب میتواند به جای پیشآموزش (pre-training)، ریزتنظیمی (finetuning) و پسآموزش (post-training) به کار رود، که به مراحل مختلف آموزش اشاره دارند:
پیشآموزی (Pre-Training)
پیشآموزی به آموزش یک مدل از ابتدا اشاره دارد - وزنهای مدل به صورت تصادفی مقداردهی اولیه میشوند. برای مدلهای زبانی بزرگ (LLMها)، پیشآموزی اغلب شامل آموزش یک مدل برای تکمیل متن است. از بین همه مراحل آموزش، پیشآموزی اغلب به مراتب پرمصرفترین مرحله از نظر منابع است. برای مدل InstructGPT، پیشآموزی تا ۹۸٪ از کل منابع محاسباتی و داده را به خود اختصاص میدهد. پیشآموزی همچنین زمان زیادی برای انجام نیاز دارد. یک اشتباه کوچک در طول پیشآموزی میتواند زیان مالی قابل توجهی به بار آورد و پروژه را به طور چشمگیری به تأخیر بیندازد. به دلیل ماهیت پرمصرف پیشآموزی، این کار به هنری تبدیل شده که تنها تعداد کمی آن را انجام میدهند. با این حال، کسانی که در پیشآموزی مدلهای بزرگ تخصص دارند، به شدت مورد تقاضا هستند.
ریزتنظیمی (Finetuning)
ریزتنظیمی به معنای ادامه دادن آموزش یک مدلِ از قبل آموزشدیده است - وزنهای مدل از فرآیند آموزشی قبلی به دست میآیند. از آنجا که مدل از پیشآموزی، دانش خاصی را دارد، ریزتنظیمی معمولاً به منابع کمتری (مانند داده و محاسبات) نسبت به پیشآموزی نیاز دارد.
پسآموزش (Post-Training)
بسیاری از افراد از اصطلاح پسآموزش برای اشاره به فرآیند آموزش یک مدل پس از مرحله پیشآموزش استفاده میکنند. به طور مفهومی، پسآموزش و ریزتنظیمی یکسان هستند و میتوانند به جای هم به کار روند. با این حال، گاهی افراد ممکن است از آنها به طور متفاوتی استفاده کنند تا اهداف مختلف را نشان دهند.
معمولاً وقتی این کار توسط توسعهدهندگان مدل انجام میشود، پسآموزش نامیده میشود. برای مثال، OpenAI ممکن است یک مدل را پسآموزش دهد تا در پیروی از دستورالعملها بهتر شود قبل از انتشار آن.
وقتی این کار توسط توسعهدهندگان برنامه انجام میشود، ریزتنظیمی نامیده میشود. برای مثال، شما ممکن است یک مدل OpenAI را (که خودش ممکن است پسآموزش دیده باشد) ریزتنظیم کنید تا آن را با نیازهای خود تطبیق دهید.
پیشآموزش و پسآموزش یک طیف را تشکیل میدهند. فرآیندها و ابزارهای آنها بسیار مشابه است. تفاوتهای آنها بیشتر در فصلهای ۲ و ۷ بررسی میشود.
برخی افراد از اصطلاح آموزش (training) برای اشاره به مهندسی پرامپت استفاده میکنند، که درست نیست. من مقالهای در Business Insider خواندم که نویسنده گفت ChatGPT را آموزش داده تا از خود جوانترش تقلید کند. او این کار را با وارد کردن یادداشتهای خاطرات کودکیاش به ChatGPT انجام داد. به زبان عامیانه، استفاده نویسنده از کلمه “آموزش” درست است، زیرا او در حال آموزش دادن مدل برای انجام کاری است. اما از نظر فنی، اگر شما به یک مدل از طریق زمینه (context)ای که به مدل وارد میکنید آموزش دهید، شما در حال انجام مهندسی پرامپت هستید.
به طور مشابه، من دیدهام افرادی از اصطلاح ریزتنظیمی استفاده میکنند در حالی که کاری که انجام میدهند مهندسی پرامپت است.
این به گردآوری، تولید و حاشیهنویسی (آنوتیشن) داده مورد نیاز برای آموزش و انطباق مدلهای هوش مصنوعی اشاره دارد.
مهندسی ML سنتی: اکثر موارد استفاده بسته (close-ended) هستند. خروجی مدل فقط میتواند بین مقادیر از پیش تعریف شده باشد (مثل «اسپم» یا «غیراسپم»). آنوتیشن چنین دادههایی آسانتر است.
مهندسی هوش مصنوعی: مدلهای پایه باز (open-ended) هستند. آنوتیشن پاسخهای باز (مثل نوشتن یک مقاله) بسیار سختتر از طبقهبندی دادههای بسته است. بنابراین آنوتیشن داده چالش بسیار بزرگتری برای مهندسی هوش مصنوعی است.
نوع داده: مهندسی ML سنتی بیشتر با دادههای جدولی (tabular) کار میکند، در حالی که مدلهای پایه با دادههای ساختارنیافته (unstructured) مانند متن، تصویر و ویدیو کار میکنند.
در مهندسی هوش مصنوعی، دستکاری دادهها بیشتر در مورد حذف دادههای تکراری (deduplication)، توکنسازی (tokenization)، بازیابی زمینه (context retrieval) و کنترل کیفیت، شامل حذف اطلاعات حساس و دادههای مضر است. مهندسی مجموعهداده تمرکز فصل ۸ خواهد بود.
بسیاری استدلال میکنند که چون مدلها اکنون کالاهایی رایج (commodities) شدهاند، دادهها عامل اصلی تمایز خواهند بود و این امر مهندسی مجموعهداده را از همیشه مهمتر میسازد. اینکه به چه میزان داده نیاز دارید به تکنیک انطباق (adapter technique) مورد استفاده شما بستگی دارد. آموزش یک مدل از ابتدا به طور کلی به داده بیشتری نسبت به ریزتنظیمی نیاز دارد، که به نوبه خود، داده بیشتری نسبت به مهندسی پرامپت نیاز دارد.
صرف نظر از میزان دادۀ مورد نیاز، تخصص در دادهها هنگام بررسی یک مدل مفید است، زیرا دادههای آموزشی آن سرنخهای مهمی درباره نقاط قوت و ضعف مدل می دهد.
بهینهسازی استنتاج به معنای سریعتر و ارزانتر کردن مدلها است. بهینهسازی استنتاج همیشه برای مهندسی ML مهم بوده است. کاربران هرگز به مدلهای سریعتر «نه» نمیگویند و شرکتها همواره از استنتاج ارزانتر سود میبرند. با این حال، با مقیاس گرفتن مدلهای پایه که منجر به هزینه و تأخیر استنتاج حتی بالاتری شده است، بهینهسازی استنتاج اهمیتی دوچندان یافته است.
یک چالش در مورد مدلهای پایه این است که آنها اغلب خودرگرسیونی (autoregressive) هستند - توکنها به صورت متوالی تولید میشوند. اگر تولید یک توکن توسط مدل ۱۰ میلیثانیه طول بکشد، تولید یک خروجی با ۱۰۰ توکن، یک ثانیه زمان میبرد و برای خروجیهای بلندتر، زمان بیشتری نیاز است. از آنجایی که کاربران به طرز بدنامی بیطاقت شدهاند، پایین آوردن تأخیر برنامههای هوش مصنوعی به حد تأخیر ۱۰۰ میلیثانیهای مورد انتظار برای یک برنامه اینترنتی معمولی، چالشی عظیم است. بهینهسازی استنتاج به یک زیرشاخه فعال در هر دو حوزه صنعت و دانشگاه تبدیل شده است.
خلاصهای از چگونگی تغییر اهمیت دستههای مختلف توسعه مدل با ظهور مهندسی هوش مصنوعی در جدول ۱-۴ نشان داده شده است.
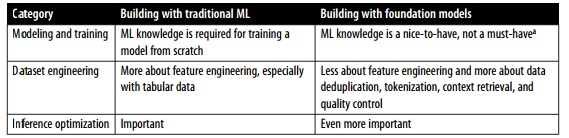
تکنیکهای بهینهسازی استنتاج، شامل کوانتیزاسیون (quantization)، تقطیر (distillation) و موازیسازی (parallelism)، در فصلهای ۷ تا ۹ مورد بحث قرار میگیرند.
در مهندسی ML سنتی، جایی که تیمها از مدلهای اختصاصی خود برای ساخت برنامهها استفاده میکنند، کیفیت مدل یک عامل تمایز است. با مدلهای پایه، جایی که بسیاری از تیمها از همان مدل استفاده میکنند، تمایز باید از طریق فرآیند توسعه برنامه به دست آید.
لایه توسعه برنامه شامل این مسئولیتها است: ارزیابی، مهندسی پرامپت، و رابط هوش مصنوعی.
1.ارزیابی
ارزیابی درباره کاهش خطرات و کشف فرصتها است. ارزیابی در سراسر فرآیند انطباق مدل ضروری است. برای انتخاب مدلها، معیارسنجی پیشرفت، تعیین اینکه آیا یک برنامه برای استقرار آماده است یا خیر، و شناسایی مسائل و فرصتها برای بهبود در تولید، ارزیابی لازم است.
در حالی که ارزیابی همیشه در مهندسی ML مهم بوده است، به دلایل زیادی با مدلهای پایه حتی مهمتر شده است. چالشهای ارزیابی مدلهای پایه در فصل ۳ مورد بحث قرار میگیرد. به طور خلاصه، این چالشها عمدتاً از ماهیت باز و قابلیتهای گستردهتر مدلهای پایه ناشی میشوند.
برای مثال، در وظایف ML بستهای مانند تشخیص کلاهبرداری، معمولاً دادههای صحیح (ground truth) مورد انتظاری وجود دارد که میتوانید خروجیهای مدل خود را با آن مقایسه کنید. اگر خروجی یک مدل با خروجی مورد انتظار متفاوت باشد، میدانید که مدل اشتباه کرده است. با این حال، برای یک وظیفه مانند چتباتها، به ازای هر پرامپت، پاسخهای ممکن بسیار زیادی وجود دارد که تهیه یک فهرست جامع از دادههای صحیح برای مقایسه پاسخ مدل با آن غیرممکن است.
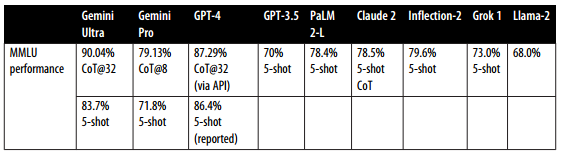
وجود تکنیکهای انطباق بسیار نیز ارزیابی را دشوارتر میکند. سیستمی که با یک تکنیک عملکرد ضعیفی دارد، ممکن است با تکنیک دیگری عملکرد بسیار بهتری داشته باشد. وقتی گوگل در دسامبر ۲۰۲۳ جمنی را راهاندازی کرد، ادعا کرد که جمنی در معیار MMLU از ChatGPT بهتر است. گوگل جمنی را با استفاده از یک تکنیک مهندسی پرامپت به نام CoT@32 ارزیابی کرده بود. در این تکنیک، به جمنی ۳۲ نمونه نشان داده شده بود، در حالی که فقط ۵ نمونه به ChatGPT نشان داده شده بود. وقتی به هر دو پنج نمونه نشان داده شد، ChatGPT عملکرد بهتری داشت، همانطور که در جدول ۱-۵ دیده می شود.
2.مهندسی پرامپت و ساخت زمینه (Prompt engineering and context construction)
مهندسی پرامپت درباره این است که مدلهای هوش مصنوعی را وادار کنیم تا فقط از ورودی، رفتارهای مطلوب را بروز دهند، بدون اینکه وزنهای مدل تغییر کنند. داستان ارزیابی جمنی، تأثیر مهندسی پرامپت بر عملکرد مدل را برجسته میکند. با استفاده از یک تکنیک متفاوت مهندسی پرامپت، عملکرد جمنی آلترا در MMLU از ۸۳.۷٪ به ۹۰.۰۴٪ رسید.
ممکن است بتوان با تنها پرامپتها مدل را وادار به انجام کارهای شگفتانگیزی کرد. دستورالعملهای درست میتوانند مدل را وادار کنند تا وظیفه مورد نظر شما را در قالب انتخابی شما انجام دهد.
مهندسی پرامپت فقط درباره گفتن اینکه مدل چه کاری انجام دهد، نیست. بلکه همچنین درباره دادن زمینه (context) و ابزارهای لازم به مدل برای انجام یک کار مشخص است. برای وظایف پیچیده با زمینه طولانی، ممکن است لازم باشد به مدل یک سیستم مدیریت حافظه ارائه دهید تا مدل بتواند تاریخچه خود را پیگیری کند. فصل ۵ مهندسی پرامپت را مورد بحث قرار میدهد و فصل ۶ ساخت زمینه را.
3.رابط هوش مصنوعی (AI interface)
رابط هوش مصنوعی به معنای ایجاد یک رابط برای کاربران نهایی است تا با برنامههای هوش مصنوعی شما تعامل داشته باشند.
قبل از مدلهای پایه، فقط سازمانهایی با منابع کافی برای توسعه مدلهای هوش مصنوعی میتوانستند برنامههای هوش مصنوعی را توسعه دهند. این برنامهها اغلب در محصولات موجود سازمانها تعبیه میشدند. برای مثال، تشخیص کلاهبرداری در Stripe، Venmo و PayPal تعبیه شده بود. سیستمهای توصیهگر بخشی از شبکههای اجتماعی و اپلیکیشنهای رسانهای مانند Netflix، TikTok و Spotify بودند.
با مدلهای پایه، هرکسی میتواند برنامههای هوش مصنوعی بسازد. شما میتوانید برنامههای هوش مصنوعی خود را به عنوان محصولات مستقل ارائه دهید یا آنها را در سایر محصولات، از جمله محصولات توسعهیافته توسط سایر افراد، تعبیه (embed) کنید. برای مثال، ChatGPT و Perplexity محصولات مستقل هستند، در حالی که Copilot گیتهاب معمولاً به عنوان یک پلاگین در VSCode استفاده میشود و گرامرلی معمولاً به عنوان یک افزونه مرورگر برای Google Docs استفاده میشود. Midjourney میتواند یا از طریق اپلیکیشن وب مستقل خود یا از طریق یکپارچهسازی آن در Discord استفاده شود.
ابزارهایی لازم است که رابطهایی برای برنامههای هوش مصنوعی مستقل ارائه دهند یا ادغام هوش مصنوعی در محصولات موجود را آسان کنند. در اینجا فقط برخی از رابطهایی که برای برنامههای هوش مصنوعی در حال محبوب شدن هستند، آورده شده است:
اپلیکیشنهای وب، دسکتاپ و موبایل مستقل.
افزونههای مرورگر که به کاربران امکان میدهند هنگام مرور اینترنت به سرعت مدلهای هوش مصنوعی را پرسوجو کنند.
چتباتهای یکپارچه شده در اپلیکیشنهای چت مانند Slack، Discord، WeChat و WhatsApp.
بسیاری از محصولات، از جمله VSCode، Shopify و Microsoft 365، APIهایی ارائه میدهند که به توسعهدهندگان امکان میدهد هوش مصنوعی را به عنوان پلاگینها و افزونهها در محصولات خود ادغام کنند. این APIها همچنین میتوانند توسط عاملهای هوش مصنوعی (AI agents) برای تعامل با جهان استفاده شوند (همانطور که در فصل ۶ مورد بحث قرار میگیرد).
در حالی که رابط چت رایجترین مورد استفاده است، رابطهای هوش مصنوعی همچنین میتوانند صوتمحور (مانند دستیارهای صوتی) یا تجسمیافته (مانند واقعیت افزوده و واقعیت مجازی) باشند.
این رابطهای جدید هوش مصنوعی همچنین به معنای روشهای جدید برای جمعآوری و استخراج بازخورد کاربر هستند. رابط مکالمه، دادن بازخورد به زبان طبیعی را برای کاربران بسیار آسانتر میکند، اما استخراج این بازخورد سختتر است. طراحی بازخورد کاربر در فصل ۱۰ مورد بحث قرار میگیرد.
خلاصهای از چگونگی تغییر اهمیت دستههای مختلف توسعه برنامه با ظهور مهندسی هوش مصنوعی در جدول ۱-۶ نشان داده شده است.

تأکید فزاینده بر توسعه برنامه کاربردی، به ویژه بر روی رابطها، مهندسی هوش مصنوعی را به توسعه فولاستک نزدیکتر میکند. اهمیت فزاینده رابطها منجر به تغییر در طراحی ابزارهای هوش مصنوعی برای جذب مهندسین فرانتاند بیشتر میشود.
به طور سنتی، مهندسی ML پایتونمحور است. قبل از مدلهای پایه، محبوبترین فریمورکهای ML عمدتاً از APIهای پایتون پشتیبانی میکردند. امروزه، پایتون همچنان محبوب است، اما پشتیبانی از APIهای جاوا اسکریپت نیز در حال افزایش است (مانند LangChain.js، Transformers.js، کتابخانه Node اوپنایآی و Vercel’s AI SDK).
در حالی که بسیاری از مهندسان هوش مصنوعی از پیشینه سنتی ML میآیند، تعداد بیشتری به طور فزایندهای از توسعه وب یا زمینه فولاستک سرچشمه میگیرند. یک مزیتی که مهندسان فولاستک نسبت به مهندسان ML سنتی دارند، توانایی آنها در تبدیل سریع ایدهها به دمو، دریافت بازخورد و تکرار است.
با مهندسی ML سنتی، شما معمولاً با جمعآوری داده و آموزش یک مدل شروع میکنید. ساختن محصول در آخر میآید. با این حال، با مدلهای هوش مصنوعی که امروزه به راحتی در دسترس هستند، این امکان وجود دارد که ابتدا با ساختن محصول شروع کنید و تنها پس از اینکه محصول وعده موفقیت داد، در داده و مدل سرمایهگذاری کنید، همانطور که در شکل ۱-۱۶ تجسم شده است.

در مهندسی ML سنتی، توسعه مدل و توسعه محصول اغلب فرآیندهای مجزایی هستند، به طوری که مهندسان ML در تصمیمگیریهای محصول در بسیاری از سازمانها به ندرت دخیلند. با این حال، با مدلهای پایه، مهندسان هوش مصنوعی تمایل دارند در ساختن محصول بسیار بیشتر دخیل باشند.
من قصد داشتم این فصل دو هدف را محقق کند. یکی توضیح ظهور مهندسی هوش مصنوعی به عنوان یک رشته، با تشکر از در دسترس بودن مدلهای پایه. دوم ارائه یک نمای کلی از فرآیند مورد نیاز برای ساخت برنامهها بر روی این مدلها.
امیدوارم این فصل به این هدف دست یافته باشد. به عنوان یک فصل مروری، تنها به اکثر مفاهیم به صورت سطحی اشاره شد. این مفاهیم در ادامه کتاب بیشتر کاوش خواهند شد.
این فصل تکامل سریع هوش مصنوعی در سالهای اخیر را مورد بحث قرار داد. از برخی از قابل توجهترین تحولات گذر کرد، از گذار از مدلهای زبانی به مدلهای زبانی بزرگ (LLM)، با تشکر از رویکرد آموزشی به نام خود-نظارتی (self-supervision)، شروع شد. سپس نشان داد که چگونه مدلهای زبانی، سایر شیوههای داده (data modalities) را در خود ادغام کردند تا به مدلهای پایه تبدیل شوند، و چگونه مدلهای پایه منجر به ظهور مهندسی هوش مصنوعی شدند.
رشد سریع مهندسی هوش مصنوعی توسط کاربردهای بسیار که با قابلیتهای نوظهور مدلهای پایه امکانپذیر شدهاند، انگیزه میگیرد. این فصل برخی از موفقترین الگوهای کاربردی را، هم برای مصرفکنندگان و هم برای بنگاهها، مورد بحث قرار داد. با وجود تعداد باورنکردنی برنامههای هوش مصنوعی که از قبل در محیط تولید (production) هستند، ما هنوز در مراحل ابتدایی مهندسی هوش مصنوعی هستیم، و نوآوریهای بیشماری هنوز ساخته نشدهاند.
قبل از ساختن یک برنامه، یک سؤال مهم اما اغلب نادیده گرفته شده این است که آیا باید آن را بسازید؟ این فصل این سؤال را همراه با ملاحظات اصلی برای ساختن برنامههای هوش مصنوعی مورد بحث قرار داد.
در حالی که مهندسی هوش مصنوعی یک اصطلاح جدید است، اما از مهندسی ML تکامل یافته است، که رشته فراگیر درگیر با ساختن برنامهها با استفاده از همه مدلهای ML است. بسیاری از اصول مهندسی ML همچنان برای مهندسی هوش مصنوعی قابل اعمال هستند. با این حال، مهندسی هوش مصنوعی همچنین چالشها و راهحلهای جدیدی را با خود به همراه میآورد. بخش آخر فصل، پشته مهندسی هوش مصنوعی (AI engineering stack) را مورد بحث قرار میدهد، از جمله اینکه چگونه از مهندسی ML تغییر کرده است.
یک جنبه از مهندسی هوش مصنوعی که به ویژه در نوشتن به چالش کشیدنش دشوار است، میزان باورنکردنی انرژی جمعی، خلاقیت و استعداد مهندسی است که جامعه ارائه میدهد. این اشتیاق جمعی اغلب میتواند طاقتفرسا باشد، زیرا پیگیری تکنیکهای جدید، اکتشافات و دستاوردهای مهندسی که به طور مداوم اتفاق میافتند، غیرممکن است.
یک تسلی این است که چون هوش مصنوعی در ادغام اطلاعات عالی است، میتواند به ما در جمعآوری و خلاصهسازی همه این بهروزرسانیهای جدید کمک کند. اما ابزارها فقط تا حدی میتوانند کمک کنند. هرچه یک فضا طاقتفرساتر باشد، داشتن یک چارچوب (framework) برای کمک به ما در جهتیابی در آن مهمتر است. این کتاب قصد دارد چنین چارچوبی را ارائه دهد.
بقیه کتاب این چارچوب را قدم به قدم کاوش خواهد کرد، از بلوک ساختمانی اساسی مهندسی هوش مصنوعی آغاز میکند: مدلهای پایه (foundation models) که ساخت بسیاری از برنامههای شگفتانگیز را ممکن میسازند.